基于协同矩阵分解的在线哈希跨模态信息检索方法与流程
本发明涉及计算机技术领域,更进一步涉及信息检索技术领域的一种基于协同矩阵分解的在线哈希跨模态信息检索方法。本发明可用于现有信息检索应用,包括文字,图片等多种模态的数据,实现在线数据模态内部及模态间的快速检索。
背景技术:
随着互联网的不断发展,数据量飞速增长,同时用以承载信息的数据形式也呈现出了多样化,这些数据通常都具有数据量大,维数较高等特点,为了能够实现对于多样化的数据进行快速准确的检索,需要采用哈希方法对数据进行降维、编码。传统的哈希检索方法需要存储大量历史数据,通过对历史数据的训练学习,建立模型,但是传统哈希检索方法并不能解决对在线数据进行模型建立的问题。如何针对上述问题实现对在线增长数据的模型建立以及不同模态间数据的快速检索,是当前信息检索技术领域需要亟需解决的问题。
guiguangding,yuchenguo,jilezhou在其发表的论文“collectivematrixfactorizationhashingformultimodaldata”(ieee国际计算机视觉与模式识别会议论文集2014年)中提出了一种基于矩阵分解的跨模态信息检索方法。该方法是一个无监督的学习方法,在训练阶段,通过矩阵分解的思想,迭代优化得到投影矩阵,不同的模态生成不同的投影矩阵,将不同模态的数据统一投影到汉明空间,得到训练样本的哈希编码。在测试阶段,通过训练阶段得到的投影矩阵将测试样本进行投影,得到测试样本的哈希编码。但是,该方法仍然存在的不足是,该方法需要对历史数据进行存储,在数据量很大的情况下,会产生很大的数据存储压力,同时面对数据的快速增长,该方法不能够解决动态增长数据的模型在线建立问题。
long-kaihuang,qiangyang,wei-shizheng在其发表的论文“onlinehashing”(国际人工智能联合会议论文集2013年)中提出了一种在线哈希信息检索方法。该方法是一个有监督在线哈希学习方法。该方法对于每次的输入数据通过类标信息判断相似性,计算损失函数,如果损失函数的值超过设定的范围则更新投影矩阵,否则无须更新投影矩阵,根据学到的投影矩阵,可以得到数据的哈希编码。但是,该方法仍然存在的不足是,该方法每次输入一对数据,数据量太小,无法很好的满足目前应用中的实际需求,并且该算法在判断数据的相似性信息时,需要数据的类标信息,但在实际的应用中,对于新数据工程实践中常常不能获知其类标信息。
综上所述,对于信息检索领域的应用,目前已有的方法仍然存在由于只对历史数据进行训练而导致模型不能实时学习新数据的特征,由于需要存储大量历史数据用于模型训练而导致存储空间不足,由于数据的类标信息难以获得而导致算法适用度较低等问题。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种基于协同矩阵分解的在线哈希跨模态信息检索方法。本发明充分考虑了现实应用中数据的状态,利用协同矩阵分解的方法,对于动态增长的无类标数据建立模型,每一轮更新中记录下计算结果,用于下一轮更新,有效提升了计算速度,降低了系统的存储压力。
实现本发明的技术思路是,在训练模式下,系统实时获取数据,利用矩阵分解方法构建信息损失函数,通过对损失函数进行迭代优化,得到当前的潜在语义矩阵,投影矩阵和哈希编码矩阵,将哈希编码矩阵进行符号函数运算,获得训练数据对应的哈希编码;在测试模式下,利用训练模式下获得的投影矩阵进行矩阵投影,得到测试数据的哈希编码矩阵,进行符号函数运算,获得测试数据的哈希编码;在对于该方法进行评估时,采用信息检索领域常用的评估标准:平均精度均值(map),该标准可以用来衡量信息检索的准确性。
本发明的具体步骤包括如下:
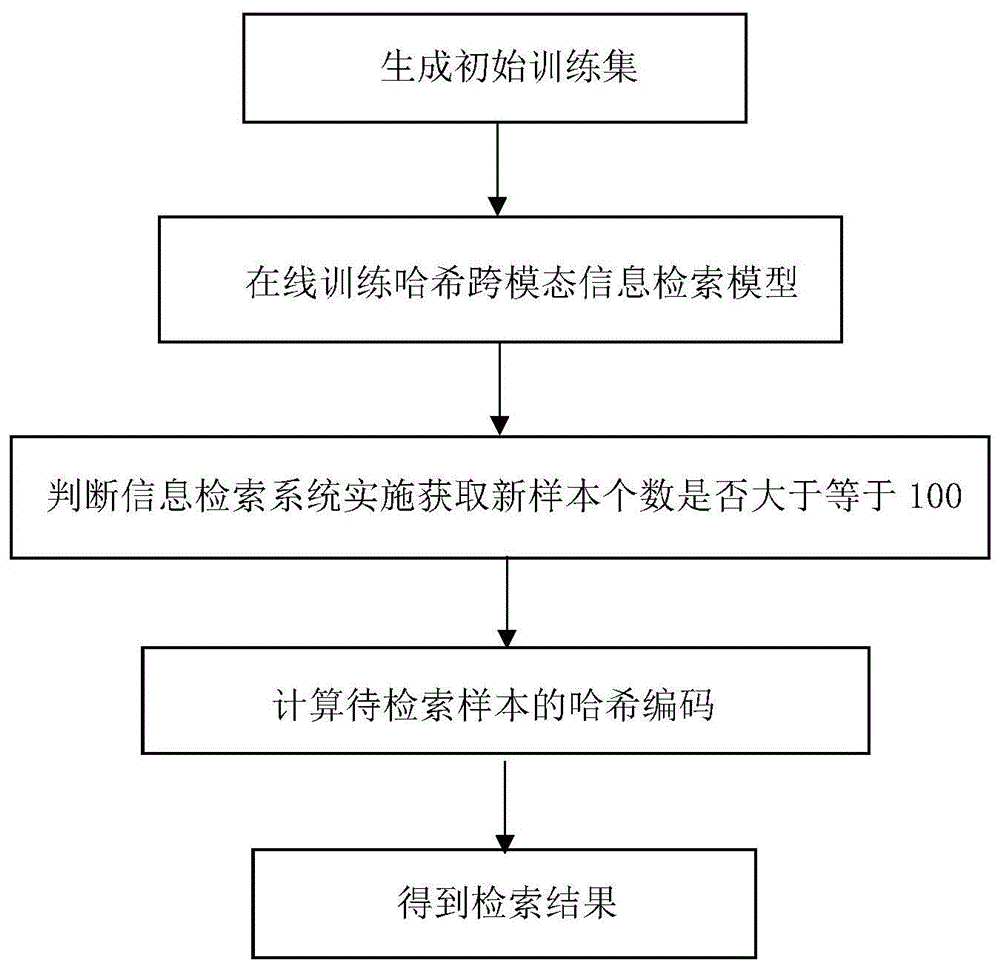
(1)生成初始训练集;
(1a)采集不少于100个图像样本和英文单词样本;
(1b)利用信息矩阵转化方法,将采集到的样本信息转化为信息矩阵,将转化后的信息矩阵存入到信息检索系统中;
(1c)将图像和英文单词一一对应生成不少于100个样本对,得到初始训练集;
(2)在线训练哈希跨模态信息检索模型;
(2a)信息检索系统实时获取不少于100个样本信息,组成当前数据信息矩阵x∈rd×n,其中,x表示数据信息矩阵,∈表示属于符号,r表示实数集,d表示样本信息的维数,若样本信息为图像信息,则d表示每一张图像像素点的总数,若样本信息为英文单词,则d表示单词向量化后的向量维数,n表示实时获取到的样本总数;
(2b)随机生成初始化潜在语义矩阵u∈rd×k、投影矩阵p∈rk×d、哈希编码矩阵v∈rk×n共三个矩阵,其中,k表示哈希编码长度,其数值由用户从8bit,16bit,24bit,32bit,64bit,128bit的编码长度中选取一个长度;
(2c)构造一个信息损失函数,该函数中包含投影矩阵、潜在语义矩阵、哈希编码矩阵的信息;
(2d)分别对信息损失函数中的投影矩阵、潜在语义矩阵和哈希编码矩阵求一阶导数,并将求导得到的矩阵带入到信息损失函数中,得到更新后的信息损失函数值;
(2e)判断更新后的信息损失函数值是否小于更新前的信息损失函数值,若是,则执行步骤(2f),否则,执行步骤(2d);
(2f)判断更新后的信息损失函数值减去更新前的信息损失函数值的差值是否大于0.001,若是,则执行步骤(2d),否则,执行步骤(2g);
(2g)将更新好的哈希编码矩阵中数值大于零的,记为1,其余记为0,得到样本的哈希编码,将其存入信息检索系统中:
(3)判断信息检索系统实时获取的新样本个数是否大于等于100,若是,则执行步骤(2),否则,执行步骤(4);
(4)计算待检索样本的哈希编码;
(4a)利用信息矩阵转化方法,将待检索的文本样本或者图像样本转化为信息矩阵;
(4b)将更新好的投影矩阵与待检索样本的信息矩阵相乘,计算出待检索样本的哈希编码;
(5)得到检索结果;
(5a)对待检索样本的哈希编码与信息检索系统中已有哈希编码进行异或操作,得到汉明距离;
(5b)将信息检索系统中存储的样本按照汉明距离的大小从小到大进行排序,将排序后的前50个样本作为检索结果。
本发明与现有技术相比有以下优点:
第一,由于本发明在线训练哈希跨模态信息检索模型,根据信息检索系统实时获取的新数据更新模型,克服了现有技术存储大量历史数据并离线进行模型训练,造成的模型对实时数据特征的拟合效果差的缺点,使得本发明具有更高的实用性,提高了信息检索系统的检索效率。
第二,本发明通过矩阵分解方法构建信息损失函数,在迭代优化的过程中无须存储大量历史数据,克服了现有技术消耗过多存储资源的问题,使得本发明具有速度快,占用存储资源更少的优点。
附图说明
图1为本发明的流程图。
图2为本发明方法与非在线哈希跨模态检索方法cmfh平均精度均值曲线对比实验图。
具体实施方式
下面结合附图1对本发明做进一步描述。
步骤1,生成初始训练集。
采集不少于100个图像样本和英文单词样本。
利用信息矩阵转化方法,将采集到的样本信息转化为信息矩阵,并将转化后的信息矩阵存入信息检索系统中。
所述的信息矩阵转化方法如下:
若样本为图像样本,则将每张图像的每行像素灰度值首尾相接依次排列,组成图像信息矩阵。
若样本为英文单词样本,则将每一个英文单词向量化,将每一个向量化后的数据按行排列,组成文本信息矩阵。
将图像和英文单词一一对应生成不少于100个样本对,得到初始训练集。
步骤2,在线训练哈希跨模态信息检索模型。
(2.1)信息检索系统实时获取不少于100个样本信息,组成当前数据信息矩阵x∈rd×n,其中,x表示数据信息矩阵,∈表示属于符号,r表示实数集,d表示样本信息的维数,若样本信息为图像信息,则d表示每一张图像像素点的总数,若样本信息为英文单词,则d表示单词向量化后的向量维数,n表示实时获取到的样本总数。
(2.2)随机生成初始化潜在语义矩阵u∈rd×k、投影矩阵p∈rk×d、哈希编码矩阵v∈rk×n共三个矩阵,其中,k表示哈希编码长度,其数值由用户从8bit,16bit,24bit,32bit,64bit,128bit的编码长度中选取一个长度。
(2.3)构造一个信息损失函数,该函数中包含投影矩阵、潜在语义矩阵、哈希编码矩阵的信息。
所述的信息损失函数如下:
其中,f表示信息损失函数,||||f表示做f范数操作,x'表示初始训练集中的图像信息矩阵或文本信息矩阵,u表示潜在语义矩阵,v'表示哈希编码矩阵,μ表示用于平衡矩阵分解与矩阵映射之间权重关系的参数,该参数是由用户在(0,1]范围内设定,p表示投影矩阵,x表示当前数据信息矩阵,v表示当前数据信息矩阵的哈希编码矩阵。
(2.4)分别对信息损失函数中的投影矩阵、潜在语义矩阵和哈希编码矩阵求一阶导数,并将求导得到的矩阵带入到信息损失函数中,得到更新后的信息损失函数值。
(2.5)判断更新后的信息损失函数值是否小于更新前的信息损失函数值,若是,则执行本步骤的(2.6),否则,执行本步骤的(2.4)。
(2.6)判断更新后的信息损失函数值减去更新前的信息损失函数值的差值是否大于0.001,若是,则执行本步骤的(2.4),否则,执行本步骤的(2.7)。
(2.7)将更新好的哈希编码矩阵中数值大于零的,记为1,其余记为0,得到样本的哈希编码,并将其存入信息检索系统中。
步骤3,判断信息检索系统实时获取的新样本个数是否大于等于100,若是,则执行步骤2,否则,执行步骤4。
步骤4,运用信息检索系统进行信息检索。
利用信息矩阵转化方法,将待检索的文本样本或者图像样本转化为信息矩阵。
将更新好的投影矩阵与待检索样本的信息矩阵相乘,计算出待检索样本的哈希编码。
所述的信息矩阵转化方法如下:
若样本为图像样本,则将每张图像的每行像素灰度值首尾相接依次排列,组成图像信息矩阵。
若样本为英文单词样本,则将每一个英文单词向量化,将每一个向量化后的数据按行排列,组成文本信息矩阵。
将更新好的投影矩阵与待检索样本的信息矩阵相乘,计算出待检索样本的哈希编码。
步骤5,得到检索结果。
对待检索样本的哈希编码与信息检索系统中已有哈希编码进行异或操作,得到汉明距离。
将信息检索系统中存储的样本按照汉明距离的大小从小到大进行排序,将排序后的前50个样本作为检索结果。
本发明的效果可以通过以下仿真实验进一步说明:
1,仿真条件:
本发明仿真实验使用matlab2016b仿真软件,将用于平衡矩阵分解与矩阵映射之间权重关系的参数μ设为0.02,数据信息矩阵的样本个数n设为10000,表示信息检索系统每次获取10000个样本信息,哈希编码长度k分别设置为16bit,32bit,64bit,128bit分别进行实验。
2,仿真内容与结果分析:
本发明的仿真实验是,首先将mirflickr数据库中的图像数据和文本数据划分为训练数据和测试数据,然后分别采用本发明方法和现有技术中非在线哈希跨模态检索方法cmfh训练哈希跨模态检索模型,再将测试数据作为待检索样本测试模型性能。
为了验证本发明的仿真实验的效果,分别计算了当哈希编码长度为16bit、32bit、64bit、128bit时,采用本发明方法和现有技术中非在线哈希跨模态检索方法cmfh建立的信息检索模型进行检索的平均精度均值,将计算出的平均精度均值用折线连接,得到平均精度均值曲线,如图2所示。其中,图2中的横坐标表示哈希编码长度,纵坐标表示检索的平均精度均值。
图2(a)为由文本信息检索图像信息所得到结果的平均精度均值结果。图2(a)中以实心方块标示的曲线表示采用本发明方法建立的信息检索模型计算得到的平均精度均值曲线,以实心圆点标示的曲线是采用传统非在线哈希跨模态检索方法cmfh进行检索得到的平均精度均值曲线。
图2(b)为由图像信息检索文本信息所得到结果的平均精度均值结果。图2(b)中以实心方块标示的曲线表示采用本发明方法建立的信息检索模型计算得到的平均精度均值曲线,以实心圆点标示的曲线是采用传统非在线哈希跨模态检索方法cmfh进行检索得到的平均精度均值曲线。
由图2的仿真结果可见,采用本发明方法建立的信息检索模型进行检索得到的平均精度均值曲线,高于采用传统非在线哈希跨模态检索方法cmfh进行检索得到的平均精度均值曲线。由此可见,采用本发明方法进行信息检索准确性显著优于传统非在线哈希跨模态检索方法cmfh。所以,与现有技术相比,本发明能有效对在线实时数据进行模型的建立和更新,显著提高了信息检索系统的检索准确性。
- 还没有人留言评论。精彩留言会获得点赞!