一种分布式自主均衡人工智能任务调度方法及系统与流程
本发明涉及人工智能算法技术领域,特别涉及一种分布式自主均衡人工智能任务调度方法及系统。
背景技术:
现有机器学习平台,同一时刻只支持对于某个特定的场景进行处理。在对于需要同时支持多种类型识别任务,以及在一个流程中需要进行多种算法组合处理的情况并没有很完善的解决方案。尤其是对于每一个单独的显卡,缺乏成熟的机制支持多模型切换;在分布式的环境下,也没有合理的充分利用集群gpu资源的灵活调度方案。
技术实现要素:
本发明的目的旨在至少解决所述技术缺陷之一。
为此,本发明的目的在于提出一种分布式自主均衡人工智能任务调度方法及系统。
为了实现上述目的,本发明的实施例提供一种分布式自主均衡人工智能任务调度方法,包括如下步骤:
(1)任务发布阶段
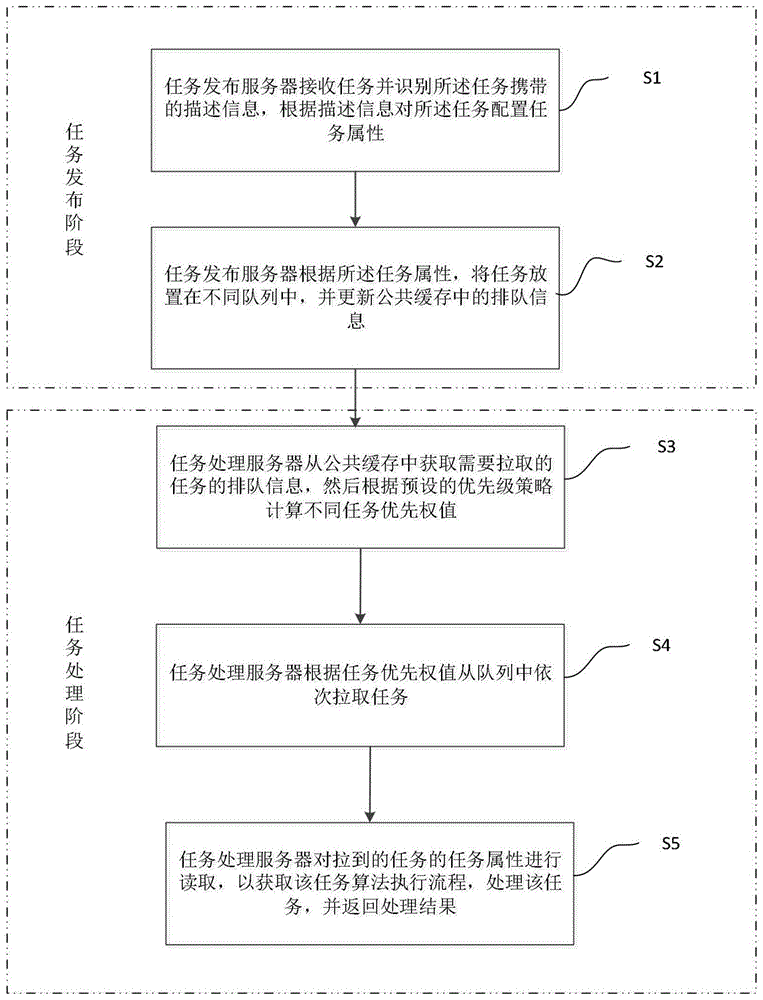
步骤s1:任务发布服务器接收任务并识别所述任务携带的描述信息,根据描述信息对所述任务配置任务属性,其中,所述任务属性记录符合该任务工作场景的算法执行流程;
步骤s2,所述任务发布服务器根据所述任务属性,将任务放置在不同队列中,并更新公共缓存中的排队信息;
(2)任务处理阶段
步骤s3,任务处理服务器从公共缓存中获取需要拉取的任务的排队信息,然后根据预设的优先级策略计算不同任务优先权值;
步骤s4,所述任务处理服务器根据任务优先权值从队列中依次拉取任务;
步骤s5,所述任务处理服务器对拉到的任务的任务属性进行读取,以获取该任务算法执行流程,处理该任务,并返回处理结果。
进一步,在所述步骤s5中,所述任务处理服务器根据所述任务属性中配置好的执行代码,执行符合该场景需要的过程,完成任务。
进一步,当队列中的任务数量超过预设值时,任务堆积信息会保存在公共缓存中,所述任务发布服务器和任务处理服务器通过所述公共缓存共享任务堆积信息,调整执行任务的策略。
进一步,所述任务发布服务器每次接收到新的任务后,将队列排队信息更新到所述公共缓存。
进一步,在所述步骤s3中,所述优先级策略根据以下条件制定:任务的数据处理量、任务所服务客户的vip等级。
本发明的实施例还提供一种分布式自主均衡人工智能任务调度系统,包括:任务发布服务器、任务处理服务器和公共缓存平台,其中,
所述任务发布服务器接收任务并识别所述任务携带的描述信息,根据描述信息对所述任务配置任务属性,其中,所述任务属性记录符合该任务工作场景的算法执行流程;然后根据所述任务属性,将任务放置在不同队列中,并更新公共缓存平台中的排队信息;
所述公共缓存平台用于存储任务的排队信息;
所述任务处理服务器用于从公共缓存平台中获取需要拉取的任务的排队信息,然后根据预设的优先级策略计算不同任务优先权值,根据任务优先权值从队列中依次拉取任务,对拉到的任务的任务属性进行读取,以获取该任务算法执行流程,处理该任务,并返回处理结果。
进一步,所述任务处理服务器还用于根据所述任务属性中配置好的执行代码,执行符合该场景需要的过程,完成任务。
进一步,当队列中的任务数量超过预设值时,任务堆积信息会保存在公共缓存中,所述任务发布服务器和任务处理服务器通过所述公共缓存共享任务堆积信息,调整执行任务的策略。
进一步,所述任务发布服务器还用于在每次接收到新的任务后,将队列排队信息更新到所述公共缓存。
进一步,所述优先级策略根据以下条件制定:任务的数据处理量、任务所服务客户的vip等级。
根据本发明实施例的分布式自主均衡人工智能任务调度方法及系统,在实际落地场景中可以自由组合使用不同的算法,同时支持多种类型的人工智能识别任务,以充分应对不同业务场景需要。同时本发明的架构设计对调度方案的配置有很大灵活性,每一块单独的显卡都能被用于多种识别任务。通过本发明,gpu的集群可以很方便的扩容或缩容。当整个系统中堆积的任务组成发生变化时,处理任务的策略也会随之自动变化,能够尽量充分的利用gpu的计算资源。本发明能够支持多种类型的识别任务,能够灵活配置调度方式,既能满足不同场景下的各种业务需求,又能充分利用每一块显卡的计算能力。本发明可以计算不同任务优先权值,选择任务进行处理,从而达到在分布式环境下均衡合理使用系统资源的目的。
本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1为根据本发明实施例的分布式自主均衡人工智能任务调度方法的流程图;
图2为根据本发明实施例的任务发布者的工作流程图;
图3为根据本发明实施例的任务处理者的工作流程图;
图4为根据本发明实施例的分布式自主均衡人工智能任务调度方法的架构图;
图5为根据本发明实施例的任务发布和任务处理的架构图;
图6为根据本发明实施例的分布式自主均衡人工智能任务调度系统的结构图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本发明提供一种分布式自主均衡人工智能任务调度方法及系统,可应用于需要人工智能算法作为在线服务的领域。
如图1和图5所示,本发明实施例的分布式自主均衡人工智能任务调度方法,包括如下步骤:
(1)任务发布阶段,参考图2所示:
步骤s1:任务发布服务器接收任务并识别任务携带的描述信息,根据描述信息对任务配置任务属性,其中,任务属性记录符合该任务工作场景的算法执行流程。
步骤s2,任务发布服务器根据任务属性,将任务放置在不同队列中,并更新公共缓存中的排队信息。
在本发明的实施例中,任务发布服务器每次接收到新的任务后,将队列排队信息更新到公共缓存。
(2)任务处理阶段,参考图3所示:
步骤s3,任务处理服务器获取本机可处理的任务列表,从公共缓存中获取需要拉取的任务的排队信息,然后根据预设的优先级策略计算不同任务优先权值,即各个任务的处理优先级。
在本发明的一个实施例中,优先级策略根据以下条件制定:任务的数据处理量、任务所服务客户的vip等级。
需要说明的是,优先级策略是由用户进行预先设置,其设置依据由用户根据需要进行制定。例如,用户可以配置优先级策略为:先对数据量大的任务进行处理,后对数据量小的任务进行处理;或者先对vip级别高的客户的任务进行处理,后对普通客户的任务进行处理。
步骤s4,任务处理服务器根据任务优先权值从队列中依次拉取任务,更新缓存中的排队信息。
步骤s5,任务处理服务器对拉到的任务的任务属性进行读取,以获取该任务算法执行流程,处理该任务,并返回处理结果。
在本步骤中,任务处理服务器根据任务属性中配置好的执行代码,执行符合该场景需要的过程,完成任务。
具体的,当任务处理服务器从缓存中读取这些信息后,依据排队信息,计算不同任务优先权值,选择任务进行处理,从而达到在分布式环境下均衡合理使用系统资源的目的。
需要说明的是,当队列中的任务数量超过预设值时,任务堆积信息会保存在公共缓存中,任务发布服务器和任务处理服务器通过公共缓存共享任务堆积信息,调整执行任务的策略。
图4为根据本发明实施例的分布式自主均衡人工智能任务调度方法的架构图。
调用端代表识别请求发送方。发送方首先将调用请求发送到负载均衡服务器。负载均衡服务器将请求发送给sv_server。sv_server将请求信息记录进redis缓存,并将请求放入消息队列mq。middle_task_client以很短的间隔向sv_server拉取识别请求。middle_task_client处理识别请求,如果有需要则调用tensorflow处理。middle_task_client将请求结果返回给sv_server。sv_server将结果记录进mysql数据库。调用方可选择拉取识别结果,或由sv_server主动返回的方式得到结果。middle_task_watcher负责监控redis中识别请求的超时请客,定期将超时任务重新放入消息队列mq。
如图6所示,本发明实施例的分布式自主均衡人工智能任务调度系统,包括:任务发布服务器1、任务处理服务器2和公共缓存平台3。
具体的,任务发布服务器1接收任务并识别任务携带的描述信息,根据描述信息对任务配置任务属性,其中,任务属性记录符合该任务工作场景的算法执行流程;然后根据任务属性,将任务放置在不同队列中,并更新公共缓存平台3中的排队信息。
在本发明的实施例中,任务发布服务器1还用于在每次接收到新的任务后,将队列排队信息更新到公共缓存平台3。
此外,任务处理服务器2还用于根据任务属性中配置好的执行代码,执行符合该场景需要的过程,完成任务。
公共缓存平台3用于存储任务的排队信息。
任务处理服务器2用于从公共缓存平台3中获取需要拉取的任务的排队信息,然后根据预设的优先级策略计算不同任务优先权值,根据任务优先权值从队列中依次拉取任务,对拉到的任务的任务属性进行读取,以获取该任务算法执行流程,处理该任务,并返回处理结果。
在本发明的一个实施例中,优先级策略根据以下条件制定:任务的数据处理量、任务所服务客户的vip等级。需要说明的是,优先级策略是由用户进行预先设置,其设置依据由用户根据需要进行制定。例如,用户可以配置优先级策略为:先对数据量大的任务进行处理,后对数据量小的任务进行处理;或者先对vip级别高的客户的任务进行处理,后对普通客户的任务进行处理。
具体的,当任务处理服务器2从缓存中读取这些信息后,依据排队信息,计算不同任务优先权值,选择任务进行处理,从而达到在分布式环境下均衡合理使用系统资源的目的。当队列中的任务数量超过预设值时,任务堆积信息会保存在公共缓存中,任务发布服务器1和任务处理服务器2通过公共缓存共享任务堆积信息,调整执行任务的策略。
根据本发明实施例的分布式自主均衡人工智能任务调度方法及系统,在实际落地场景中可以自由组合使用不同的算法,同时支持多种类型的人工智能识别任务,以充分应对不同业务场景需要。同时本发明的架构设计对调度方案的配置有很大灵活性,每一块单独的显卡都能被用于多种识别任务。通过本发明,gpu的集群可以很方便的扩容或缩容。当整个系统中堆积的任务组成发生变化时,处理任务的策略也会随之自动变化,能够尽量充分的利用gpu的计算资源。本发明能够支持多种类型的识别任务,能够灵活配置调度方式,既能满足不同场景下的各种业务需求,又能充分利用每一块显卡的计算能力。本发明可以计算不同任务优先权值,选择任务进行处理,从而达到在分布式环境下均衡合理使用系统资源的目的。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。本发明的范围由所附权利要求极其等同限定。
- 还没有人留言评论。精彩留言会获得点赞!