适于购物小票的图片文字识别方法与流程
本发明涉及一种适于购物小票的图片文字识别方法。
背景技术:
现有图片文字识别方法有多种,但往往需要较大的数据处理量,采用高性能的计算机或者利用云端服务器进行文字识别,既不便捷,又需要较高的成本。
技术实现要素:
为解决上述技术问题,本发明提供了一种适于购物小票的图片文字识别方法,以简化处理过程,降低设备要求,方便使用。
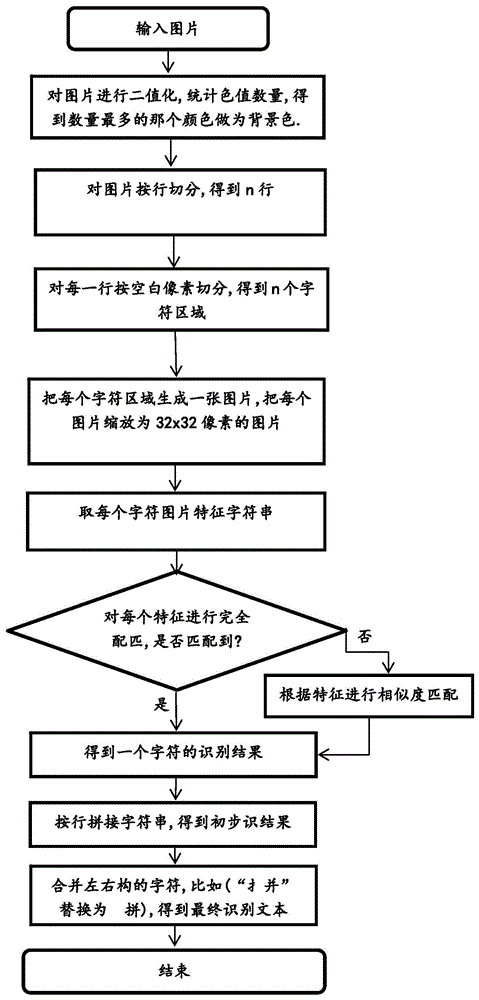
本发明的技术方案是:一种适于购物小票的图片文字识别方法,包括下列步骤:
1)对图片进行二值化,统计色值数量,将色值数量最多的颜色做为背景色;
2)对图片按行切分,获得一行或多行;
3)对切分后的每一行沿空白像素纵向切分,得到一个或多个字符区域;
4)将每个字符区域生成一张字符图片,将每个字符图片缩放为一个特定尺寸(纵横像素数)的图片;
5)提取每个字符图片的字符图片特征;
6)依据字符图片特征进行字符查询,获得相应的字符,字符查询以特征数据库为数据基础,所述特征数据库为体现字符图片特征与相应字符映射关系的数据库;
7)将查询获得的字符顺序排列,形成初步的文字识别结果。
优选地,将每个字符图片缩放为一个32×32像素的小图片。
所述字符图片特征优选为字符图片中各像素的值顺序排列成的特征字符串。
所述字符图片中各像素的值的顺序排列通常应为同一行的顺序为由左到右,不同行的顺序为由上到下,以适应于现代文字排列习惯。
优选地,以1为字符图片上的前景色像素(通常为黑色)的值,以0为字符图片上的背景色(通常为白色)像素的值。
所述特征数据库的字段通常可以包括dna、width、height和words,其中dna的字段值为字符图片特征,width和height的字段值分别为字符图片的宽和高,words的字段值为所映射的字符。
通常应构建特征数据库的特征索引。
所述特征索引可以包括完全匹配索引和相似性索引。
所述完全匹配索引为针对每个元组,计算dna的hash值hash(dna),将hash(dna)转为36进制数的字符串,再拼接width和height,以由此获得的字值符hash(dna)_width_height作为键,以words作为值,得到一个全量特征数据集。
与上述完全匹配索引不同的是,所述相似性索引为先将dna进行分词再构建特征索引。通常,每个分词的最长长度可以设定为27,长度不足27时取其全部。
优选地,在进行字符查询时,先采用完全匹配索引查询,获得完全匹配的字符,在没有完全匹配的字符的情况下,再采用相似性索引查询,获得相似度最大的字符。
优选地,检测初步的文字识别结果中是否存在同一左右构文字的横向排列字符相互分离的情形。当存在同一左右构文字的横向排列字符相互分离的情形时,将构成左右构文字的横向排列字符合并,替换为相应的文字,由此形成最终的文字识别结果;当不存在同一左右构文字的横向排列字符相互分离的情形时,以初步的文字识别结果作为最终的文字识别结果。
可以依据字符合并字典进行横向排列字符相互分离的左右构文字的横向排列字符合并,所述字符合并字典为体现左右构文字的左、右字符与该文字的映射关系的字典或数据库。
初步的文字识别结果中是否存在同一左右构文字的横向排列字符相互分离的情形的检测中,可以依据常规文字、符号和文字偏旁数据库进行字符的识别,在发现不属于常规文字和符号且属于文字偏旁的字符时,依据字符合并字典查询其是否与相邻字符构成一个左右构文字,如是,将其与与其构成一个左右构文字的相邻字符合并,即替换为相应的左右构文字。
可以采用扫描仪、数码照相机或摄像机等进行小票等待识别图片的采集和/或输入。
本发明的有益效果是:由于以图片二值化后数量最多的颜色做为背景色,适应于不同颜色的小票,降低了分辨误差,降低了分析的数据处理量;由于按空白像素将行切分为若干字符区域,方便了运算;由于全部字符区域均缩放为32×32像素的字符区域图片,更好地适用于小票的文字特点,有利于在保证准确性的同时减少数据处理量,且为后续处理提供了条件;由于采用hash值构建全量特征数据集,适应于小票的语言特点,既减少了数据量,同时也保证了识别的准确性;由于以字符区域图片各像素值组成的字符串作为特征字符串进行完全匹配,在不能完全匹配的情形下进行相似性匹配,匹配精确,且有助于减少数据处理量;由于进行了左右构字符的合并,弥补了字符区域切分导致的左右构文字分体的缺陷。
附图说明
图1是本发明的流程图;
图2是一种小票实例;
图3是图2所示的小票的切分识别结果部分截图;
图4是图2上面的“越”抽取出来的特征字符串;
图5是相似度判断的原理示意图。
具体实施方式
下面,结合附图和实施例,具体说明本发明的实施方式。
图1显示了本发明的一种工作流程。
以图2显示的小票样式为例,经过按行切分和同一行纵向切分,切分效果参见图3。
以图3涉及的“越”为例,将该文字(或符号)对应的字符区域经过缩放后提取特征信息。将该字符图片上的前景色像素点(黑色字迹部分)看作是1,背景色(白色空白部分)看作是0,得到是“越”字的像素图像如图4所示,该像素图像中各点的像素值排列成字符串(可称为特征字符串),作为特征数据,此字符串记作dna,此图片的宽度记为width,高度记为height,以dna、width、height作为一个特征,映射字符“越”记为words,记录在特征数据库。
针对小票或其他待处理图片可能涉及的所有文字和符号,逐一进行上述操作,形成特征数据库。
识别过程说明:
1)构建特征索引
从特征数据库中取出每一条特征信息进行构建索引.特征索引主要分为下面两部分:
完全匹配索引。完全匹配索引构建过程如下:根据特征数据库中的特征字符串dna计算其hash值并转为36进制数的字符串,再拼接宽、高,得到字值符hash(dna)_width_height作为键,words作为值,得到一个全量特征数据集;
相似性索引。相似性匹配索引是把一个特征数据看作是一个文档,对其进行分词,每个词最长长度为27,不足27则取它的全部。
2)识别
输入小票图片后,选择切分方法进行按行、按列切分,缩放为32x32像素小图,然后抽取特征,根据特征先进行完全匹配,如果匹配失败,再进行查询相似性索引,得到一个最相似的结果。
dna相似性索引检索抽象可以为一个向量空间模型,如图5所示。
d(document)表示一篇文档(即一条特征信息,一篇文档包括3个字段dna、width、height);
q(query)表示查询表达式;
f(field)表示一篇文档中的字段(dna,width,height);
t(term)表示27个字符的词;
根据夹角越小余弦值越大的性质,最终通过计算向量间夹角的余弦值作为两个项之间的相似度,公式如下:
score(q,d)表示查询向量q和文档向量d的夹角余弦;
v(q):查询向量
v(d):文档向量
v(q)·v(d)表示查询向量q和文档向量d的点积(可看作交集)
qi表示一个查询中的一个词(由27个0或1组成的字符串)
di表示一个文档中的一个词(由27个0或1组成的字符串)
相似性索引查询,是把dna按27个字符进行分词,以分词及width、height进行模糊检索,得到特征最相似的一个结果。
对所有字符图片的循环完成以后,再做一次字符合并,用“字符合并字典”进行替换操作。
字符合并字典是一个键值格式的文件,如:
讠己=记
亥刂=刻
……
将初步识别结果中这些带有明显特点的字符串替换成正常的汉字,比如“讠己”被替换为“记”,“亥刂”替换为“刻”等等,替换完成后就得到了最终结果。
本发明公开的各优选和可选的技术手段,除特别说明外及一个优选或可选技术手段为另一技术手段的进一步限定外,均可以任意组合,形成若干不同的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!