一种大数据聚合查询方法与流程
本申请涉及数据查询技术领域,尤其涉及一种大数据聚合查询方法。
背景技术:
目前,随着计算机技术和网络技术创新进步,特别是虚拟化技术的进步,还有新概念、新方案的创新和发展,尤其是docker技术的快速发展,为在线教育云平台的推出奠定了基础。
在现有技术中,教育云平台一般采用微服务架构。微服务架构解决了传统的分层架构中的一些问题,它的核心特点是高可伸缩性、易于开发、测试和部署独立的服务组件,这些服务组件解耦的、分布式的、相互独立的。
但是,在教育云平台上采用微服务架构时,由于源数据分布在各个数据库中,因此在对源数据进行查询时,难以解决跨服务、跨数据库的关联查询问题,查询效率较低。
技术实现要素:
有鉴于此,本发明提供了一种大数据聚合查询方法,从而可以解决微服务架构中跨服务、跨数据库的关联查询问题,提高教育云平台上的软件的查询效率。
本发明的技术方案具体是这样实现的:
一种大数据聚合查询方法,该方法包括如下步骤:
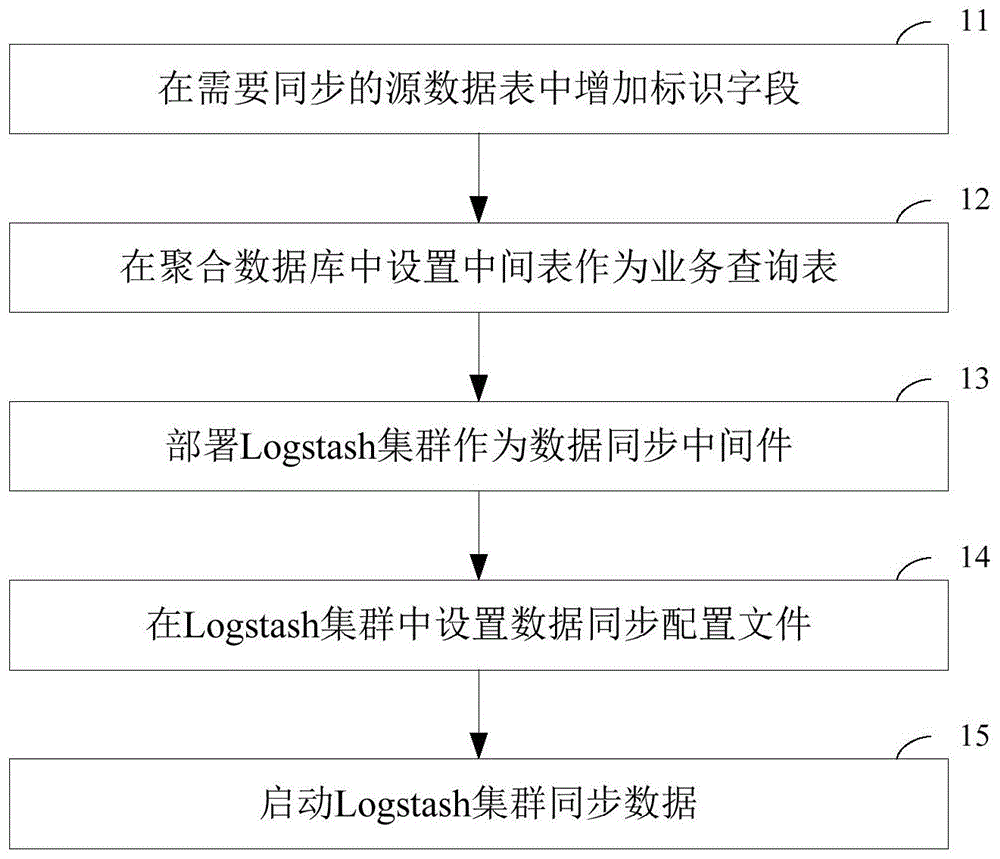
在需要同步的源数据表中增加标识字段;
在聚合数据库中设置中间表作为业务查询表;
部署logstash集群作为数据同步中间件;
在logstash集群中设置数据同步配置文件;
启动logstash集群同步数据。
较佳的,所述源数据表为基础数据库中的用户表或业务数据库中的业务表。
较佳的,所述标识字段为时间戳。
较佳的,所述启动logstash集群同步数据包括:
当源数据表中的数据发生变更时,更改源数据表中的标识字段的取值;
logstash集群按照预设时间间隔轮询相应的源数据表;
当logstash集群检测到源数据表中的标识字段的取值发生变化时,从源数据表中读取变更后的数据并进行处理;
logstash集群将处理后的数据输出至聚合数据库中的中间表。
较佳的,所述logstash集群包括多个logstash。
较佳的,当logstash集群包括第一logstash、第二logstash和第三logstash时:
将第一logstash、第二logstash和第三logstash注册到zookeeper中;
将第一logstash和第三logstash作为主logstash,将第二logstash作为从logstash,将各个主logstash的同步状态保存到zookeeper中;
当任意一个主logstash的服务出现问题时,由zookeeper选举产生新的主logstash;
新的主logstash从zookeeper获取数据同步状态,继续执行任务。
较佳的,所述基础数据库中的用户表中的数据包括:用户编号、姓名和性别;
所述业务数据库中的业务表中的数据包括:用户编号和业务数据。
较佳的,所述更改源数据表中的标识字段的取值为:
将时间戳的取值更改为当前数据发生变更的时间。
如上可见,在本发明中的大数据聚合查询方法中,由于在源数据表中增加了标识字段,在聚合数据库中设置中间表作为业务查询表,并将logstash集群作为数据同步中间件,因此引入了数据更新的触发机制,并在中间表中同步冗余了业务数据,使得业务查询只需进行单表聚合查询,而不必考虑具体的源数据分布在哪个数据库,从而解决了微服务架构中跨服务、跨数据库的关联查询问题。
另外,由于使用中间表可以快速地进行查询、分页及排序,因此还解决了微服务架构中无法进行模糊查询、分页、排序的问题,从而大大提高了教育云平台上的软件的查询效率。
另外,在本发明的技术方案中,由于部署了logstash集群作为数据同步中间件,并在logstash集群中设置了数据同步配置文件,因此可以通过同步机制在数据同步时就进行计算、统计、分析,并将相应的结果保存在订制好的数据表中,从而解决了现有技术中的其它方案中无法处理查询返回大量数据的问题。
另外,在本发明的技术方案中,还可以根据实际的业务需求调整中间表的结构,冗余不同数据,以满足业务需求,从而解决了微服务架构中的业务的可扩展性的问题。
此外,由于还可以进一步在logstash集群中设置多个logstash,从而还可以有效地避免在数据同步过程中由于logstash集群出现单点故障而导致无法进行数据同步的问题。
附图说明
图1为本发明实施例中的大数据聚合查询方法的流程图。
图2为本发明实施例中的大数据聚合查询方法的部署示意图。
具体实施方式
为使本发明的技术方案及优点更加清楚明白,以下结合附图及具体实施例,对本发明作进一步详细的说明。
图1为本发明实施例中的大数据聚合查询方法的流程图,图2为本发明实施例中的大数据聚合查询方法的部署示意图。如图1和图2所示,本发明实施例中的大数据聚合查询法包括如下所述步骤:
步骤11,在需要同步的源数据表中增加标识字段。
在本步骤中,可以在需要同步的各个源数据表中都增加一个标识字段,作为校验数据是否变更的标识。
例如,较佳的,在本发明的一个具体实施例中,所述源数据表可以是基础数据库中的用户表,也可以是业务数据库中的业务表。
另外,较佳的,在本发明的一个具体实施例中,所述标识字段可以是时间戳,也可以是其它的可以作为校验数据是否变更的标识的标识字段。
步骤12,在聚合数据库中设置中间表作为业务查询表。
在本步骤中,可以预先在聚合数据库中设置一个中间表,并将该中间表作为业务查询表。
例如,如图2所示,可以在聚合数据库中设置一个中间表,该中间表可以存储各种数据信息(例如,用户编号、姓名、性别和业务数据等)。
步骤13,部署logstash集群作为数据同步中间件。
在本步骤中,可以预先设置一个logstash集群,并将该logstash集群作为数据同步中间件。其中,logstash是一种开源数据搜集引擎。
另外,在本发明的技术方案中,上述步骤12和步骤13可以同时执行,也可以先后执行。例如,可以先执行步骤12,也可以先执行步骤13,也可以同时执行步骤12和步骤13。
步骤14,在logstash集群中设置数据同步配置文件。
步骤15,启动logstash集群同步数据。
当通过上述的步骤11~14完成所有的设置之后,在本步骤中,即可启动logstash集群同步数据。
在本发明的技术方案中,可以通过多种方式来实现上述的步骤15。以下将以其中的一种实现方式为例对本发明的技术方案进行详细的介绍。
例如,较佳的,在本发明的一个具体实施例中,所述步骤15可以包括如下的步骤:
步骤151,当源数据表中的数据发生变更时,更改源数据表中的标识字段的取值。
例如,当基础数据库中的用户表中的数据(例如,用户编号、姓名和性别等)发生变更时,如果此时的标识字段是时间戳,则更改用户表中的时间戳的取值,将时间戳的取值更改为当前数据发生变更的时间。
再例如,当业务数据库中的业务表中的数据(例如,用户编号和业务数据等)发生变更时,如果此时的标识字段是时间戳,则更改业务表中的时间戳的取值,将时间戳的取值更改为当前数据发生变更的时间。
步骤152,logstash集群按照预设时间间隔轮询相应的源数据表。
步骤153,当logstash集群检测到源数据表中的标识字段的取值发生变化时,从源数据表中读取变更后的数据并进行处理。
步骤154,logstash集群将处理后的数据输出至聚合数据库中的中间表。
通过上述的步骤151~154,即可在源数据表中的数据发生变更时,及时地将变更后的数据输出至聚合数据库中的中间表中。因此,业务只需通过对聚合数据库中的中间表的查询操作即可执行所需的操作,而不必考虑具体的源数据分布在哪个数据库。
另外,较佳的,在本发明的一个具体实施例中,所述logstash集群可以包括多个logstash。
例如,如图2所示,在本发明的一个较佳的具体实施例中,所述logstash集群包括三个logstash:第一logstash、第二logstash和第三logstash。
通过在上述logstash集群中设置多个logstash,可以有效地避免在数据同步过程中由于logstash集群出现单点故障而导致无法进行数据同步的问题。
例如,较佳的,在本发明的一个具体实施例中,当logstash集群包括三个logstash时,所述步骤13可以包括如下的步骤:
步骤131,将第一logstash、第二logstash和第三logstash注册到zookeeper(一种分布式的,开放源码的分布式应用程序协调服务)中。
步骤132,将第一logstash和第三logstash作为主logstash(logstashmaster),将第二logstash作为从logstash(logstashslave),将各个主logstash的同步状态保存到zookeeper中。
步骤133,当任意一个主logstash的服务出现问题时,由zookeeper选举产生新的主logstash。
步骤134,新的主logstash从zookeeper获取数据同步状态,继续执行任务。
同理,如果logstash集群包括其它数量(例如,2个、4个等)logstash时,也可以执行与上述步骤131~134相类似的操作,以避免logstash集群出现单点故障而导致无法进行数据同步的问题,具体的操作方式在此不再赘述。
通过上述的步骤11~15,即可实现一种大数据聚合查询方法。
综上所述,在本发明的技术方案中,由于在源数据表中增加了标识字段,在聚合数据库中设置中间表作为业务查询表,并将logstash集群作为数据同步中间件,因此引入了数据更新的触发机制,并在中间表中同步冗余了业务数据,使得业务查询只需进行单表聚合查询,而不必考虑具体的源数据分布在哪个数据库,从而解决了微服务架构中跨服务、跨数据库的关联查询问题。
另外,由于使用中间表可以快速地进行查询、分页及排序,因此还解决了微服务架构中无法进行模糊查询、分页、排序的问题,从而大大提高了教育云平台上的软件的查询效率。
另外,在本发明的技术方案中,由于部署了logstash集群作为数据同步中间件,并在logstash集群中设置了数据同步配置文件,因此可以通过同步机制在数据同步时就进行计算、统计、分析,并将相应的结果保存在订制好的数据表中,从而解决了现有技术中的其它方案中无法处理查询返回大量数据的问题。
另外,在本发明的技术方案中,还可以根据实际的业务需求调整中间表的结构,冗余不同数据,以满足业务需求,从而解决了微服务架构中的业务的可扩展性的问题。
此外,由于还可以进一步在logstash集群中设置多个logstash,从而还可以有效地避免在数据同步过程中由于logstash集群出现单点故障而导致无法进行数据同步的问题。
因此,本发明中提供了一种在教育云平台上使用数据库聚合的查询方案,该查询方案应用于教育云平台上,可以更快速地创新出新的应用场景,也可以更快速的满足教育云平台上创造新业务的需求。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!