一种基于YOLO算法的AI装维巡检方法及系统与流程
本发明涉及人工智能技术领域,具体涉及一种基于yolo算法的ai装维巡检方法及系统。
背景技术:
随着运营商宽固业务快速发展,装维施工的巡检支撑的工作量显著增加,传统巡检工作场景包括设备机房、户外odn箱体等。由于巡检人员有限,只能通过定时派发巡检单的方式针对极少部分的设备进行抽检。而巡检的方式则是现场人员通过人工检查然后拍照上传交由后端人员,后端人员按照一定的施工标准,对拍摄的现场设备照片进行人工审核。其中工作量最大的是对运营商通信设备odn光交箱中的端口使用情况进行人工查看,进而与系统资源数据进行比对,校验装维施工是否准确。
采用这种方式存在巡检覆盖率低、巡检周期长、消耗大量人力成本、准确率低等诸多的问题。首先,一次巡检会包括10张左右的照片,而且每一张都需要人工去根据施工标准审核。其次,对于端口资源使用审核来说,一张照片往往会包含上百个端口,都需要和资源系统的端口信息一一比对,人工审核准确率低,实际施工的资源端口和资源系统端口往往存在30%左右的误差。
本发明针对上述的缺点和问题,设计了基于yolo算法的ai装维质检方法。图像识别算法是以深度学习范畴下的卷积神经网络为基础,针对目前的装维巡检场景下的照片进行模型优化,能够实现对巡检的照片进行自动审核,智能化的判断该照片是否符合施工标准。
技术实现要素:
针对上述现有技术存在的问题,本发明提供了一种基于yolo算法的ai装维巡检方法,其特征在于,包括如下步骤:
(1)采集现场人员拍摄的质检场景图像集合,通过卷积神经网络模型训练,且根据卷积神经网络模型对采集的新上传图片分类预测,结束当前质检;
(2)上传质检图片,针对质检图像预处理后,通过改进的yolo算法进行图像的端口特征识别,且输出结果;
(3)构建图像端口矩阵,将所述端口识别输出结果通过端口矩阵输出表示。
作为上述方案的进一步优化,针对上传的质检场景,根据现场施工和巡检标准,将图片根据合规以及每一种不合规的情形进行分类。
作为上述方案的进一步优化,所述改进的yolo算法即采用不同大小比例的窗口块,通过预设定窗口块的滑动距离,将所述窗口块遍历整张图片,根据遍历的窗口块子区域图像分类。
作为上述方案的进一步优化,所述改进的yolo算法逻辑计算获取有效的窗口块子区域。
作为上述方案的进一步优化,所述改进的yolo算法具体步骤包括如下:
(11)卷积神经网络分割上传的经过质检的采集图片获格s×s的网格;
(12)s×s网格的每个单元块获取且预测对应单元块图像的obeject;
(13)每个单元格预测b(b∈n)个边界框boundingbox,每个boundingbox反馈自身的位置,且预测边界框的置信度confidencescore;
(14)每个网格预测c(c∈n)个条件类别概率,设为pr(classi|obeject),标记为c类,class为类,i=0,1,2...,则每个网格预测b个boundingbox,且预测c个类别,即输出张量为s×s(5*b+c);
(15)根据单元网格预测的class信息与boundingbox预测的置信度获取每个boundingbox的特定置信度,且对应进行设置阈值,剔除分数低于阈值的boxes,余下的boxes通过非最大抑制方法筛选,获取最终的检测结果。
作为上述方案的进一步优化,所述的置信度包括两个方面:
(21)边界框含有图像obeject的可能性大小,设为pr(obeject);所述的边界框为空白领域,即不包含图像obeject,对应的pr(obeject)=0;所述的边界框包含obeject,对应的pr(obeject)=1;
(22)边界框的准确度,所述的准确度通过预测框与实际框的交并比iou进行表征,设为
作为上述方案的进一步优化,所述的边界框的大小和位置通过特征值进行表征,(xcenter,ycenter,w,h):
所述(xcenter,ycenter)为边界框的中心位置,即相对于每个单元格左上角坐标点的位移量,且图像单位逻辑对应单元格的大小;
所述(w,h)为边界框的宽度和高度值,边界框的w和h预测值逻辑对应图片的宽和高的比例;
作为上述方案的进一步优化,所述的端口矩阵构建流程包括如下:
(31)设定识别框左上角的点(x,y)标记对应识别框的位置;
(32)根据x的数值大小,选择0.5x的点为中心点,确定中心点左右两边距离中心点最近的点,将中心点与左右距离最近的点拟合成一条直线;
(33)以步骤(32)获取的直线为中心线,分别以等间距绘制两条平行线,则位于所述两条平行线之间的点作为同一行的点;
(34)初始点集合中剔除步骤(33)挑选的同一行的点,且重复步骤(33),直至所有的点均被划分为具体一行;
(35)对于已经分好的点,计算每一行对应y的均值,按照从上至下进行排序;且对每一行的点按照x的大小进行先后排序。
一种基于yolo算法的ai装维巡检系统,包括:
图像采集模块,用于从现有巡检系统采集原始设备巡检照片;
图像预处理模块,针对采集的海量巡检图片,按照业务场景和审核标准进行分类统计,过滤干扰图片;
执行模块,通过构建yolo算法模型,对经过图像预处理操作的图片通过yolo算法学习和模型训练;且通过yolo算法对上传的经过预处理的图片进行算法识别与检测;
传输模块,用于上传质检场景的巡检图片至云端服务器;
存储模块,用于存储巡检人员上传的经过预处理的巡检图片和部署深度学习网络神经模型。
本发明采用上述技术方案,与现有技术相比,本发明的一种基于yolo算法的ai装维巡检方法,具有以下有益效果:
1.本发明的一种基于yolo算法的ai装维巡检方法,通过改进yolo算法,有效筛选并减少检测过程分类的子区域,保障了分类器的结构简单化,提升速度优势,且增加了topdown的多级预测和加深网络手段,便于识别端口之类的小目标,识别准确率高,预测耗时更低。
2.本发明的一种基于yolo算法的ai装维巡检方法,通过在传统的人工识别的合规与不合规基础上,细致划分不合规的具体类别,便于神经网络更加细致提取当前采集的质检图像特征,提高待识别图像的精准度。
3.本发明的一种基于yolo算法的ai装维巡检方法,通过构建端口矩阵,直观反映当前采集的质检图片的端口占用情况,有效降低人工比对的成本,提高了生产效率。
附图说明
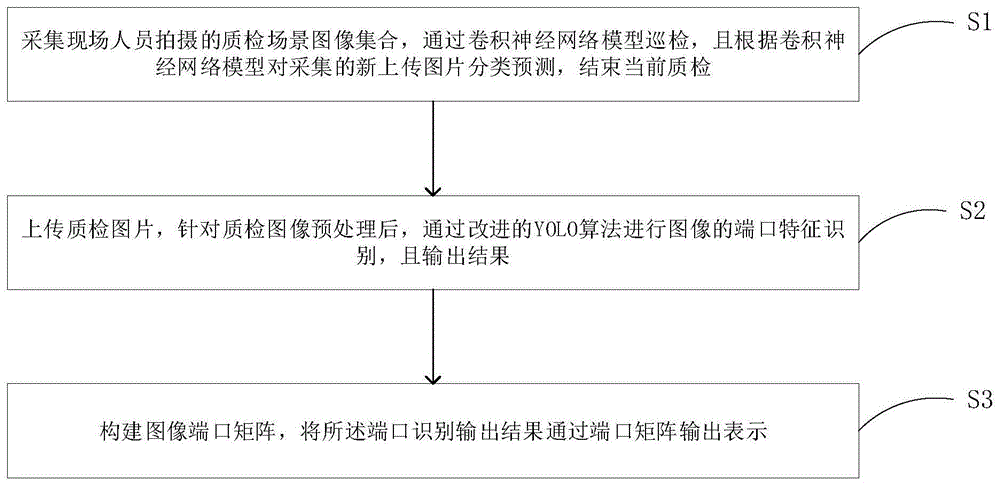
图1为本发明的一种基于yolo算法的ai装维巡检方法的流程示意图;
图2为本发明的一种基于yolo算法的ai装维巡检方法的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面通过附图中及实施例,对本发明进行进一步详细说明。但是应该理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限制本发明的范围。
实施例1
参阅图1,本发明提供了一种基于yolo算法的ai装维巡检的方法,包括如下步骤:
s1,采集现场人员拍摄的质检场景图像集合,通过卷积神经网络模型巡检,且根据卷积神经网络模型对采集的新上传图片分类预测,完成当前质检工作;优选的,本实施例的采集的上传质检场景图像上传至google的inceptionv4网络中进行模型巡检;
作为上述方案的进一步优化,现场采集的图片在进行分类过程还包括图片预处理,即针对光线不佳、拍摄角度差、照片模糊、翻拍以及无关业务的照片进行整理过滤,对于尺寸过大或目标区域实际拍摄过小的图片进行合理裁剪;
作为上述方案的进一步优化,本实施例针对上传的质检场景图片,根据施工现场和巡检标准,将质检场景图片按照合规以及每一种不合规的情形进行分类,大大提高分类预测的准确性;
优选的,某移动机房的巡检人员采集机房的布线走线图像,根据巡检人员反馈的图像数据,细致划分走线图像的类别,包括非走线、合规、走线下垂面板、走线未过孔以及其他类别,通过细致的划分,让神经网络精准提取图像的特征,从而有效提高对于采集图像的识别准确率;
s2,对通过质检工作的图片,进行图片预处理,再通过改进的yolo算法对图像的端口特征识别;
s3,构建图像端口矩阵,将所述端口识别输出结果通过端口矩阵输出表示;
作为上述方案的进一步优化,所述的端口矩阵具体步骤包括如下:
(31)设定识别框左上角的点(x,y)标记对应识别框的位置;
(32)根据x的数值大小,选择0.5x的点为中心点,确定中心点左右两边距离中心点最近的点,将中心点与左右各一个点拟合成一条直线;
(33)以步骤(32)获取的直线为中心线,分别以等间隔绘制两条平行线,则位于所述两条平行线之间的点作为同一行的点;
(34)初始点集合中剔除步骤(33)挑选的同一行的点,且重复步骤(33),直至所有的点均被确定为具体一行;
(35)对于已经分好的点,计算每一行对应y的均值,按照从上至下进行排序;且对每一行的点按照x的大小进行先后排序。
实施例2
本发明的一种基于yolo算法的ai装维巡检的方法,提出一种改进的yolo算法,采用不同大小比例的窗口块,通过预设定窗口块的滑动距离,将所述窗口块遍历整张图片,针对遍历的窗口块子区域图像分类,根据逻辑计算,获取有效的窗口块子区域,减少因多子区域需要大计算量,有效提高速度;
作为上述方案的进一步优化,所述改进的yolo算法具体步骤包括如下:
(11)卷积神经网络分割上传的经过质检的采集图片获格s×s的网格;
(12)s×s网格的每个单元块获取且预测对应单元块图像的obeject;
(13)每个单元格预测b(b∈n)个边界框boundingbox,每个boundingbox反馈自身的位置,且预测边界框的置信度confidencescore;
(14)每个网格预测c(c∈n)个条件类别概率,设为pr(classi|obeject),标记为c类,class为类,i=0,1,2...,则每个网格预测b个boundingbox,且预测c个类别,即输出张量为s×s(5*b+c);
(15)根据单元网格预测的class信息与boundingbox预测的置信度获取每个boundingbox的特定置信度,且对应进行设置阈值,剔除分数低于阈值的boxes,余下的boxes通过非最大抑制方法筛选,获取最终的检测结果;
作为上述方案的进一步优化,所述的置信度包括两个方面:
(21)边界框含有图像obeject的可能性大小,设为pr(obeject);所述的边界框为空白领域,即不包含图像obeject,对应的pr(obeject)=0;所述的边界框包含obeject,对应的pr(obeject)=1;
(22)边界框的准确度,所述的准确度通过预测框与实际框的交并比iou进行表征,设为
作为上述方案的进一步优化,所述的边界框的大小和位置通过特征值进行表征,(xcenter,ycenterw,h):
所述(xcenter,ycenter)为边界框的中心位置,即相对于每个单元格左上角坐标点的位移量,且图像单位逻辑对应单元格的大小;
所述(w,h)为边界框的宽度和高度值,边界框的w和h预测值逻辑对应图片的宽和高的比例;
作为上述方案的进一步优化,所述的端口矩阵构建流程包括如下:
(31)设定识别框左上角的点(x,y)标记对应识别框的位置;
(32)根据x的数值大小,选择0.5x的点为中心点,确定中心点左右两边距离中心点最近的点,将中心点与左右各一个点拟合成一条直线;
(33)以步骤(32)获取的直线为中心线,分别以等间距绘制两条平行线,则位于所述两条平行线之间的点作为同一行的点;
(34)初始点集合中剔除步骤(33)挑选的同一行的点,且重复步骤(33),直至所有的点均被确定为具体一行;
(35)对于已经分好的点,计算每一行对应y的均值,按照从上至下进行排序;且对每一行的点按照x的大小进行先后排序。
实施例3
本发明还提供了一种基于yolo算法的ai装维巡检系统,包括:
图像采集模块100,用于从现有巡检系统采集原始设备巡检照片;
图像预处理模块200,针对采集的海量巡检图片,按照业务场景和审核标准进行分类统计;
执行模块400,通过构建yolo算法模型,对经过图像预处理操作的图片通过yolo算法学习和模型训练;且通过yolo算法对上传的经过预处理的图片进行算法识别与检测;
传输模块300,用于上传质检场景的巡检图片至云端服务器;
存储模块500,用于存储巡检人员上传的经过预处理的巡检图片和部署深度学习网络神经模型;
通过采集巡检系统现有的原始设备巡检照片,通过对海量照片进行预处理,剔除光线不好、角度较差、模糊严重、翻拍和无关业务的照片,对于尺寸较大、目标区域较小的图片进行裁剪,且通过构建图片分类和目标检测的yolo算法模型,对于预处理的图片进行模型训练和模型学习,再将成熟的yolo算法模型部署至云端服务器,且将端口识别和图片分类预测的功能开放到api接口,管理人员发送巡检工作单至巡检人员,巡检人员接收到巡检工作指令后,对现场设备进行拍照,拍照的过程中调用yolo算法模型功能api接口,完成图像的智能审核工作。
本发明的一种基于yolo算法的ai装维巡检方法及系统,通过采集海量现场原始设备的巡检图片,通过inceptionv4卷积神经网络模型巡检,且根据模型对采集的新上传图片分类预测,上传质检图片至云端平台,针对质检图像预处理后,通过改进的yolo算法进行上传图像的端口特征识别,通过测试后检验结果,输出结果;构建图像端口矩阵,将所述端口识别输出结果通过端口矩阵输出表示。本发明的一种基于yolo算法的ai装维巡检方法及系统,通过在传统的人工识别的合规与不合规基础上,细致划分不合规的具体类别,便于神经网络更加细致提取当前采集的质检图像特征,提高待识别图像的精准度,且通过构建端口矩阵,直观反映当前采集的质检图片的端口占用情况,有效降低人工比对的成本,提高了生产效率。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!