一种面向深度学习模型训练和学习的影像图像数据扩充方法与流程
本发明涉及一种面向深度学习模型训练和学习的影像图像数据扩充方法,属于计算机医学图像计算技术领域。
背景技术:
在大数据时代一个高性能的深度模型往往需要大量的高质量数据,但高质量数据的获取并不容易,因此这也意味着一个健壮(robust)的模型并不容易获得。其次,与自然图像相比,医学图像数据的获取往往更为困难,其根源来自病例数据获取不易,同时数据的使用也存在一定的伦理和隐私限制,很难从实际角度上解决。例如,美国国立卫生研究院(nih)在17年9月公布了胸部影像(ct)图像数据集中共包含11万张图像数据,在去敏感信息的问题上,nih团队使用人机配合的模式一共筛查了七遍,其中包括最后纯人工筛查的两遍,临时雇佣了14位医学博士耗费数月时间,工作量非常大。在一定角度上,该情况加重了大数据模式在医学诊断领域发展的困境。
由于影响数据量不足,影像图像数据还常常具有很强的异质性(heterogeneity)。由于数据集获取困难,在图像样本数据不足的情况下,对于某种稀有病例往往只有极少量样本可供予模型进行训练、学习与测试,往往造成这种具有独特影像特性的样本数据在大量其他正、负样本的“冲击”下被当做异常数据。针对某些发病率较低且恶性程度通常较高的肿瘤的研究往往需要大批量的数据研究,样本数量不足也会造成数据类别的不均衡,从而导致过拟合(overfitting)。
此外,在许多情况下,计算机影像图像处理模型从分子亚型的分类到各类诊断评级系统的搭建,在获得出色的性能的同时都对高质量数据量有极高的要求。对于影像数据而言,例如影像科医生往往会根据自身习惯对核磁共振机器的一部分参数进行调节以突出特定的组织,这就造成了同一台机器不同时期的扫描结果也会有较大的差异。因此,通过数据扩充来实现影像图像的主动领域适应是提高模型精度和性能的关键。由于影像图像数据的特征信息往往更丰富也更隐秘,很多有价值的信息均属于“亚视觉”特征,对于大量的如反色、超像素等方法,往往在医学图像领域的应用很局限,也需要在预测端进行数据扩充,以应对在模型应用时出现的一些非正常案例。
针对上述问题,目前有一些解决方法。如在网络中加入类别正则化项,平衡过大或者过小的权重值来减少数据自身的不平衡性;也可在网络搭建时采用弃权(dropout)技巧,动态调整网络基础架构来避免过拟合现象。不过,现有方法在解决影像数据的异质性方面明显不足,无法从根本上解决数据量不足的问题,不利于一些稀有病例的影像分析。本发明介绍的数据扩充是一种行之有效的策略,尤其适合于影像图像数据的扩充。
技术实现要素:
本发明要解决的技术问题是针对现有技术在解决影像数据异质性和分析稀有病例影像方面的不足,提出一种面向深度学习模型训练和学习的影像图像数据扩充方法,将系列数据扩充的方法应用于医学图像处理的深度模型训练学习,有效地平衡地扩充数据集,通过数据迭代扩充,帮助医生提高工作效率和疾病诊断的精准率,实现医工结合的高效医疗和精准医疗。
为解决上述技术问题,本发明提供一种面向深度学习模型训练和学习的影像图像数据扩充方法,包括以下步骤:
(1)判断数据类型,鉴别ct或mri图像数据;
(2)对于影像数据,判断是否有划定roi,并结合肿瘤区域大小,选用相应的方法完成影像数据集的构建;
(3)采用基本的图像变换法对影像数据集进行训练,获得初步训练数据集。获得初步训练数据集,初步扩充后的数据集已经能使深度学习网络获得一定的性能攀升。此时,对于进行初步扩充后的数据还可以使用生成对抗网络(gan)进行进一步的更丰富的数据扩充。之后,即可将数据集送入深度学习网络模型中进行参数训练。在常用的网络模型的参数训练过程中,我们也可以使用hnm的方法,来对数据集进行进一步的平衡。
(4)对初步训练数据集进行数据扩充,再采用网络模型进行深度训练,最后进行概率预测。使用训练好的模型,针对新的一批患者数据,能有效提升网络模型的鲁棒性(对数据的泛化能力)和各类性能,如准确率、f1-score、dice系数、miou、map等。
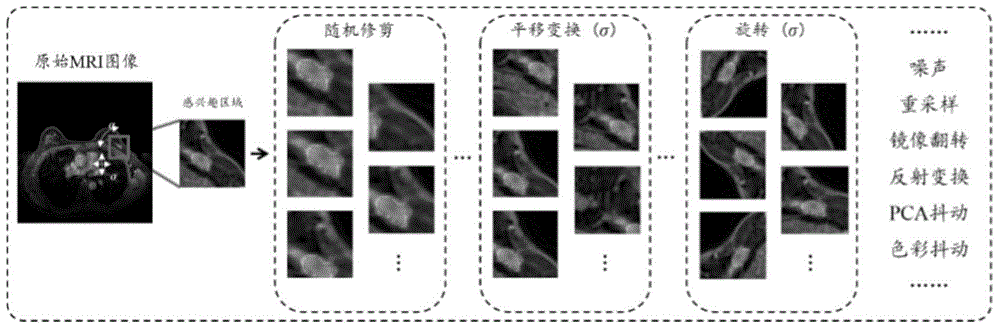
所述步骤(2)中,影像数据集的构建采用mri基于roi的数据扩充方法,首先选取原始mri图像的感兴趣区域,然后采用常规方法,针对感兴趣区域图像依次进行修剪、平移变换、旋转、除噪、重采样、镜像翻转、反射变换、pca抖动、色彩抖动处理,获得mri影像数据集。除上述的方法之外,还可以使用更加高级的基于生成对抗网络(gan)的数据扩充方法,其方法是通过学习训练数据集中的数据分布,在预测阶段使用随机噪声即可产生任意数量的扩充数据。
本方法中,基于roi的数据扩充,可以是在给定由医生标定或是算法导出的感兴趣区域(regionofinterest,roi)的影像数据集中随机取块,即从原始图像感兴趣区域中任意取块得出数个修剪后的小块用作训练集的构建。
本方法中,针对特定图像数据修剪的修剪框尺寸不能太小,随机的剪裁和取块往往会偏离roi选定框的主要内容。
本方法中,图像的旋转是针对一定roi区域的旋转,对完整影像图像翻转可能会对组织结构的分布造成破坏,构成异常数据。肿瘤自身的形状往往没有单一而固定的模式,它们往往不会出现较大幅度的翻转,对肿瘤的旋转扩充方法更有利于挖掘图像信息的多样性,从而有效提升深度网络的性能和稳定性。
所述除噪过程是采用现有滤波器对处理图像中的干扰信息进行滤除。如高斯滤波、均值、中值滤波等。高斯滤波实际上是一种加权变换模型,利用了图像主要信息与噪声的能量差异来滤除服从正态分布的干扰信号,通常的实现方式是对离散的滑动窗进行卷积,也可用通过傅里叶变换。
所述步骤(3)具体是采用现有图像数据训练方法,对图像数据集进行多次(n次)训练,初步预测各数据概率,获得初步训练数据集。
所述步骤(4)具体是采用hnm泛化型数据增强方式,在对影像数据集进行扩充和逐步平衡后,通过深度网络训练模型,对初步训练数据集中的mri图像数据进行多次(n+1次)迭代训练,继而进行概率预测,确定目标图像。
本方法中,对于不平衡数据集的扩充和平衡,使用hardnegativemining(hnm)的方法,对mri或ct影像数据进行泛化能力比较强的扩充,而不是统一形式的扩充。在刚开始训练的时候由于数据不平衡,一部分属于小类别的数据倾向于被错分到大类别中,此时将这些分错的小类别数据删选出来,有针对性的把小类别数据扩充,慢慢地使数据变得平衡。也可以通过重复采样,即在不产生过拟合的情况下,通过重复采样同一张图像数据来实现对原始不平衡数据的扩充。还可通过对原始图像中的对比度进行增强来扩充数据集,利用mri图像像素密度高的特点扩大不同像素间的差异。
所述深度网络训练模型为alexnet、resnet、segnet、deeplab、yolo、ssd其中一种。采用的深度学习模型都有较好的适用性。较为典型的,在分类网络resnet-101中,针对4种亚型的乳腺癌的分类能有效提升预测准确率。
所述方法的数据概率预测端还加入有数据扩充,以提高模型预测能力。在模型搭建与测试完成后,一般情况下即可以用作一个可靠的框架来对对象实现较为精准的预测,但医学图像的多变性往往可能会超出模型所能涵盖的范围。因此,在计算和时间允许的情况下,可以在预测时加入数据扩充,然后采用多人投票的方式得出最终预测结果。主要是扩充模型还未涵盖到的数据分布,在经过扩充后可以更贴近实际情况,从而扩充模型的预测能力。
本发明基于人工智能的深度学习,将一系列数据扩充的方法应用在医学图像处理领域的深度模型训练的学习上,可以有效地平衡地扩充数据集,减少网络过拟合,提高模型的准确率和泛化能力等,解决由医学图像数据异质性而出现的异常数据现象,有助于利用深度学习的方式进行计算机辅助诊断,提高诊断效率和准确率,减轻医生负担。
附图说明
图1是本发明mri基于roi区域的数据扩充方法原理图。
图2是本发明hnm泛化型数据增强方式第n次迭代过程原理图,由于数据不均衡导致预测概率偏向大类别typed(真实类别为typec)。
图3是本发明采用hnm方法均衡数据集后预测概率恢复正常结果原理图,。
图4是本发明实施例用于前列腺mr图像对比度增强前后对比图。
图5是本发明实施例对roi区域进行各类滤波结果对比图。
图6是本发明乳腺癌四种亚型预测流程图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步详尽描述,实施例中未注明的技术或产品,均为现有技术或可以通过购买获得的常规产品。
实施例1:如图1-6所示,本面向深度学习模型训练和学习的影像图像数据扩充方法包括以下步骤:
(1)判断数据类型,鉴别ct或mri图像数据;
(2)对于影像数据,判断是否有划定roi,并结合肿瘤区域大小,选用相应的方法完成影像数据集的构建;
(3)采用基本的图像变换法对影像数据集进行训练,获得初步训练数据集。获得初步训练数据集,初步扩充后的数据集已经能使深度学习网络获得一定的性能攀升。此时,对于进行初步扩充后的数据还可以使用生成对抗网络(gan)进行进一步的更丰富的数据扩充。之后,即可将数据集送入深度学习网络模型中进行参数训练。在常用的网络模型的参数训练过程中,我们也可以使用hnm的方法,来对数据集进行进一步的平衡。
(4)对初步训练数据集进行数据扩充,再采用网络模型进行深度训练,最后进行概率预测。使用训练好的模型,针对新的一批患者数据,能有效提升网络模型的鲁棒性(对数据的泛化能力)和各类性能,如准确率,f1-score,dice系数,miou,map等。
在步骤(2)中,影像数据集的构建采用mri基于roi的数据扩充方法,首先选取原始mri图像的感兴趣区域,然后采用常规方法针对感兴趣区域图像依次进行修剪、平移变换、旋转、除噪、重采样、镜像翻转、反射变换、pca抖动、色彩抖动、弹性畸变、灰阶调整处理,获得mri影像数据集。
本方法中,基于roi的数据扩充是在给定由医生标定的感兴趣区域(regionofinterest,roi)的影像数据集中随机取块,即从原始图像感兴趣区域中任意取块得出数个修剪后的小块用作训练集的构建。
本方法中,针对特定图像数据修剪的修剪框保持较大尺寸,以防止随机剪裁和取块偏离roi选定框的主要内容。
本方法中,图像的旋转是针对一定roi区域的旋转,以防止对完整影像图像翻转破坏组织结构的分布,构成异常数据。
本方法中,图像的除噪过程是采用现有高斯滤波器对处理图像中的干扰信息进行滤除,对离散的滑动窗进行卷积,利用图像主要信息与噪声的能量差异来滤除服从正态分布的干扰信号。
本方法中,步骤(3)具体是采用现有图像数据训练方法,对图像数据集进行多次(n次)训练,初步预测各数据概率,获得初步训练数据集。
本方法中,步骤(4)具体是采用hnm泛化型数据增强方式,在对影像数据集进行扩充和逐步平衡后,通过深度网络训练模型,对初步训练数据集中的mri图像数据进行多次(n+1次)迭代训练,继而进行概率预测,确定目标图像。
本方法中,对于不平衡数据集的扩充和平衡,使用hardnegativemining(hnm)的方法,对mri或ct影像数据进行泛化能力比较强的扩充。在刚开始训练的时候由于数据不平衡,一部分属于小类别的数据倾向于被错分到大类别中,此时将这些分错的小类别数据删选出来,有针对性的把小类别数据扩充,慢慢地使数据变得平衡。同时,在不产生过拟合的情况下,通过重复采样同一张图像数据来实现对原始不平衡数据的扩充。
本方法中,深度网络训练模型采用alexnet。
本方法中,数据概率预测端还加入有数据扩充,增加模型还未涵盖到的数据分布,从而扩充模型的预测能力,采用多人投票的方式得出最终预测结果。
实施例2:如图1-6所示,本面向深度学习模型训练和学习的影像图像数据扩充方法包括以下步骤:
(1)判断数据类型,鉴别ct或mri图像数据;
(2)对于影像数据,判断是否有划定roi,并结合肿瘤区域大小,选用相应的方法完成影像数据集的构建;即采用mri基于roi的数据扩充方法,首先选取原始mri图像的感兴趣区域,然后采用常规方法针对感兴趣区域图像依次进行修剪、平移变换、旋转、除噪、重采样、镜像翻转、反射变换、pca抖动、色彩抖动处理,获得mr影像数据集。
基于roi的数据扩充是在由现有算法导出的给定感兴趣区域(regionofinterest,roi)的影像数据集中随机取块,即从原始图像感兴趣区域中任意取块得出数个修剪后的小块用作训练集的构建。针对特定图像数据修剪的修剪框保持较大尺寸,以防止随机剪裁和取块偏离roi选定框的主要内容。
图像的旋转是针对特定roi区域的旋转,以防止对完整影像图像翻转破坏组织结构的分布而构成异常数据。图像的除噪过程采用现有高斯滤波、均值滤波、中值滤波方法,对处理图像中的干扰信息进行滤除,通过傅里叶变换,利用图像主要信息与噪声的能量差异来滤除服从正态分布的干扰信号。
(3)采用基本的图像变换法对影像数据集进行训练,获得初步训练数据集。获得初步训练数据集,初步扩充后的数据集已经能使深度学习网络获得一定的性能攀升。此时,对于进行初步扩充后的数据还可以使用生成对抗网络(gan)进行进一步的更丰富的数据扩充。之后,即可将数据集送入深度学习网络模型中进行参数训练。在常用的网络模型的参数训练过程中,我们也可以使用hnm的方法,来对数据集进行进一步的平衡。
(4)对初步训练数据集进行数据扩充,再采用网络模型进行深度训练,最后进行概率预测。使用训练好的模型,针对新的一批患者数据,能有效提升网络模型的鲁棒性(对数据的泛化能力)和各类性能,如准确率,f1-score,dice系数,miou,map等。即采用hnm泛化型数据增强方式,在对影像数据集进行扩充和逐步平衡后,通过深度网络训练模型,对初步训练数据集中的mr图像数据进行多次(n+1次)迭代训练,继而进行概率预测,采用多人投票的方式得出最终预测结果,确定目标图像。
对于不平衡数据集的扩充和平衡,使用hardnegativemining(hnm)的方法,对mri或ct影像数据进行泛化能力比较强的扩充。在刚开始训练的时候由于数据不平衡,一部分属于小类别的数据倾向于被错分到大类别中,此时将这些分错的小类别数据删选出来,有针对性的把小类别数据扩充,慢慢地使数据变得平衡。同时,在不产生过拟合的情况下,通过重复采样同一张图像数据来实现对原始不平衡数据的扩充;并通过对原始图像中的对比度进行增强来扩充数据集,利用mri图像像素密度高的特点扩大不同像素间的差异。
深度网络训练模型采用segnet。
实施例3:如图1-6所示,本面向深度学习模型训练和学习的影像图像数据扩充方法包括以下步骤:
(1)判断数据类型,鉴别ct或mri图像数据;
(2)对于影像数据,判断是否有划定roi,并结合肿瘤区域大小,选用相应的方法完成影像数据集的构建;即采用mri基于roi的数据扩充方法,首先选取原始mri图像的感兴趣区域,然后采用常规方法针对感兴趣区域图像依次进行修剪、平移变换、旋转、除噪、重采样、镜像翻转、反射变换、pca抖动、色彩抖动处理,获得mr影像数据集。
基于roi的数据扩充是在由现有算法导出的给定感兴趣区域(regionofinterest,roi)的影像数据集中随机取块,即从原始图像感兴趣区域中任意取块得出数个修剪后的小块用作训练集的构建。针对特定图像数据修剪的修剪框保持较大尺寸,以防止随机剪裁和取块偏离roi选定框的主要内容。
图像的旋转是针对特定roi区域的旋转,以防止对完整影像图像翻转破坏组织结构的分布而构成异常数据。图像的除噪过程采用现有高斯滤波、均值滤波、中值滤波方法,对处理图像中的干扰信息进行滤除,通过傅里叶变换,利用图像主要信息与噪声的能量差异来滤除服从正态分布的干扰信号。
(3)采用基本的图像变换法对影像数据集进行训练,获得初步训练数据集。获得初步训练数据集,初步扩充后的数据集已经能使深度学习网络获得一定的性能攀升。此时,对于进行初步扩充后的数据还可以使用生成对抗网络(gan)进行进一步的更丰富的数据扩充。之后,即可将数据集送入深度学习网络模型中进行参数训练。在常用的网络模型的参数训练过程中,我们也可以使用hnm的方法,来对数据集进行进一步的平衡。
(4)对初步训练数据集进行数据扩充,再采用网络模型进行深度训练,最后进行概率预测。使用训练好的模型,针对新的一批患者数据,能有效提升网络模型的鲁棒性(对数据的泛化能力)和各类性能,如准确率,f1-score,dice系数,miou,map等。即采用hnm泛化型数据增强方式,在对影像数据集进行扩充和逐步平衡后,通过深度网络训练模型,对初步训练数据集中的mr图像数据进行多次(n+1次)迭代训练,继而进行概率预测,采用多人投票的方式得出最终预测结果,确定目标图像。
对于不平衡数据集的扩充和平衡,使用hardnegativemining(hnm)的方法,对mri或ct影像数据进行泛化能力比较强的扩充。在刚开始训练的时候由于数据不平衡,一部分属于小类别的数据倾向于被错分到大类别中,此时将这些分错的小类别数据删选出来,有针对性的把小类别数据扩充,慢慢地使数据变得平衡。同时,在不产生过拟合的情况下,通过重复采样同一张图像数据来实现对原始不平衡数据的扩充;并通过对原始图像中的对比度进行增强来扩充数据集,利用mri图像像素密度高的特点扩大不同像素间的差异。
深度网络训练模型采用yolo。
上面结合附图对本发明的技术内容作了说明,但本发明的保护范围并不限于所述内容,在本领域的普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下对本发明的技术内容做出各种变化,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!