问答机器人训练方法、系统及问答机器人与流程
本发明涉及电路领域,尤其涉及一种问答机器人训练方法、系统及问答机器人。
背景技术:
电商平台中,往往会设置问答机器人,用于解决用户提出的常见问题,在现有的电商平台中,现有客服机器人基本为问答机器人,常见的实现方式如下:
1.基于关键词的精确匹配或者模糊匹配;这种方式的机器人非常简单,客户问的问题只能是单个的词汇,而不是复杂的句式,常用语微信公众号平台的一些关键词回复,且经常会出现由于匹配不到相关关键词而导致无法回答的情况。
2.对问题和知识库进行分词,对分词结果进行匹配;这种方式的机器人会增强匹配到的题库知识的概率,但是经常会出现“答非所问”的问题。
3.利用近期深度学习模型构造监督模型,利用生成模型以及分类模型,但是模型往往无法有效地结合。无法对多模型的样本做针对性分类样本训练。
技术实现要素:
本发明的目的是针对上述现有技术存在的缺陷,提供一种问答机器人训练方法、系统及问答机器人,以解决现有技术中的问答机器人答题匹配度不高、不够智能的技术问题。
本发明实施例中,提供了一种问答机器人训练方法,其包括:对由多个训练样本组成的语义相似度训练数据集进行训练,根据训练样本中的两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失来更新所述训练样本的样本权重,其中,所述相似度训练数据集由多个训练样本组成,每个训练样本包括了两个不同的训练语句以及对两个训练语句设置的相似度标签和样本权重。
本发明实施例中,所述的问答机器人训练方法,具体包括:
对所述语义相似度训练数据集进行训练,得到词向量矩阵和字典向量矩阵;
根据所述词向量矩阵和字典向量矩阵得到每个训练样本中的两个训练语句的综合词向量;
采用设定的训练模型分别对每个训练样本中的两个训练语句的综合词向量进行训练,分别得到两个训练语句的语义向量;
根据所述两个训练语句的语义向量计算所述两个训练语句的相似度;
计算所述两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失,根据所述交叉熵损失得出所述两个训练语句所在的训练样本的样本权重并更新所述样本权重。
本发明实施例中,对由多个训练样本组成的语义相似度训练数据集进行训练得到词向量矩阵和字典向量矩阵的具体过程包括:
输入语义相似度训练数据集并设置训练样本初始化权重;
在所述语义相似度训练数据集中随机选择设定数量的训练样本进行训练,生成由每一个训练语句分解得到的词组成的词向量矩阵;
将所述语义相似度训练数据集中选择的训练样本中的每一个训练语句转化为字符数据,形成与所述字符数据对应的字典向量矩阵。
本发明实施例中,选择训练样本进行训练时,记录被选择的训练样本的样本id。
本发明实施例中,根据所述词向量矩阵和字典向量矩阵得到每个训练样本中的两个训练语句的综合词向量的具体过程包括:
根据所述词向量矩阵,将训练样本中的两个训练语句分解为两个原始词向量;
将所述两个原始词向量和所述字典向量矩阵进行综合,得到训练样本中的两个训练语句的综合词向量。
本发明实施例中,对所述两个原始词向量和所述字典向量矩阵采用加法操作替代、乘积操作替代或者向量连接替代来得到训练样本中的两个训练语句的综合词向量。
本发明实施例中,采用多个cnn模型根据两个训练语句的综合词向量得到两个训练语句的语义向量。
本发明实施例中,计算所述两个训练语句的相似度的计算公式如下:
本发明实施例中,更新的样本权重的计算公式如下:
本发明实施例中,还提供了一种问答机器人训练系统,其采用上述的问答机器人训练方法对问答机器人进行训练。
本发明实施例中,还提供了一种问答机器人,其上述的问答机器人训练系统训练得到。
与现有技术相比较,本发明的问答机器人训练方法和系统,对由多个训练样本组成的语义相似度训练数据集进行训练,根据训练样本中的两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失来更新所述训练样本的样本权重,基于知识构建多模型融合的方法对训练样本进行训练,在训练的过程对样本权重进行更新,解决了训练模型对样本偏重的缺陷,提高了训练后的问答机器人的答题匹配度。
附图说明
图1是本发明实施例的问答机器人训练方法的流程图。
图2是本发明实施例的问答机器人训练方法中的信号处理过程的示意图。
图3是图1中的步骤s1的具体流程图。
图4是图1中的步骤s2的具体流程图。
具体实施方式
本发明中,提供了一种问答机器人训练方法,其包括:对由多个训练样本组成的语义相似度训练数据集进行训练,根据训练样本中的两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失来更新所述训练样本的样本权重。下面结合具体实施例进行说明。
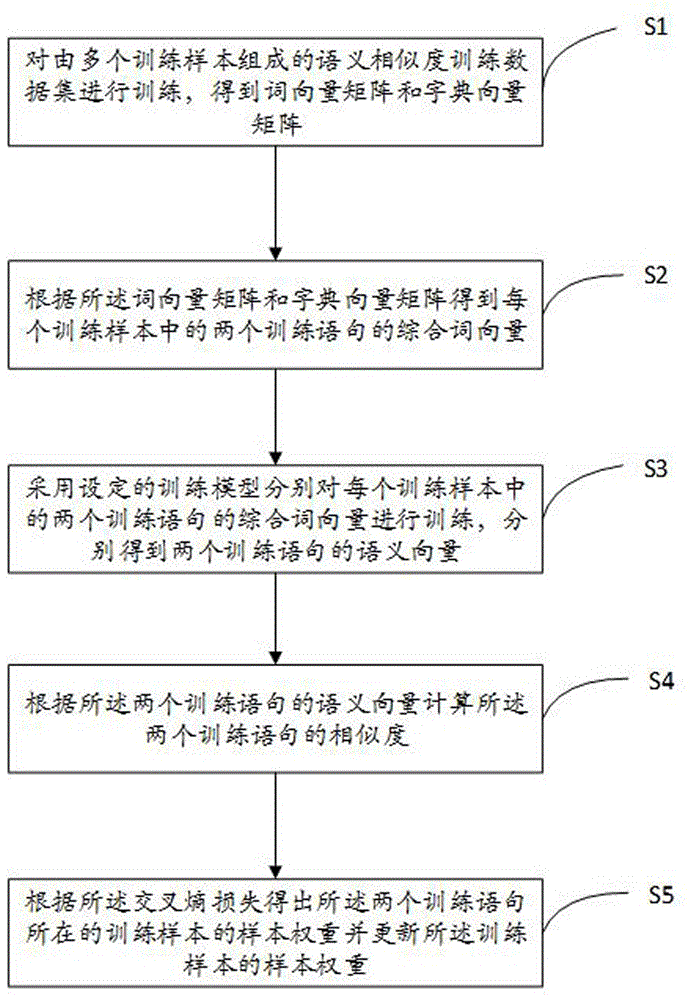
如图1和图2所示,本发明实施例中,所述问答机器人训练方法,具体包括步骤s1-s5。下面分别进行说明。
步骤s1:对由多个训练样本组成的语义相似度训练数据集进行训练,得到词向量矩阵和字典向量矩阵,其中,所述相似度训练数据集由多个训练样本组成,每个训练样本包括了两个不同的训练语句以及对两个训练语句设置的相似度标签和样本权重。
如图3所示,步骤s1包括:
步骤s11:输入语义相似度训练数据集并设置训练样本初始化权重;
步骤s12:在所述语义相似度训练数据集中随机选择设定数量的训练样本进行训练,生成由每一个训练语句分解得到的词组成的词向量矩阵;
步骤s13:将所述语义相似度训练数据集中选择的训练样本中的每一个训练语句转化为字符数据,形成与所述字符数据对应的字典向量矩阵。
需要说明的是,步骤s11中,所述相似度训练数据集中,每个训练样本包括两个训练语句[(sentence1,sentence2)和人工设置的相似度标签lable,对于初始输入的相似度训练数据集来说,假设训练样本的数量为n,则设置每一个样本权重为1/n。
步骤s12中,选择训练样本进行训练时,记录被选择的训练样本的样本id,所述样本id为每一条数据的唯一标识,也为每一个样本权重的唯一标识。训练得到的词向量矩阵可以标识如下:
train_data1=[[emj,...,emk],[eml,...,emh]],label=[1,0],
其中,eml表示词向量,label表示设置的相似度标签。
步骤s13中,字典向量是把所有的训练数据集的单词去重复,得到最后的单词集合,例如,对于一个训练语句,[‘你吃饭了吗’,‘什么时候吃饭’],转化为字符数据:[‘你’,’吃’,’饭’,’了’,’吗’;‘什’,’么’,’时’,’候’,’吃’,’饭’],形成字符,然后随机初始化所有训练数据集字符形成字符对应向量字典矩阵,表示成char2vec={'char1':m1,...,chark:mk},其中chari表示实际字符,mi表示字向量。进一步
地,字典向量矩阵可以采用下式表示:
char_data1=[[md,...,mh],[me,...,mj]]
步骤s2:根据所述词向量矩阵和字典向量矩阵得到每个训练样本中的两个训练语句的综合词向量。
如图4所示,步骤s2包括:
步骤s21:根据所述词向量矩阵,将训练样本中的两个训练语句分解为两个原始词向量;
步骤s22:将所述两个原始词向量和所述字典向量矩阵进行综合,得到训练样本中的两个训练语句的综合词向量。
需要说明的是,步骤s22中,对所述两个原始词向量和所述字典向量矩阵采用加法操作替代、乘积操作替代或者向量连接替代来得到训练样本中的两个训练语句的综合词向量。
步骤s3:采用设定的训练模型分别对每个训练样本中的两个训练语句的综合词向量进行训练,分别得到两个训练语句的语义向量。
本发明实施例中,步骤s3中,采用多个cnn模型根据两个训练语句的综合词向量得到两个训练语句的语义向量。
步骤s4:根据所述两个训练语句的语义向量计算所述两个训练语句的相似度。计算所述两个训练语句的相似度的计算公式如下:
步骤s5:计算训练样本中的两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失,根据所述交叉熵损失得出所述两个训练语句所在的训练样本的样本权重并更新所述训练样本的样本权重。更新之后的样本权重的计算公式如下:
进一步地,本发明实施例中,还提供了一种问答机器人训练系统,其采用上述的问答机器人训练方法对问答机器人进行训练。
进一步地,本发明实施例中,还提供了一种问答机器人,其上述的问答机器人训练系统训练得到。
综上所述,本发明的问答机器人训练方法和系统,对由多个训练样本组成的语义相似度训练数据集进行训练,根据训练样本中的两个训练语句的相似度与所述两个训练语句的相似度标签的交叉熵损失来更新所述训练样本的样本权重,基于知识构建多模型融合的方法对训练样本进行训练,在训练的过程对样本权重进行更新,解决了训练模型对样本偏重的缺陷,提高了训练后的问答机器人的答题匹配度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!