一种基于软件网络结构特征的软件可靠性度量方法与流程
本发明属于软件复杂网络领域,是一种基于软件网络结构特征的软件可靠性度量方法。
背景技术:
随着这几十年网络与信息技术的快速发展,软件作为计算机实现各项功能,辅助人们进行各项活动的载体,在当今世界各行各业中发挥着重要的作用。高效、安全的软件系统高度依赖于软件质量,因此,在软件投入使用前,对软件的质量和可靠性有清晰的了解尤为重要。
传统软件可靠性评价方法是类似于硬件的可靠性评价:1)根据用户的实际使用情况,构造操作剖面生成测试用例;2)使用生成的测试用例执行软件测试;3)收集失效间隔时间;4)选择可靠性模型进行评估。这是一个复杂而又漫长的过程,用户的实际操作情况难以预料。同时失效时间的收集和可靠性模型的选择都存在很大的不确定性。因此,软件作为一个不同于硬件的,结构清晰可见的系统。
软件是一种公认的人工复杂系统。若将软件系统中的类、子程序、构件等元素视为节点,元素间的相互关系视为为节点间的(有向)边,软件的结构实质上表现成为一种互连的复杂网络拓扑。目前一些有关软件网络的研究,已经证明软件网络具备复杂网络“无标度”和“小世界”的基本特征,大量复杂网络的分析和研究方法同样适用于软件网络。
从方法层面看,现有软件可靠性分析方法主要分为基于软件测试数据的软件可靠性增长模型(softwarereliabilitygrowthmodel,srgm),以及基于体系结构的软件可靠性分析模型(architecturebasedsoftwarereliabilitymodel,absrm)两大类型(参考文件[1])。
基于软件测试数据的软件可靠性增长模型(srgm)以软件测试失效数据作为模型基础,使用黑盒测试方法从系统失效数据分布、概率论的角度分析、评估软件整体的可靠性。到目前为止,已经有大量srgm模型及其相关改进模型,其中影响力较高的模型有:j-m模型,yamada等人的s模型,goel和okumoto的nhpp模型,广义nhpp模型,schneidewind模型,duane模型,musa的对数泊松分布模型,littlewood-vernal可靠性增长模型,langberg和singpurwalla的贝叶斯模型等等。这些模型可以通过软件测试收集失效数据,并对软件整体的可靠性进行预测。
近年来在现有模型的基础上研究者们开始逐渐关注如何更有效的测试软件,不影响软件测试效果的前提下减少测试用例以及改进软件测试流等方面。bhawana等人(参考文件[2])基于遗传算法提出一种通过识别关键路径,根据路径的关键性加权的软件路径集群,从而通过减少没有用处或冗余的测试用例来提高测试效率的方法。afzal等人(参考文件[3])则总结了18项软件测试流程改进方法及其特点,找出了他们的优缺点以及应用的范围。代码覆盖率是软件测试从业者现在采用的核心质量指标之一,masri等人(参考文件[4])对现有代码覆盖率的标准进行了总结和比较,找出各覆盖标准之间的区别并加以评价。
但是基于软件测试数据的软件可靠性模型普遍并不关心软件系统内部的模块结构与构件组成。而对于目前规模大、复杂度高、基于构件式开发的软件系统来说,单纯依靠失效数据进行可靠性评估是不够的,软件的结构特征也需要进行考虑。
软件体系结构(softwarearchitecture,sa)包含软件元素、软件元素外部的可见属性以及元素之间的关系。基于体系结构的软件可靠性分析模型(absrm)在传统srgm的基础上,分析软件体系结构,以构件或模块作为基本单位,利用软件模块的执行特点,模块之间的相互作用关系进行可靠性评估,然后针对于构件或模块之间的相关关系进行进一步的计算以获得准确的软件系统可靠性。absrm方法可以分为3类:基于状态的方法、基于路径的方法和基于增量假设的方法。
基于状态的方法(参考文件[1])一般使用构件控制流图来刻画系统结构,并假定软件的软件模块间的控制转换具有markov性质,即意味着当给定任意时刻软件模块的控制信息时,软件未来的行为就将与过去无关,然后建立相应的数学模型来预测评估系统可靠性,其软件体系结构一般由转移概率矩阵来描述。这类模型包括littlewood模型,cheung模型,laprie模型,kubat模型,gokhale模型,ledoux模型等。根据模型不同,软件系统体系结构可被建模为离散时间马尔可夫链dtmc,连续时间马尔可夫链ctmc,半马尔可夫过程smp,有向无环图,以及随机petri网等。基于路径的方法一般使用软件在执行时的路径表达作为软件体系结构的抽象,把软件的失效行为用路径失效的形式表达。而软件可能的执行路径一般通过实验测试或者相应算法确定。这类模型包括shooman模型,krishnumurthy-mathur模型,yacoub,cukie和amman模型等。增量型方法假设组成系统的每个构件的可靠性都可以使用建模,即系统可靠性也满足性质,则系统的失效密度函数可以通过将所有构件失效密度函数累加获得,而基于增量型假设的方法并不显式地考虑软件体系结构。
相对于srgm而言,absrm模型仅需要单个构件的可靠性信息,而无需进行软件系统集成测试来获取失效数据,是软件早期进行可靠性评估、提高软件质量的重要手段之一。然而absrm在实际应用中仍然存在许多问题,比如:1)马尔科夫模型中假设构件之间相互独立,即假设某一个构建的失效行为并不影响其他构建的状态,而忽略了构件之间的失效依赖关系;2)一般假设构建是顺序执行的,而忽略了构件之间的并行执行问题;3)建模往往只适用于软件生命周期的某一阶段;4)忽略了软件构建的重要性水平,即认为软件结构体系中的每一个构建是同等地位的,而不考虑软件可靠性对构建的敏感性;5)利用软件模块之间的转换概率,路径执行概率,模块平均转换时间等描述软件系统时都假设这些值是可以精确测量的,而往往实际工程中很难得到这些数值;6)大部分模型假设构建的可靠性已知,但实际工程中部分参数较难获取;7)所构建的模型会因为建模方式和建模人员而异,因此存在很大的随机性,也并不能证明模型的正确性和准确性(参考文件[5]和[6])。
软件可靠性评估能够在一定情况下比较准确的获得软件项目整体可靠性的估计值,也是近些年来软件工程实际使用的主要评估手段。然而可靠性评估的模型方法只能对软件整体的正常运行概率进行估计,无法精确的预测软件模块或代码的错误数量、分布等信息,更无法实现对软件故障的定位。
参考文献:
[1]王强.构件软件可靠性分析理论与方法研究[d].合肥工业大学,2012.
[2]bhawna,gkumar,pkbhatia,softwaretestcasereductionusinggeneticalgorithm:amodifiedapproach[j].internationaljournalofinnovativescience,engineering&technology,vol.3issue5,may2016.
[3]afzalw,alones,glocksienk,etal.softwaretestprocessimprovementapproaches[j].journalofsystems&software,2016,111(c):1-33.
[4]masriw,zaraketfa.coverage-basedsoftwaretesting:beyondbasictestrequirements[j].advancesincomputers,2016.
[5]史卫民.基于体系结构的软件可靠性评估综述[j].计算机工程与设计,2015,第2期:419-425.
[6]魏颖,张波,李丽,等.基于体系结构的软件可靠性评估[j].光学精密工程,2010,02期(2):485-490.
技术实现要素:
针对目前可靠性评估无法精确预测软件模块或代码的错误数量、分布等信息,更无法实现对软件故障的定位等问题,本发明提出一种基于软件网络结构特征的软件可靠性度量方法。
本发明提出的一种基于软件网络结构特征的软件可靠性度量方法,首先获取目标软件的完整的软件源代码,构建软件网络,其次对软件网络中的模块进行重要性计算,识别出软件中的重要模块;然后,对每个重要模块的结构复杂性、代码复杂性、接口复杂性和变更频率进行计算,再进一步计算软件的结构可靠性风险、代码可靠性风险、接口可靠性风险和变更可靠性风险;最后,综合四个方面的风险来对软件可靠性进行度量。
所述的对每个重要模块的结构复杂性、代码复杂性、接口复杂性和变更频率进行计算,具体是:
模块i的结构复杂性mci为模块的标准结构熵与基本环数、平均度的乘积,表示如下:
其中,hsi表示模块i的标准结构熵;bcli表示模块i的基本环数;adi表示模块i的平均度;
模块i的代码复杂性mcci计算如下:
其中,ni为模块i中元素的个数,cycj为元素j的圈复杂度,dj为元素j的度;
模块i的接口复杂性mici计算如下:
其中,pj为元素j中的变量数;
模块i的模块变更频率mcri计算如下:
其中,mcti为模块i在其寿命中的变化次数,li为模块i的寿命。
进一步,基于计算的所有重要模块的结构复杂性、代码复杂性、接口复杂性和变更频率,分别获得软件的结构可靠性风险、代码可靠性风险、接口可靠性风险和变更可靠性风险如下:
设软件中有n个模块,识别出n×t%个重要模块,则:
软件的结构可靠性风险mmr为:
软件的代码可靠性风险mcr为:
软件的接口可靠性风险mir为:
软件的变更可靠性风险mcrr为:
其中,ri为模块i的重要性度量值。
综合软件四个方面的可靠性风险,度量软件可靠性srr如下:
srr=α1×mmr+α2×mcr+α3×mir+α4×mcrr
其中,α1,α2,α3,α4分别为四方面可靠性风险的权重值,α1+α2+α3+α4=1。
软件可靠性srr的值越大,则软件可靠性风险越高。
本发明方法针对复杂软件系统软件,采用复杂网络的思想将软件抽象为网络,从软件网络的角度对软件模块的重要性进行度量,找到软件中的关键模块,同时根据这些关键模块的结构复杂性、代码复杂性、结构复杂性和变更效率计算模块的可靠性风险,进而综合模块的可靠性风险来度量软件整体的可靠性风险。与现有技术相比,本发明方法具有以下明显优势和积极效果:
(1)本发明方法不需要现有耗时耗力的可靠性测试,不需要执行软件可靠性测试,节省了时间和人力资源;
(2)本发明方法避免了失效时间收集,操作剖面构建以及可靠性模型选择等可能受人因影响的问题,全过程可自动化完成;
(3)本发明方法从软件的结构出发,首先从多个角度综合度量软件模块的重要性并对其排序选出重要模块,然后从结构复杂性、代码复杂性、接口复杂性和变更频率四个方面来计算重要模块的可靠性风险,解决了现有大部分模型中规避的软件模块可靠性难以评估的问题,并能够定位到高风险模块具体位置。
附图说明
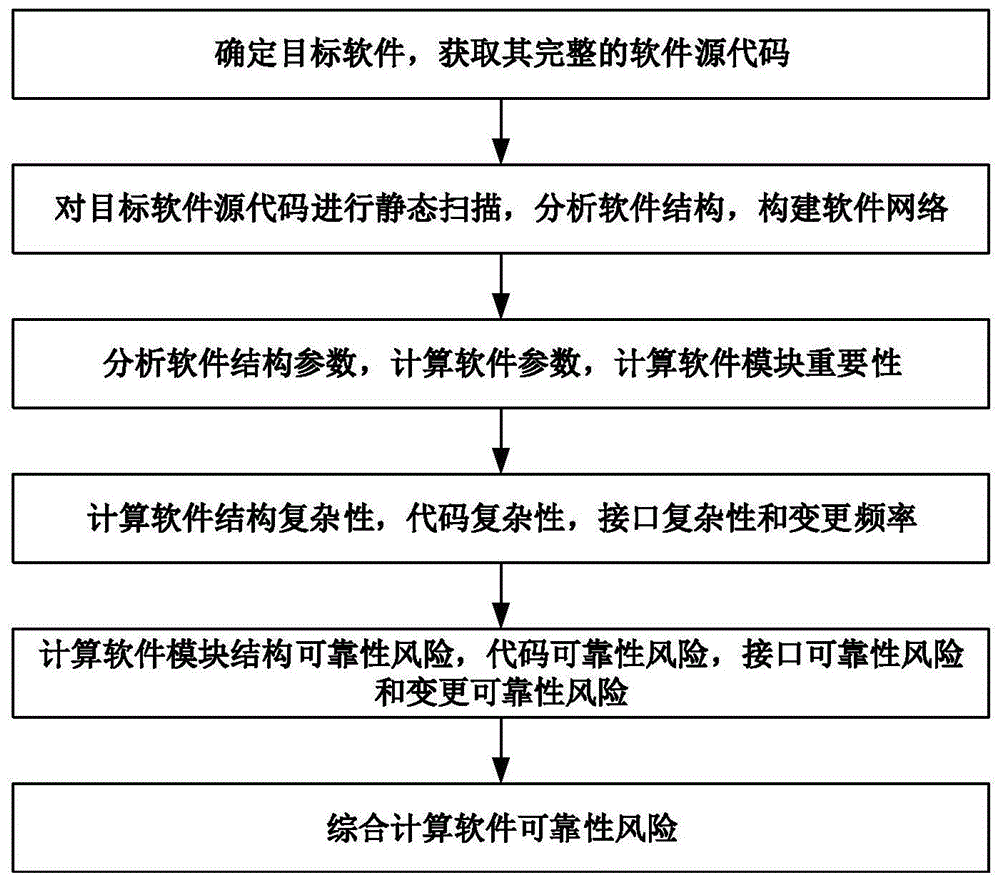
图1是本发明基于软件网络结构特征的软件可靠性度量方法的整体流程图;
图2是本发明实施例中nagioscore软件某版本的类网络图;
图3是本发明方法中重要模块度量的示意图;
图4是本发明从四个方面度量软件可靠性的示意图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图和具体实施例对本发明作进一步的详细和深入描述。
本发明针对现有技术的不足,提供一种基于软件网络结构特征的软件可靠性度量方法,包括六个步骤,如图1所示。步骤1:确定目标软件,获取其完整的软件源代码;步骤2:在步骤1的基础上对目标软件源代码进行静态扫描,分析软件结构,构建软件网络。步骤3:在步骤2的基础上分析软件结构参数,计算软件参数,计算软件模块重要性,识别出软件中的重要模块;步骤4:在步骤2的基础上计算软件中重要模块的结构复杂性、代码复杂性、接口复杂性和变更频率;步骤5:在步骤3和4的基础上计算软件模块结构可靠性风险,代码可靠性风险,接口可靠性风险和变更可靠性风险。步骤6:在步骤5的基础上综合计算软件可靠性风险。
本发明实施例以面向对象软件nagioscore某版本为例,如图2所示,为该软件的类网络图。在步骤2中利用静态代码扫描技术抽取软件程序中不同的类以及它们之间的相互作用关系,以类为节点,关系为边构建软件类网络。软件类网络g的定义形式如:g={v,e},其中v表示的类网络节点集合,v=(v1,v2,...,vn),每个节点代表一个类,n为节点个数;e表示的有向边的集合,e=(eij|i,j=1,2,...,n),有向边代表类之间的调用关系。同时,针对隶属同一个类中的函数和方法,结合与这些函数和方法存在直接关系的其他类中的函数和方法,将这些函数和方法作为节点,函数和方法间的关系作为边构成类子网络。
在步骤3中,首先根据步骤2中所建立的类子网络的基础上度量模块重要性,从而识别软件中的重要模块。此处所述的软件中的模块就是指网络中的节点。
首先从全局和局部两个方面度量模块的重要性,具体方法如图3所示,模块重要性排序公式为:
mkey={ri|maxt%(r′1<r′2<……<r′i)}
ri=αgi(cci,kci,bci,rri)+βli(si,ci,msi,aci)
其中,mkey表示软件系统中关键模块的集合,ri为软件系统中模块的重要性的评价值,ri′为按重要度排序后序号为i的模块的重要度,t是可调节参数,工程人员可以根据实际确定t的大小,gi(cci,kci,bci,rri)表示基于整体层面的软件模块重要性的评价值,li(si,ci,msi,aci)表示基于局部层面的软件模块重要性评价值,α和β分别代表对整体和局部重要性偏好和风险容忍度。模块整体和局部重要性的计算公式为:
其中,qij为模块i的参数j按照最大最小值标准化后的数值,qmax为参数j的最大值。fi(cci,kci,bci,rri)和zi(si,ci,msi,aci)分别为整体和局部参数的标准化公式。
在fi(cci,kci,bci,rri)中,j=1,2,3,4分别代表参数cci,kci,bci,rri,分别是模块i的接近数,核数,介数,逆向波及度。在zi(si,ci,msi,aci)中,j=1,2,3,4分别代表参数si,ci,msi,aci,分别是模块i的强度,聚集系数,模块规模,模块内耦合度。
下面说明模块所涉及到的全局参数和局部参数。
接近数cc:度量节点在软件网络中的位置,即模块在软件系统中的中心程度,接近数的取值越大,表示度量的模块与其他模块之间的距离越小,该模块越处于整个软件系统的核心位置,从网络信息传输与流动的角度来说,接近数越大的节点对于信息流动具有最佳的观察视野。模块i的接近数cci的计算公式如下:
其中,n表示网络中节点总数,dij为网络中任意两节点i和j之间距离,即两节点之前最少的边数。
核数kc:度量模块在软件系统中的深度。一个网络的k-核是指反复去掉网络中度值小于k的所有节点及其连接边,即k-核分解,直到网络中剩下节点的度值都不小于k时的网络子图。一个节点存在于k-核网络中,而在(k+1)-核中被移除,那么该节点的核度就为k。通过k核分解,度量模块所处的层次,模块所处的层次越深,说明模块在软件系统中所提供的功能和服务越基础,模块的重要性越强。
介数bc:反映了节点对整个网络的影响力,在软件网络中从控制信息传递的角度来说,介数越高的节点对于网络中信息的流动流动具有越高的控制力,其重要性越大。节点i的介数bci的计算公式如下:
其中,guv为从节点u到节点v的最短路径的数目,niuv为从节点u到节点v的最短路径中经过节点i的最短路径的数目。
逆向波及度rr:度量软件系统中直接或者间接调用模块i的其他模块的数量。模块的逆向波及度越大,说明模块对信息流的潜在影响力越大,该模块越重要。节点i的逆向波及度rri的计算公式如下:
其中,vi和vk表示网络中的节点i和节点k,vk→vi表示从vk指向vi的边。
强度s:节点强度反映了节点与网络中其他节点的连接情况,在软件网络中节点强度越大,表示软件模块依赖的其他的模块的数量越大,模块与邻居模块之间的交互越紧密,模块的重要性越强。节点i的强度si的计算公式如下:
其中,wij表示在加权网络中由节点i指向节点j的边的权重值,wji表示在加权网络中由节点j指向节点i的边的权重值。在网络中边的权重值是根据调用关系的频数来确定的。
聚集系数c:度量与节点直接交互的邻居节点之间的联系程度,在软件系统中,与模块i直接交互的邻居模块之间联系越紧密,在一定程度上说明模块i越重要。节点i的聚集系数ci的计算公式如下:
其中,ki表示节点i的度,即节点i的邻居个数,ei表示节点i与ki个邻居节点之间实际存在的边的数目。
模块规模ms:度量模块内软件元素的数量。
模块内耦合度ac:度量模块内部元素之间的耦合程度。节点i的模块内耦合度aci的计算公式如下:
其中,n表示模块内的软件元素的数量,ei表示这些元素之间存在的边的数量。模块规模和模块内耦合度都反映了模块自身的复杂程度。
本发明中,通常取重要性排名前20%的模块作为软件影响力最大的模块,即重要模块。
步骤4中,综合软件模块的结构复杂性,代码复杂性,接口复杂性和变更频率评价模块的整体可靠性风险,如图4所示。
其中模块i的结构复杂性mci,是度量软件模块网络结构的复杂程度,其计算公式为:
mci=hsi×bcli×adi
其中,hsi表示模块i的标准结构熵;bcli表示模块i的基本环数;adi表示模块i的平均度,软件模块在软件网络中被抽象为节点。
标准结构熵hs:反映软件网络节点的复杂度,平均度值越大,软件调用关系越复杂。
网络中的结构熵定义为
结构熵的最大值hmax=log2n,结构熵的最小值hmin=log2n-[n(n-1)]log2(n-1)。
因此标准结构熵hs为:
对于每个重要模块i,根据上面公式可以得到标准结构熵his。
平均度ad:反映软件网络节点的复杂度,平均度值越大,软件调用关系越复杂。模块i,即节点i的平均度ad计算公式如下:
公式中的ni、ei分别是模块i的子网络中的节点总数和边数量。
基本环数bcl:反映软件网络中所有构成环状结构的基本环数量的总和。环状结构会增大整个软件结构的复杂性,在软件开发过程中应该尽量避免环状结构的出现。基本环数bcl的值等于构成软件网络中所有环状结构的基础环结构的最小集合。对模块i的子网络来进行分析得到模块i的基本环数bcli。
代码复杂性mcci衡量模块内函数的方法在代码层面的平均复杂程度,若模块i中元素j的圈复杂度为cycj,模块中元素的个数为ni,元素j的度为dj,则模块i的代码复杂性值为:
其中:
圈复杂度cycj:圈复杂度是一种代码复杂度的衡量标准,用来衡量一个模块判定结构的复杂程度,数量上表现为独立线性路径条数,即合理的预防错误所需测试的最少路径条数。圈复杂度大说明程序代码可能质量低且难于测试和维护,根据经验,程序的可能错误和高的圈复杂度有着很大关系。元素j圈复杂度cycj计算公式如下:
cycj=p+1
其中p为元素j的程序中判定节点的数量。
模块i的接口复杂性mici衡量模块中函数的平均接口数目,函数拥有越多的接口,数据便越复杂,相互之间的影响和联系也会越多,元素j中的变量数为pj,则模块i的接口复杂性计算公式为:
模块变更频率mcri它衡量模块在其生命周期中的变化情况。模块越频繁的发生变化,越容易引入缺陷,从而也会增加模块的可靠性风险。模块i的模块变更频率的计算公式为:
其中mcti为模块在其寿命中的变化次数;li为模块i的寿命,即模块存在的版本数。
通过上面获得的关键模块的四方面参数,可以来获得关键模块的可靠性,发现其中的高风险模块。
结合软件模块的结构复杂性,代码复杂性,接口复杂性和变更频率四者可以综合评价软件中模块的复杂程度,同时基于:
a.关键重要模块的内部复杂性越高,那么引入缺陷的风险越大,给可靠性带来的风险越高。
b.关键重要模块的变更越频繁,那么引入缺陷的风险越高,给可靠性带来的风险越大。
这两点,在步骤5中以软件关键模块的结构复杂性,代码复杂性,接口复杂性和变更频率度量软件整体在这4个方面的可靠性风险,其中包含n个模块的软件的结构可靠性风险mmr为:
类似的,代码可靠性风险mcr为:
接口可靠性风险mir为:
变更可靠性风险mcrr为:
其中|n×t%|为n×t%的模,t∈(0,100]的实数。
步骤6综合结构可靠性风险mmr、代码可靠性风险mcr、接口可靠性风险mir及变更可靠性风险mcrr四方面可靠性风险,度量软件整体可靠性srr,其计算公式为:
srr=α1×mmr+α2×mcr+α3×mir+α4×mcrr
其中α1+α2+α3+α4=1,分别表示四方面风险的权重值。
mmr,mcr,mir,mcrr从四个方面定量的评价软件的可靠性风险问题,方便软件设计,开发,测试和使用人员了解软件在哪一方面的风险更大,以及提高软件可靠性的方向。同时根据软件实际规模,功能等调节各项风险的权重值,通过srr值定量的评价软件的可靠性风险,该值越大,则软件可靠性风险越高。
- 还没有人留言评论。精彩留言会获得点赞!