服务于监察机关的数据查询系统的制作方法
本发明涉及监察机关数据查询技术领域,具体涉及一种服务于监察机关的数据查询系统。
背景技术:
“互联网+”时代下的信息每一秒都在发生变化,在办理案件过程中,要想在审讯中尽快突破犯罪嫌疑人,必须事先对他进行多方面的了解,更多地与“互联网信息”打交道将成为审讯工作的新着眼点,目前缺少业务相关的使用软件而且调查涉及业务繁琐,需要强大的搜索查证功能。
技术实现要素:
为解决上述技术问题,本发明提出了一种服务于监察机关的数据查询系统,以达到为监察机关提供有效的数据支持,智能分析数据管理,提高搜索查证的效率,提高办案效率的目的。
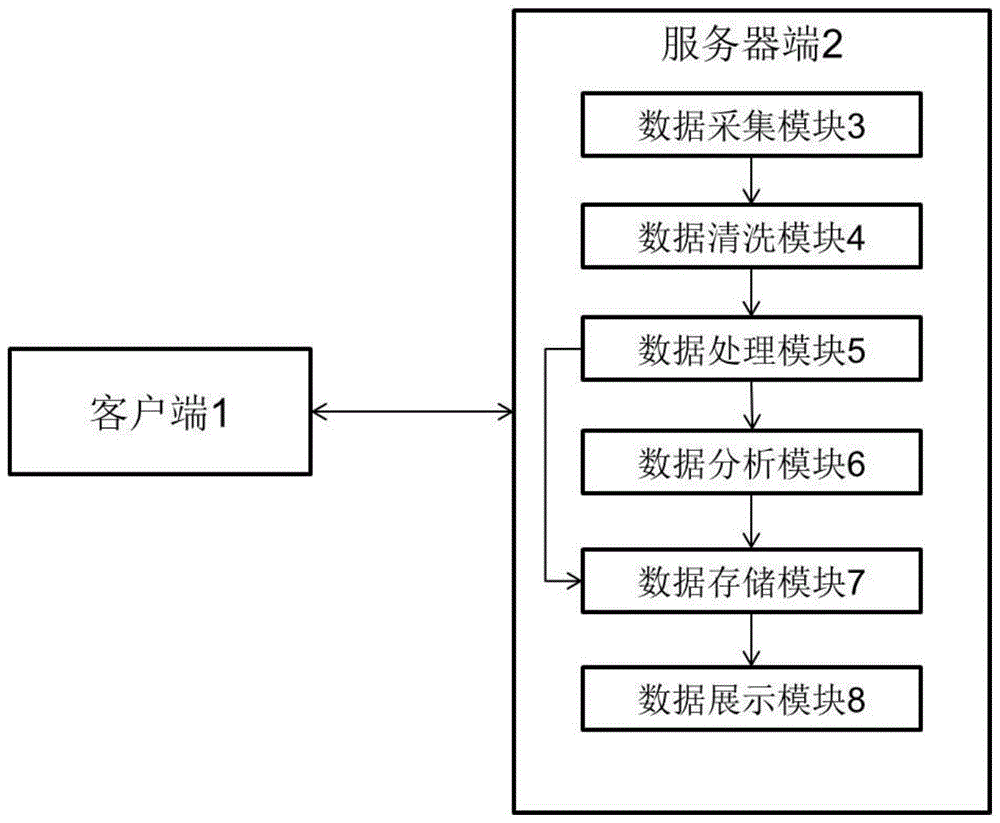
为达到上述目的,本发明的技术方案如下:一种服务于监察机关的数据查询系统,所述系统包括:客户端和服务器端,所述客户端与服务器端之间通过网络连接;
所述客户端,用于为调查人员提供数据查询;
所述服务器端包括:数据采集模块、数据清洗模块、数据处理模块、数据分析模块、数据存储模块和数据展示模块;
所述数据采集模块,用于从源数据网站爬取监察相关数据;
所述数据清洗模块,用于对数据采集模块爬取的数据进行筛除和甄别;
所述数据处理模块,用于对数据清洗模块筛除和甄别后的数据进行分类整理;
所述数据分析模块,用于对数据处理模块整理后的数据进行关联分析;
所述数据存储模块,用于存储数据分析模块分类整理后的数据和数据关联分析的结果;
所述数据展示模块,用于在调查人员通过客户端查询时将相应的数据和数据关联分析结果推送至客户端。
进一步地,所述客户端包括:关键词拆分模块和语义识别模块,所述关键词拆分模块,用于拆分调查人员输入的关键词;所述语义识别模块,用于识别关键词语义并根据相应的分词规则拆分调查人员输入的关键词。
进一步地,所述源数据网站包括:带有搜索引擎的浏览器、政务信息公开网站、政府信息公开网站和企业信息公开网站。
进一步地,所述监察相关数据包括:舆情数据、人事数据、招投标数据、机构数据和企业数据。
进一步地,所述数据清洗模块对爬取的数据进行筛除包括:筛除重复数据、无用数据和无价值数据;所述数据清洗模块对爬取的数据进行甄别包括:甄别数据的类别、行业、利用价值和信息热度。
进一步地,所述数据处理模块对数据进行分类整理包括:对数据进行格式化、序列化、分类和拆分梳理。
进一步地,所述数据分析模块对数据进行关联分析是对数据进行语义分析和大数据分析后建立数据与数据之间的关联。
进一步地,所述源数据网站还包括:调查智库和调查指南,所述调查智库,用于提供法律信息、实时要闻、文书和案列;所述调查指南,用于提供机构位置信息。
本发明具有如下优点:
(1).本发明通过爬虫技术定向、深层爬取浏览器和公开网站的数据并对数据进行清洗分类,有效的为监察机关提供数据支持,提高调查人员搜索查证的效率。
(2).本发明通过对数据进行分析并建立数据与数据之间的关联,便于调查人员理清数据关系,提高办案效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1为本发明实施例公开的服务于监察机关的数据查询系统功能模块示意图;图中数字和字母所表示的相应部件名称:
1、客户端;2、服务器端;3、证据导入模块;4、证据整理模块;5、信息展示模块;6、案件数据展示模块;7、证据展示模块;8、证据操作模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明提供了一种服务于监察机关的数据查询系统,其工作原理是通过爬虫技术定向、深层爬取浏览器和公开网站的数据并对数据进行清洗分类,通过对数据进行分析并建立数据与数据之间的关联,以达到为监察机关提供有效的数据支持,智能分析数据管理,提高搜索查证的效率,提高办案效率的目的。
下面结合实施例和具体实施方式对本发明作进一步详细的说明。
如图1所示,一种服务于监察机关的数据查询系统,所述系统包括:客户端1和服务器端2,所述客户端1与服务器端2之间通过网络连接;
所述客户端1,用于为调查人员提供数据查询;
所述服务器端2包括:数据采集模块、数据清洗模块、数据处理模块、数据分析模块、数据存储模块和数据展示模块;
所述数据采集模块,用于从源数据网站爬取监察相关数据;
所述数据清洗模块,用于对数据采集模块爬取的数据进行筛除和甄别;
所述数据处理模块,用于对数据清洗模块筛除和甄别后的数据进行分类整理;
所述数据分析模块,用于对数据处理模块整理后的数据进行关联分析;
所述数据存储模块,用于存储数据分析模块分类整理后的数据和数据关联分析的结果;
所述数据展示模块,用于在调查人员通过客户端1查询时将相应的数据和数据关联分析结果推送至客户端1。
其中,从源数据网站爬取监察相关数据采用seleniumchromedrive,seleniumphantomjs爬取数据,web的自动测试工具和基于webkit的无界面的浏览器的有机结合,可持续、可广泛、可精确地对相关地数据来源进行大规模的数据采集。
其中,所述客户端1包括:关键词拆分模块和语义识别模块,所述关键词拆分模块,用于拆分调查人员输入的关键词;所述语义识别模块,用于识别关键词语义并根据相应的分词规则拆分调查人员输入的关键词。
其中,关键词拆分采用盘古分词,语意识别采用nlp汉字分词技术。
其中,所述源数据网站包括:带有搜索引擎的浏览器、政务信息公开网站、政府信息公开网站和企业信息公开网站。
其中,带有搜索引擎的浏览器包括:百度、搜狗、360、必应和谷歌等。
其中,所述监察相关数据包括:舆情数据、人事数据、招投标数据、机构数据和企业数据。
其中,所述数据清洗模块对爬取的数据进行筛除包括:筛除重复数据、无用数据和无价值数据;所述数据清洗模块对爬取的数据进行甄别包括:甄别数据的类别、行业、利用价值和信息热度。
其中,所述数据处理模块对数据进行分类整理包括:对数据进行格式化、序列化、分类和拆分梳理。
其中,所述数据分析模块对数据进行关联分析是对数据进行语义分析和大数据分析后建立数据与数据之间的关联。
其中,所述源数据网站还包括:调查智库和调查指南,所述调查智库,用于提供法律信息、实时要闻、文书和案列;所述调查指南,用于提供机构位置信息,法律信息、实时要闻、文书和案列有助于调查人员进行审讯,机构位置信息有利于调查人员取证。
调查人员在客户端1输入想要搜索的关键字,客户端1对关键字进行拆分匹配,将拆分匹配后的关键字发送至服务器端2,服务器端2向客户端1推送数据和数据关联分析结果供调查人员查看。
其中,输入的关键字包括:人物姓名、机构名称、手机号、银行卡号等。
查人事:对人物履历结构化分析,根据任职年份进行结构化。查询人物的履历中显示相关人员,通过匹配某个时间段某个单位有哪些领导人同时任职,疑似为同事关系,匹配某个时间段某个院校同时上学,疑似为同学关系。
查法规:输入关键词后,模糊匹配法律法规的标题和正文,搜索到相关的法律法规,同时能够标记出法律法规的失效性。
招投标:既满足最新招投标信息的检索与内容查看,也满足能够通过关键字(姓名或手机号)检索到某人或某手机号所参与的本地区相关的招投标信息,并显示招投标信息的全部内容,以便调查人员更好的执行法律监督职能。
舆情数据:可以选择自己关注的舆情类别,舆情类别在数据字典维护,同语义模块的舆情类别。舆情推送的时候结合舆情类别以及设定的关键词进行自动推送。
以上所述的仅是本发明所公开的一种服务于监察机关的数据查询系统的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!