基于人像的视频生成系统的制作方法
本发明实施例涉及视频处理技术领域,尤其涉及基于人像的视频生成系统。
背景技术:
虚拟人像是指利用计算机生成的人像。目前基于人像的视频生成方法主要是通过计算机图形技术合成三维动画人物,用动画参数驱动人脸的面部、头部等表情动作。
然而,这种方式需要针对某个特定人像进行建模,如若更换一个人像,需要重新调整模型,不具有普适性。
技术实现要素:
本发明实施例提供一种基于人像的视频生成系统,以提高基于人像的视频生成的普适性。
本发明实施例提供了一种基于人像的视频系统,包括:第一输入单元,适于获取目标人脸静态图像;第二输入单元,适于获取人像表达控制数据;目标人像生成单元,包括训练完成的生成对抗网络模型,适于对所述第一输入单元输入的目标人脸静态图像及所述第二输入单元输入的人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成图像序列,所述图像序列中人像的动作与所述人像表达控制数据的表达特征匹配;输出单元,适于输出所述目标人像生成单元所生成的图像序列。
可选地,所述第二输入单元包括以下至少一种:第一输入子单元,适于输入情感数据;第二输入子单元,适于输入语音数据。
可选地,所述第二输入子单元包括:文本转语音模块,适于获取文本数据,并将所述文本数据转换为语音数据。
可选地,所述第一输入子单元包括以下至少一种:情感标签输入模块,适于输入情感标签作为所述情感数据;情感识别模块,适于识别所述语音数据或所述文本数据的情感特征,将识别出的情感特征序列作为所述情感数据。
可选地,所述目标人像生成单元包括:人像生成器,适于对所述目标人脸静态图像和所述人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成所述图像序列。
可选地,所述人像生成器包括:第一图像编码器,适于将所述目标人脸静态图像进行编码,提取得到图像特征集;人像情感表达特征提取器,适于将所述情感数据输入预设的人像表达特征提取模型,提取得到人像情感表达特征序列。
可选地,所述人像情感表达特征提取器包括以下至少一种:面部表情特征提取器,适于将所述情感数据输入预设的表情特征提取模型,提取得到人像面部表情特征序列;姿态特征提取器,适于将所述情感数据输入预设的姿态特征提取模型,提取得到人像姿态特征序列。
可选地,所述人像情感表达特征提取器还包括:时序变换器,适于对所述人像面部表情特征序列或人像姿态特征序列按照预设的规则进行时序变换。
可选地,所述人像情感表达特征提取器还包括:音频编码器,适于对输入的语音数据进行音频特征提取处理,得到音频特征序列。
可选地,所述人像生成器还包括:特征融合器,适于将特征提取后所得到的特征序列进行时序匹配及维度融合,所述特征融合模块包括:时序匹配器,适于将所述图像特征集与所述人像表达特征序列分别进行时序匹配;维度融合器,将所述图像特征集与各所述人像表达特征序列进行维度融合,得到联合特征向量;图像解码器,适于将所述联合特征向量进行图像解码,得到所述图像序列。
可选地,所述时序匹配器适于将所述音频特征序列与所述图像特征集进行时序匹配,使得所述图像序列中人像的口型与所述音频特征序列匹配。
可选地,所述目标人像生成单元还包括:判别器,所述判别器适于与所述人像生成器耦接并联合迭代训练,其中:所述人像生成器适于从训练数据集获取目标人脸静态图像及人像表达控制数据输入所述人像生成器,生成匹配所述人像表达控制数据的图像序列作为训练生成图像序列;所述判别器适于在训练阶段对所述人像生成器所生成的图像序列与所获取的目标人脸动态图像进行比较,且所述判别器迭代过程的每一轮先固定人像生成器的参数,使得判别器达至最优值,之后再固定判别器达至最优值时的参数,更新所述人像生成器的参数,循环迭代直至所述训练生成图像序列与所述目标人脸动态图像的差异值收敛至预设阈值时,确定所述对抗网络模型训练完成。
可选地,所述判别器包括以下至少一种:身份判别器,适于对所生成的图像序列中的人像进行身份判别;表情判别器,适于对所生成的图像序列中的表情特征进行情感判别;音频判别器,适于对所生成的图像序列中的音频特征进行音频判别;姿态判别器,适于对所生成的图像序列中的姿态特征进行姿态判别。
可选地,所述判别器适于通过预设的差异损失函数来判别所生成的图像序列与所述目标人脸动态图像的差异值,并通过所述差异损失函数中的对应的系数约束相应判别器的权重。
采用本发明实施例,采用训练完成的生成对抗网络模型对输入的目标人脸静态图像和人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成图像序列并输出,采用上述图像生成方案,无须针对某个特定人像进行专门建模,因而当更换目标人像时,无须对所述训练完成的生成对抗网络模型进行重新调整,因而上述视频生成方案具有更强的普适性,且由于无须针对某个特定人像进行专门建模,因而也可以降低视频生成成本。
进一步地,由于所述人像表达控制数据可以包括情感数据和语音数据,因而所生成的视频可以对人像的表情、姿态等情感表达动作与语音(口型)进行同步控制,使得所生成的视频中的人像更加真实生动,可以优化用户的听觉和视觉体验。
进一步地,可以直接获取语音数据,也可以将获取的文本数据转换为语音数据,从而可以满足用户的多种可能的输入需求,方便用户操作。
进一步地,通过获取用户输入的情感标签作为情感数据,可以使所生成的视频中人像的表情能够更加准确地满足用户对人像情感表达的需求,因而可以进一步提高用户体验。
进一步地,通过识别获取的语音数据或文本数据的情感特征,将识别出的情感特征序列作为所述情感数据,可以使人像的表情与语音数据所表达的情感更加一致,使得所生成的视频中的人像更加真实、自然。
进一步地,通过将所述情感数据输入预设的表情特征提取模型,提取得到人像面部表情特征序列,并对所述人像面部表情特征序列按照预设的规则进行时序变换,可以提高视频中人像表情的连贯性。
进一步地,通过将图像特征集与人像表达特征序列分别进行时序匹配,并将所述图像特征集与人像表达特征序列进行维度融合,可以使得所生成的视频中的人像的表达特征更加真实、自然。
进一步地,通过将所述音频特征序列与所述人像面部表情特征序列进行时序匹配,使得所述图像序列中人像的口型与所述人像面部表情特征序列匹配,或将所述音频特征序列与所述人像姿态特征序列进行时序匹配,使得所述图像序列中人像的口型与所述人像姿态特征序列匹配,使得视频中人像的口型与表情,口型与人像姿态更加匹配,因而可以进一步提高所生成的视频中人像的真实性。
进一步地,在所述生成对抗网络模型训练过程中,将判别器和人像生成器联合迭代训练,所述判别器迭代过程的每一轮先固定人像生成器的参数,使得判别器达至最优值,之后再固定判别器达至最优值时的参数,更新所述人像生成器的参数,循环迭代直至所述训练生成图像序列与所述目标人脸动态图像的差异值收敛至预设阈值,采用上述方式训练,可以提高所生成的视频中人像的真实性。
进一步地,在训练过程中,通过对训练生成图像序列中的人像进行身份判别、情感判别或音频判别,可以实现对所生成视频中人像真实性的多维度识别,从而可以进一步提高所生成的视频中人像的真实性。
进一步地,通过预设的差异损失函数来判断所生成的图像序列是否达到预设的真实度阈值,并通过所述差异损失函数中的系数约束相应判别类型的权重,使得可以根据用户需求强化相应的人像表达特征,从而可以增强所生成的视频中人像的个性化。
附图说明
图1示出了本发明实施例中一种基于人像的视频生成方法的流程图;
图2示出了本发明实施例中一种基于人像的视频生成系统的结构示意图;
图3示出了本发明实施例中一种人像生成器的结构示意图;
图4示出了本发明实施例中另一种人像生成器的结构示意图;
图5示出了本发明实施例中一种目标人像生成单元的结构示意图;
图6示出了本发明实施例中一种判别器的结构示意图;
图7示出了本发明实施例中另一种判别器的结构示意图。
具体实施方式
如前所述,目前基于某个特定人像进行建模生成基于人像的视频的方式的普适性不够。
针对上述问题,本发明实施例采用训练完成的生成对抗网络模型(generativeadversarialnetworks,gans)对输入的目标人脸静态图像和人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成图像序列,并在确定所述生成的图像序列达到预设的真实度阈值时,输出所生成的图像序列。采用本发明实施例的视频生成方法,无须针对某个特定人像进行专门建模,因而当更换目标人像时,无须对所述训练完成的生成对抗网络模型进行重新调整,故具有更强的普适性,且由于无须针对某个特定人像进行专门建模,因而也可以降低视频生成成本。
为使本领域技术人员更好地理解和实现本发明实施例,以下参照附图,通过具体实施进行详细介绍。
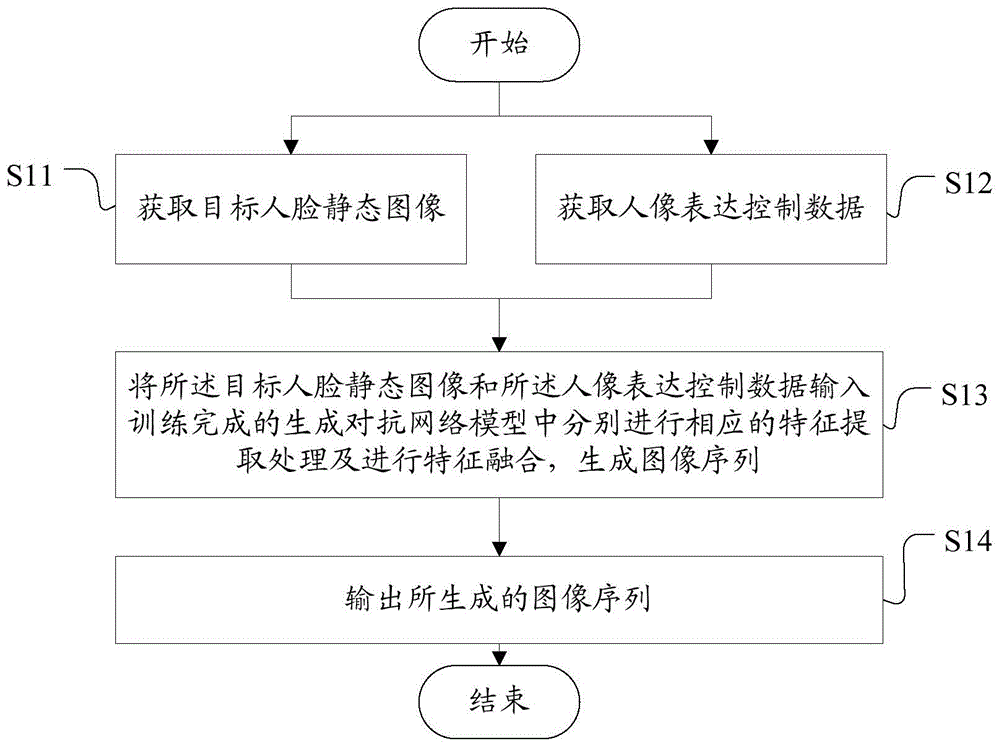
参照图1所示的基于人像的视频生成方法的流程图,在本发明实施例中,可以采用如下步骤进行视频生成,包括:
s11,获取目标人脸静态图像。
在具体实施中,目标人脸静态图像可以为一幅静态图像,也可以为多幅静态图像。
在具体实施中,可以从本地或者网上下载所述目标人脸静态图像,也可以采用摄像头或照相机等拍照设备或摄像设备直接获取所述目标人脸静态图像。
s12,获取人像表达控制数据。
在具体实施中,所述人像表达控制数据为情感数据,也可以为语音数据,或者同时包含情感数据和语音数据。
在具体实施中,对于语音数据,可以直接获取;也可以获取文本数据,并将所述文本数据转换为语音数据。
在具体实施中,可以通过一种或多种方式来获取所述情感数据。例如,可以获取用户输入的情感标签作为所述情感数据。情感标签可以为:微笑、大笑、狂笑、忧郁、悲伤、冷漠、喜悦等。具体可以在训练过程中进行设置或定义。又如,可以识别所述语音数据或所述文本数据的情感特征,将识别出的情感特征序列作为所述情感数据。或者,可以识别所述目标人脸静态图像的表情特征作为所述情感数据。
s13,将所述目标人脸静态图像和所述人像表达控制数据输入训练完成的生成对抗网络模型中分别进行相应的特征提取处理及进行特征融合,生成图像序列,所述图像序列中人像的动作姿态与所述人像表达控制数据的表达特征匹配。
为生成本发明实施例基于人像的视频,所述生成对抗网络可以包括人像生成器,即所述生成器可以对所述目标人脸静态图像和所述人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成所述图像序列。以下通过具体实施方式说明本发明实施例中的人像生成器如何生成基于人像的视频。
在具体实施中,可以对所述目标人脸静态图像进行编码,提取得到图像特征集。例如,可以采用预设的卷积神经网络对所述目标人脸静态图像进行编码,提取所述图像特征集,可以通过预设的图像编码器进行提取。
在具体实施中,所述图像序列中人像的动作姿态可以包括面部表情、口型、头部姿态等其中一种或多种。所生成的图像序列中人像的动作姿态的类型与所获取的人像表达控制数据的类型对应。
在具体实施中,对于情感数据,可以将其输入预设的人像表达特征提取模型,提取得到人像情感表达特征序列。基于人像情感表达的方式比较丰富,在本发明实施例中,可以根据需要将所述情感数据输入所选择的一种或多种人像情感表达特征提取模型进行特征提取处理。例如,可以将所述情感数据输入预设的表情特征提取模型,提取得到人像面部表情特征序列。又如,可以将所述情感数据输入预设的姿态特征提取模型,提取得到人像姿态特征序列。例如人像姿态特征可以包括:摇头、点头、歪头等。
在具体实施中,为增强人像面部表情的连贯性,可以对提取到的人像面部表情特征序列按照预设的规则进行时序变换。例如,可以对所述人像面部表情特征按照所述语音数据中句子间隔进行时序变换。又如,可以对所述人像面部表情特征按照预设的时间段进行时序变换。其中,对于按照句子间隔进行时序变换的方式,在具体实施中,不同人像面部表情之间可以按照人像面部表情特征的线性插值进行估计,也可以根据获取的人像面部表情数据集,采用相应的神经网络来提取所述人像面部表情特征的特征变换。在本发明一实施例中,采用卷积神经网络(convolutionalneuralnetwork,cnn)和循环神经网络(recurrentneuralnetwork,rnn)按照句子间隔进行时序变换。所述人像面部表情数据集可以在训练阶段获取。
在具体实施中,所述人像表达控制数据可以包括语音数据。可以将所述语音数据输入所述训练完成的生成对抗网络模型中进行音频特征提取处理,提取得到音频特征序列。在本发明一实施例中,将所述语音数据采用梅尔频率倒谱系数(mfcc)提取音频特征,输入一维卷积神经网络(cnn)进行编码,并采用预设的循环神经网络(rnn)接入时序特征,得到所述音频特征序列。
在具体实施中,可以采用如下方式进行特征融合:将所述图像特征集与所述人像表达特征序列分别进行时序匹配;将所述图像特征集与所述人像表达特征序列进行维度融合,得到联合特征向量,将所述联合特征向量进行图像解码,得到所述图像序列。
其中,在进行时序匹配过程中,可以根据输入的人像表达特征序列的特点进行相应的时序匹配操作。
对于音频特征序列,在具体实施中,可以执行以下的时序匹配操作:可以将所述音频特征序列与所述图像特征集进行时序匹配,使得所述图像序列中人像的口型与所述音频特征序列匹配。在本发明一实施例中,人像的口型可以包括唇部动作,在本发明其他实施例中,人像的口型可以包括唇部动作及说话时相关的面部肌肉动作。
对于没有语音输入的场景,对于人像面部表情特征序列,可以将所述人像面部表情特征序列与所述人像姿态特征序列进行时序匹配,使得所述图像序列中人像的面部表情与所述人像姿态匹配。
在进行维度融合过程中,可以直接将图像特征集与各人像表达特征序列进行连接,生成联合特征向量。例如,图像特征集x1,通常为二维cnn形式的输出、语音特征序列x2,通常为rnn输出序列,表情特征序列x3,通常为二维cnn序列,则可以将所述图像特征集x1、语音特征序列x2和表情特征序列x3直接连接,即可获得相应的联合特征向量。在具体实施中,可以将所得到的联合特征向量输入预设的图像解码器,得到所生成的图像序列,即为本发明实施例所生成的基于人像的视频。
s14,输出所生成的图像序列。
为使本领域技术人员更好地理解和实现本发明实施例,以下通过几个具体的应用场景对本发明上述实施例基于人像的视频生成方法进行详细介绍:
在本发明一实施例中,用户可以只输入一幅或多幅目标人脸静态图像,可以从所述目标人脸静态图像中获取用户的面部表情数据作为情感数据。之后,可以通过gans从所述一幅或多幅目标人脸静态图像中提取图像特征集,对于情感数据,可以将其输入gans预设的表情特征提取模型,提取得到人像面部表情特征序列。进而可以将所述人像面部表情特征序列与所述图像特征集进行特征融合,生成图像序列,继而可以输出所述图像序列作为本发明实施例基于人像的视频。
在本发明另一实施例中,用户可以输入所选取的目标人脸静态图像,并输入情感标签。采用训练完成的gans从所述一幅或多幅目标人脸静态图像中提取图像特征集,并从所输入的情感标签中提取人像面部表情特征序列,在具体实施中,还可以对所述人像面部表情特征序列进行时序变换以增强所生成的视频中人像表情变化的流畅度,例如,可以按照预设的时间段进行时序变换。gans之后可以对所述面部表情特征序列与所述图像特征集进行特征融合,生成所述图像序列。
在本发明另一实施例中,用户可以输入所选取的目标人脸静态图像,并输入情感标签、语音或者文本数据。对于文本数据,可以在gans中或之外设置相应的文本转语音(text-to-speech,tts)模块将输入的文本数据转换为语音数据。继而可以采用训练完成的gans模型分别相应提取图像特征集、人像面部表情特征序列、音频特征序列,继而可以将三者进行特征融合,包括进行音频与表情时序的匹配及进行维度融合,生成图像序列。
可以理解的是,以上仅为便于理解,通过一些具体场景进行示例。本发明实施例并不限于上述应用场景或具体实现方式。
在具体应用过程中,例如用户也可以不输入表情标签,所述训练完成的gans模型可以从用户输入的音频或文本数据中获取情感数据,继而生成相应的面部表情特征序列、人像姿态特征序列等。然而进行特征融合并进行真实度判别,即可输出达到预设的真实度阈值的图像序列。
为使本领域技术人员更好地理解和实现本发明实施例,以下对本发明实施例所采用的gans模型如何训练进行详细说明。
如前所述,为实现基于人像的视频生成方法的普适性,本发明实施例所采用的gans模型可以包括人像生成器。
为使生成的图像序列中的人像满足真实性需求,可以预先对所述gans模型进行训练。
在训练阶段,所述gans模型除所述人像生成器外,还可以包括判别器,所述判别器适于与所述人像生成器耦接并联合迭代训练,其中,所述人像生成器适于从训练数据集获取目标人脸静态图像及人像表达控制数据输入所述人像生成器,生成匹配所述人像表达控制数据的图像序列作为训练生成图像序列;
所述判别器适于在所述生成网络模型训练时对所述人像生成器所生成的图像序列与所获取的目标人脸动态图像进行比较,且所述判别器迭代过程的每一轮先固定人像生成器的参数,使得判别器达至最优值,之后再固定判别器达至最优值时的参数,更新所述人像生成器的参数,循环迭代直至所述训练生成图像序列与所述目标人脸动态图像的差异值收敛至预设阈值时,确定所述对抗网络模型训练完成。
在具体实施中,可以通过预测的差异损失函数来判别所述训练生成图像序列与所述目标人脸动态图像的差异值。
在具体实施中,所述判别器可以执行以下至少一种判别操作:对所生成的图像序列中的人像进行身份判别;对所生成的图像序列中的表情特征进行情感判别;对所生成的图像序列中的音频特征进行音频判别;对所生成的图像序列中的姿态特征进行情感判别。
在具体实施中,可以通过所述差异损失函数中的系数约束相应判别类型的权重。
在本发明一实施例中,在训练过程中,通过身份判别器对所生成的图像序列中的人像进行身份判别;通过表情判别器对所生成的图像序列中的表情特征进行情感判别;通过音频判别器对所生成的图像序列中的音频特征进行音频判别。以下对所采用的差异损失函数进行详细说明。首先,可以设置整体差异损失函数loss,整体差异损失函数可以定义如下:
loss=∑i=1,2,3λili+λrlr;
各差异损失函数可以定义如下:
li=ei{log[di(xi′)]}+ei{log[1-di(xi′)]},(i=1,2,3);
lr=∑allpixel|g-t|。
其中,ei{…}是对一段序列取平均,比如:
对于身份判别器,
对于语音判别器,e2为定义语音帧内的平均值;
对于表情判别器,e3为定义表情时间间隔内的平均值;
g是人像生成器得到的生成图像结果;t是目标人像的真实视频结果;
lr是g-t在重建图像的像素层面的lp-norm差异,即p范数差异,即对一个向量x=[x1,x2,…,xn]可以通过以下公式计算其p范数:
||x||p=(|x1|p+|x2|p+…+|xn|p),p=0,1,2,…
一般的loss函数的设置主要采用p=0,1,2的情况,即l0范数,l1范数和l2范数,均可以通过以上公式进行计算。
在训练过程中,可以寻找使得loss最大的判别器和使loss最小的人像生成器,即:argmingenmaxdiscrloss;其中,gen表示人像生成器,discr表示判别器,由此得到的人像生成器即训练完成,可以作为本发明实施例中生成人像口型和表情视频的人像生成器。
为使本领域技术人员更好地理解和实现本发明实施例,以下对本发明实施例所采用的基于人像的视频生成系统及所采用的gans模型进行详细介绍。
如图2所示,本发明实施例提供了一种基于人像的视频生成系统20,包括:第一输入单元21、第二输入单元22、目标人像生成单元23和输出单元24,其中:
第一输入单元21,适于获取目标人脸静态图像;
第二输入单元22,适于获取人像表达控制数据;
目标人像生成单元23,包括训练完成的生成对抗网络模型,适于对所述第一输入单元21输入的目标人脸静态图像及所述第二输入单元22输入的人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成图像序列,所述图像序列中人像的动作姿态与所述人像表达控制数据的表达特征匹配;
输出单元24,适于输出所述目标人像生成单元23所生成的图像序列。
在具体实施中,所述第一输入单元21获取的可以为一幅图像,也可以为多幅静态图像所形成的图像序列,图像可以为二维图像,也可以为三维图像。
在具体实施中,所述第二输入单元22可以包括第一输入子单元221和第二输入子单元222中的至少一种,其中:
第一输入子单元221,适于输入情感数据;
第二输入子单元222,适于输入语音数据。
在具体实施中,所述第二输入子单元222还可以包括文本转语音模块(未示出),适于获取文本数据,并将所述文本数据转换为语音数据。
在具体实施中,所述第一输入子单元221可以包括以下至少一种:
情感标签输入模块(未示出),适于输入情感标签作为所述情感数据;
情感识别模块(未示出),适于识别所述语音数据或所述文本数据或目标人像静态图片中的情感特征,将识别出的情感特征序列作为所述情感数据。
在具体实施中,可以通过所述情感标签输入模块获取用户输入的情感标签。可以通过情感识别模块从所输入的语音数据或文本数据或目标人像静态图像中识别得到情感特征序列。
本发明实施例目标人像生成单元23可以包括gans模型。在具体实施中,如图2所示,目标人像生成单元23可以包括人像生成器231,所述人像生成器231适于对所述目标人脸静态图像和所述人像表达控制数据分别进行相应的特征提取处理及进行特征融合,生成所述图像序列。
为使本领域技术人员更好地理解和实现本发明实施例,以下对本发明实施例中人像生成器的结构和工作原理进行详细说明。
参照图3所示的本发明实施例中一种人像生成器的结构示意图,在本发明实施例中,人像生成器30可以包括:第一图像编码器31和人像情感表达特征提取器32和特征融合器33,其中:
第一图像编码器31,适于将所述静态人脸图像进行编码,提取得到图像特征集;
人像情感表达特征提取器32,适于将所述情感数据输入预设的人像表达特征提取模型,提取得到人像情感表达特征序列;
特征融合器33,适于将特征提取后所得到的特征序列进行时序匹配及维度融合。
在具体实施中,所述人像情感表达特征提取器32可以包括以下至少一种:
面部表情特征提取器321,适于将所述情感数据输入预设的表情特征提取模型,提取得到人像面部表情特征序列;
姿态特征提取器322,适于将所述情感数据输入预设的姿态特征提取模型,提取得到人像姿态特征序列。
在具体实施中,所述人像情感表达特征提取器32还可以包括:时序变换器323,适于对所述人像面部表情特征序列或人像姿态特征序列按照预设的规则进行时序变换。
在具体实施中,所述面部表情特征提取器321和姿态特征提取器322所提取到的特征序列也可以分别输入到不同的时序变换器进行处理。
在具体实施中,所述人像情感表达特征提取器32还可以包括:音频编码器324,适于对输入的语音数据进行音频特征提取处理,得到音频特征序列。
在具体实施中,如图3所示,所述特征融合模块33可以包括:时序匹配器331和维度融合器332,其中:
所述时序匹配器331,适于将所述图像特征集与所述人像表达特征序列分别进行时序匹配;
维度融合器332,将所述图像特征集与各所述人像表达特征序列进行维度融合,得到联合特征向量;
图像解码器333,适于将所述联合特征向量进行图像解码,得到所述图像序列。
在具体实施中,所述时序匹配器331适于将所述音频特征序列与所述图像特征集进行时序匹配,使得所述图像序列中人像的口型与所述音频特征序列匹配。
通过将所述音频特征序列与所述人像面部表情特征序列进行时序匹配,使得所述图像序列中人像的口型与所述人像面部表情特征序列匹配,从而可以进一步提高所生成的视频中人像的真实性。
为使本领域技术人员更好地理解和实现本发明实施例,以下通过一个具体应用中所采用的目标人像生成单元中的人像生成器的结构进行详细说明。
图4示出了本发明实施例中一种人像生成器的结构示意图。在本发明一实施例中,参照图4,人像生成器40可以包括:第一图像编码器41、音频编码器42、表情特征提取器43、表情特征模型m、特征融合器44以及图像解码器45。在具体实施中,还可以包括rnn46。此外,为了增强人像表情的连贯性,还可以包括时序变换器47。
在具体实施中,可以将所述目标人脸静态图片输入所述第一图像编码器41进行编码,提取(二维)图像特征集x1,例如,所述第一图像编码器41可以采用(二维)cnn进行编码,提取所述(二维)图像特征集x1。
在具体实施中,对于语音数据,其中已经包含了时序信息和音频信息,因而可以直接进行音频编码,得到某个时间段(音频帧t2)内的音频特征序列x2。例如,音频编码器42可以采用mfcc提取得到音频特征序列x2。之后可以输入一维rnn46进行编码,利用rnn接入时序特征,生成rnn输出序列。
而对于输入的文本数据,如图4所示,则需要先通过tts模块48转换为语音数据,将转换后的语音数据作为所述音频编码器42进行后续处理。在具体实施中,tts模块48也可以设置在人像生成器外部,如图4所示。
在具体实施中,继续参照图4,用户还可以输入情感标签序列,对于输入的情感标签序列,可以由表情特征提取器43利用预设的表情特征模型m进行人像面部表情特征提取,得到人像面部表情特征序列x3。之后为增强所生成视频中人像表情的连贯性,可以采用时序变换器47对人像面部表情特征序列x3进行时序变换。
对于本发明实施例基于gans模型生成基于人像的视频。如前所述,在采用本发明目标人像生成单元23进行图像序列生成前,为提高所生成的图像序列的真实性,可以预先对目标人像生成单元23的人像生成器231进行训练。
参照图5所示的目标人像生成单元23,在具体实施中,所述目标人像生成单元23除了人像生成器231外,还可以包括判别器232,所述判别器232适于与所述人像生成器231耦接并联合迭代训练,其中:
所述人像生成器231,适于从训练数据集获取目标人脸静态图像及人像表达控制数据,生成匹配所述人像表达控制数据的图像序列作为训练生成图像序列;
所述判别器232,适于在训练阶段对所述人像生成器231所生成的图像序列与所获取的目标人脸动态图像进行比较,且所述判别器232迭代过程的每一轮先固定人像生成器231的参数,使得判别器232达至最优值,之后再固定判别器232达至最优值时的参数,更新所述人像生成器231的参数,循环迭代直至所述训练生成图像序列与所述目标人脸动态图像的差异值收敛至预设阈值时,则确定所述对抗网络模型训练完成。
在训练阶段,可以利用预设的表情识别算法自动生成情感标签,也可以手动标注情感标签,例如手动标注某句话或者某个时间段内的情感标签。训练过程所得到的情感标签列表要和基于gans的人像生成器具体应用过程中所采用的情感标签列表一致。
对于本发明实施例中预设的表情特征模型m,可以利用表情数据集预先训练提取不同表情的特征,比如可以利用基于cnn的表情识别算法在预设的人脸数据库(如cmuvasc&pie数据库)提取不同的表情的特征,所述表情特征模型m训练的情感标签列表与本发明实施例中生成视频的情感标签列表匹配。这里所采用的cnn结构可以与提取(二维)图像特征集x1的cnn结构不同。
继续参照图4,所提取得到的(二维)图像特征集x1、音频特征序列x2和人像面部表情特征序列x3通过特征融合器64进行特征融合,之后输出至图像解码器45进行处理,即可生成基于人像的图像序列。
采用上述人像生成器40,可以实现对人像表情的控制,在有语音输入的情况下,可以实现对人像表情和语音(口型)的同步控制,从而可以提高所生成的视频中人像的真实性,使得所生成的视频中的人像更加真实生动,可以优化用户的听觉和视觉体验。
在具体实施中,特征融合器44可以包括时序匹配器(未示出)和维度融合器(未示出)。其中,通过时序匹配器可以将音频特征序列与表情特征序列进行时序匹配,使得所生成的视频中的人像的表情与口型同步控制,视频中人像的面部动作更加自然。
由于所提取得到的图像特征集x1通常为二维cnn输出序列,语音特征序列x2通常为rnn输出序列、人像面部表情特征序列x3通常为二维cnn序列,因而在具体实施中,维度融合器可以将图像特征集x1、语音特征序列x2通常为rnn输出序列和人像面部表情特征序列x3三者直接连接,获得联合特征向量,之后将所述联合特征向量输入图像解码器45,即可自动生成图像序列x,形成基于人像的视频。
在具体实施中,为保证所采用的人像生成器达到预设的真实度要求,可以根据需要,选择设计相应的判别器。
在具体实施中,所述判别器可以通过预设的差异损失函数来判别所生成的图像序列与所述目标人脸动态图像的差异值。在具体实施中,还可以通过所述差异损失函数中的对应的系数约束相应判别器的权重。
在具体实施中,可以采用如下方式训练所述目标人像生成单元23:从训练数据集获取目标人脸静态图像及人像表达控制数据输入所述人像生成器231,生成匹配所述人像表达控制数据的图像序列作为训练生成数据。之后,将所述训练生成数据与所述训练数据集中的动态视频图像输入所述判别器232。为了确定训练效果,可以采用预设的差异损失函数进行判别,在确定二者的差异损失函数小于预设值时,确定所述gans训练完成。
在所采用的gans模型训练阶段,如图5所示,可以从预设的训练数据集50获取训练数据。可以从所述训练数据中获取目标人像静态图像,所述人像生成器的输入可以包括目标人脸静态图像,还可以从所述训练数据集50中获取语音数据或文本数据。在训练过程中,可以选取公开数据集如grid或tcdtimit作为数据来源,也可以根据需要将从影视剧、电视节目中所截取的视频片段、图片和相应的字幕作为数据来源。本发明实施例对所选择的训练数据集的具体类型和来源均不作限制。
图6示出了本发明实施例提供了一种判别器的结构示意图。根据需要,判别器60可以包括如下的任意一种或多种判别器:
身份判别器61,适于对所生成的图像序列中的人像进行身份判别;
表情判别器62,适于对所生成的图像序列中的表情特征进行情感判别;
音频判别器63,适于对所生成的图像序列中的音频特征进行音频判别;
姿态判别器64,适于对所生成的图像序列中的姿态特征进行姿态判别。
例如,对于没有语音输入的情形,可以仅采用身份判别器61,或者仅采用表情判别器62,或者同时采用身份判别器61和表情判别器62。对于有语音输入的情形,可以仅采用身份判别器61、表情判别器62或音频判别器其中任意一种,或者同时采用身份判别器61和音频判别器63,或者同时采用身份判别器61和表情判别器62,或者三者同时采用。
在多个判别器配合使用时,可以根据需求,设置各个判别器对应的差异损失函数的系数,从而可以根据用户需求强化相应的人像表达特征,增强所生成的视频中人像的个性化。
图7示出了本发明实施例中另一种判别器的结构示意图。在本发明一实施例中,如图7所示,在训练阶段,判别器70可以与图4所示的人像生成器40配合使用。根据需要,判别器70可以包括身份判别器71、音频判别器72和表情判别器73其中至少一种,其中:
身份判别器71,用于判断人像生成器所生成的图像序列的每一幅图像都是真人,输出第一判别结果d1。
音频判别器72,可以利用所生成的图像序列(视频)和音频特征,判断所生成的图像序列是否真实,输出第二判别结果d2。
表情判别器73,可以利用所生成的图像序列和表情特征,判断所生成的图像序列是否真实,输出第三判别结果d3。
在具体实施中,可以通过差异损失函数与相应的真实度阈值进行比较,来判断所生成的图像序列的真伪。
在本发明一实施例中,整体差异损失函数可以定义如下:
loss=∑i=1,2,3λili+λrlr;
各差异损失函数可以定义如下:
li=ei{log[di(xi′)]}+ei{log[1-di(xi′)]},(i=1,2,3);
lr=∑allpixel|g-t|。
其中,ei{…}是对一段序列取平均,比如:
对于身份判别器,
对于语音判别器,e2为定义语音帧内的平均值;
对于表情判别器,e3为定义表情时间间隔内的平均值;
g是人像生成器得到的生成图像结果;t是目标人像的真实视频结果;
lr是g-t在重建图像的像素层面的lp-norm差异,即p范数差异,即对一个向量x=[x1,x2,…,xn]可以通过以下公式计算其p范数(请补充):
||x||p=(|x1|p+|x2|p+…+|xn|p),p=0,1,2,…
一般的loss函数的设计主要采用p=0,1,2的情况,即l0范数,l1范数和l2范数,均可以通过以上公式进行计算。
在训练过程中,可以寻找使得loss最大的判别器和使loss最小的人像生成器,即:argmingenmaxdiscrloss;其中,gen表示人像生成器,discr表示判别器,由此得到的人像生成器即训练完成,可以作为本发明实施例中生成人像口型和表情视频的人像生成器。
上述实施例中示出了各判别器分开情况下总体差异损失函数的计算过程。在具体实施中,上述音频判别器72和情感判别器73也可以合并为一个,仅采用一个差异损失函数进行判别。
在具体实施中,继续参照图7,可以先对生成的图像序列进行预处理,提取出相应的特征序列后,再将提取出的特征序列及输入所述目标人像模型的输入数据分别输入对应的判别器进行比较判断,输出判别结果。以下结合参照图6和图7进行详细说明。
对于身份判别,可以将人像生成器40经图像解码器45生成的图像序列与输入的目标人像静态图片分别输入第二图像编码器74进行处理后,得到相应的图像特征集x1和x1’,将二者分别输入身份判别器71,即可得到所述第一判别结果d1。
对于音频判别,可以将人像生成器40经图像解码器45生成的图像序列输入第三图像编码器75进行处理,得到音频特征序列x2’,之后输入rnn77进行编码,与从训练数据集获取的音频特征序列x2输入rnn77进行处理后的音频特征序列分别输入音频判别器72进行比较,得到第二判别结果d2。
对于表情判别,可以将人像生成器40经图像解码器45生成的图像序列输入第四图像编码器76,提取得到表情特征序列x3’,将其与人像生成器40中提取得到的表情特征序列x3分别输入时序变换器78进行时序变换,之后再输入表情判别器73,得到第三判别结果d3。
对于上述得到的第一判别结果d1、第二判别结果d2和第三判别结果d3可以采用上述的整体差异损失函数进行计算后,得到统一的判别结果d,当统一的判别结果d的判别结果达到预设的真实度阈值时,即可将生成的图像序列x输出。
在具体实施中,上述实施例中判别器70所采用的图像编码器、rnn、时序变换器等与所接入的人像生成器40中相应的图像编码器、rnn、时序变换器等可以为同一个或者结构及参数均相同。
为便于上述本发明实施例基于人像的视频的生成方法的实现,本发明实施例还提供了一种视频生成设备,所述视频生成设备可以包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时可以执行上述任一实施例所述基于人像的视频生成方法的步骤,具体实施可以参照上述实施例的介绍,此处不再赘述。
为便于上述本发明实施例基于人像的视频的生成方法的实现,本发明实施例还提供了一种计算机可读存储介质,其上存储有计算机指令,所述计算机指令运行时可以执行上述任一实施例所述基于人像的视频生成方法的步骤。具体实施可以参照上述实施例的介绍,此处不再赘述。所述计算机存储介质可以包括:rom、ram、磁盘或光盘等。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!