一种基于行动轨迹构建用户兴趣画像的方法及其数据更新方法与流程
本发明涉及用户兴趣画像技术领域,尤其涉及基于用户行动轨迹,构建用户兴趣画像的方法及其数据更新方法。
背景技术:
用户画像是一个将用户的特征和属性抽象化并以标签来表示的模型。一个标签概括了用户的一个特征,例如性别,年龄,学历,消费习惯,兴趣偏好等。用户画像技术支撑了个性化推荐,广告营销等应用,为公司或企业提供了信息基础,帮助企业精准定位到用户群体和用户需求。
构建用户兴趣画像的核心工作是给用户贴上兴趣偏好的标签,而标签的生成来自与对用户行为信息的分析。随着wifi定位,gps,gsm等定位技术的发展,用户在地理空间的位置和移动轨迹数据更容易的获取。这些丰富的轨迹数据蕴藏了有价值的用户线下行为,更能挖掘出用户偏好,比如用户常去餐馆,口味偏好,运动场所等。
但是,当前用户兴趣画像的方法多适用于对用户在互联网的线上行为数据分析,包括用户在网站的点击网页,观看视频,阅读新闻,购买商品等行为信息。这些方法无法处理用户在物理世界中的线下行为数据,时空间数据。
技术实现要素:
本发明的主要目的在于提供一种基于行动轨迹构建用户兴趣画像的方法及其数据更新方法,以通过用户线下行为轨迹来获取用户兴趣偏好数据,从而构建用户在物理世界中的兴趣画像。
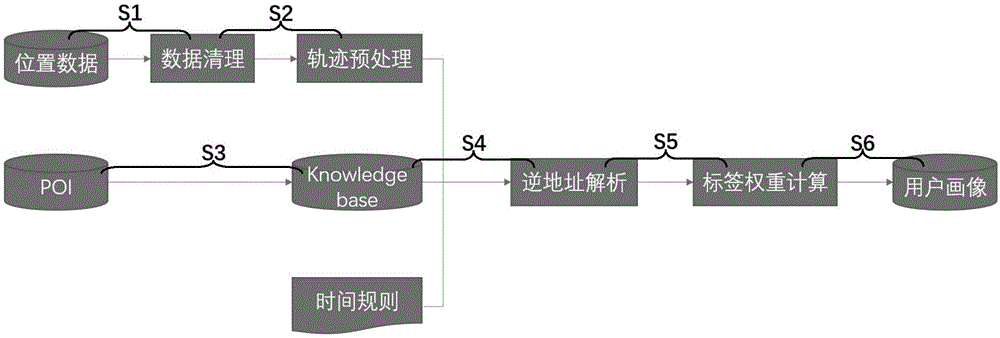
为了实现上述目的,根据本发明的一个方面,提供了一种基于行动轨迹构建用户兴趣画像的方法,步骤包括:s1采集用户位置信息,经数据处理后,获取定位点并构筑用户位置轨迹;s2聚类处理用户位置轨迹上的各个定位点,获取停留点,并根据时间序列连接各停留点,重构成事件轨迹;s3预先定义poi(points-of-interest)地理信息数据库中各个兴趣点在不同时间规则下的兴趣标签;s4对各停留点进行逆地址解析,以经poi地理信息数据库处理后,获取对应的兴趣点及兴趣标签,并计算兴趣标签初步权重;s5根据兴趣点兴趣标签的初步权重进行权重历史衰减计算,后再进行汇总计算,以获取该停留点对应的兴趣点兴趣标签权重的集合;s6根据用户事件轨迹中各停留点上权重显著的兴趣标签,侧写用户的兴趣画像。
在优选实施方式中,该用户位置信息数据处理步骤包括:对用户位置信息进行数据清理,移除错误位置信息获取位置点后;构建原始位置轨迹,根据漂移点处理规则,移除原始位置轨迹中漂移的位置点以得出定位点。
在优选实施方式中,该漂移点处理规则包括:将原始位置轨迹分割成若干子轨迹;根据各子轨迹上两位置点距离和时间计算出各子轨迹速度;根据预设速度阀值筛选子轨迹,判断出漂移位置点并移除,以获得定位点。
在优选实施方式中,该各定位点的聚类处理步骤包括:将距离或时间中至少一种相近的定位点聚集为一类,以形成停留点。
在优选实施方式中,该停留点对应多个兴趣点,根据距离阀值对兴趣点进行筛除,并赋予各兴趣点距离及时间权重中的至少一种。
在优选实施方式中,该兴趣标签初步权重计算步骤包括:获取停留点对应的各兴趣点及对应兴趣标签的集合;并根据距离和时间权重计算公式
在优选实施方式中,该权重历史衰减计算步骤包括:根据兴趣标签初步权重计算结果计算公式nweight(tagi)=weightk(tagi)*λ^(durationk)实现兴趣标签权重的衰减。
在优选实施方式中,该兴趣标签的汇总计算步骤包括:计算公式
在优选实施方式中,该时间规则为将时间细分为工作日、休息日及小时粒度,并对应设定兴趣标签,以预设在不同时段所处事件概率,以形成时间权重。
为了实现上述目的,本发明的另一个方面,还提供了一种基于行动轨迹构建用户兴趣画像的数据更新方法,步骤包括:采用如权利要求1该的基于行动轨迹构建用户兴趣画像的方法,针对用户增量的位置轨迹重复s1,s2,s4步骤获取对应增量兴趣标签及其权重后,利用s5步骤更新兴趣点兴趣标签权重的集合,以供s6步骤更新用户的兴趣画像。
通过本发明提供的基于行动轨迹构建用户兴趣画像的方法及其数据更新方法,能够利用用户线下地理空间的行为数据来挖掘用户的兴趣偏好信息,以生产出具有重要性程度和时效性的用户兴趣画像,从而更为精确的对用户进行侧写,具有较强商业利用价值。
附图说明
构成本申请的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明基于行动轨迹构建用户兴趣画像的方法步骤示意图;
图2是本发明基于行动轨迹构建用户兴趣画像的方法中兴趣点、兴趣标签及停留点结构分布概念示意图(图中数值仅为概念示例)。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
为了使本领域的技术人员更好的理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,在本领域普通技术人员没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明的保护范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“s1”、“s2”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,此外下述文中各“事件”即“停留点”,“poi”(points-of-interest)即“兴趣点”。
为利用用户线下地理空间的行为数据,来精确的挖掘出用户的兴趣偏好信息,本发明的用户兴趣画像构建方法,主要基于对用户行动轨迹数据的清理及筛选等处理,以得出相对准确的用户位置轨迹,并进一步赋予语义信息及对应兴趣权重,从而挖掘出用户行为轨迹背后所能反应出的用户兴趣情况,以供更为精确的对用户进行侧写及构建出用户准确的兴趣画像。
请参阅图1至图2因此根据本发明的实施例,提供的该基于行动轨迹构建用户兴趣画像的方法,具体步骤包括:s1采集用户位置信息,经数据处理后,获取定位点并构筑用户位置轨迹,其中该用户位置信息数据处理步骤具体包括:对用户位置信息进行数据清理,举例来说,即用户的位置信息数据是地理空间的经纬度数据和时间戳,表示为(uid,longitude,latitude,time)。其中uid是用户的唯一识别码,经过加密的id数据,防止泄露用户的数据隐私;iongitude和iatitude分别是经度和纬度,time为时间戳。第一步的清理工作中是移除错误的,属性值为空的位置数据,第二步清理时间错误的位置数据,如由于用户设备设置的原因,客户端时间会为不正确的时间,比如1970年的原点时间。这样错误时间的位置数据会被清理掉。从而移除错误位置信息获取位置点。
而后,根据用户访问该位置点的时间顺序进行顺序连接,以构建出原始位置轨迹,并根据漂移点处理规则,移除原始位置轨迹中漂移的位置点以得出定位点。具体来说,由于定位技术,比如gps的原因,定位时的位置点会出现偏差或漂移的情况,会造成定位信息的不准确。
因此为了解决此类技术问题,本发明实施例中优选使用基于速度的特征,对原始位置轨迹上的各个位置点进行漂移检测和筛除处理。其中该漂移点处理规则包括:将原始位置轨迹分割成若干子轨迹,即每一个子轨迹是一对前后相邻的位置点,这样一个含有n个点的原始位置轨迹,可分割成n-1个子轨迹的集合,而后根据各子轨迹上两位置点距离和时间计算出各子轨迹速度,并与预设的速度阀值进行比对,将超过速度阈值的子轨迹的两个位置点移除,从而形成子轨迹的筛选,以获得定位点,并根据时间序列将各定位点连接后,即可构筑出用户位置轨迹。
s2聚类处理用户位置轨迹上的各个定位点,即将距离或时间中至少一种相近的定位点聚集为一类,获取停留点,如图2所示,并根据时间序列连接各停留点,重构成事件轨迹。具体来说,从人的行为学角度分析,在一个定位点或其附近进行了一定时间的逗留,可以推测是进行了某些活动或事件,因此本发明利用聚类技术从用户的位置轨迹中提取停留点,可以为后续识别该停留点所能从事的活动或事件提供判断依据,而本发明的实施例中以采用dbscan算法为例进行说明,以对用户位置轨迹中的定位点进行聚类处理,但并未进行限制,本领域技术人员应当知晓,任何可以用于定位数据聚类计算的现有技术皆属于本发明的揭露范围。
其中该dbscan算法是一个基于密度的聚类方法,是将距离相近且范围内密度大的数据归为同一个类中。而该dbscan算法需要两个参数,eps和minpts。eps是一个距离值,指明范围的大小;minpts是数据的数量,指明范围内数据密度程度的度量。对于轨迹数据,本方法将一定空间范围和时间范围内聚集的定位点进行聚类,一个类表示该类所有的点为对同一个地区的访问和停留,表示一次事件。
而本发明还进一步对dbscan算法进行扩展,提供空间距离和时间距离的计算,即对定位点在地理空间维度和时间维度进行聚类。聚类结束后,用户会拥有一个或多个停留点,每个停留点包含多个定位点。本方法通过计算当前停留点中的各个定位点的相对位置的中心点,来表示所指的停留点的空间位置即经纬度;通过计算该停留点内各定位点的最大时间戳和最小时间戳的差来计算出这次停留点访问的停留时间。之后根据将停留点按时间序列进行连接,就可生成事件轨迹。
s3预先定义poi地理信息数据库中各个兴趣点在不同时间规则下的兴趣标签,具体来说,本发明使用p0i(points-of-interest)地理信息数据库,对各个兴趣点预先设定语义信息,即兴趣标签,从而通过将用户事件轨迹的停留点关联到对应的兴趣点上,即可为事件轨迹添加更丰富的语义信息。例如一个兴趣点为地理空间的一个实体,比如某个商店,某个公园,某个健身房等。因此兴趣点信息包含位置经纬度和标签信息。如类别为场所的类型,比如餐馆,学校,健身房等。
而本发明的实施方案中,则优选对该兴趣点预先设定标签,以便各行各业可根据用户行为轨迹做出符合自身行业需求的用户侧写画像。因此本发明以用户对地理空间中实体场所的访问行为为依据,将实体场所附带的预设标签打在用户身上。如一兴趣点类别对应是健身房,但对于医药领域该兴趣标签可以是健康类以标注对健康有要求,而对于健身塑身领域来说,该兴趣标签则可以是健美类以标注具有健身习惯,从而形成不同领域所需的侧写。
而另一方面,本发明在优选实施方式下,还可根据兴趣点的类别预先给兴趣点标注不同兴趣偏好标签。比如,某一家餐厅的类别为川菜餐馆,为该兴趣点设定餐饮偏好为川菜;某一家健身房的类别为运动,为该兴趣点设定运动偏好为健身。因此可知每个兴趣点可以被标注一个或多个兴趣偏好标签。
此外,本发明的实施方式下,还考虑到用户在不同时间段到访一个兴趣点,所发生活动的概率是不同的。比如,一家餐馆,中午12点的到访和下3点的到访发生就餐的概率不同,前者的概率更高,而后者的概率低一些。基于此假设,本实施例中还设定了该兴趣点类型的时间规则。即该时间规则为将时间细分为工作日、休息日及小时粒度,并对应设定兴趣标签,以预设在不同时段所处事件概率,以形成时间权重。从而进一步对上述兴趣标签进行更为具体的设定。以供后续进行权重运算,准确得出该兴趣点在特定时间内在进行何种事件的概率。
s4对各停留点进行逆地址解析,以经poi地理信息数据库处理后,获取对应的兴趣点及兴趣标签,并计算兴趣标签初步权重,具体来说,本实施例中以使用基于geohash的逆地址解析方法为例进行说明,但并未进行限制,本领域技术人员应当知晓,任何可以用于逆地址解析计算的现有技术皆属于本发明的揭露范围。
首先,为每个停留点的经纬度点计算geohash,而在本实施例中,该停留点是落在一定范围的空间区域,因此在该停留点内,用户对该区域内的任何兴趣点都有可能进行访问,只是距离的近远表明了对该兴趣点访问可能性的大小。
而距离近的兴趣点,用户访问的概率较距离远的兴趣点访问的概率高。基于这个概念,本实施例下考虑到运算效率及人类行为习惯,优选距离停留点中心最近的5个兴趣点为该用户在停留点访问过的兴趣点。
同时,进一步为各个兴趣点设置一个距离权重,即如果停留点与兴趣点的距离小于25米,则该兴趣点的距离权重为1;否则,该poi的距离权重为0.25。所以该停留点中被选取的各个对应的兴趣点都附带一个距离权重值。然后,根据停留点停留的起止时间范围及,对应兴趣点在该起止时间范围内发生对应活动的概率,即对应兴趣标签的概率,则还需对对应的兴趣点赋予一个时间权重。从而对该停留点关联的兴趣点赋予距离权重和时间权重。
而得出相应停留点所对应的兴趣点及兴趣标签,还不能准确的知晓用户在各停留点内进行了何种活动,因此为了准确的预测或判断出用户在事件轨迹上各个停留点所参与活动背后代表的兴趣标签之间的可能性或有效程度,需要对筛选出的兴趣标签进行权重计算。
具体来说,即对用户在事件轨迹中的每一个停留点,获取兴趣点及对应的兴趣标签,并计算各兴趣标签的距离及时间权重,如公式1所示如下:
其中tagi的权重为该poik的距离权重distweightk乘以时间权重timeweightk。一个停留点关联多个兴趣点,兴趣标签tagi的初步权重为每个兴趣点里tagi的权重的和。例如:一个停留点stop1,这样,用户事件轨迹中的每一个停留点都有一个兴趣标签集合,每个兴趣标签附带一个权重值,指明该兴趣标签在该停留点中的有效程度。
其中需要具体说明的是,该tagi为各个兴趣标签,n为停留点对应的所有兴趣点的数量,poik为这个停留点对应的第k个poi(兴趣点),exist(poik,tagi)判断poik是否包含标签tagi,如果包含,则返回值1,反之,返回值0,distweightk为poik的距离权重,timeweightk为poik的时间权重。示例:
一次事件(一个停留点),发生事件为周四中午12点,对应的附近三个poi,分别为:某个川菜馆(口味偏好标签:辣),distweight为1.0;某个湘菜馆(口味偏好标签:辣),distweight为0.25;某个扬州菜馆(口味偏好标签:清淡),distweight为1.0;中午12点对应的时间权重为0.75,那么,各标签的权重为:
标签“辣”的权重:weight(辣)=1.0*0.75+0.25*0.75=0.9375;
标签“清淡”的权重:weight(清淡)=1.0*0.75=0.75。
从而可以根据上述权重计算出该停留点上用户有较大几率是会选择吃辣菜即光顾了川菜馆,从而形成对用户兴趣的初步画像。
s5根据兴趣点兴趣标签的初步权重进行权重历史衰减计算,后再进行汇总计算,以获取该停留点对应的兴趣点兴趣标签权重的集合,原因在于,用户事件轨迹中的多个停留点在不同的时间段难免会遇到访问同一个或同一个类型的兴趣点的问题,那对应的兴趣标签会出现在多个停留点中,因此逻辑上来说每次停留点中的该兴趣标签的权重应该会不一样。因而本发明的实施例中优选考虑到用户画像系统中的一个重要特性,即兴趣标签时效性,该兴趣标签权重随着时间的增加而衰减。
因此基于上述理论,本发明提出了时间衰减因子的概念,让曾经的历史停留点产生的某个兴趣标签在当前最新日期进行时间衰减,调整其权重。从而提出该兴趣标签新权重的计算公式2如下:
nweight(tagi)=weightk(tagi)*λ^(durationk)以实现兴趣标签权重的衰减。
其中λ为给定一个时间衰减因子。那么该历史停留点中的兴趣标签当前的日期里新权重值,就会低于当时兴趣标签的权重值,实现标签权重的衰减。
tagi为某个兴趣标签,weightk(tagi)为兴趣标签tagi在第k个事件(停留点)的权重,λ为时间衰减因子,durationk为事件k日期距离当前日期的间隔天数。示例:
该兴趣标签“辣”,上一次事件(停留点)的权重如若为0.8,上次事件与当前日期间隔duration为5天,时间衰减因子为0.98,那么标签“辣”在当前日期的新权重为:nweight(辣)=0.8*0.98^5=0.72,从而形成对该兴趣标签的权重衰减计算。
最后各兴趣点标签根据上述公式1和2的处理后,对各个兴趣标签的新权重进行汇总,生成标签在当前的最新权重。计算方式如公式3:
tagi为某个兴趣标签,m为包含tagi的所有事件(停留点)的个数,k为事件(停留点)在包含tagi的所有事件(停留点)列表中的序号,weightk(tagi)为标签tagi在事件k中的权重,λ为时间衰减因子,durationk为第k个事件到当前日期的间隔天数。示例:
标签“辣”,出现在三次事件中,分别为事件1,事件2,事件3:
事件1:标签“辣”权重0.5,间隔天数duration为10;
事件2:标签“辣”权重0.6,间隔天数duration为5;
事件3:标签“辣”权重0.8,间隔天数duration为2;
时间衰减因子λ为0.98;
那么,标签“辣”的最新权重为:
weight(辣)=0.5*0.98^10+0.6*0.98^5+0.8*0.98^2=1.72,从而通过上述计算重新汇总所有停留点的兴趣标签新权重,形成各个停留点上的兴趣标签集合。
s6最终根据用户事件轨迹中各停留点上权重显著的兴趣标签,即可得知用户的兴趣倾向,从而为侧写用户的兴趣画像提供依据,具体来说,即通过对用户历史事件轨迹的计算后,存储该用户的各兴趣标签被至用户画像的存储系统内,从而即可为更上层的应用提供丰富的数据支撑,以了解用户的线下兴趣偏好。
本发明的另一个方面,还提供了一种基于行动轨迹构建用户兴趣画像的数据更新方法,步骤包括:采用如权利要求1该的基于行动轨迹构建用户兴趣画像的方法,针对用户增量的位置轨迹重复s1,s2,s4步骤获取对应增量兴趣标签及其权重后,利用s5步骤更新兴趣点兴趣标签权重的集合,以供s6步骤更新用户的兴趣画像。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
本领域技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序存储在一个存储介质中,包括若干指令用以使得单片机、芯片或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
此外,本发明实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施例的思想,其同样应当视为本发明实施例所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!