一种就业数据分析与数据挖掘分析的平台系统的制作方法
本发明涉及智慧校园信息化技术领域,特别涉及一种就业数据分析与数据挖掘分析并展示的平台系统。
背景技术:
近年来,随着数据库信息量的急剧增长和存储设备的不断升级,给院校带来大量的数据,远远超出了院校对数据的分析、综合和抽取“知识”的能力。通过传统方法所获得的存在于这些数据中的信息量仅仅是整个数据库所包含信息的一小部分,即数据的表层信息,然而隐藏在这些数据之后的更重要的信息是关于这些数据的整体特征的描述及其对发展趋势的预测等信息,即知识,这是我们无法用传统方法来获取的。为了处理这些数据,开发新一代能够“自动地”、“智能地”分析处理这些海量的原始数据的工具显得非常必要。于是数据挖掘技术应运而生,并成为一个新兴的、在数据库和信息决策领域处于前沿研究的方向之一。数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识,这些知识是隐含的,事先未知的潜在有价值的信息。
目前智慧校园的数据基础设施不够完善,对数据进行深度挖掘分析的应用较少。且目前大多应用过于单一,停留在数据的展示、查询、统计等层面,应用软件不够人性化,使用麻烦。每个应用软件都需要单独注册,而且帐号密码各不相同,经常在需要用时想不到帐号密码,不得不找管理员帮助找回密码、或者干脆就不用了。不知道各应用软件中有没有需要查看的信息,但每进入一个应用系统都要手工登录很麻烦,所以没人通知就不去看了。智慧校园的建设缺乏一个统一平台,没有这个平台就无法进行数据的有效整合,更提不上数据的交叉分析与应用了。
传统的就业质量分析平台,采用传统的调研方式,主要是通过电话访问、现场走访(面谈)、通讯app等形式,进行跟踪调查,收集毕业生的就业去向以及满意度等各项数据,再基于院校提供的基础数据,经过统计、分析生成各项数据表,完成质量报告的撰写。而对就业数据的挖掘也过于单一,停留在数据的展示、查询、统计等层面。无法满足各院校对于数据监控、数据挖掘、大数据分析日益增长的需求。
技术实现要素:
本发明的目的是提供一种就业数据分析与数据挖掘分析的平台系统以解决背景技术中提及问题。
为了实现上述目的,本发明提供如下技术方案:
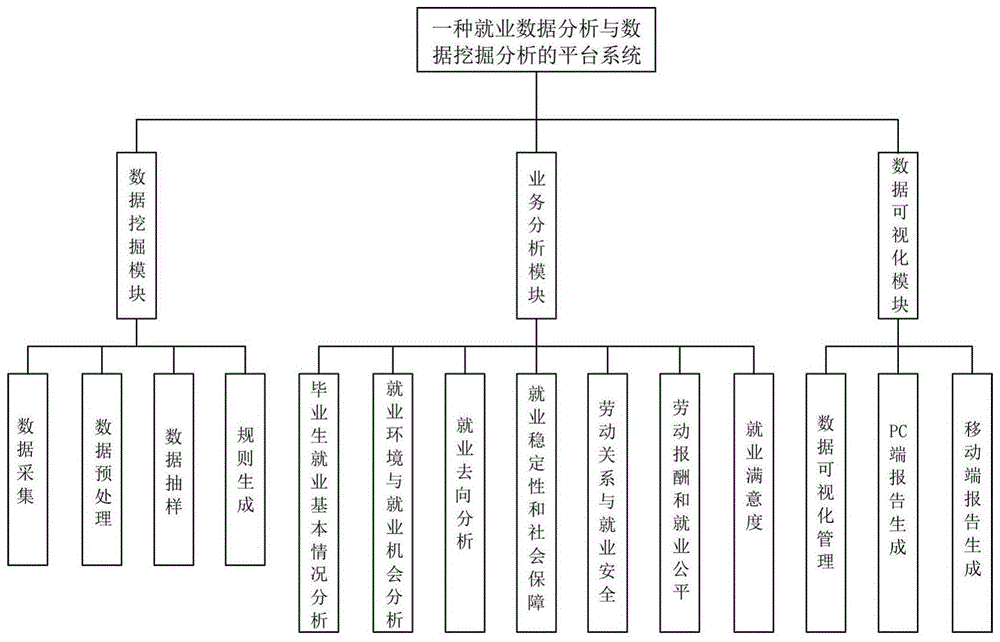
一种就业数据分析与数据挖掘分析的平台系统,包括数据挖掘模块、业务分析模块和可视化管理模块;
数据挖掘模块包括以下步骤:
a10:数据采集,定期将数据库文件和电子表格更新到系统数据库;
a20:数据预处理,将数据采集中更新到系统数据库中的信息通过数据集成录入到系统数据库内,再通过数据选择与数据清理进行筛选与清理;
a30:数据抽样,通过选取样本功能筛选出具有代表性的数据,然后基本区间计算量化属性的基本区间数目,然后对每个属性按等深分箱划分区间,并将划分信息保存,再通过数据集的转化,将抽样数据集中的每个学生记录按其取值转化为布尔型的位串,并保留在文件中,最后通过数据挖掘找出所有频集;
a40:规则生成,得到所有的频集及其支持度后,则生成规则;
业务分析模块:数据挖掘模块处理完成后,接下来就需要针对具体的业务分析挖掘需求来进行数据挖掘应用;根据业务对模型进行解释和应用;
可视化管理模块包括以下步骤:
b10:用户登录,启动可视化模块的用户操作界面,并向用户进行显示;
b20:参数配置,设置参数配置选项;
b30:数据请求,除了在本地输入和调动资源数据之外,业务客户端还可以接收用户在用户操作界面输入的基础数据请求指令,生成基础数据请求信息,发送给基础数据服务器,以获取网络侧的资源;
b40:图表生成,生成图表以及动态图像:
b50:信息发布,通过信息发布服务器将信息发布到用户客户端。
进一步地,步骤a10中,数据采集覆盖结构化数据、半结构化数据;结构化数据包括与mysql同构的数据库和异构的数据库;半结构化数据文件通过ftp、http传输。
进一步地,步骤a20中,数据库文件采用odbc添加到系统数据库中;电子表格采用编程逐条录入到系统数据库中;数据选择是从所有与业务对象有关的数据中选择适用于数据挖掘应用的数据,舍弃与数据挖掘无关的数据;数据清理是利用系统发现的错误和不一致的数据,用交互的方式来消除数据源中的噪声、孤立点数据,纠正数据中的不一致。
进一步地,所述业务分析模块中具体的业务分析包括:毕业生就业基本情况分析、就业环境与就业机会分析、就业去向分析、就业稳定和社会保障分析、劳动关系与就业安全、劳动报酬和就业公平、就业满意度。
进一步地,在步骤b10中,在业务客户端的用户操作界面上,用户可以点击用户操作界面上的选项进行相应的操作,也可以根据用户操作界面的显示输入文字信息,还可以输入数据请求指令,以调用相应的资源数据;资源数据包括:学生信息资源数据和就业信息资源数据以及第三方数据。
进一步地,在步骤b40中,动态影像的开发采用html5+reactjs+bootstrap的混合技术进行实施。
本发明的有益效果为:
采用本设计中的平台系统,能够根据院校学生的基础学籍与就业数据,对毕业学生的整体就业质量做一个分析,针对某一具体的专业、企业、行业开展针对性的数据分析,从点到面地解决问题,生成就业质量分析报告;从而有了更多的数据来源途径和获取数据手段,一份有效的就业质量分析报告能够产生巨大的价值。就业质量分析报告不仅能够对整体市场环境和宏观经济走向做判断,还可以深入到教育的每个环节、了解学校招生以及毕业学生就业的真实情况。
附图说明
图1是本发明的系统功能模块结构示意图;
图2是本发明中数据挖掘模块的功能流程图;
图3是本发明中可视化管理模块的功能流程图。
具体实施方式
以下结合附图对本发明进行进一步说明:
如图1-3所示,一种就业数据分析与数据挖掘分析的平台系统,包括数据挖掘模块、业务分析模块和可视化管理模块;
数据挖掘模块包括以下步骤:
a10:数据采集,数据采集覆盖结构化数据、半结构化数据。结构化数据包括与mysql同构的数据库和异构的数据库;半结构化数据文件通过ftp、http传输,这些数据根据其特点提取公共部分、舍去不定部分而结构化。系统定期将数据库文件(招生管理系统、学籍管理系统、就业管理系统、教务管理系统)、电子表格(学籍信息、学生实习信息、学生就业信息)中的数据更新到系统数据库。数据的采集采用网络将原数据保存到云数据库服务器。
a20:数据预处理,数据预处理模块下设数据集成、数据选择和数据清理。只要不影响数据选择,数据清理一般放在数据选择之后,可以减少数据清理量。数据集成在数据选择和数据清理之后,这样可以使数据集成时的数据量较小,提升处理效率。
将数据采集中更新到系统数据库中的信息通过数据集成录入到系统数据库内,再通过数据选择与数据清理进行筛选与清理;
数据集成:由数据采集模块收集到的数据包括应届毕业生的基本信息表、选课表、课程表、考勤表和就业信息表。其中选课表、课程表、学生基本信息表(学籍表)为数据库文件,就业信息表部分为电子表格。数据库文件采用odbc添加到系统数据库中,由于每年的课程表基本相同,至多有少许新增课程,而新增课程的编号又是顺序添加的,因此只对课程表采取更新,即试图找到课程编号大于源表中最大编号的课程并添加。又如有的学生可能有重修课程,因此在学生选课表中会多次出现<学号-课程号>相同的元祖,只是选课时间有所不同。因此会删除若干元祖而只保留一条,删除原则是:若成绩是分类属性的(通过/未通过),则找到并保留成绩通过的元祖,否则保留选课日期最近的元祖;若成绩是量化属性的,则找到值最大的元祖并保留,而其余删除。
部分就业数据表为电子表格,采用编程逐条录入到系统数据库中。录入后需要进行数据选择和清理,按各对应表将分类属性的值转化为整数值。
数据选择:数据选择是从所有与业务对象有关的数据中选择适用于数据挖掘应用的数据,舍弃与数据挖掘无关的数据。例如:学生就业信息表、学籍表和学生选课表以学号键来连接,学生选课表和课程表以课程号来连接。学生选课表包括了该年所有毕业生的选课信息,而有一部分学生由于种种原因并未就业(如继续深造、延长学制、个人问题等),数据选择过程中可以剔除该部分数据。
收集到的数据有些为重复数据,如以前已经录入的学生信息又出现在本年度表中,因此需要检测学号、身份证号码,保证数据的正确性和唯一性。有些属性和挖掘并不相关(姓名,联系方式等),在数据集成的同时将无关的属性剔除,只保留挖掘所需的有关属性,即投影操作。由于学籍表、就业信息表格式相对固定,所以在系统中设置投影条件,无需用户设置。
数据清理:利用系统发现的错误和不一致的数据,用交互的方式来消除数据源中的噪声、孤立点数据,纠正数据中的不一致。数据清理主要处理数据的空缺和错误等问题,系统首先将明显的错误数据报告给用户。(如学历、职业资格超出集合范围等),由用户决定修改或放弃该条记录。
数据因产生的途径和过程不同,其表示也可能不同,特别是分类属性的值。例如在地域对应关系表中,将“东莞”对应为“沿海城市”,而采集到的数据中出现了“广东东莞”。显然“广东东莞”和“东莞”表示相同的内容,但作为字符串二者是不同的。在将分类属性值转换为整数值时,计算机很难正确地、智能地判断,因此需要将二者的值统一,如都为“东莞”。
数据采集模块和数据预处理模块定期执行,以半年为周期,收集毕业生在校内的信息和就业信息。
a30:数据抽样,系统数据库中积累了历届毕业生的信息后容量会大大增加,从大量数据中进行挖掘不仅需要大量的执行时间,而且也不能保证比从抽样数据集中挖掘得到更多的有效规则。该模块下包含以下功能:
选取样本功能:在用户接口提供所有属性,对某些属性设定过滤条件,并按这些条件在系统数据库中选择样本数据集。
基本区间划分:当得到抽样数据集之后,计算量化属性的基本区间数目,然后对每个属性按等深分箱划分区间,并将划分信息保存。
数据集的转化:抽样数据集中的每个学生记录按其取值转化为布尔型的位串,并保留在文件中。
以上3个子模块在系统的具体实现为:
选取样本功能:根据用户给出的过滤条件选择一部分有代表性的数据,以减少挖掘的时间和空间开销。系统给出了所有属性及其可能的值,供用户选择。
基本区间划分:根据用户给出的最小支持度m和部分完全性水平k,结合数据库中的数量属性数目n,计算划分区间的数目
数据集转化:将抽样数据转化为数据文件并保存在服务器,转化方法是首先将过滤后的各表连接。按学生就业信息表中的学号查找其他表中的对应学号,选课表中该学号对应的所有课程均作为属性,就业信息表和基本信息表中的属性保持不变。对每一学号生成一个位串b=b1,b2,b3,..,bn,bi为b的子串,bi=b1,b2,..,bk(bk∈{0,1})。每个子串bi对应一个属性,bi分配的位数k取决于改属性的区间或归类的数目,即k=num。若改属性在这个元祖中的取值所对应的整数位j,该k位子串的第j位为1,其他位则均为0。同时将分配信息保存为树形结构。
数据挖掘:
由基本分区产生所有的频集:基于apriori算法,由位操作进行支持度的计数,找出所有频集。
由频集产生规则:根据规则产生的原则由频集得到规则。
具体实现方式如下:
采用项集表示数据结构,该结构包括一个字符串数据段、两个位串数据段、一个整数数据段和一个该节点类型的指针段。其中字符串数据段用字符记录为i-项集,整型数据段记录支持的元祖数目,指针段指向下一节点,布尔数据段标志该项集是否具有合并空间。位串数据段与表示学生信息的位串有相同的结构,在bits位串中,项集所涉及到的所有项的对应的位置为1,其余为0;而在mask中,项集所涉及到的所有属性的对应子串全部置为1,非涉及的属性的对应位为0。
1-频集的产生:本过程分为两部分:1、支持度计算,对分类属性的每个归类(如地域)或分类(如性别)计算支持度,若大于最小支持度则将该归类/分类及其支持度加入指针数组。2、对量化属性的分区进行合并。合并的原则是:任取频集链表中的两个节点i1和i2,比较其字符串数组数据段,若为同一属性的不同区间,且区间相邻,则计算c=i1.count+i2.count,若c/n<1/r,则在链表中加入新节点i3,同时将属性名及合并后区间的范围写入字符串数组数据段。所以合并完成后将所有不满足最小支持度的区间删除。
k-频集的产生:得到1-频集及其支持度后我们采用apriori的核心算法产生k-频集。该算法分为连接步和剪枝步,连接步用于产生候选项集,剪枝步则计算这项项集的支持度以确定是否为频集。
s40:规则生成:得到所有的频集及其支持度后,我们就可以生成规则。若a为频集,且
a40:规则生成,得到所有的频集及其支持度后,则生成规则;
业务分析模块:在数据样本抽取完成并经过预处理之后,接下来就需要针对具体的业务分析挖掘需求来进行数据挖掘应用。本发明实例中将就业数据质量分析按照七大体系进行挖掘模型的构建。即毕业生就业基本情况分析、就业环境与就业机会分析、就业去向分析、就业稳定和社会保障分析、劳动关系与就业安全、劳动报酬和就业公平、就业满意度七大业务挖掘分析模块。根据业务对模型进行解释和应用。
1、毕业生就业基本情况分析:该挖掘分析模块的模型构建是基于毕业学生的学籍信息以及就业信息。按照大类别分类、分层次的列举展示毕业生的人数分布及性别结构。下设毕业生总体规模,用于展示毕业生分布情况,包括:性别分布统计,学历分布统计,专业分布统计,生源地分布统计。
毕业生就业基本情况,根据云端备份的就业信息。计算产业分布比率、行业分布比率、单位性质分布比率。
例如根据学生的就业信息,计算从事岗位与所学专业的关联值。分析学生在选择企业时存在的问题。
2、就业环境与就业机会分析:就业率,就业人数是实际工作人数与升学、培训、参军、出国等之和,优质就业率(由学院推荐就业部门按毕业生与就业单位签订合同情况统计)就是优质就业人数除以实际工作人数x100%,对口就业率就是对口就业人数除以实际工作人数x100%,稳定就业率是稳定工作人数除以实际工作人数x100%,参保人数是购买社保人数除以实际工作人数x100%。罗列年终就业率较高的专业(前5名)和较低的专业(后5名),并分析原因。分学历层次分性别分专业罗列创业人数比例,罗列创业率较高的主要专业(前5名),分析毕业生专业与创业环境的关联问题。对口就业率分析:本实例在进行对口就业率分析是基于量化关联规则挖掘方法,找出学生的在校属性与就业属性之间的关联性。系统运行过程中,系统管理员可以对所有学院毕业生的就业信息数据进行分析,学院领导可以对其所在的学院毕业生的就业信息进行分析。在对就业信息进行分析时,用户可以根据自己需求对不同属性进行挖掘。
3、就业去向分析:毕业生毕业去向主要包括协议(合同)就业、升学、参军、创业和待就业。列出毕业生在第一、二、三产业和新兴产业就业人数占比。分析毕业生专业与产业的对应性。
4、就业稳定和社会保障分析:稳定就业指毕业生就业半年以上而且还在此单位工作状态,这种状态的人数就是稳定就业人数。(在从事一份工作半年以上而刚换了新工作视作为不稳定就业)。罗列签订就业合同人数及占比、购买社保数据及占比,比较签订合同与购买社保的数量,分析不购买社保及不签订合同的主要原因。
5、劳动关系与就业安全分析:罗列毕业生与用人单位发生劳动争议的例数、劳动争议处理案外调解例数及劳动争议处理案外调解占比,分析劳动争议主要涉及内容、发生的主要原因及劳动争议处理案外调解的情况。罗列工伤人数及占比,分析发生工伤事故的主要原因及处理情况(包括毕业生工作加班情况)。
6、劳动报酬和就业公平分析:罗列平均月薪较高的专业(前5名)和平均月薪较低的专业(后5名),并根据毕业生月平均收入与城镇单位人员月平均收入比率分析各专业毕业生在社会竞争的优劣情况。罗列离校未就业总人数,男女人数及离校未就业男女毕业生占比。分析未就业主要原因,包括身体情况、多次就业不成功及就业歧视等方面分析。
7、就业满意度分析:包括:学生对于对学校课程设置实用性的满意度,学生对学校就业创业指导的满意度,学生对学校就业推荐服务态度的满意度,学生对学校就业推荐的组织安排工作的满意度,学生对学校就业信息收集发布工作的满意度。毕业生就业满意度调查情况要分学历层次统计分析,例如:本数据从2018届毕业生总数中对3人进行了随机抽样调查填写《毕业生满意度调查表》。其中:中级班0人,高级班3人,预备技师班0人。进过统计汇总2018届毕业生总体满意度为80.00%。毕业率调查满意率=(满意+基本满意×0.8)/(满意+基本满意+不满意)×100%。
可视化管理模块包括以下步骤:
b10:用户登录,业务客户端用于根据用户输入的账号密码,启动可视化模块的用户操作界面,并向用户进行显示;在业务客户端的用户操作界面上,用户可以点击用户操作界面上的选项进行相应的操作,也可以根据用户操作界面的显示输入文字信息,还可以输入数据请求指令,以调用相应的资源数据。包括:学生信息资源数据和就业信息资源数据以及第三方数据。
b20:参数配置,参数配置选项,可以进行相应的参数配置等。通过点击操作界面上的功能按钮可以进行添加文字、添加图片、导出图片和更改系统设置等操作。添加图片可以包括添加系统的内部图片和外部图片两种模式。除此之外,还可以对系统区域图片显示的投影方式进行选择。比如通过下拉菜单可以选择亚尔伯斯和墨卡托两种投影方式。
b30:数据请求,除了在本地输入和调动资源数据之外,业务客户端还可以接收用户在用户操作界面输入的基础数据请求指令,生成基础数据请求信息,发送给基础数据服务器,以获取网络侧的资源。基础数据服务器调用的信息基础数据是基于数据属性中的时间信息选择最后更新的数据,发送给业务客户端。
b40:图表生成,生成图表以及动态图像,使用户更加直观清楚的了解信息。动态影像的开发采用html5+reactjs+bootstrap的混合技术进行实施。
b50:信息发布,通过信息发布服务器将信息发布到用户客户端,就可以将业务客户端生成的数据可视化图像显示信息对广大用户进行发布,使得广大用户都可以方便直观的查看到可视化的就业质量分析图表与报告。
以上b10为数据可视化管理,b20~b40为pc端报告生成,b50为移动端报告生成。
本模块提供的就业数据可视化模块,根据用户的具体需求,基于数据图形化解析算法,通过操作便捷的图形化界面,可快速完成各种参数的配置、定义和数据调用,使用该模块生成可视化图像的速度大大提升。
一种数据挖掘方法,包括如下步骤:
步骤1:数据采集。结构化数据包括与mysql同构的数据库和异构的数据库;半结构化数据文件通过ftp、http传输,这些数据根据其特点提取公共部分、舍去不定部分而结构化。系统定期将数据库文件(招生管理系统、学籍管理系统、就业管理系统、教务管理系统)、电子表格(学籍信息、学生实习信息、学生就业信息)中的数据更新到系统数据库。数据的采集采用网络将原数据保存到云数据库服务器。
步骤2:数据选择与预处理。数据选择是从所有与业务对象有关的数据中选择适用于数据挖掘应用的数据,舍弃与数据挖掘无关的数据。例如:学生就业信息表、学籍表和学生选课表以学号键来连接,学生选课表和课程表以课程号来连接。学生选课表包括了该年所有毕业生的选课信息,而有一部分学生由于种种原因并未就业(如继续深造、延长学制、个人问题等),数据选择过程中可以剔除该部分数据。
步骤3:业务分析应用。在数据样本抽取完成并经过预处理之后,接下来就需要针对具体的业务分析挖掘需求来进行数据挖掘应用。
一种数据可视化管理模块,步骤包括:
步骤1:用户登录,用于获取用户信息,判断权限与角色。
步骤2:数据请求与图像生成。
步骤3:信息发布。
以上所述并非对本发明的技术范围作任何限制,凡依据本发明技术实质对以上的实施例所作的任何修改、等同变化与修饰,均仍属于本发明的技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!