一种复杂背景下动作分类方法及分类系统与流程
本发明属于图像处理技术领域,具体涉及一种复杂背景下动作分类方法及分类系统。
背景技术:
人体动作识别是目前人工智能研究的热门领域,随着智能监控领域的不断发展,音视频监控设备可以监控人们活动的方方面面,产生了很多可以大量利用的音视频数据,通过这些音视频数据可以分析人类的行为动作,通过人体动作的幅度、面部表情和语音声调判断人体的动作剧烈程度,避免潜在的犯罪活动。
人体的动作剧烈程度基本上分为剧烈、平静和柔和三个方面。现有的研究领域主要单独依靠采集的图像识别人体的动作行为,对于真正人体由于情感波动而引起的动作剧烈程度的判定并不十分准确。现有的大部分人体动作识别方法基本上是在单一视角下采集的图像上进行分析处理,并不能有效描述一个人的动作行为状态,容易造成识别不准的情况出现。并且图像之间没有联系,没有有效的时域或频域关联信息。
现有技术中关于人体动作识别方法,有通过卷积神经网络获取人体动作光流图和视频的卷积特征图,最后通过支持向量机分类得出人体动作识别结果。该方法只是在单一视角下的图像上进行处理,并且没有结合视频图像的时域信息、多维视角图像和人的情感波动情况,对于人体特征的描述不准确。
除此之外,还有通过深度学习提取肢体动作全局特征信息,利用开发的tensorflow,python等软件对肢体动作进行分类,并映射到对应的高兴、伤心和中性情绪中去。该方法也只是在单一视角下的图像上进行处理,并且没有结合视频图像的时域信息、多维视角图像和人的情感波动情况,对于人体特征的描述不准确。容易受到图像环境影响,方法鲁棒性不强。
目前已有的方法主要是根据单一视角图像进行人体动作行为的识别,易受环境变化影响,方法的鲁棒性低并且准确度不高。
技术实现要素:
针对现有技术存在的问题,本发明的目的是提供一种复杂背景下动作分类方法与动作分类系统,具体涉及一种基于超像素分割、深度学习和脑电波信号复杂背景下动作分类方法及动作分类系统。解决现有技术中单一视角图像进行人体动作行为的识别,易受环境变化影响,方法的鲁棒性低并且准确度不高的问题。
为达到上述目的,本发明采用如下技术方案:
一种复杂背景下动作分类方法,包括以下步骤:
步骤1,采用下采样加速方法对动作时序图像进行超像素分割得到超像素分割结果;根据超像素分割结果对动作时序图像进行下采样得到视觉概要图像;采用深度学习语义分割网络对视觉概要图像进行图像分割得到动作掩模图像;
步骤2,采用cnn类网络提取步骤1中的动作时序图像的时刻图像特征与动作掩模图像的时刻图像特征得到时刻特征图谱,然后采用rnn类网络按时间顺序提取时刻特征图谱的时段图像特征得到结合了图像时序信息的特征图谱;
步骤3,同时采集步骤1中人体在对应时段做出动作时的脑电波形图像,采用rnn类网络按照时间顺序提取脑电波形图像的图像特征得到脑电波形特征图谱;
步骤4,对步骤2中结合了图像时序信息的特征图谱和步骤3中脑电波形特征图谱进行特征图谱合并得到合并后的特征图谱,然后采用cnn类网络对合并后的特征图谱进行分类得出动作分类结果。
具体地,步骤1中的下采样加速方法包括像素1:1条件下采样加速方法和像素1:3条件下采样加速方法。
进一步地,步骤1中根据超像素分割结果对动作时序图像进行下采样包括:
s1,将超像素分割结果结合深度学习平均池化方法,计算每一块超像素中所有像素点的灰度平均值;
s2,将s1中计算得到的灰度平均值重新再赋值给所对应的每一块超像素中的像素点,生成视觉概要图像。
一种复杂背景下动作分类系统,包括本发明所述的复杂背景下动作分类方法。
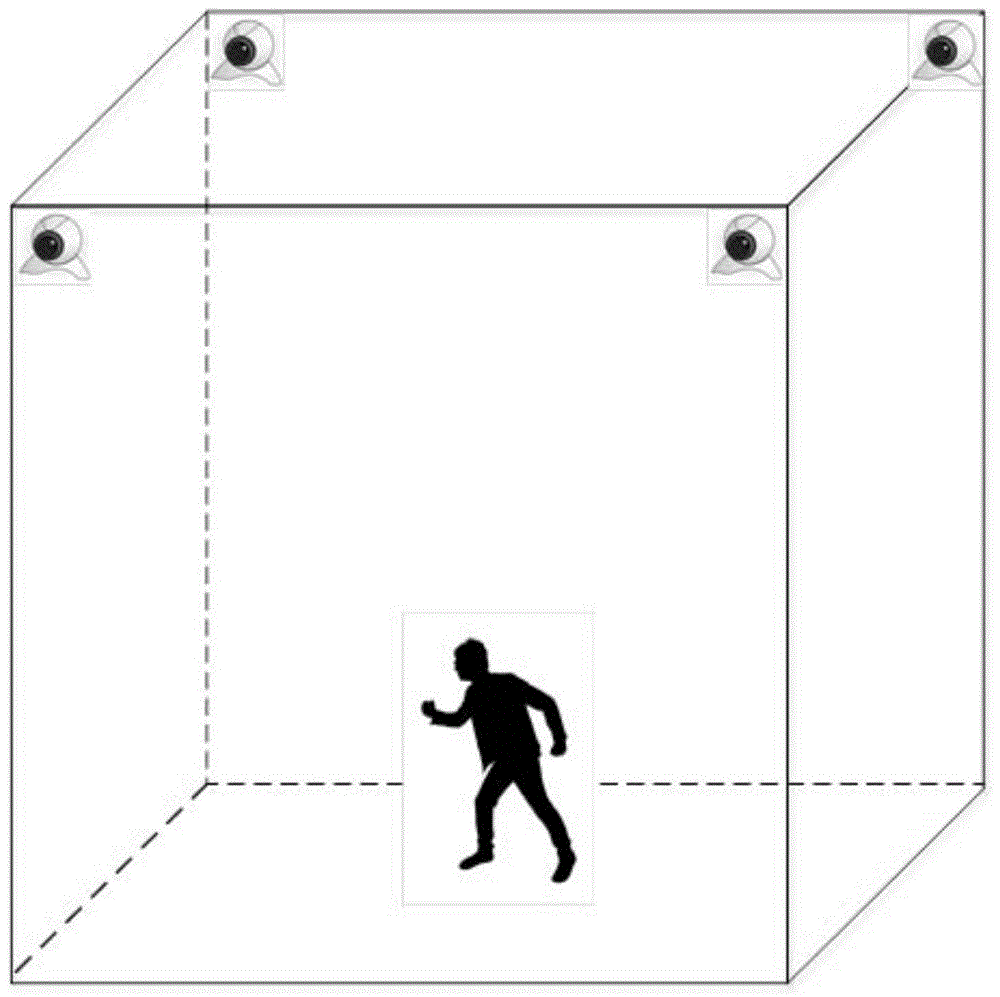
进一步地,包括动作信息采集系统,所述的动作信息采集系统包括摄像头,所述的摄像头至少有4个。
本发明与现有技术相比具有以下的有益效果:
1、本发明通过采集四个视角的人体动作图像,对四个视角的动作图像进行分类处理,提高了方法的鲁棒性,克服了在面对多维视角情况下其他方法的不稳定性;
2、本发明通过图像分割,提取出人体动作区域,增强了图像感兴趣区域,使得在面对复杂背景下影响人体动作区域占比小的问题得到有效解决;
3、本发明提出了一种结合超像素和深度学习网络图像分割方法,使得图像分割更加注重边缘信息,提高图像分割准确率;
4、本发明通过结合人体脑电信号,将脑电波形特征和人体动作图像相结合,相对于单独的依靠图像分析人体动作更加有效和准确,提高了人体动作分类效果;
5、本发明在进行图像分析时添加了时域信息,通过rnn类网络提取整个时段图像特征,提高了人体动作分类的准确性和有效性。
附图说明
图1是本发明人体动作信息采集的示意图;
图2是本发明采集到的人体图像;
图3是本发明图像超像素分割结果图;
图4是本发明中像素1:1条件下采样示意图;
图5是本发明中像素1:1条件下采样加速方法子区域像素聚类情况示意图;
图6是本发明中像素1:3条件下采样示意图;
图7是本发明中像素1:3条件下采样加速方法子区域中心像素聚类情况示意图;
图8是本发明中人体动作掩模图像;
图9是实施例1中人体动作的最终分类结果示意图。
以下结合说明书附图和具体实施方式对本发明做具体说明。
具体实施方式
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
遵从上述技术方案,如图1至9所示,本发明公开了一种复杂背景下动作分类方法及动作分类系统。具体是基于超像素分割、深度学习和脑电波信号复杂背景下人体动作分类方法及动作分类系统。
脑机交互是人类大脑与外部环境之间建立一种新型的信息交流与控制通道,实现人脑与外部设备之间的直接交互。脑机设备通过收集大脑的脑电来对人体行为进行分析。人体动作剧烈程度和脑电的波形状态有直接联系。通过采集四个视角的人体动作图像实现多维视角描述同一动作特征,并且通过基于超像素的图像分割,得出主要人体特征区域,关联图像时域信息和在该时域阶段产生的脑电波形,根据rnn类深度学习网络提取相应特征图谱,并将相应特征图谱通过cnn类深度学习网络再进行高维特征提取,最后将得到的高维特征进行分类得出结果,该方法提高了动作分类的准确性和鲁棒性。
主要包括以下步骤:步骤1,采用下采样加速方法对动作时序图像进行超像素分割得到超像素分割结果;根据超像素分割结果对动作时序图像进行下采样得到视觉概要图像;采用深度学习语义分割网络对视觉概要图像进行图像分割得到动作掩模图像;
步骤2,采用cnn类网络提取步骤1中的动作时序图像的时刻图像特征与动作掩模图像的时刻图像特征得到时刻特征图谱,然后采用rnn类网络按时间顺序提取时刻特征图谱的时段图像特征得到结合了图像时序信息的特征图谱;
步骤3,同时采集步骤1中人体在对应时段做出动作时的脑电波形图像,采用rnn类网络按照时间顺序提取脑电波形图像的图像特征得到脑电波形特征图谱;
步骤4,对步骤2中结合了图像时序信息的特征图谱和步骤3中脑电波形特征图谱进行特征图谱合并得到合并后的特征图谱,然后采用cnn类网络对合并后的特征图谱进行分类得出动作分类结果。
本发明中“四个视角”是指在人体站立时,在人体上方设有4个摄像头,这4个摄像头的安装位置与人体形成以人体头部为顶点的四角锥体,此时,从这4个摄像头的视角对人体进行动作拍摄的视角即为“四个视角”。
“多维视角”是指相对于现有技术中的只从一个摄像头的拍摄角度对人体进行动作拍摄,本发明的动作分类方法提出至少可以从4个摄像头的拍摄角度对人体进行动作拍摄,此时的拍摄视角即为“多维视角”。
“下采样”是指对图像像素值进行重新赋值,通过平均池化思想对超像素内像素值进行求和平均,将求和平均后得到的平均值重新赋值给超像素内每一个像素,然后组成新的图像。
实施例1:
本实施例给出一种复杂背景下动作分类方法,详细步骤介绍如下:
动作信息采集:在一个密闭的房间中,位于人体上方四个顶角处安装有四个摄像头(ezvizcs-c2hc-3b2wfr,可视角度不低于60°)。一个实验者头戴脑电设备(neuralscanpro+)在房间中间做动作,安装在密闭房间中四个顶点的四个摄像头可实时采集该实验者的人体动作时序图像,如图1-2所示。然后将采集到的大量人体动作时序图像进行存储,后文将人体动作时序图像简称为动作时序图像。由于摄像头分辨率较高,采集到的动作时序图像尺寸较大,为了提高整个方法的处理速度,将所有动作时序图像尺寸转换为512×512像素,然后通过人工标注,对动作时序图像的人体区域groundtruth和图像动作标签进行标注。
本发明采用labelme图像标注工具完成图像人体区域groundtruth和图像动作标签的标注,由人工标注分类完成。图像动作标签主要分为动作剧烈、动作柔和和动作平静,标签分类依据是:如果人体没有肢体动作或肢体动作幅度微小(手臂与向下垂直方向角度小于10°,并且腿部与向下垂直方向角度小于10°),该情况则判定为动作平静;如果人体肢体动作幅度较小且没有夸张造型(手臂其中之一与向下垂直方向角度大于10°且小于90°,或者腿部其中之一与向下垂直方向角度大于10°且小于30°,并且另外的手臂与向下垂直方向角度小于90°和另外的腿部与向下垂直方向角度小于30°),该情况判定为动作柔和;如果人体动作幅度较大且造型夸张(手臂其中之一与向下垂直方向角度大于90°,或者腿部其中之一与向下垂直方向角度大于30°,另外的手臂和腿部角度随意),该情况判定为动作剧烈。上述标签分类依据结合了人工主观意识,采用本发明提出的方法进行动作分类时,可根据实际情况进行图像动作标注。
步骤1,采用下采样加速方法对动作时序图像进行超像素分割,得到超像素分割结果;根据超像素分割结果对动作时序图像进行下采样,得到视觉概要图像;采用深度学习语义分割网络对视觉概要图像进行图像分割,得到动作掩模图像;
具体操作步骤为:采用下采样加速方法对上述4个角度,各2万帧得到的图像尺寸为512×512像素的动作时序图像进行超像素分割。本发明中的下采样加速方法主要是对对lsc算法进行改进,为了降低lsc超像素分割算法的时间复杂度,从而得出超像素分割结果,如图3所示。
本发明中下采样加速方法包括通过像素1:1条件下采样和像素1:3条件下采样的两种加速方法加速lsc超像素分割算法。
其中,(1)像素1:1条件下采样加速方法主要包括:
s1,将图像尺寸转换后的动作时序图像包含的全部像素个数为n,将n划分为子区域①和子区域②,每个子区域包含n/2个像素,如图4所示,其中子区域①为黑色像素,子区域②为白色像素;
s2,子区域①中的像素通过lsc算法进行聚类并标记为子区域①像素标签;
s3,令p为子区域②中的任意像素,如图5所示。如果p的四个相邻子区域①像素标签相同,则直接标记p像素标签为相邻的子区域①像素标签,如图5a所示;如果p的四个相邻子区域①像素标签属于n(2≤n≤4)个不同的类别,则通过lsc算法计算p与n个不同的类别中心之间的距离,将距离最短的相邻子区域①像素标签赋予p像素,如图5(b)、5(c)和5(d)所示,为n的另外3种情况。
与像素1:1条件下采样加速方法类似,本发明还提出了像素1:3条件下采样加速方法,主要包括:
s1,将图像尺寸转换后的动作时序图像包含的n个像素划分为子区域①和子区域②,其中子区域①包含n/4个像素,子区域②包含3×n/4个像素,如图6所示,其中子区域①为黑色像素,子区域②为白色像素;
s2,子区域①中的像素通过lsc算法进行聚类并标记子为区域①像素标签;
s3,令q为子区域①中处于相邻4个黑色像素对角线交点的子区域②中的任意像素,如图7所示。
如图7a所示,如果q的四个相邻子区域①像素标签相同,则直接标记q像素标签为相邻的子区域①像素标签;如果q的四个相邻子区域①像素标签属于n(2≤n≤4)个不同的类别,则通过lsc算法计算q与n个不同的类别中心之间的距离,将距离最短的相邻子区域①像素标签赋予q像素,如图7(b)、7(c)和7(d)所示,为n的另外3种情况。
s4,经过s1~s3之后,动作时序图像中n/2个像素被标记标签,包括s2中标记的子区域①中的n/4个像素和s3中标记的子区域②中的n/4个像素。至此,在子区域②像素中仍有n/2个像素没有标签,且像素分布和图4一样,接下来采用像素1:1条件下采样加速方法中的s3标记剩余没有标签的n/2个像素。
因为同一超像素中的像素在颜色、纹理和强度上共享相似的视觉特征,并且超像素有利于提取动作时序图像局部结构特征,所以超像素分割后的动作时序图像不需要具体考虑全局每个像素的视觉特征,只需要考虑超像素之间的结构特征。因此,根据超像素分割结果对人体动作时序图像进行下采样,得到视觉概要图像的具体步骤为:
s1,将超像素分割后的结果即超像素分割后的动作时序图像结合深度学习平均池化方法,计算每一块超像素中所有像素点的灰度平均值,即三通道(l,α,β)颜色平均值,采用的公式为:
其中l,α,β表示动作时序图像的三个通道,n表示其中任一张动作时序图像包含的全部像素个数,i表示n中第i个像素。
s2,将s1中计算得到的灰度平均值重新赋值给所对应的每一块超像素中的像素点,生成视觉概要图像。
然后采用深度学习语义分割网络(如fcn、segnet、maskr-cnn、pspnet和refinenet等)对上述的视觉概要图像进行图像分割,得到人体动作掩模图像;具体包括:先结合动作时序图像和人工标注的动作时序图像的人体区域groundtruth训练深度语义分割网络,得到训练好的网络,然后采用训练好的网络分割出人体动作掩模图像,如图8中白色区域所示。
步骤2,采用cnn类网络提取步骤1中的动作时序图像的时刻图像特征与动作掩模图像的时刻图像特征得到时刻特征图谱,然后采用rnn类网络按时间顺序提取时刻特征图谱的时段图像特征,得到结合了图像时序信息的特征图谱;
人体动作掩模图像进一步增强了原始图像人体动作区域,可以提高人体动作区域的识别率,4个摄像头分别标记为a,b,c和d,若拍摄人体动作时按摄像头a、摄像头b、摄像头c和摄像头d的顺序进行拍摄采集,则将任一时刻t1时的动作时序图像和步骤1的动作掩模图像分别按同样的采集顺序(a,b,c和d)进行排列,得到排列好的图像,排列好的图像的数量是(4+4)×3通道,其中第一个4表示步骤一中从四个角度采集到的4张视频图像,第二个4表示步骤二分割出的人体动作掩模图像,3表示是三通道图像。然后采用cnn类网络(如:vgg-16、inception-v4、resnet、resnet-inceptionv2和densenet等)对排列好的图像提取特征,得到t1时刻特征图谱。
人体做出一个动作是有时间序列的,有效利用采集到的原始视频图像的时序信息可以提高人体动作识别率。采用rnn类网络(如rnn和lstm网络)按照时间顺序对t1~tn时刻内的视频图像提取整个时段图像特征,得到t1~tn时刻的整体特征图谱,即结合了图像时序信息的特征图谱。rnn类网络是时序记忆网络,它们是基于rnn网络做出的改进,适合处理具有时间序列的事件。
步骤3,同时采集步骤1中人体在对应时段做出动作时的脑电波形图像,并调整其尺寸与上述动作时序图像尺寸(512×512像素)一致,然后采用rnn类网络按照时间顺序提取脑电波形图像的图像特征,得到脑电波形特征图谱。
步骤4,对步骤2中结合了图像时序信息的特征图谱和步骤3中脑电波形特征图谱进行特征图谱合并,得到合并后的特征图谱,然后采用cnn类网络对合并后的特征图谱进行分类得出动作分类结果。人体在做出动作时,脑中会有相应情绪产生,结合人脑信息和视觉图像信息,可以准确地分析出人体做出动作的类别。最终分类结果分为动作剧烈、动作柔和和动作平静三种,如图9所示,图9判断出为动作柔和,其准确率为96%。
实施例2
为了验证提出方法的有效性,本发明在采集的动作时序图像上进行实验验证:
摄像头按照人体三种动作剧烈程度在复杂背景下采集图像,实验选取了四个角度上的图像各20000张进行分类。该分类实验遵循标准的交叉验证策略,采用四折交叉验证进行实验,实验结果表明本发明方法在复杂背景下,仍有较高的分类效果,平均准确率为95%。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!