标题推断器的制作方法
电子文档(ed)(例如,字处理文档、电子表格、幻灯片、网页等)可包括最佳地描述ed内的特定内容的标题(例如,名称、题目、图例、标签、插图说明等)。通常,对用户来说,标题内的文本更易于回想。然而,在ed内,标题并不总是明确标识的(即,标示和/或标注的)。无论如何,用户仍然希望搜索ed中的标题。
技术实现要素:
一般而言,在一个方面,本发明涉及一种处理电子文档(ed)以推断ed中的标题的方法,其中所述ed包含多个字符。所述方法包括:生成ed的置标版本,所述ed的置标版本包含ed中的字符的文本样式属性、文本布局属性和文本内容信息,其中根据文本布局属性,所述字符被分组成至少第一段落和第二段落,并且文本样式属性和文本布局属性中的每个与预定加权分数关联;生成文本样式属性和文本布局属性的统计信息;对于文本样式属性和文本布局属性中的每个,根据所述预定加权分数和统计信息计算相对加权分数;对于第一段落和第二段落中的每个,根据所述统计信息和相对加权分数计算样式标准分数和布局标准分数;根据文本内容信息计算文本内容分数;和根据样式标准分数、布局标准分数和文本内容分数,计算标题置信度分数;以及对于ed,生成包括第一段落和第二段落中的每个的标题置信度分数的元数据,用于供推断ed中的标题。
一般而言,在一个方面,本发明涉及一种处理电子文档(ed)以推断ed中的标题的系统,其中所述ed包含多个字符。所述系统包括:存储器;和连接到所述存储器的计算机处理器,所述计算机处理器:生成ed的置标版本,所述ed的置标版本包含ed中的字符的文本样式属性、文本布局属性和文本内容信息,其中根据文本布局属性,所述字符被分组成至少第一段落和第二段落,并且文本样式属性和文本布局属性中的每个与预定加权分数关联;生成文本样式属性和文本布局属性的统计信息;对于文本样式属性和文本布局属性中的每个,根据所述预定加权分数和统计信息计算相对加权分数;对于第一段落和第二段落中的每个,根据所述统计信息和相对加权分数计算样式标准分数和布局标准分数;根据文本内容信息计算文本内容分数;和根据样式标准分数、布局标准分数和文本内容分数,计算标题置信度分数;以及对于ed,生成包括第一段落和第二段落中的每个的标题置信度分数的元数据,用于供推断ed中的标题。
一般而言,在一个方面,本发明涉及一种保存用于处理电子文档(ed)以推断ed中的标题的计算机可读程序代码的计算机可读记录介质,其中所述ed包含多个字符。所述计算机可读程序代码使计算机:生成ed的置标版本,所述ed的置标版本包含ed中的字符的文本样式属性、文本布局属性和文本内容信息,其中根据文本布局属性,所述字符被分组成至少第一段落和第二段落,并且文本样式属性和文本布局属性中的每个与预定加权分数关联;生成文本样式属性和文本布局属性的统计信息;对于文本样式属性和文本布局属性中的每个,根据所述预定加权分数和统计信息计算相对加权分数;对于第一段落和第二段落中的每个,根据所述统计信息和相对加权分数计算样式标准分数和布局标准分数;根据文本内容信息计算文本内容分数;和根据样式标准分数、布局标准分数和文本内容分数,计算标题置信度分数;以及对于ed,生成包括第一段落和第二段落中的每个的标题置信度分数的元数据,用于供推断ed中的标题。
根据以下的说明和附加的权利要求书,本发明的其他方面是明显的。
附图说明
图1表示按照本发明的一个或多个实施例的系统。
图2表示按照本发明的一个或多个实施例的流程图。
图3a-3k是按照本发明的一个或多个实施例的实现例子。
图4表示按照本发明的一个或多个实施例的计算系统。
具体实施方式
下面参考附图,详细说明本发明的具体实施例。考虑到一致性,附图中的相同元件用相同的附图标记表示。
在本发明的实施例的以下详细说明中,记载了许多具体细节,以便更透彻地理解本发明。然而,对本领域的技术人员来说,显然可以在没有这些具体细节的情况下实践本发明。在其他情况下,未详细说明公知的细节,以避免不必要地使说明变得复杂。
一般而言,本发明的实施例提供一种处理电子文档(ed)以推断ed中的标题(例如,名称、题目、图例、标签、插图说明等)的方法、计算机可读记录介质和系统。具体地,获得包含一行或多行文本的电子文档(ed),通过解析ed生成ed的置标版本。ed的置标版本包含构成各行文本的字符的内容、布局和样式信息。对ed的置标版本执行一个或多个处理,以把多行文本分成段落,和计算各个段落的标题置信度分数。借助计算的各个段落的标题置信度分数,即使标题未被明确标识(即,标示和/或标注),也能够推断ed的标题。
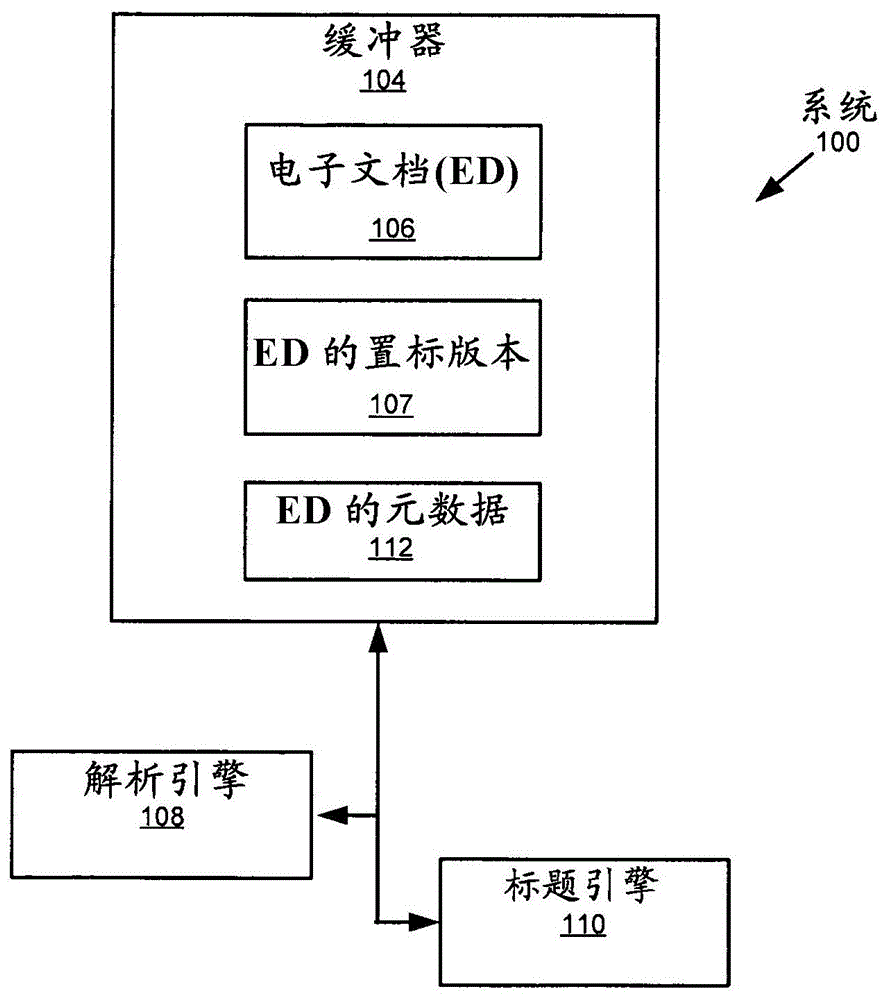
图1表示按照本发明的一个或多个实施例的系统(100)。如图1中所示,系统(100)具有多个组件,例如包括缓冲器(104)、解析引擎(108)和标题引擎(110)。各个这些组件(104、108、110)可以位于同一计算设备(例如,个人计算机(pc)、膝上型计算机、平板pc、智能电话机、多功能打印机、信息站、服务器等)上,或者位于由具有有线和/或无线段的任意规模的网络连接的不同计算设备上。这些组件中的每一个在下面讨论。
在本发明的一个或多个实施例中,缓冲器(104)可以用硬件(即,电路系统)、软件或者它们的任意组合实现。缓冲器(104)被配置成保存包括由字符组成的一行或多行文本的电子文档(ed)(106)。ed(106)还可包括图像和图形。可以从任意来源获得(例如,下载、扫描等)ed(106)。ed(106)可以是ed集合的一部分。此外,ed(106)可以是任意大小以及任意格式(例如,pdf、ooxml、odf、hml等)。
在本发明的一个或多个实施例中,解析引擎(108)可以用硬件(即,电路系统)、软件或者它们的任意组合来实现。解析引擎(108)解析ed(106),以提取ed中的字符的内容、布局和样式信息,并根据提取的信息生成ed的置标版本(107)。ed的置标版本(107)可被保存在缓冲器(104)中。
在本发明的一个或多个实施例中,样式信息可包括识别ed(106)中的每个字符的样式细节的一个或多个文本样式属性。例如,文本样式属性可包括ooxml的样式名称属性、html的标题标签、字体大小属性、粗体属性、下划线属性、字体名称属性、字体颜色属性,等等。这点在下面参考图3b和3c更详细例示。
在本发明的一个或多个实施例中,布局信息可包括内容边界框信息(例如,ed(106)的一页上的所有内容的边界框和每行文本的边界框)以及行距信息。布局信息可用于确定和/或计算识别每行文本的基本结构的一个或多个文本布局属性。例如,布局信息可包括诸如居中属性、空白符属性之类的属性。这点在下面参考图3b和3f-3h更详细例示。
在本发明的一个或多个实施例中,解析引擎(108)利用文本布局属性识别ed(106)内的一个或多个段落。在一个或多个实施例中,ed(106)中的段落可能只包括一行文本。另外,段落不一定以缩进开头。
在本发明的一个或多个实施例中,文本内容信息可包括ed(106)的一个和/或所有段落中的字符的计数(“字符计数”)。例如,段落可以是例如通过空白符,与各行文本的一个或多个其他分组分隔开来的一行或多行文本的分组。这点在下面参考图3a更详细例示。
在本发明的一个或多个实施例中,标题引擎(110)可以用硬件(即,电路系统)、软件或者它们的任意组合实现。标题引擎(110)被配置成计算ed(106)中的各个段落的标题置信度分数,并根据各个段落的标题置信度分数识别(即,推断)ed(106)中的可能标题。在一个或多个实施例中,ed(106)可能不包括标题,或者可能具有不止一个标题(即,可能不止一个段落具有匹配最高标题置信度分数)。
在本发明的一个或多个实施例中,标题引擎(110)取回文本样式属性和文本布局属性的预定加权分数的集合。每个文本样式和文本布局属性与所述集合内的预定加权分数关联(紧密联系)。所述预定加权分数由用户根据用户对哪些文本样式和文本布局属性最有可能指示标题的优先级(即,哪些文本样式和文本布局属性最常与在ed中找到的标题关联)的考虑来确定。例如,假定用户知道标题更可能包含粗体字符,而不是独特的字体颜色。粗体属性的预定加权分数将会大于字体颜色属性的预定加权分数。再例如,假定用户知道与包括粗体字符相比,标题更可能被居中。居中属性的预定加权分数将会大于粗体属性的预定加权分数。这点在下面参考图3d更详细例示。
在本发明的一个或多个实施例中,预定加权分数的集合可被保存在缓冲器(108)中,并可由用户在任意时候确定、访问和/或修改。预定加权分数也可由例如与ed关联的配置文件和/或保存在ed中的默认参数预先定义。在一个或多个实施例中,预定加权分数之和被设定为1。或者,预定加权分数之和可被设定为任意常数(例如,10、100、0.1、5等)。
在本发明的一个或多个实施例中,标题引擎(110)识别ed的置标版本(107)中的各个文本样式属性和文本布局属性,并生成各个文本样式属性和文本布局属性的统计信息。
在本发明的一个或多个实施例中,各个文本样式属性的统计信息可包括各个文本样式属性的可变性和频次。文本样式属性的可变性可根据识别出的文本样式属性的变化的数量来确定。例如,如果在ed(106)中,识别出字体大小为11、14和16的字符(即,识别出字体大小的3种变化),那么字体大小属性的可变性将会为3。再例如,假定在ed(106)中存在粗体字符。粗体属性的可变性将会为2(例如,对于粗体字符为真,和对于非粗体字符为假)。文本样式属性的频次可根据具有文本样式属性的每种变化的字符的基数来确定。例如,假定ed(106)总共具有745个字符,这745个字符中的29个字符的字体大小为16。字体大小属性为16的频次将会为29。这点在下面参考图3e更详细例示。
在本发明的一个或多个实施例中,各个文本布局属性的统计信息可包括ed(106)的一页上的所有内容的边界框的一个或多个值(即,描述ed(106)的一页上的所有内容的右边界、左边界、上边界和下边界的值)。各个文本布局属性的统计信息还可包括与各个段落关联的空白符的数量。这包括每行文本的垂直空白符(即,各行文本或文档的边缘或边界框之间的空白符)和水平空白符(即,文本行中的第一字符及最后字符与页面上的所有内容的边界框的左右边界之间的空白符)的数量。水平空白符可被分成前导空白符(即,文本行中的第一字符与页面上的所有内容的边界框的左边界之间的空白符)和尾随空白符(即,文本行中的最后字符与页面上的所有内容的边界框的右边界之间的空白符)。这点在下面参考图3a和3f-3h更详细例示。
在本发明的一个或多个实施例中,标题引擎(110)根据文本样式属性和文本布局属性的统计信息,把各个文本样式属性和文本布局属性的预定加权分数调整为相对加权分数。通过把相对加权分数设定为用户定义的值,或者利用预定加权分数以及文本样式属性和文本布局属性的统计信息计算相对加权分数,可以进行所述调整。在一个或多个实施例中,调整预定加权分数,以考虑到如统计信息所反映的,一些文本样式属性和文本布局属性对ed(106)中标题的推断来说并不引人注意(例如,不相关)。
例如,假定ed(106)是pdf文档。pdf文档不包括包含在ooxml文档中的样式名称属性。于是,样式名称属性的预定加权分数被降低(即,调整),以反映样式名称属性与ed(106)的当前格式(即,pdf)不相关。再例如,在一个或多个实施例中:可变性为1(即,它们不变化)的所有文本样式属性的预定加权分数可被设定为相对加权分数0;对于居中属性,通过按反映ed(106)中的具有最佳居中的段落(即,ed(106)中的最居中段落)的居中分数(下面例示)来缩放预定加权分数,可以计算相对加权分数;以及对于空白符属性,把相对加权分数设定成与预定加权分数相同,因为所有文档都包含空白符。这点在下面参考图3i更详细例示。
调整预定加权分数的方法不限于上面说明的例子。在一个或多个实施例中,根据统计信息考虑ed(106)中的各个文本样式属性和文本布局属性的相关性的其他方法可用于调整预定加权分数。
在本发明的一个或多个实施例中,在相对加权分数之和不等于1的情况下,标题引擎(110)缩放相对加权分数,以致相对加权分数之和等于1。这点在下面参考图3i更详细例示。或者,在相对加权分数之和不等于对于预定加权分数之和设定的常数(例如,10、100、0.1、5等)的情况下,标题引擎(110)缩放相对加权分数,以致相对加权分数之和等于设定的常数。
在本发明的一个或多个实施例中,标题引擎(110)计算ed(106)中的各个段落的居中分数。段落的居中分数识别段落在ed(106)中居中(即,该段落的各行居中)的程度。居中分数可被计算为0~1之间的值,0是不居中,1是高度居中。通常,已知标题是居中的。于是,居中的段落更有可能是ed(106)中的标题。在一个或多个实施例中,根据各行文本的尾随空白符(“trailing_white_space”)和前导空白符(“leading_white_space”),居中分数(“centering_score”)被计算为:
centering_score=1-(|leading_white_space–trailing_white_space|)÷(leading_white_space+trailing_white_space)
在一个或多个实施例中,用于计算居中属性的相对加权分数的居中分数可以是对于ed(106)中的各个段落计算的最大居中分数。
计算居中分数的方法不限于上面说明的例子。在一个或多个实施例中,考虑到ed(106)的文本布局属性的统计信息和布局信息的其他方法可用于计算居中分数。
在本发明的一个或多个实施例中,标题引擎(110)计算ed(106)的各个段落的空白符分数。段落的空白符分数是根据段落周围的空白符的数量(即,段落周围的水平空白符和垂直空白符的数量)计算的。空白符分数高指示该段落很可能被偏移,这通常与标题的已知布局关联(即,已知标题在ed正文中被偏移)。空白符分数是0~1之间的值,0是最低分数,1是最高分数。在一个或多个实施例中,一行文本的空白符分数(“white_space_score”)可被计算为:
white_space_score=horiz_white_space_score×vert_white_space_score
水平空白符分数(horiz_white_space_score)可被计算为:
horiz_white_space_score=min_max_width÷content_bounding_box_width
段落的min_max_width是包含段落的各行文本的最大水平空白符的集合的最小值。对于只有一行文本的段落,min_max_width是最大水平空白符。例如,假定段落包括3行文本,并且包含这3行文本每一行的最大水平空白符的集合为x={0.01,0.01和4.87}。集合x中的最小值0.01是该段落的min_max_width。content_bouding_box_width是包括该段落的ed的页面的内容边界框的宽度。例如,假定段落在ed的页面1上,并且ed的页面1具有左边界在0.99、右边界在7.45的内容边界框。content_boudning_box_width被设定为6.46(即,7.45-0.99)。
在一个或多个实施例中,通过找出段落的最大垂直空白符,并且比较最大垂直空白符(“max_vert_white_space”)与最小阈值(“min_threshold”)和最大阈值(“max_threshold”),可以计算垂直空白符分数(vert_white_space_score)。如果最大垂直空白符大于最大阈值,那么垂直空白符分数被设定为1。如果最大垂直空白符小于最小阈值,那么垂直空白符分数被设定为0。如果最大垂直空白符在最大阈值和最小阈值之间,那么垂直空白符分数可被计算为((max_vert_white_space-min_threshold)÷(max_threshold-min_threshold))。最大阈值可被设定为在统计信息中计算的ed(106)的平均行距的1.5倍,最小阈值可被设定为平均行距的0.5倍。例如,假定ed(106)的平均行距为0.1,那么最大阈值将为0.15,而最小阈值将为0.05。
计算空白符分数的方法不限于上面说明的例子。在一个或多个实施例中,考虑到ed(106)的文本布局属性的统计信息和布局信息的其他方法可用于计算空白符分数。
在本发明的一个或多个实施例中,标题引擎(110)计算ed(106)的各个段落的样式标准分数。样式标准得分可以是0~1之间的值,表示段落中的字符的样式与通常和标题关联的一种或多种样式(即,已知的标题样式)的匹配程度,0不太可能是标题样式,而1很可能是标题样式。样式标准分数可被计算为各个文本样式属性的最终样式分数之和。文本样式属性的最终样式分数是根据文本样式属性的评分函数(即,样式评分函数)和文本样式属性的相对加权分数计算的。
在本发明的一个或多个实施例中,为了计算文本样式属性的评分函数,标题引擎(110)可计算文本样式属性的独特性分数和/或合意性分数。在本发明的一个或多个实施例中,独特性分数反映文本样式属性的变化在ed(106)中是独特的(即,特殊的/罕见的)。对于各个段落,文本样式属性的独特性分数(“uniqueness_score”)可被计算为:
uniqueness_score=distribution_ratio×sparsity_score
在一个或多个实施例中,distribution_ratio反映文本样式属性的最常见变化在段落中出现的频次。例如,假定ed的段落a总共包括29个字符,并且这29个字符之中的29个都是粗体(即,粗体属性的变化为真)。作为(29÷29)的结果,段落a的粗体属性的分布比率为1。
在一个或多个实施例中,sparsity_score反映文本样式属性的变化在ed(106)中有多罕见。
sparsity_score=1-(num_char_variation÷total_char_ed)
例如,假定上述相同条件,并且进一步假定ed(106)具有总共745的字符计数(“total_char_ed”),这745个字符之中的38个是粗体(即,粗体属性的变化为真)。作为1-(38÷745)的结果,粗体属性的稀疏性分数为0.95。此外,作为(1×0.95)的结果,段落a的粗体属性的独特性分数为0.95。
在本发明的一个或多个实施例中,合意性分数反映文本样式属性的变化不仅是唯一的,而且与ed(106)中的文本样式属性的最常见变化相比,更可能与存在于标题中的样式关联。例如,假定ed(106)包含字体大小为11、14和16的字符。11的字体大小是字体属性的最常见变化。16的字体大小是最大字体大小,也更可能是标题的字体大小,因为通常已知标题中的文本更大。根据16的字体大小(即,desired_variation),可计算字体属性的合意性分数。各个字体大小也被赋予数值。例如,字体大小11可被赋予值11,而字体大小16可被赋予值16。
在本发明的一个或多个实施例中,对于各个段落,文本样式属性的合意性分数(“desirability_score”)可被计算为:
desirability_score=(most_com_var_para-most_com_var_ed)÷(desired_variation-most_com_var_ed)
例如,假定其中文档具有为11、14和16的字体大小,并且为16的字体大小被选为desired_variation的上述相同条件。ed(106)中的最常见字体大小(“most_com_var_ed”)为11,而段落b中的最常见变化(“most_com_var_para”)是为16的字体大小。段落b的字体属性的合意性分数将会被计算为(16-11)÷(16-11)=1。
在本发明的一个或多个实施例中,对于各个段落,文本样式属性的评分函数可被计算为:
scoring_function=uniqueness_score
在本发明的一个或多个实施例中,当对于文本样式属性计算合意性分数时,对于各个段落,文本样式属性的评分函数可被计算为:
scoring_function=uniqueness_score×desirability_score
在本发明的一个或多个实施例中,标题引擎(110)计算ed(106)的各个段落的布局标准分数。布局标准分数可以是0~1之间的值,该值表示段落的布局与一个或多个通常与标题关联的布局(即,已知标题布局)的匹配程度,0不太可能是标题布局,而1很可能是标题布局。布局标准分数可被计算为各个文本布局属性的最终布局分数之和。文本布局属性的最终布局分数是根据文本布局属性的评分函数(即,布局评分函数)和文本布局属性的相对加权分数计算的。在一个或多个实施例中,上面讨论的居中分数和空白符分数分别是居中属性和空白符属性的布局评分函数。
计算文本样式属性和文本布局属性的评分函数的方法不限于上述例子。在一个或多个实施例中,考虑文本样式属性和文本布局属性的统计信息的其他方法可用于计算文本样式属性和文本布局属性的评分函数。
在本发明的一个或多个实施例中,标题引擎(110)根据文本内容信息,计算ed(106)的各个段落的文本内容分数。文本内容分数表示基于段落的字符计数,段落是标题的可能性。通常已知标题较短(即,包含较少的字符),较高的文本内容分数指示段落较短(即,包含较少的字符),从而更可能是标题。
在本发明的一个或多个实施例中,段落的文本内容分数(“text_score”)可被计算为:
text_score=1-(par_visible_char_count÷largest_par_visible_
char_count)
par_visible_char_count表示对其计算text_score的段落的可见字符计数(即,不包括各个单词之间的空格的字符计数)。largest_par_visible_char_count表示ed(106)中的最大段落的可见字符计数。例如,假定对其计算text_score的段落包括为24的可见字符计数,并且ed(106)中的最大段落包括为191的可见字符计数。于是,段落具有为0.87的文本内容分数。
计算段落的文本内容分数的方法不限于上面说明的例子。在一个或多个实施例中,考虑到各个段落的字符计数的其他方法可被用于计算各个段落的文本内容分数。
在本发明的一个或多个实施例中,标题引擎(110)利用各个段落的样式标准分数、布局标准分数和文本内容分数,计算各个段落的标题置信度分数。在一个或多个实施例中,标题置信度分数可以是0~1之间的常数,更接近于1的标题置信度分数指示段落更可能是ed(106)中的标题。
在本发明的一个或多个实施例中,段落的标题置信度分数可被计算为:
title_confidence_score=(styling_criteria_score+layout_criteria_score)×text_score
例如,假定段落具有0.4277的样式标准分数、0.3552的布局标准分数和0.87的文本内容分数。段落的标题置信度分数为0.68,这指示该段落是ed(106)的标题的可能性更高。
计算段落的标题置信度分数的方法不限于上面说明的例子。在一个或多个实施例中,考虑文本样式属性和文本布局属性的统计信息、文本内容信息以及相对加权分数的其他方法可用于计算各个段落的标题置信度分数。
在本发明的一个或多个实施例中,标题引擎(110)生成ed(106)的元数据(112),元数据(112)包括各个段落的标题置信度分数,并把元数据(112)保存在缓冲器(104)中。或者,在一个或多个实施例中,标题引擎(110)把标题置信度分数回存到ed的置标版本(107)中。在一个或多个实施例中,元数据(112)可被保存在外部缓冲器中,并且每当需要推断ed(106)的标题时,由标题引擎(110)取回。
在本发明的一个或多个实施例中,标题引擎(110)接收来自用户的请求,以在包含搜索项(例如,出现在标题中的文本)的ed的集合内搜索的标题。标题引擎(110)解析ed的集合,以识别包含该搜索项的段落。标题引擎(110)取回集合内的包含带有搜索项的段落的ed,并比较各个段落的标题置信度分数。在比较各个段落的标题置信度分数之后,对于包含搜索项的段落,标题引擎(110)从包含确定的最大标题置信度分数的ed开始,到包含确定的最小标题置信度分数的ed为止地把取回的ed显示在显示屏幕上。例如,假定ed的集合包括文档a和文档b。文档a包括带有搜索项的段落,并且该段落的标题置信度为0.68。文档b包括带有搜索项的段落,并且该段落的标题置信度为0.07。标题引擎(110)将取回文档a和文档b两者,并在文档b之前显示文档a。
尽管系统(100)被表示成具有3个组件(104、108、110),不过在本发明的其他实施例中,系统(100)可具有更多或更少的组件。此外,可以跨组件地拆分上述各个组件的功能。此外,各个组件(104、108、110)可被多次使用,以执行迭代操作。
图2表示按照本发明的一个或多个实施例的流程图。该流程图描述推断电子文档(ed)中的标题的处理。图2中的一个或多个步骤可由上面关于图1说明的系统(100)的组件进行。在本发明的一个或多个实施例中,图2中所示的一个或多个步骤可被省略、重复和/或按照与图2中所示的顺序不同的顺序进行。因而,本发明的范围不应被视为局限于图2中所示的步骤的具体排列。
参见图2,首先,获得包括由字符组成的一行或多行文本的ed(步骤205)。所述一行或多行文本构成ed中的段落。ed还可包括图像和图形。可以从任意来源获得(例如,下载、扫描等)ed。ed可以是ed集合的一部分。此外,ed可以是任意大小以及任意格式(例如,pdf、ooxml、odf、html等)。
在步骤210,如上关于图1所述,ed被解析,以生成包括字符的文本样式属性、文本布局属性和文本内容信息的ed的置标版本。
在步骤215,如上关于图1所述,对于文本样式属性和文本布局属性,取回预定加权分数的集合。在一个或多个实施例中,各个文本样式属性和文本布局属性与集合中的预定加权分数关联(紧密联系)。
在步骤220,如上关于图1所述,利用ed的置标版本生成文本样式属性和文本布局属性的统计信息。
在步骤225,如上关于图1所述,根据预定加权分数和生成的统计信息,对每个文本样式属性和文本布局属性计算和/或设定相对加权分数。
在步骤230,如上关于图1所述,利用相对加权分数和生成的统计信息,对各个段落计算样式标准分数、布局标准分数和文本内容分数。
在步骤235,如上关于图1所述,利用各个段落的样式标准分数、布局标准分数和文本内容分数,对ed中的各个段落计算标题置信度分数。
在步骤240,如上关于图1所述,生成保存ed中的各个段落的标题置信度分数的元数据,并将其保存在保存ed的同一个缓冲器中。或者,该缓冲器可以是没有ed的不同缓冲器。在一个或多个实施例中,标题置信度分数被回存到ed的置标版本中。
图3a-3k表示按照本发明的一个或多个实施例的实现例子。在一个或多个实施例中,在图3a-3k中所示的实现例子中,应用上面关于图1说明的例证计算方法。然而,对本领域的技术人员来说,显然可以应用不同的计算方法。
图3a表示包括由字符组成的一行或多行文本的电子文档(ed)(301)。各个文本行可被分组成段落(302)。如图3a中所示,共有6个段落(302)(为了可读性目的,有些段落未被标记),包括从上至下的段落1~6。各个段落(302)可包括一行或多行文本。各个段落(302)也不要求缩进。
如图3a中所示,所有段落(302)都被围绕在ed内容边界框(303)之内。在一个或多个实施例中,ed内容边界框(303)定义ed(301)的单页中的所有内容的基本结构。ed内容边界框(303)可以由对于该页面设定的页边距定义。
如图3a中所示,文本行边界框(305)定义ed内容边界框(303)内的一行文本的基本结构。ed(301)中的每行文本包括文本行边界框(305)。每行文本还可包括前导空白符(307)和尾随空白符(309),如上关于图1所述。文本行边界框(305)和ed内容边界框(303)用于计算每行文本的前导空白符(307)和尾随空白符(309)。
图3b表示ed的置标版本(315)(“置标ed”)的一部分。如图3b中所示,置标ed(315)包括ed(301)的段落1(即,最顶部的段落)中的字符的样式信息(321)、布局信息(317)和内容信息(319)。如图3b中所示,作为定义文本(即,style_id)的各种特征或方面(即,样式)的变量(即,v:1),呈现样式信息(321)。布局信息(317)包括在图3a中所示的文本行边界框(305)的尺寸,所述尺寸用于计算ed(301)的文本布局属性。内容信息(319)包括应用有样式信息(321)的文本行中的所有字符。
图3c表示置标ed(315)的局部部分。如图3c中所示,样式信息(321)包括ed(301)中的字符的文本样式属性(例如,字体、字体大小、字体颜色、粗体)。
图3d表示包括ed(301)中的字符的文本样式属性和文本布局属性的预定加权分数的集合的表格。对本领域的普通技术人员来说,显然在ed(301)中也可找到未在该表格中显示的其他属性。如图3d中所示,通常与存在于标题中的属性(即,标题属性)关联的属性被赋予较高的预定加权分数。预定加权分数可由用户设定和修改。
图3e表示包括在图3d中所示的表格中列举的文本样式属性的统计信息的表格。如图3e中所示,提供文本样式属性的每种变化及每种变化的频次。变化信息可用于确定文本样式属性的可变性分数。变化的频次反映ed中的具有该变化的字符的数目。例如,假定ed(301)总共具有745个字符。如图3e中所示,ed(301)中的所有字符都具有相同的ooxml_style_name(即,样式名称属性)、font_name(即,字体名称属性)、和font_color(即,字体颜色属性)。
图3f表示包含图3a中所示的ed内容边界框(303)的尺寸的表格。如图3f中所示,根据ed(301)的最左侧边界和最上侧边界,计算各个值。
图3g表示包括图3a中所示的ed(301)的段落1~3的垂直间距和水平间距信息的表格。如图3g中所示,垂直间距的前值和后值分别表示在段落上方和下方的空白符的数量。水平间距的前值和后值分别表示前导空白符和尾随空白符(307、309)。图3g中所示的间隔信息可被用于把各行文本分组成段落。
在本发明的一个或多个实施例中,在图3g的表格中所示的垂直和水平间距值可根据图3b中的布局信息(317)和图3f中的ed内容边界框(303)尺寸来计算。例如,对于段号1,布局信息(317)指示段落1开始于离ed(301)的最左侧边界2.69英寸之处(即,段落1中的第一个字符开始于离ed(301)的最左侧边界2.69英寸之处)。把该值减去ed内容边界框(303)的左边界的值(即,0.99英寸),结果得到段落1的1.69英寸的前导空白符值。另外,如图3b中所示,段落1的宽度为3.11英寸。于是,段落1的最后字符距离ed(301)的最左侧边界5.8英寸(即,2.69英寸+3.11英寸)。如图3f中所示,ed内容边界框(303)的右边界终止于离ed(301)的最左侧边界7.45英寸之处。于是,作为7.45英寸减去5.8英寸的结果,段落1的尾随空白符值可被计算为1.65。
图3h表示包括图3a中所示的ed(301)中的垂直间距的总结的表格。图3h中所示的信息可用于计算布局评分函数,如上关于图1所述。
图3i表示包括图3a中所示的ed(301)中的各个文本样式属性和文本布局属性的相对加权分数的集合的表格。如图3i中所示,应用如上关于图1所述的调整预定加权分数的方法。具体地,在一个或多个实施例中:可变性为1的所有文本样式属性的预定加权分数可被设定成为0的相对加权分数;对于居中属性,通过按反映ed(106)中的具有最佳居中的段落(即,ed(106)中的最居中段落)的居中分数来缩放预定加权分数,可以计算相对加权分数;对于空白符属性,把相对加权分数设定成与预定加权分数相同,因为所有文档都包含空白符。
如图3i中所示,根据上述调整方法,一些文本样式属性现在具有为0的相对加权分数,相对加权分数之和不再等于1。相对加权分数被缩放,以致相对加权分数之和等于1。缩放的相对加权分数显示在图3i的表格的最右侧一列中。
图3j表示包括段落1-3的居中分数的表格。图3j中所示的信息可用于计算文本布局属性的布局评分函数和相对加权分数,如上关于图1所述。例如,假定段落1的居中分数是ed(106)的最大居中分数(即,段落1是ed(301)中的最居中段落(502))。段落1的居中分数被用于计算居中属性的相对加权分数。如图3i中所示,除以居中属性的预定加权分数的居中属性的相对加权分数为0.99,(即,最大居中分数)。类似地,在一个或多个实施例中,每个段落的居中分数可被设定为布局评分函数,以计算居中属性的最终布局分数。如果段落包括不止一个居中分数,那么对于布局评分函数设定段落的最小居中分数。
图3k表示包括图3a中所示的ed(301)的段落1和段落2的标题置信度分数的表格。图3k还包括为计算标题置信度分数所需的各个段落的一个或多个值(例如,样式和布局评分函数、缩放的相对加权分数、最终样式和布局分数、和文本内容分数)。如图3k中所示,段落1具有为0.68的标题置信度分数,该分数接近于1,从而指示段落1是标题的可能性高。相比之下,段落2具有为0.07的标题置信度分数,该分数接近于0,从而指示段落2不是标题的可能性高。返回参见图3a,图3a的目视检查显示段落1(即,“whydogsarebetterthancats”)看来是ed(301)的可能标题,而段落2看来是常规句子。
本发明的实施例实质上可以在任何类型的计算系统上实现,而与所使用的平台无关。例如,计算系统可以是一个或多个移动设备(例如,膝上型计算机、智能电话机、个人数字助手、平板计算机或者其他移动设备)、桌上型计算机、服务器、服务器机箱中的刀片服务器,或者至少包括为执行本发明的一个或多个实施例的最低限度处理能力、存储器、及输入和输出设备的任何其他类型的计算设备或设备。例如,如图4中所示,计算系统(400)可包括一个或多个计算机处理器(402)、关联的存储器(404)(例如,随机存取存储器(ram)、高速缓冲存储器、闪存等)、一个或多个存储设备(406)(例如,硬盘、诸如只读光盘(cd)驱动器或数字通用光盘(dvd)驱动器之类的光盘驱动器、闪存记忆棒等)、以及许多其他元件和功能。计算机处理器(402)可以是用于处理指令的集成电路。例如,计算机处理器可以是一个或多个核心,或者处理器的微核心。计算系统(400)还可包括一个或多个输入设备(410),比如触摸屏、键盘、鼠标、麦克风、触控板、电子笔或者任何其他类型的输入设备。此外,计算系统(400)可包括一个或多个输出设备(408),比如屏幕(例如,液晶显示器(lcd)、等离子体显示器、触摸屏、阴极射线管(crt)监视器、投影仪或者其他显示设备)、打印机、外部存储器或者任意其他输出设备。输出设备中的一个或多个可以与输入设备相同或不同。计算系统(400)可以通过网络接口连接(示图示),连接到网络(412)(例如,局域网(lan)、诸如因特网之类的广域网(wan)、移动网络、或者任何其他类型的网络)。输入和输出设备可以本地或远程(例如,通过网络(412))连接到计算机处理器(402)、存储器(404)和存储设备(406)。存在许多不同类型的计算系统,并且上述输入和输出设备可以采取其他形式。
呈进行本发明的实施例的计算机可读程序代码形式的软件指令可被整个或部分地,临时或永久地保存在计算机可读记录介质上,比如cd、dvd、存储设备、磁盘、磁带、闪存、物理存储器、或者任意其他计算机可读存储介质。具体地,软件指令可对应于当由处理器执行时,被配置成进行本发明的实施例的计算机可读程序代码。
此外,上述计算系统(400)的一个或多个元件可以位于远程位置,并通过网络(412)与其他元件连接。此外,可在具有多个节点的分布式系统上实现本发明的一个或多个实施例,其中本发明的各个部分可以位于分布式系统内的不同节点上。在本发明的一个实施例中,节点对应于不同的计算设备。或者,节点可对应于具有关联的物理存储器的计算机处理器。或者,节点可对应于具有共享存储器和/或资源的计算机处理器或者计算机处理器的微核心。
尽管关于数量有限的实施例,说明了本发明,不过受益于本公开,本领域的技术人员会意识到可以设计出不脱离本文中公开的本发明的范围的其他实施例。因而,本发明的范围只应由附加的权利要求书限定。
- 还没有人留言评论。精彩留言会获得点赞!