一种语料标注方法、构造语料方法及装置与流程
本发明一般地涉及人工智能领域,特别是涉及自然语言处理标注的方法。
背景技术:
用自然语言与计算机进行通信,这是人们长期以来所追求的。因为它既有明显的实际意义,同时也有重要的理论意义:人们可以用自己最习惯的语言来使用计算机,而无需再花大量的时间和精力去学习不很自然和习惯的各种计算机语言;人们也可通过它进一步了解人类的语言能力和智能的机制。
标注主要是为了为自然语言处理(nlp)模型提供供其学习的语料,使其通过对被标注的语料进行学习,能够在大量文字中快速识别其中的内容信息点。
目前,有三种方法可以构建标注语料。一种是使用分词器进行分词,提取出项目需要的实体将其标注;一种是采用字符串匹配的方法进行直接匹配标注;另一种是人工标注。第一种方法受限于分词器算法和词库的限制,容易造成实体缺标,漏标,少标的现象;第二种因采用字符串直接匹配,容易存在大量的误标情况;第三种是效率极低,且成本高。目前没有一种办法可以完美解决各种情况下的实体识别,让nlp模型快速、准确识别出大量文字中的内容信息点。
技术实现要素:
为了解决现有技术中存在的上述问题,本发明提供一种语料标注方法、构造语料方法及装置。
第一方面,本发明实施例提供一种语料标注方法,其中,包括:配置实体词库步骤,构建实体词库,实体词库储存实体词;匹配步骤,将语料与实体词进行匹配;筛选步骤,对匹配到实体词的语料进行筛选;筛选步骤包括歧义词识别步骤,歧义词识别步骤通过对匹配到的实体词在语料中前后是否存在歧义进行识别,从而筛选语料;标注步骤,对经过筛选步骤保留的语料和未匹配到实体词的语料分别进行标注。
在一实施例中,还包括:实体词增量步骤,对实体词库中的实体词进行扩充。
在一实施例中,其中,筛选步骤还包括:分词筛选步骤,通过分词器对语料进行筛选。
在一实施例中,其中,筛选步骤还包括:完全重叠词判断步骤,对分词筛选步骤中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,其中,筛选步骤还包括:语境判断步骤,根据匹配到的实体词的类别与语料的语境是否相符进行筛选。
在一实施例中,其中,筛选步骤还包括:实体词长度判断步骤,在语境判断步骤之前,对匹配到的实体词的长度进行判断,仅对匹配到的实体词的长度未达到词长预定值的语料进行语境判断步骤。
在一实施例中,其中,筛选步骤还包括:分词筛选步骤,通过分词器对语料进行筛选;语境判断步骤,根据匹配到的实体词的类别与语料的语境是否相符进行筛选;实体词类别判断步骤,根据匹配到的实体词的类别决定采用分词筛选步骤或语境判断步骤。
在一实施例中,其中,筛选步骤还包括:完全重叠词判断步骤,对分词筛选步骤排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,其中,筛选步骤还包括:实体词长度判断步骤,在语境判断步骤之前,对匹配到的实体词的长度进行判断,仅对匹配到的实体词的长度未达到词长预定值的语料进行语境判断步骤。
在一实施例中,其中,筛选步骤还包括:有效语料判断步骤,根据语料的长度与匹配到的实体词的长度差值是否大于差值预设值进行筛选。
在一实施例中,其中,筛选步骤还包括:部分重叠词判断步骤,根据是否存在匹配到两个或两个以上的实体词部分重叠进行筛选。
在一实施例中,其中,筛选步骤还包括:排除词过滤步骤,判断在匹配步骤中匹配到的实体词是否为预设排除词,放弃匹配为预设排除词的实体词。
在一实施例中,其中,配置实体词库步骤还包括:配置排除词库步骤,构建排除词库,预设排除词存放于排除词库中。
在一实施例中,其中,筛选步骤还包括:优先级判断步骤,在匹配到的一个或多个实体词被另外一个或多个实体词完全覆盖之际,根据预设条件进行判断仅保留匹配其中一个实体词。
在一实施例中,其中,预设条件是匹配到的实体词的长度和/或类别。
在一实施例中,其中,配置实体词库步骤中,根据实体词的类别构建一个或多个实体词库。
在一实施例中,其中,匹配步骤中,将语料循环匹配在一个或多个实体词库中的实体词。
在一实施例中,其中,配置实体词库步骤还包括:配置插入词库步骤,构建插入词库,用于增补实体词。
在一实施例中,其中,还包括:标注计数步骤,根据实体词的类别,对经过标注的语料中匹配到的实体词进行统计。
在一实施例中,其中,还包括:停止标注步骤,当标注计数步骤统计的一个类别中匹配到的实体词超过数量预定值时,停止对类别的实体词进行标注。
第二方面,本发明实施例提供一种构造语料方法,其中,包括:语料收集步骤,将语料标注方法中筛选步骤筛选出的语料进行收集;待换实体词收集步骤,收集用于构造语料的待换实体词;替换步骤,根据实体词的类别,将语料收集步骤收集到的语料中匹配到的实体词,替换为待换实体词收集步骤收集到的相同类别的待换实体词;再标注步骤,对通过替换步骤得到的语料进行标注。
在一实施例中,其中,语料收集步骤还包括:对仅匹配到一个实体词的语料进行收集。
在一实施例中,其中,待换实体词收集步骤还包括:对语料标注方法中被标注的实体词的数量进行统计,将数量低于标注数量预定值的实体词进行收集。
在一实施例中,其中,替换步骤还包括:标志替换步骤,将实体词替换为标志,标志能够表示实体词的类别;实体词替换步骤,根据标志的类别,将标志替换为与标志的类别相同的待换实体词。
第三方面,本发明实施例提供一种语料标注装置,其中,包括:配置实体词库模块,用于构建实体词库,实体词库储存实体词;匹配模块,用于将语料与实体词进行匹配;筛选模块,用于对匹配到的实体词的语料进行筛选;筛选模块还包括歧义词识别模块,歧义词识别模块用于根据匹配到的实体词在语料中前后是否存在歧义,筛选语料;标注模块,用于对经过筛选模块保留的语料和未匹配到实体词的语料分别进行标注。
在一实施例中,其中,还包括:实体词增量模块,用于对实体词库中的实体词进行扩充。
在一实施例中,其中,筛选模块还包括:分词筛选模块,用于通过分词器对语料进行筛选。
在一实施例中,其中,筛选模块还包括:完全重叠词判断模块,用于对分词筛选模块中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,其中,筛选模块还包括:语境判断模块,用于根据匹配到的实体词的类别与语料的语境是否相符进行筛选。
在一实施例中,其中,筛选模块还包括:实体词长度判断模块,用于判断匹配到的实体词的长度,将匹配到的实体词的长度未达到词长预定值的语料通过语境判断模块进行筛选。
在一实施例中,其中,筛选模块还包括:分词筛选模块,用于通过分词器对语料进行筛选;语境判断模块,用于根据匹配到的实体词的类别与语料的语境是否相符进行筛选;实体词类别判断模块,用于根据匹配到的实体词的类别,决定语料通过分词筛选模块或语境判断模块。
在一实施例中,其中,筛选模块还包括:完全重叠词判断模块,用于对分词筛选模块中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,其中,筛选模块还包括:实体词长度判断模块,用于判断匹配到的实体词的长度,将匹配到的实体词的长度未达到词长预定值的语料通过语境判断模块筛选。
在一实施例中,其中,筛选模块还包括:有效语料判断模块,用于根据语料的长度与匹配到的实体词的长度差值是否大于差值预设值进行筛选。
在一实施例中,其中,筛选模块还包括:部分重叠词判断模块,用于根据是否存在匹配到两个或两个以上的实体词部分重叠进行筛选。
在一实施例中,其中,筛选模块还包括:排除词过滤模块,用于判断在匹配模块中匹配到的实体词是否为预设排除词,放弃匹配为预设排除词的实体词。
在一实施例中,其中,配置实体词库模块:还用于构建排除词库,预设排除词存放于排除词库中。
在一实施例中,其中,筛选模块还包括:优先级判断模块,用于在匹配到的一个或多个实体词被另外一个或多个实体词完全覆盖之际,根据预设条件进行判断仅保留匹配其中一个实体词。
在一实施例中,其中,预设条件是匹配到的实体词的词长和/或类别。
在一实施例中,其中,配置实体词库模块,还用于根据实体词的类别构建一个或多个实体词库。
在一实施例中,其中,匹配模块中,还用于将语料循环匹配在一个或多个实体词库中的实体词。
在一实施例中,其中,配置实体词库模块还用于构建插入词库,用于增补实体词。
在一实施例中,其中,还包括:标注计数模块,用于根据实体词的类别,对经过标注的语料中匹配到的实体词进行统计。
在一实施例中,其中,还包括:停止标注模块,在标注计数模块统计的一个类别中匹配到的实体词超过数量预定值之际,停止对类别的实体词进行标注。
第四方面,本发明实施例提供一种构造语料装置,其中,包括:语料收集模块,用于将语料标注方法中筛选步骤筛选出的语料进行收集;待换实体词收集模块,用于收集用于构造语料的待换实体词;替换模块,用于根据实体词的类别,将语料收集模块收集到的语料中匹配到的实体词,替换为待换实体词收集模块收集到的相同类别的待换实体词;再标注模块,用于对通过替换模块得到的语料进行标注。
在一实施例中,其中,语料收集模块还用于:对仅匹配到一个实体词的语料进行收集。
在一实施例中,其中,待换实体词收集模块还用于:对语料标注方法中被标注的实体词的数量进行统计,将数量低于标注数量预定值的实体词进行收集。
在一实施例中,其中,替换模块还包括:标志替换模块,用于将实体词替换为标志,标志能够表示实体词的类别;实体词替换模块,用于根据标志的类别,将标志替换为与标志的类别相同的待换实体词。
第五方面,本发明实施例提供一种电子设备,其中,电子设备包括:存储器,用于存储指令;以及处理器,用于调用存储器存储的指令执行语料标注方法或构造语料方法。
第五方面,本发明实施例提供一种计算机可读存储介质,其中,计算机可读存储介质存储有计算机可执行指令,计算机可执行指令在由处理器执行时,执行语料标注方法或构造语料方法。
本方案实施例提供的一种语料标注方法、构造语料方法及装置,能够提高标注的准确率,提高匹配量,并且提高标注效率。能够提供给nlp模型提供更全面的有效语料,方便nlp模型学习。
附图说明
通过参考附图阅读下文的详细描述,本发明实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
图1示出了本发明实施例提供的一语料标注方法示意图;
图2示出了本发明实施例提供的另一语料标注方法示意图;
图3示出了本发明实施例提供的另一语料标注方法示意图;
图4示出了本发明实施例提供的另一语料标注方法示意图;
图5示出了本发明实施例提供的一构造语料方法示意图;
图6示出了本发明实施例提供的一语料标注装置示意图;
图7示出了本发明实施例提供的一构造语料装置示意图;
图8示出了本发明实施例提供的一种电子设备示意图。
在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
下面将参考若干示例性实施方式来描述本发明的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本发明,而并非以任何方式限制本发明的范围。
需要注意,虽然本文中使用“第一”、“第二”等表述来描述本发明的实施方式的不同模块、步骤和数据等,但是“第一”、“第二”等表述仅是为了在不同的模块、步骤和数据等之间进行区分,而并不表示特定的顺序或者重要程度。实际上,“第一”、“第二”等表述完全可以互换使用。
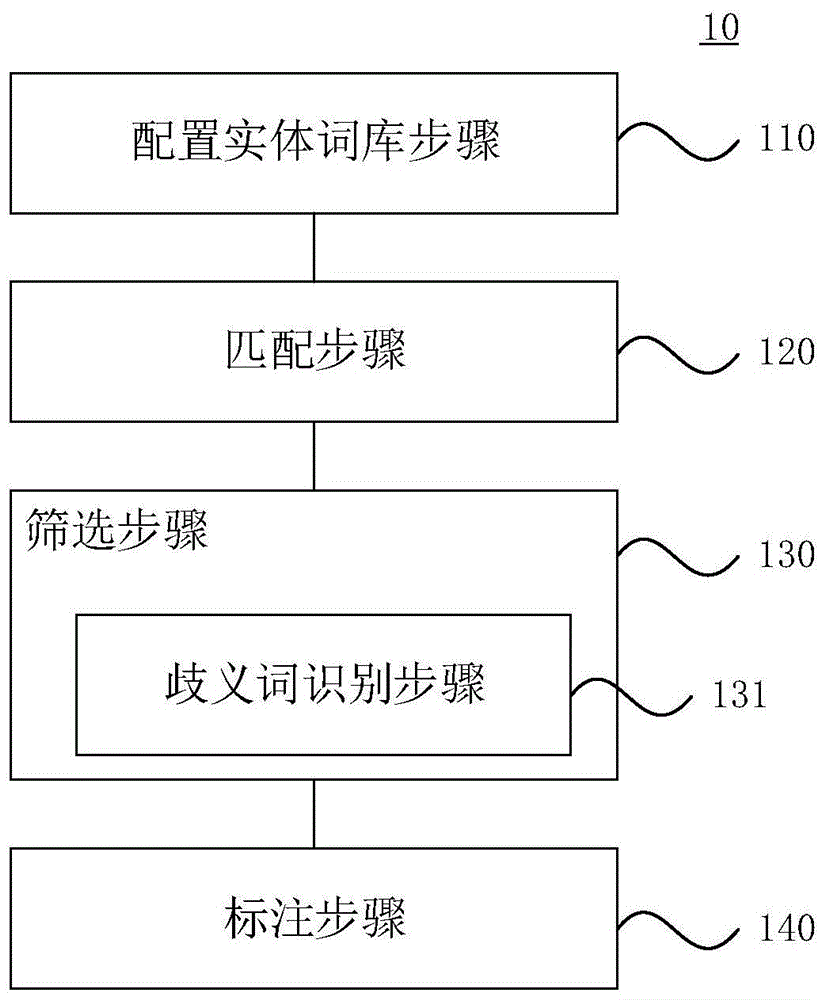
图1为语料标注方法10的一个实施例的流程示意图。如图1所示,该实施例方法包括:配置实体词库步骤110、匹配步骤120、筛选步骤130、歧义词识别步骤131、标注步骤140。下面对图1中的各步骤进行详细说明。
配置实体词库步骤110,构建实体词库,实体词库储存实体词。
根据需要为nlp模型提供学习的语料中的信息点,通过多种方式获取需要用于标注的实体词。在本实施例中,可以通过以下一种或多种方式获得实体词以构建实体词库:获取已有数据库中的热门实体词;获取网络中的热门实体词;获取已有数据库中的全部实体词。
在一实施例中,语料标注方法10包括语料获取步骤,获取用于标注的语料,但不限于以下几种实施方式。对需要标注的语料,可根据实际的需求获取,获取的方式可以是从已有数据库中获取,也可以通过网络获取。在一实施例中,语料获取步骤还包括:配置语料库步骤,构建语料库用于存放用于标注的语料。通过配置原始语料库,将获取的语料存放在原始语料库中。同时,为了便于nlp模型的学习,通过标点符号的分割,以5-30字的单句的形式保存语料。
在一实施例中,配置实体词库步骤110中,根据实体词的类别构建一个或多个实体词库。可根据兴趣点(pointsofinterest,poi)的需求,根据实体词的类别构建一个或者多个实体词库,例如“餐饮、住宿、景点娱乐、交通、美食、目的地”等。
在一实施例中,配置实体词库步骤110还包括配置插入词库步骤,在每个实体词库中构建插入词库,用于增补实体词。使得后续实体词的扩展更加方便。
在一实施例中,配置实体词库步骤110还包括配置排除词库步骤,在每个实体词库中构建排除词库,用于保存预设排除词。预设排除词为不希望对其进行标注的实体词。
匹配步骤120,将语料与实体词进行匹配。
本实施例中,采用直接匹配的方法,将nlp模型所需要的语料,匹配之前构建的实体词库中的实体词,包括插入词库中的实体词,但不包括排除词库中的实体词。
本实施例中,可以将匹配到的实体词以下述格式方式暂存:“(匹配到的实体词,匹配到的位置,实体词的类别)”,每个语料创建一个列表(list),将通过筛选保留的实体词以上述格式存放在list中,并最终根据list中的信息进行标注。例如:语料:北京饭店是北京最好的饭店;匹配到的内容:(“北京饭店”,“0”,“1”),其中“北京饭店”代表实体词内容、“0”代表该实体词在该语料中第一个字出现的位置、“1”代表餐饮,即类别;同理,(“北京”,“0”,“6”)和(“北京”,“5”,“6”);“6”代表目的地的类别。通过该种方式便于后续的筛选和标注。
在一实施例中,根据实体词的类别构建一个或者多个实体词库,匹配步骤120可通过循环匹配的方式,将语料循环匹配在一个或多个实体词库中的实体词。以保证全面匹配。
筛选步骤130,对匹配到实体词的语料进行筛选。
通过筛选步骤130对语料的准确性进行有效提高,通过不同的筛选方式可以从不同角度针对可能出现的误标的情况进行判断,保存准确的语料,使得nlp模型的学习更加可靠。
本实施例中,筛选步骤130包括歧义词识别步骤131,歧义词识别步骤131通过对匹配到的实体词在语料中前后是否存在歧义进行识别,从而筛选语料。
本实施例中,歧义识别步骤131中含有两部分,一部分是算法,一部分是数据库。在算法部中,会对与标注词相连接的词汇进行判别。在数据库中,保留大量的常用词、专业词。在多数情况下,词库无法及时更新一些新词,导致分词错误,产生误标。通过歧义识别步骤131,可以检查出将被标注的实体词前后位置是否有所述情况发生,向模型提供最准确的含有标注内容的语料。例如:语料:我跟漂亮的小宝贝和美妞去吃下午茶。如经过分词器,会将该语料分成:我rr,跟p,漂亮a,的udel,小宝贝nz,和美ns,妞儿n,去vf,吃v,下午茶nf。“和美”被识别为地名,“妞儿”被识别为人。使用其他分词器和词库也无法完全准确分词,导致误标。通过使用歧义识别步骤131,可以发现“和美”中的“美”,和“美妞儿”中的“美”在同一位置,因此可以识别出,该语料中可能存在误标的情况。歧义识别步骤131会检查所有匹配到的实体词的前后位置是否有以上情况发生,一旦发生这种情况,为了向nlp模型提供最准确的含有标注内容的语料,这句语料将被丢弃。
标注步骤140,对筛选步骤130筛选出的语料和未匹配到实体词的语料分别进行标注。
本实施例中,可采用以下标注序列体系中的一种:io,bio,bioe,bmewo,bmewo+。以bio序列标注体系为例:对不需要标注的内容会被标注为o,需要被标注的实体词的第一个字会被标注为b(开头)、其余字标注为i(中间内容),同时也会对所标注的实体词的类别做区分。
在一实施例中,对经过筛选保留的语料通过bio序列标注体系标注,同时,也对未匹配到实体词的语料进行bio序列标注体系标注(即,全句均标注为o),使得nlp模型能够对比学习。
图2示出了语料标注方法10的另一实施例的流程示意图,如图2所示,语料标注方法10还包括:实体词增量步骤111,对实体词库中的实体词进行扩充。
扩充的方式有多种,本实施例以一例作为说明。以酒店名称为例:“三亚一线天大酒店(亚龙湾分店)”,在这个酒店名字中包含有目的地:“三亚”,酒店后缀:“大酒店”,括号内补充内容:“(亚龙湾分店)”。在实体词增量步骤111,我们可通过已有数据库或从网络获取的数据,匹配目的地前缀识别出开头是否含有目的地;后缀,如酒店,宾馆,旅馆,度假酒店等;以及括号内补充内容,来进行合理的排列组合组转写成具有实际意义,可以读懂的该酒店名称不同叫法。例如:去掉目的地后仍旧包含具有酒店意义的后缀,那么可以去掉目的地;去掉括号内内容后仍旧含有酒店意义的后缀,那么可以去掉括号内容;将酒店后缀词条内的内容转换,如“酒店”变为“旅馆”等;将酒店后缀名、目的地、括号补充内容中的一项或几项去除后,如果剩下的字数较少,这时候为了避免出现歧义,我们选择放弃这条改写。由“三亚一线天大酒店(亚龙湾分店)”扩充的部分词:一线天大酒店;一线天酒店;一线天旅馆;一线天大酒店(亚龙湾分店);三亚一线天大酒店。
获取的实体词可能存在不准确的情况,或者有一些缩略词并未被获取,通过实体词增量步骤111对实体词进行扩充,使得实体词能够更加全面,提高了标注的完整性,减少了漏标的情况。
图3示出了语料标注方法10的另一些实施例的流程示意图,如图3所示,本公开的筛选步骤130中,还可包括其他一个或多个方式的筛选方式,通过不同的筛选方式,能够更加有效的避免误标的情况,提高标注的准确性。
在一实施例中,筛选步骤130还包括分词筛选步骤132,通过分词器对语料进行筛选。
本实施例中,通过分词器确认匹配到的实体词的类别,如出现歧义则这句语料将被丢弃。例如:语料:意大利有好吃的意面和美味的咖啡。其中“和美”会被直接匹配成目的地,而分词器会将这个句子分词为:“意大利ns,有vyou,好吃a,的ude1,意面nf,和cc,美味n,的ude1,咖啡nf”,其中ns用来表示目的地名字。因此经过分词器的筛选避免了误标。
可采用不同的分词器进行分词,本实施例中采用的是汉语言处理包(hanlp)分词器,hanlp是一种开源的,集中文分词、自然语言处理(ner)、摘要关键字、句法分析等一体的包含语料包的分词器。
在一实施例中,筛选步骤130还包括完全重叠词判断步骤1321,对分词筛选步骤132中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
本实施例中,完全重叠词判断步骤1321用来识别在被重叠在其他实体词中一些词实体词,并让它保留下来不被分词筛选步骤132删除掉。例如:语料:“北京饭店是北京最好的饭店”;匹配到的内容:(“北京饭店”,“0”,“1”),其中1代表餐饮类别;(“北京”,“0”,“9”)、(“北京”,“5”,“9”),其中9代表目的地类别。然而在(“北京”,“0”,“9”)中,分词器会将“北京饭店”定义为一个实体,其中的“北京”则不会被识别为一个目的地,则该句会被分词筛选步骤132排除。而完全重叠词判断步骤1321,将被分词筛选步骤132排除的语料再进行筛选,从而保护这些已经被匹配到的正确的词不被丢弃。
在一实施例中,筛选步骤130还包括语境判断步骤133,根据匹配到的实体词的类别与语料的语境是否相符进行筛选。
本实施例中,根据实体词类别,配置与类别相对应的字词组,例如:住宿类别的实体词,对应的字词组可以有:“预订”、“住”等,利用这些字词组来判断该条语料的语境是否符合所匹配实体词。例如:语料:“我们今天晚住在如家”,其中“如家”这个酒店名称词汇会被匹配到,并且语料中含有“住”这个跟住宿相关的词汇,因此这句将被保留。而语料:“这里如家一般温暖舒适”,在这句中虽然也有“如家”,但是这里的“如家”指的并不是“如家酒店”,在语境判断步骤133中,没有在其中发现跟住宿相关的词汇,所以这句语料将被丢弃。
通过语境判断步骤133能够有效提高准确性,减少误标的情况。
在一实施例中,筛选步骤130还包括:实体词长度判断步骤1331,在语境判断步骤133之前,对匹配到的实体词的长度进行判断,仅对匹配到的实体词的长度未达到词长预定值的语料进行语境判断步骤。
在实体词的长度较短的情况下,更加容易出现误标的情况,相比而言,实体词的长度如果比较长,误标的情况就会相对较少,因此在实体词的长度比较长的情况下运用语境判断步骤133也会造成一定的错误的丢弃语料的情况。为了标注效果更好,更全面,本实施例还包括实体词长度判断步骤1331,对于存在实体词长度未达到词长预定值的情况下进行语境判断步骤133,而如果实体词长度超过词长预定值则无需进行语境判断步骤133。这里的词长预定值可以根据实际的类别来确定,如,三个字。
在一实施例中,筛选步骤130还包括:分词筛选步骤132、语境判断步骤133、以及实体词类别判断步骤134,实体词类别判断步骤134根据匹配到的实体词的类别决定采用分词筛选步骤132或语境判断步骤133。
在实际匹配中,如果有某类别的实体词的长度均很短并且容易出现误标的情况下,可以通过实体词类别判断步骤134来将全部该类词汇采用分词筛选步骤132进行筛选。例如:目的地类别的词汇,字长普遍较短而且极其容易出现歧义,还可能出现在任何语境下,如果采用语境判断步骤133可能会造成漏标和误标。因此,通过实体词类别判断步骤134来进行区分筛选方式,提高标注质量。
在另一例中,可进一步相应的包括完全重叠词判断步骤1321和/或实体词长度判断步骤1331。
在一实施例中,筛选步骤130还包括:有效语料判断步骤135,根据语料的长度与匹配到的实体词的长度差值是否大于差值预设值进行筛选。
有效语料判断步骤135中,判断语料的长度必须比所匹配到的每一个实体词的长度均大于一个差值预设值。该差值预设值可以根据实际情况来定,如,三个字。如果长度差值为超过差值预设值,则这句语料将被丢弃。
想要nlp模型更准确的记住一个实体词,就要把这个实体词放到一条完整的句子中,配合当下的语境,要表达出一个完整的意思,而不是在实体词前后之间没有什么联系的句子。因此,通过有效语料判断步骤135进行筛选,能够提高语料的质量。在另一实施例中,有效语料判断步骤135可以跟在匹配步骤120之后先进行,这样可以提高后续筛选的效率。
在一实施例中,筛选步骤130还包括:部分重叠词判断步骤136,根据是否存在匹配到两个或两个以上的实体词部分重叠进行筛选。
部分重叠词判断步骤136判断一句语料中的两个或两个以上的实体词是否存在部分重叠的情况,如果存在该种情况,则这句语料将被丢弃。例如:语料:“黄焖鸡公煲都很好吃”。作者可能是想表达黄焖鸡和鸡公煲都很好吃这个意思,但是可能由于打字习惯或者错误导致了该语料的不准确和标注的混乱,该种语法混乱的语料被nlp模型学习会造成识别的不准确。因此,通过部分重叠词判断步骤136鉴别语料是否是一条优秀、逻辑表述正常的句子,或者可能会被误标的句子加以排除。
在一实施例中,筛选步骤130还包括:排除词过滤步骤137,判断在匹配步骤中匹配到的实体词是否为预设排除词,放弃匹配为预设排除词的实体词。
排除词过滤步骤137可以判断语料中是否含有预设排除词,即一些不希望进行匹配并标注的实体词,如果通过匹配步骤120匹配到的实体词为预设排除词,则放弃匹配该实体词。在一实施例中,配置实体词库步骤110还包括配置排除词库步骤,在每个实体词库中构建排除词库,用于保存预设排除词。如根据实体词不同类别建立多个词库时,不希望对某实体词的某类别进行标注,则可以通过在该类别的实体词库中的排除词库中加入该实体词。例如,“北京饭店”可能出现在餐饮和住宿两个类别的词库中,但不希望其作为住宿的类别被标注时,则在住宿类别的实体词库中的排除词库中加入“北京饭店”,则语料中的“北京饭店”仅会被以餐饮类别被匹配到。
在一实施例中,筛选步骤130还包括:优先级判断步骤138,在匹配到的一个或多个实体词被另外一个或多个实体词完全覆盖之际,根据预设条件进行判断仅保留匹配其中一个实体词。
在一些语料中存在匹配的一个或多个实体词被另外一个或多个实体词完全覆盖的情况,即,一个实体词中包含另一个实体词,或是在不同类别中具有相同的实体词被先后匹配出。优先级判断步骤138在这种情况下判断保留哪个重叠词,让标注的更加准确。例如:语料:“北京饭店是北京最好的饭店”,匹配到的内容:(“北京饭店”,“0”,“1”),其中1代表餐饮类别、(“北京”,“0”,“9”)和(“北京”,“5”,“9”)其中9代表目的地类别。在这个句子中,存在(“北京饭店”,“0”,“1”)和(“北京”,“5”,“9”)是属于完全覆盖的关系,而正确的标注应该仅标注“北京饭店”,对“北京饭店”中含有的“北京”不应进行标注,因此通过优先级判断步骤138根据预设条件判断保留哪个实体词。
在一实施例中,预设条件可以是匹配到的实体词的长度和/或类别。在根据具有完全覆盖关系的实体词长度判断时,选择长度更长的实体词进行标注,原因在于字数越长说明描述内容越多,越准确。同时,也可以根据实际的标注类别的需要,根据类别设置优先级,还以上述例子加以说明:在一些情况下(“北京饭店”,“0”,“1”)也有可能被当成是宾馆,那么这句语料会出现第四个实体词(“北京饭店”,“0”,“2”),其中2代表宾馆类别实体词。在这种情况下,就取决于实际需求,如果需要将“北京饭店”在nlp模型中被识别成饭店,那么就设置餐饮类别的优先级高于宾馆类别的优先级,保留(“北京饭店”,“0”,“1”);反之,则保留(“北京饭店”,“0”,“2”)。通过优先级判断步骤138能够使得我们标注的内容更加准确可靠。
以上是对匹配步骤120以及筛选步骤130做了详细介绍。关于筛选步骤130中的多种筛选方式,可以选取其中的一种或几种。关于匹配和筛选的形式,可以但不限于以下几种实施方式:
在一实施例中,将语料通过匹配步骤120匹配全部实体词,将语料通过筛选步骤130进行筛选时,对于语料中匹配到的每一个实体词分别进行筛选。该种方式简单易行,适用于实体词量不多,类型相对单一的情况。
在另一实施例中,将语料通过匹配步骤120匹配一个实体词后,通过筛选步骤130进行筛选,通过筛选保留该语料后,再经过匹配步骤120进行匹配下一个实体词,直到匹配到语料中所有的实体词并逐一通过筛选步骤130。该种方式更加准确,适合语料较长的情况。
在另一实施例中,根据类别建立多个实体词库,匹配步骤120一次匹配一个实体词库中的实体词,经过筛选步骤130保留该语料后,再经过匹配步骤120匹配下一个词库中的实体词,直到匹配到语料中所有的实体词并逐一通过筛选步骤130。在本实施例中,可以将分词筛选步骤132中判断决定采用分词筛选步骤132的类别的词库,在最后进行匹配和筛选。该种方式能够更加准确的匹配和标注,适合多种类别实体词的情况。
在另一实施例中,根据类别建立多个实体词库,匹配步骤120一次匹配一个实体词库中的实体词;经过筛选步骤130中除优先级判断步骤138和歧义识别步骤131以外的步骤;如保留该语料,则再经过匹配步骤120匹配下一个词库中的实体词,直到匹配到语料中所有的实体词并逐一通过筛选步骤130中除优先级判断步骤138和歧义识别步骤131以外的步骤;如保留该语料,则可依次通过优先级判断步骤138和歧义识别步骤131进行进一步筛选。在本实施例中,可以将分词筛选步骤132中判断决定采用分词筛选步骤132的类别的词库,在最后进行匹配和筛选。该种方式能够更加准确的匹配和标注,在多种类别实体词的情况下提高语料质量。
图4示出了语料标注方法10的另一实施例的流程示意图,如图4所示,语料标注方法10还包括:标注计数步骤150,根据实体词的类别,对经过标注的语料中匹配到的实体词进行统计。
为了帮助我们更好地把握标注效果,标注计数步骤150用来记录哪些实体词被标注过以及被标注的次数。标注计数步骤150可以监测被标注语料内容的情况。使得后续的更新、检查、迭代变得更加简单方便。
在一实施例中,语料标注方法10还包括:停止标注步骤,当标注计数步骤150统计的一个类别中匹配到的实体词超过数量预定值时,停止对类别的实体词进行标注。
标注计数步骤150的统计,停止标注步骤能够停止标注某类别的实体词。通过停止标注步骤可以制定某类实体词的数量预定值,一旦到达数量预定值,这类词就不会被再次标注了。在文字内容中,某些类别很容易出现被大量匹配的情况,然而当同一个词出现的次数太多时,对nlp模型的学习也是不利的。因此,通过标注计数步骤150和停止标注步骤能够提高nlp模型的学习的效率。
图5示出了构造语料方法20的实施例的流程示意图,如图5所示,在一些情况下,某些实体词在语料中出现的较少,导致供nlp模型学习的素材较少,因此,本公开提出一种构造语料方法20,通过人工的构造语料,使得标注的语料更加全面,提供更完善的供nlp模型学习的素材。具体来说,构造语料方法20包括:语料收集步骤210、待换实体词收集步骤220、替换步骤230以及再标注步骤240。下面对图5中的各步骤进行详细说明。
语料收集步骤210,语料标注方法10中筛选步骤筛选出的语料进行收集。
对通过语料标注方法10筛选的语料进行收集,得到用于构造语料的素材。可以将通过语料标注方法10筛选步骤130筛选出还未标注的语料进行复制,单独保存于一个文件夹中。
待换实体词收集步骤220,收集用于构造语料的待换实体词。
获取需要构造的实体词,也就是将需要补充的实体词进行获取并存放。
替换步骤230,根据实体词的类别,将语料收集步骤收集到的语料中匹配到的实体词,替换为待换实体词收集步骤收集到的相同类别的待换实体词。
为了保证构造出的语料也是正确的,需要对实体词的类别进行判断,替换的待换实体词与语料中的原有实体词应属于相同类别。
再标注步骤240,对通过替换步骤230得到的语料进行标注。
通过构造语料方法20能够采取替换手段,速度极快的构造语料,不需要检查。
在一实施例中,语料收集步骤210还包括:对仅匹配到一个实体词的语料进行收集。从而使得构造的语料会更加准确,直接按照所属的类别,和实体词进行直接替换,使得替换更加容易。
在一实施例中,待换实体词收集步骤220还包括:对语料标注方法10中被标注的实体词的数量进行统计,将数量低于标注数量预定值的实体词进行收集。从而使得能够针对标注量低的实体词构造语料,能够高效率的补充语料。
在一实施例中,替换步骤230还包括:标志替换步骤,将实体词替换为标志,标志能够表示实体词的类别;实体词替换步骤,根据标志的类别,将标志替换为与标志的类别相同的待换实体词。采用该种替换方式,能够方便对一个语料进行多次替换,便于构造更多语料。
图6为语料标注装置30的一个实施例的流程示意图。如图6所示,语料标注装置30中包含多个模块,以下结合图6对各实施例详细说明。
在一实施例中,语料标注装置30包括:配置实体词库模块310、匹配模块320、筛选模块330、歧义词识别模块331、标注模块340。
配置实体词库模块310,用于构建实体词库,实体词库储存实体词。
在一实施例中,配置实体词库模块310中,还用于根据实体词的类别构建一个或多个实体词库。
在一实施例中,配置实体词库模块310还用于在每个实体词库中构建插入词库,用于增补实体词。使得后续实体词的扩展更加方便。
在一实施例中,配置实体词库模块310还用于在每个实体词库中构建排除词库,用于保存预设排除词。预设排除词为不希望对其进行标注的实体词。
匹配模块320,用于将语料与实体词进行匹配。
在一实施例中,根据实体词的类别构建一个或者多个实体词库,匹配模块320可通过循环匹配的方式,将语料循环匹配在一个或多个实体词库中的实体词。以保证全面匹配。
筛选模块330,用于对匹配到实体词的语料进行筛选。
本实施例中,筛选模块330包括歧义词识别模块331,歧义词识别模块331通过对匹配到的实体词在语料中前后是否存在歧义进行识别,筛选语料。
标注模块340,对筛选模块330筛选出的语料和未匹配到实体词的语料分别进行标注。
在一实施例中,语料标注装置30还包括:实体词增量模块311,对实体词库中的实体词进行扩充。
在一实施例中,本公开的筛选模块330中,还可包括其他一个或多个模块,通过不同的筛选方式,能够更加有效的避免误标的情况,提高标注的准确性。
在一实施例中,筛选模块330还包括分词筛选模块332,用于通过分词器对语料进行筛选。
在一实施例中,筛选模块330还包括完全重叠词判断模块3321,用于对分词筛选模块332中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,筛选模块330还包括语境判断模块333,用于根据匹配到的实体词的类别与语料的语境是否相符进行筛选。
在一实施例中,筛选模块330还包括:实体词长度判断模块3331,用于判断匹配到的实体词的长度,将匹配到的实体词的长度未达到词长预定值的语料通过语境判断模块筛选。
在一实施例中,筛选模块330还包括:分词筛选模块332、语境判断模块333、以及实体词类别判断模块334,实体词类别判断模块334根据匹配到的实体词的类别,决定语料通过分词筛选模块或语境判断模块进行筛选。
在一实施例中,筛选模块330还包括:完全重叠词判断模块3321,用于对分词筛选模块332中排除的语料,根据是否存在匹配到的实体词被其它匹配到的实体词完全覆盖进行筛选。
在一实施例中,筛选模块330还包括:实体词长度判断模块3331,用于判断匹配到的实体词的长度,将匹配到的实体词的长度未达到词长预定值的语料通过语境判断模块333筛选。
在一实施例中,筛选模块330还包括:有效语料判断模块335,用于根据语料的长度与匹配到的实体词的长度差值是否大于差值预设值进行筛选。
在一实施例中,筛选模块330还包括:部分重叠词判断模块336,用于根据是否存在匹配到两个或两个以上的实体词部分重叠进行筛选。
在一实施例中,筛选模块330还包括:排除词过滤模块337,用于判断在匹配模块中匹配到的实体词是否为预设排除词,放弃匹配为预设排除词的实体词。
在一实施例中,筛选模块330还包括:优先级判断模块338,用于在匹配到一个或多个的实体词之际,根据预设条件进行判断仅保留匹配其中一个实体词。
在另一实施例中,根据类别建立多个实体词库,匹配模块320一次匹配一个实体词库中的实体词;经过筛选模块330中除优先级判断模块338和歧义识别模块331以外的模块;如保留该语料,则再经过匹配模块320匹配下一个词库中的实体词,直到匹配到语料中所有的实体词并逐一通过筛选模块330中除优先级判断模块338和歧义识别模块331以外的模块;如保留该语料,则可依次通过优先级判断模块338和歧义识别模块331进行进一步筛选。在本实施例中,可以将分词筛选模块332中判断决定采用分词筛选模块332的类别的词库,在最后进行匹配和筛选。
在一实施例中,语料标注装置30还包括标注计数模块,根据实体词的类别,对经过标注的语料中匹配到的实体词进行统计。
在一实施例中,语料标注装置30还包括:停止标注模块,当标注计数模块统计的一个类别中匹配到的实体词超过数量预定值时,停止对类别的实体词进行标注。
图7示出了构造语料装置40的实施例的流程示意图,如图7所示,在一些情况下,某些实体词在语料中出现的较少,导致供nlp模型学习的素材较少,因此,本公开提出一种构造语料装置40,通过人工的构造语料,使得标注的语料更加全面,提供更完善的供nlp模型学习的素材。具体来说,构造语料装置40包括:语料收集模块410、待换实体词收集模块420、替换模块430以及再标注模块440。下面对图7中的装置进行详细说明。
语料收集模块410,用于将语料标注装置30中通过语料标注方法10筛选出的语料进行收集。
待换实体词收集模块420,用于收集用于构造语料的待换实体词。
替换模块430,用于根据实体词的类别,将语料收集模块410收集到的语料中匹配到的实体词,替换为待换实体词收集模块420收集到的相同类别的待换实体词。
再标注模块440,用于对通过替换模块430得到的语料进行标注。
在一实施例中,语料收集模块410还用于:对仅匹配到一个实体词的语料进行收集。从而使得构造的语料会更加准确,直接按照所属的类别,和实体词进行直接替换,使得替换更加容易。
在一实施例中,待换实体词收集模块420还用于:对语料标注方法10中被标注的实体词的数量进行统计,将数量低于标注数量预定值的实体词进行收集。从而使得能够针对标注量低的实体词构造语料,能够高效率的补充语料。
在一实施例中,替换模块430还包括:标志替换模块,将实体词替换为标志,标志能够表示实体词的类别;实体词替换模块,根据标志的类别,将标志替换为与标志的类别相同的待换实体词。采用该种替换方式,能够方便对一个语料进行多次替换,便于构造更多语料。
图8所示的是本发明实施例提供的一种电子设备50,电子设备包括:存储器510,配置用于存储指令;以及处理器520,配置用于调用指令执行上述可能的实施方式中任一的方法。
本发明实施例还提供一种计算机可读存储介质,计算机可读存储介质存储有计算机可执行指令,计算机可执行指令在由处理器执行时,执行上述可能的实施方式中任一的方法。
尽管在附图中以特定的顺序描述操作,但是不应将其理解为要求按照所示的特定顺序或是串行顺序来执行这些操作,或是要求执行全部所示的操作以得到期望的结果。在特定环境中,多任务和并行处理可能是有利的。
本发明的方法和装置能够利用标准编程技术来完成,利用基于规则的逻辑或者其他逻辑来实现各种方法步骤。还应当注意的是,此处以及权利要求书中使用的词语“装置”和“模块”意在包括使用一行或者多行软件代码的实现和/或硬件实现和/或用于接收输入的设备。
此处描述的任何步骤、操作或程序可以使用单独的或与其他设备组合的一个或多个硬件或软件模块来执行或实现。在一个实施方式中,软件模块使用包括包含计算机程序代码的计算机可读介质的计算机程序产品实现,其能够由计算机处理器执行用于执行任何或全部的所描述的步骤、操作或程序。
出于示例和描述的目的,已经给出了本发明实施的前述说明。前述说明并非是穷举性的也并非要将本发明限制到所公开的确切形式,根据上述教导还可能存在各种变形和修改,或者是可能从本发明的实践中得到各种变形和修改。选择和描述这些实施例是为了说明本发明的原理及其实际应用,以使得本领域的技术人员能够以适合于构思的特定用途来以各种实施方式和各种修改而利用本发明。
- 还没有人留言评论。精彩留言会获得点赞!