一种基于U-NET神经网络的三维医学图像配准方法与流程
本发明属于图像配准领域,主要涉及一种基于u-net神经网络的三维医学图像配准方法。
背景技术:
在医疗应用中,需要把不同时间、不同成像设备(ct、mri等)记录的同一病人相同部位的两套(三维)图像进行匹配、叠加,此过程称为图像配准。传统的配准方法主要分三类:
1.特征点配准。特征点配准方法提取图像特征点,通过相似性度量匹配特征点对,根据匹配的特征点对求得图像的空间坐标变换参数。
2.刚性配准。刚性配准方法把待配准的物体当作刚体,仅使用平移、旋转、缩放、剪切等手段,实现配准。
3.弹性配准。弹性配准把待配准的物体当作会形变的弹性物体或流体,通过求解弹性力学或流体力学方程实现配准。
其中,特征点配准受制于特征点提取方法和技术,需要较多的经验及长时间调试;刚性配准受变形手段限制,面对柔软易形变的物体(如人体内脏器官)效果不理想;而弹性配准克服了刚性配准的问题,但需要对形变场各点作优化,但其优化自由度大、计算量大、耗时长。
技术实现要素:
本发明的目的在于针对现有方法的缺陷,提供一种基于u-net神经网络的三维医学图像配准方法,能够克服传统配准方法中的技术局限,同时基于神经网络的循环优化方法可以得到更加精准的配准效果,同时速度快,比传统的配准方法的速度提高了十几倍,大大提高了图像配准的效率。
为解决上述技术问题,本发明通过以下方法方案进行实施:
一种基于u-net神经网络的三维医学图像配准方法,包括训练部分和应用部分,其中,所述训练部分包括以下步骤:
s1、对多组训练图像进行预处理,每组所述训练图像包括目标三维医学图像和对应的待配准三维医学图像;所述预处理包括归一化处理和刚性图像配准;
s2、将所述多组训练图像输入基于u-net架构的图像配准神经网络中;
s3、所述图像配准神经网络对输入的训练图像进行处理,得到形变场;所述形变场为与所述待配准三维医学图像等大的场,所述形变场包括多个三维矢量;所述三维矢量表示所述待配准三维医学图像中对应位置的体素的移动方向及移动距离;
s4、将所述形变场作用于输入的所述待配准三维医学图像进行更新,得到更新后的待配准三维医学图像;
s5、利用预设的损失函数对所述更新后的待配准三维医学图像和所述目标三维医学图像进行损失计算,得到损失函数值;
s6、将所述损失函数值输入深度学习优化器,所述深度学习优化器对所述图像配准神经网络的参数进行优化;
s7、重复执行步骤s2-s6,对所述图像配准神经网络进行多次优化,直至所述损失函数值的变化量低于预设阈值,得到优化后的图像配准神经网络;
所述应用部分包括以下步骤:将欲进行配准的目标三维医学图像和待配准三维医学图像输入所述优化后的图像配准神经网络,得到形变场,将所述形变场作用于所述待配准三维医学图像得到配准后的三维医学图像。。
进一步的,所述步骤s1中,所述预处理还包括对所述训练图像进行图像切割或填补,使得所述训练图像的尺寸符合所述图像配准神经网络的输入尺寸。
进一步的,所述步骤s1中通过调用itk中自带的刚性图像配准api进行所述刚性图像配准。
进一步的,所述步骤s3中,所述训练图像在所述图像配准神经网络中经过编码器进行下采样,所述编码器包括多层三维卷积,相邻的两层所述三维卷积间执行一次三维最大池化,经过解码器进行上采样,所述解码器包括多层三维卷积,相邻的两层三维卷积间执行一次三维转置卷积,其中,所述编码器中的三维卷积和所述解码器中的三维卷积的层数相同,且所述编码器中的三维卷积的输出图像通过连结输入至对应层的所述解码器中的三维卷积以进行图像融合。
进一步的,所述编码器和所述解码器的卷积核大小均为3×3×3;除了第一层所述三维卷积和最后一层所述三维卷积的滤波器为16个外,其余的所述三维卷积的滤波器均为32个。
进一步的,所述三维最大池化的卷积核大小为2×2×2,步长为2×2×2。
进一步的,所述步骤s5中,所述损失函数为交换关联,其公式如下:
其中,cc为交换关联,ω为两图像的重叠区域,p为所述重叠区域中的体素,n(p)为体素p的邻域,q为所述训练图像中的体素,f(q)为所述目标三维医学图像中体素q的体素值,m(φ(q))为所述更新后的待配准三维医学图像中体素q的体素值,φ为所述形变场的空间变换,∈是个小量,用于避免出现分母为0的情况。
进一步的,步骤s5中,所述损失函数为互信息计算函数,其公式如下:
mi(f,m(φ))=h(f)+h(m(φ))-h(f,m(φ))
其中,f为所述目标三维医学图像,m(φ)为所述更新后的待配准三维医学图像,φ为所述形变场的空间变换;h为熵,所述h的计算公式如下:
h(a)=-∑pr(a)lnpr(a)
其中,a为计算参数,pr(a)为a的体素值分布概率。
进一步的,所述步骤s6中的深度学习优化器为adam优化器。
进一步的,所述应用部分还包括:
将所述配准后的三维医学图像和目标三维医学图像重复输入所述优化后的图像配准神经网络进行配准并得到多个形变场,将多个形变场叠加得到最终形变场,将所述最终形变场作用于所述待配准三维医学图像实现图像配准。
与现有方法相比,本发明的有益方法效果如下:
本发明公开的一种基于u-net神经网络的三维医学图像配准方法,通过先利用训练图像对u-net架构的神经网络进行训练优化,再把训练好的模型应用于新来的图像的配准,能够克服传统配准方法中的技术局限,同时基于神经网络的循环优化方法可以得到更加精准的配准效果,同时速度快,比传统的配准方法的速度提高了十几倍,大大提高了图像配准的效率。
附图说明
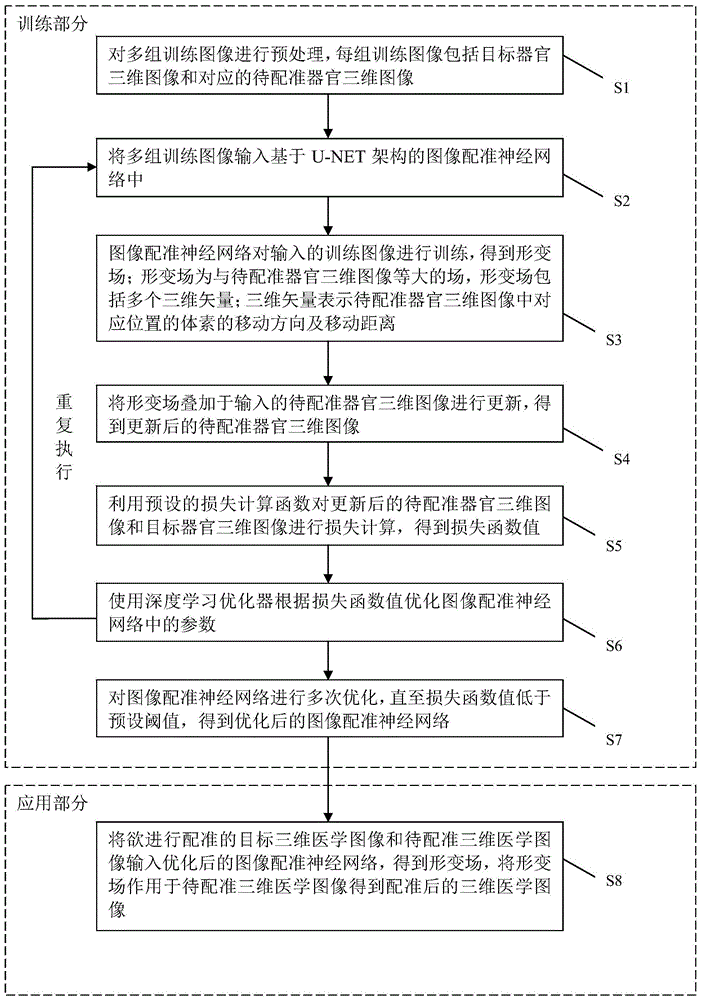
图1为本发明中具体实施方式中所述的三维医学图像配准方法的步骤示意图;
图2为本发明中具体实施方式中所述的形变场的二维示意图;
图3为本发明中具体实施方式中所述的图像配准网络的训练示意图。
具体实施方式
为了充分地了解本发明的目的、特征和效果,以下将结合附图与具体实施方式对本发明的构思、具体步骤及产生的方法效果作进一步说明。
如图1所示,本发明公开了一种基于u-net神经网络的三维医学图像配准方法,包括训练部分和应用部分,其中,训练部分包括以下步骤:
s1、对多组训练图像进行预处理,每组训练图像包括目标三维医学图像和对应的待配准三维医学图像;预处理包括归一化处理和刚性图像配准;
s2、将多组训练图像输入基于u-net架构的图像配准神经网络中;
s3、图像配准神经网络对输入的训练图像进行处理,得到形变场;形变场为与待配准三维医学图像等大的场,形变场包括多个三维矢量;三维矢量表示待配准三维医学图像中对应位置的体素的移动方向及移动距离;形变场在二维角度下的示意图如图2所示,其中每个箭头代表该位置的体素需要移动的方向和距离;
s4、将形变场作用于输入的待配准三维医学图像进行更新,得到更新后的待配准三维医学图像;
s5、利用预设的损失函数对更新后的待配准三维医学图像和目标三维医学图像进行损失计算,得到损失函数值;
s6、使用深度学习优化器根据损失函数值优化图像配准神经网络中的参数;
s7、重复执行步骤s2-s6,对图像配准神经网络进行多次优化,直至损失函数值的变化量低于预设阈值,得到优化后的图像配准神经网络;
应用部分包括以下步骤:
s8、将欲进行配准的目标三维医学图像和待配准三维医学图像输入优化后的图像配准神经网络,得到形变场,将形变场作用于待配准三维医学图像得到配准后的三维医学图像。
通过实施上述三维医学图像配准方法,通过先利用训练图像对u-net架构的神经网络进行训练优化,再把训练好的模型应用于新来的图像的配准,能够克服传统配准方法中的技术局限,同时基于神经网络的循环优化方法可以得到更加精准的配准效果,同时速度快,比传统的配准方法的速度提高了十几倍,大大提高了图像配准的效率。
具体的在上述实施例中,应用部分还包括:
将配准后的三维医学图像和目标三维医学图像重复输入优化后的图像配准神经网络进行配准并得到多个形变场,将多个形变场叠加得到最终形变场,将最终形变场作用于待配准三维医学图像实现图像配准。
通过上述步骤,操作人员在实际运用图像配准神经网络对医学图像进行配准时,若出现一次配准的效果不好,可以选择重复对医学图像进行配准以达到更精确的配准效果,在其余的训练方式中若使用这一方式会严重拖延配准工作的效率,但是由于本技术效率极高,单次配准只需要十几秒,因此这一重复配准方式仍然可以达到非常高的配准效率。
具体的在上述实施例中,步骤s1中,预处理还包括对训练图像进行图像切割或填补,使得训练图像的尺寸符合图像配准神经网络的输入尺寸。
具体的在上述实施例中,步骤s1中,调用itk中自带的刚性图像配准api进行刚性图像配准。
具体的在上述实施例中,步骤s3中,如图3,步骤s3中,训练图像在图像配准神经网络中经过编码器进行下采样,编码器包括多层三维卷积,相邻的两层三维卷积间执行一次三维最大池化,经过解码器进行上采样,解码器包括多层三维卷积,相邻的两层三维卷积间执行一次三维转置卷积,其中,编码器中的三维卷积和解码器中的三维卷积的层数相同,且编码器中的三维卷积的输出图像通过连结输入至对应层的解码器中的三维卷积以进行图像融合。具体的,编码器和解码器的卷积核大小均为3×3×3;除了第一层三维卷积和最后一层三维卷积的滤波器为16个外,其余的三维卷积的滤波器均为32个;三维最大池化的卷积核大小为2×2×2,步长为2×2×2。
具体的在上述实施例中,步骤s5中,损失函数需要根据不同的情况来决定,在实际的图像配准需求中,目标三维医学图像和待配准三维医学图像可能是同一模态的三维图像,或是不同模态的三维图像。
当目标三维医学图像和待配准三维医学图像是同一模态的三维图像时,例如两者均为ct扫描图像时,损失函数选择交换关联,其公式如下:
其中,cc为交换关联,ω为两图像的重叠区域,p为重叠区域中的体素,n(p)为体素p的邻域,q为训练图像中的体素,f(q)为目标三维医学图像中体素q的体素值,m(φ(q))为更新后的待配准三维医学图像中体素q的体素值,φ为形变场的空间变换,∈是个小量,用于避免出现分母为0的情况。
当目标三维医学图像和待配准三维医学图像是不同模态的三维图像时,例如将mr图像和ct图像进行配准时,损失函数选择互信息计算函数,其公式如下:
mi(f,m(φ))=h(f)+h(m(φ))-h(f,m(φ))
其中,f为目标三维医学图像,m(φ)为更新后的待配准三维医学图像,φ为形变场的空间变换;h为熵,h的计算公式如下:
h(a)=-∑pr(a)lnpr(a)
其中,a为计算参数,pr(a)为a的体素值分布概率,具体的,pr(a)为a在预先分好的多个体素区间中的单个体素区间内的体素分布概率。
具体的在上述实施例中,步骤s6中的深度学习优化器为adam优化器,具体的,实际情况中,工程师也可以根据实际情况选择如bgd、sgd或mbgd等基于梯度下降的优化器对神经网络进行优化。
以上详细描述了本发明的较佳具体实施例,应当理解,本领域的普通方法人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本方法领域中方法人员依本发明构思在现有方法基础上通过逻辑分析、推理或者根据有限的实验可以得到的方法方案,均应该在由本权利要求书所确定的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!