一种分布式水文模型汇流并行方法与流程
本发明涉及水资源调度
技术领域:
,尤其涉及一种分布式水文模型汇流并行方法。
背景技术:
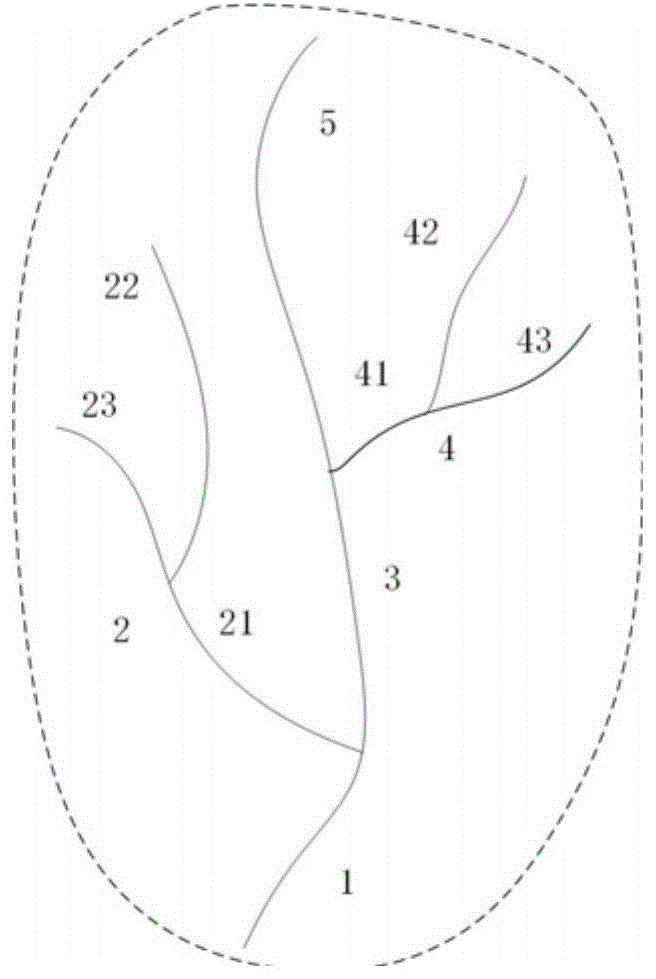
:分布式水文模型是探索和认识复杂水文循环过程和机理的有效手段,也是解决许多水文实际问题的有效工具,已经在气候变化、lucc、缺资料地区、生态水文学、水资源管理等领域的研究中发挥了重要作用。分布式水文模型具有计算密集的特点,主要体现在:(1)流域水文模拟高度复杂,包括不同下垫面的产流过程模拟以及坡面和河道汇流等,计算过程中存在许多中间变量,具有数据传输密集;(2)分布式水文模型涉及大量的栅格或者子流域数据。随着遥感技术和地理信息系统的发展,分布式水文模型能够获取到的信息越来越多,模拟的范围越来越大,同时划分的单元也越来越精细,模拟单元计算密集;(3)流域水文过程计算要求较高的时间动态性,时间步长往往为小时或分钟尺度,具有时间密集的特点。分布式水文模型对高性能计算提出了很高的要求,传统的串行计算难以满足其要求,需要并行计算技术为模型提供高速率运算。随着分布式模型模拟的尺度越来越大,分辨率越来越精细,分布式水文模拟对计算能力提出了很高的要求。其中,openmp并行框架在水文模型并行计算研究中应用较为广泛,这种并行计算技术的发展为开发并行化的分布式水文模型,解决大范围分布式水文汇流模拟的性能瓶颈问题提供了良好的条件。汇流模块由于具有依赖性的汇流机制导致无法直接并行计算。就分布式水文模型并行计算而言,许多学者对基于二叉树流域编码下的并行方法进行研究,但是存在很多水文模型河网划分应用的是pfafstetter流域编码,由于pfafstetter编码对河网划分方式与其他编码有所不同,其本身解决不了子流域之间依赖关系问题,不适用于汇流并行计算。技术实现要素:本发明的目的在于提供一种分布式水文模型汇流并行方法,从而解决现有技术中存在的前述问题。为了实现上述目的,本发明采用的技术方案如下:一种分布式水文模型汇流并行方法,包括如下步骤:s1、通过确定汇流并行计算的初始状态,即子流域上游与下游的依赖关系表,分别标注出当前子流域上游和下游子流域的编码号ix;s2、对pfafstetter流域编码进行改造,在原来一维数组(ix)单独定义子流域的基础上,将其扩展为二维数组(ix,il),其中il表示为当前子流域具有的所有上游依赖子流域以及自身在内的个数;s3、通过openmp编程对汇流模块改造,对il等于1的子流域合理分配给cpu不同的线程,进行多线程的并行计算;同时,当前流域汇流模拟结束跳出并行域后,对自身和有依赖关系的所有下游子流域的il减1;s4、循环整个线程分配过程和数组计算过程,直到所有子流域都计算完成,即所有子流域的il都等于0时停止计算,输出汇流结果。优选地,s2包括如下步骤:s201,ix按照pfafstetter流域编码规则编码赋值;s202,对pfafstetter流域编码当中表示子流域编号的一维数组编码(ix)扩展,生成二维数组(ix,il),il代表当前子流域拥有的所有上游依赖子流域个数,包括上游子流域的依赖上游子流域,以此类推,这个数目需要将当前的子流域计算在内,对il统计后将计算结果赋值。优选地,s3中,所述通过openmp编程对汇流模块改造,包括数组私有化,赋予汇流模块参数初始值,对il等于1的子流域汇流过程分配给不同线程计算,当il等于1的子流域计算完成后,跳出并行域,每条子流域的二维数组需要重新计算,对自身子流域和具有依赖关系的所有下游子流域的il都减去1。优选地,s4具体为:二维数组重新计算完毕后,再次进入并行域,对il等于1的子流域继续进行多线程并行分配和计算,循环整个分配过程和二维数组的重新计算过程,直至整个汇流模拟过程中所有的子流域的il都等于0,代表汇流模拟已经完成,输出汇流计算结果。本发明的有益效果是:本发明提供的分布式水文模型汇流并行方法,通过充分考虑汇流模块子流域之间的依赖关系在编码的角度的处理方法,对于pfafstetter流域编码的分布式水文模型汇流模块给出了并行计算的解决方案;并利用openmp编程进行并行化改造,提高了基于pfafstetter编码的分布式水文模型汇流模块的计算效率。所以,采用本发明提供的方法,解决了现有技术中,基于pfafstetter编码的分布式水文模型汇流过程无法直接利用openmp框架并行计算的问题,加快分布式水文模型汇流过程计算速度。附图说明图1是在pfafstetter流域编码规则下生成的一维编码示意图;图2是按照本发明的方法将一维编码扩展成为的二维数组示意图;图3是子流域第一次进入并行域计算后的数组重分配示意图;图4是子流域第二次进入并行域计算后的数组重分配示意图;图5是子流域第三次进入并行域计算后的数组重分配示意图;图6是汇流全过程计算完成后子流域数组示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。本发明实施例提供了一种分布式水文模型汇流并行方法,按照如下步骤进行实施:s1、通过确定汇流并行计算的初始状态,即子流域上游与下游的依赖关系表,分别标注出当前子流域上游和下游子流域的编码号ix。在步骤s1中,并行计算初始准备需要得到子流域之间的拓扑关系表,表中需要有当前子流域编号,下游子流域编号,上游若干个子流域的编号(即pfafstetter流域编码中的ix,子流域编号中0代表没有)。如下表所示:子流域编号(ix)下游子流域编号上游子流域编号1上游子流域编号21021321122232221002321003141541342434241004341005300s2、对pfafstetter流域编码进行改造,在原来一维数组(ix)单独定义子流域的基础上,将其扩展为二维数组(ix,il),其中il表示为当前子流域具有的所有上游依赖子流域个数(包含自身)。在步骤s2中,首先,ix按照pfafstetter流域编码规则编码赋值,然后,对pfafstetter流域编码当中表示子流域编号的一维数组编码(ix)扩展,生成的二维数组(ix,il),il代表当前子流域拥有的所有上游依赖子流域个数,包括上游子流域的依赖上游子流域,以此类推。这个数目需要将当前的子流域计算在内,对il统计后将计算结果赋值。例如:图1是在pfafstetter流域编码规则下生成的一维编码,可以看出子流域41的依赖上游子流域为42、43,子流域3的所有依赖上游子流域为41、42、43、5,按照本发明的方法将其扩展为二维数组,可如图2所示,子流域22、23、42、43、5没有上游依赖子流域只有自身子流域因此il等于1,二维编码表示为(22,1),(23,1),(42,1)、(43,1)、(5,1)。子流域21和41分别拥有两个依赖上游子流域再加上自身子流域因此il等于3,二维编码表示为(21,3)、(41,3)。同理,子流域3有4个依赖上游子流域加上自身子流域后il等于5,二维编码表示为(3,5)。子流域1有8个依赖上游子流域加上自身子流域后il等于9,二维编码表示为(1,9)。s3、通过openmp编程对汇流模块改造,对il等于1的子流域合理分配给cpu不同的线程,进行多线程的并行计算。同时,当前流域汇流模拟结束跳出并行域后,都要对自身和有依赖关系的所有下游子流域的il减1。步骤s3,利用openmp编程对分布式水文模型汇流模块改造,包括数组私有化(可采用如下的语句:!$ompthreadprivate),赋予汇流模块参数初始值(可采用如下的语句:!$ompcopyin),对il等于1的子流域汇流过程分配给不同线程计算(可采用如下的语句:!$ompparalleldo)等(上述的语句为本发明中,openmp框架针对fortran语言,c语言原理相似)。当il等于1的子流域计算完成后,跳出并行域,每条子流域的二维数组需要重新计算,对自身子流域和具有依赖关系的所有下游子流域的il都减去1。例如:如图2所示,第一批进入并行域即il等于1的子流域包括(22,1)、(23,1)、(42,1)、(43,1)、(5,1),并行域为这些子流域分配线程进行多线程并行计算,计算完成跳出并行域。对二维数组重新计算,每一条il等于1的流域汇流模拟结束后都要对自身和有依赖关系的所有下游子流域的il减1,从而得到图3的状态,自身减1的二维数组变为(22,0)、(23,0)、(42,0)、(43,0)、(5,0),有依赖关系的所有下游子流域il减1的二维数组变为(41,1)、(21,1)、(3,2)、(1,4)。s4、循环整个线程分配过程和数组计算过程,直到所有子流域都计算完成,即所有子流域的il都等于0时停止计算,输出汇流计算结果。步骤s4中,二维数组重新计算完毕后,再次进入并行域,对il等于1的子流域继续进行多线程并行分配和计算。由图3可以得知第二次进入并行域进行任务计算的子流域编号为(21,1),(41,1),计算完一个子流域后就对当前子流域和所有依赖下游子流域的il减1,如图4所示,得到(21,0)、(41,0),(3,1),(1,2)。同理,第三次进入并行域的子流域为(3,1),计算完后子流域本身和依赖下游子流域编码变为(3,0)、(1,1)(如图5所示)。最后,子流域(1,1)进入并行域进行计算,由于没有下游,计算结束后只将自身子流域的il减1,变为(1,0)。整个计算过程即对il等于1的子流域遍历循环计算的过程和二维数组的重新分配得过程,直至整个汇流模拟过程中所有的子流域的il都等于0(图6所示),代表汇流模拟已经完成,输出汇流计算结果。通过采用本发明公开的上述技术方案,得到了如下有益的效果:本发明提供的分布式水文模型汇流并行方法,通过充分考虑汇流模块子流域之间的依赖关系在编码的角度的处理方法,对于pfafstetter流域编码的分布式水文模型汇流模块给出了并行计算的解决方案;并利用openmp编程进行并行化改造,提高了基于pfafstetter编码的分布式水文模型汇流模块的计算效率。所以,采用本发明提供的方法,解决了现有技术中,基于pfafstetter编码的分布式水文模型汇流过程无法直接利用openmp框架并行计算的问题,加快分布式水文模型汇流过程计算速度。以上所述仅是本发明的优选实施方式,应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1