基于多设备乱序数据的实时计算方法及系统与流程
本发明涉及数据处理领域,尤其涉及一种基于多设备乱序数据的实时计算方法及系统。
背景技术:
随着流程工业的发展,大量高频采集的测量数据需要实时存储,而如果再采用传统的关系数据库则难以满足数据实时存储速度和存储容量的高要求,对实时数据和实时事务的应用需求已难以胜任。
于是,适用于工业监控领域的实时数据库应运而生。实时数据库针对快速读写对应设计了时标型数据结构和高频缓存技术,可以实现海量数据的毫秒级读写。此外,基于压缩算法和对时间与索引的特殊处理,实时数据库能够节省大量的存储空间,支持大容量数据的有效存储。目前,实时数据库已经应用到众多领域,主要作为企业实时信息中枢,支持如调度系统、物料平衡系统等制造执行系统的应用,为工业企业生产信息的存储和访问提供统一数据源,实现实时监控和高级控制。
实时计算是实时数据库的核心技术之一。与离线计算相比,实时计算在方法实现方面需要考虑得更多,这是因为实时计算能够用到的内存资源远不如离线计算,而且处理过程的时间限制更加严格,这都要求实时计算方法必须做相当多的优化。
在理想情况下,实时计算在执行过程中读取和使用的数据都应是现场设备的最新值。然而,这是不现实也是不可能做到的。因为各个数据由不同精度的传感器获得,部分数据不在同一时刻也在所难免。此外,由于节点处理效率不同,总会有某些数据传入时间会滞后,真实情况与理想情况下数据的时间戳会不可避免地存在偏差,引发数据乱序,基于乱序数据情况下的实时计算方法比较困难。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中基于乱序数据情况下的实时计算方法比较困难,为保持多设备乱序数据的时间一致性,提供一种基于多设备乱序数据的实时计算方法及系统。
本发明是通过下述技术方案来解决上述技术问题:
一种基于多设备乱序数据的实时计算方法,所述基于多设备乱序数据的实时计算方法包括:
实时数据库从多个设备分别采集实时数据;
以预设的读取周期读取所述实时数据库,对于每个所述读取周期,获取当前所述读取周期的时间范围内所述多个设备的最新实时数据;
根据预设算法对所述最新实时数据进行运算得到运算结果。
较佳地,所述以预设的读取周期读取所述实时数据库,对于每个所述读取周期,获取当前所述读取周期的时间范围内所述多个设备的最新实时数据的步骤之后还包括:
判断当前所述读取周期内是否获取到每个设备的最新实时数据,若否,则将未获取到的所述最新实时数据的设备的前一个所述读取周期的时间范围的最新实时数据作为当前所述读取周期内的最新实时数据。
较佳地,所述根据预设算法对所述最新实时数据进行运算得到运算结果的步骤之后还包括:
将所述运算结果保存于所述实时数据库中。
较佳地,所述实时数据包括实时数据值和与所述实时数据值对应的时间戳。
较佳地,所述运算结果包括运算结果值、与所述运算结果值对应的时间戳和与所述时间戳对应的数据质量信息,所述数据质量信息用于表征所述运算结果是否准确。
一种基于多设备乱序数据的实时计算系统,所述基于多设备乱序数据的实时计算系统包括采集模块、读取模块和运算模块;
所述采集模块用于利用实时数据库从多个设备分别采集实时数据;
所述读取模块用于以预设的读取周期读取所述实时数据库,对于每个所述读取周期,获取当前所述读取周期的时间范围内所述多个设备的最新实时数据;
所述运算模块用于根据预设算法对所述最新实时数据进行运算得到运算结果。
较佳地,所述基于多设备乱序数据的实时计算系统还包括判断模块,所述判断模块用于判断当前所述读取周期内是否获取到每个设备的最新实时数据,若否,则将未获取到的所述最新实时数据的设备的前一个所述读取周期的时间范围的最新实时数据作为当前所述读取周期内的最新实时数据。
较佳地,所述基于多设备乱序数据的实时计算系统还包括存储模块,所述存储模块用于将所述运算结果保存于所述实时数据库中。
较佳地,所述实时数据包括实时数据值和与所述实时数据值对应的时间戳。
较佳地,所述运算结果包括运算结果值、与所述运算结果值对应的时间戳和与所述时间戳对应的数据质量信息,所述数据质量信息用于表征所述运算结果是否准确。
本发明的积极进步效果在于:
本发明通过设置读取周期,并以读取周期读取实时数据库,并获取当前读取周期内,从多个设备采集的最新实时数据,将获取到的多个设备的最新实时数据设置为同一时间戳数据,这样就消除了实时数据乱序的问题,并保持了多设备乱序数据的时间一致性,可简单方便的根据预设算法对同一时间戳数据进行运算并得到运算结果。
附图说明
图1为本发明的实施例1的基于多设备乱序数据的实时计算方法的流程示意图。
图2为本发明的实施例1的基于多设备乱序数据的实时计算方法的两个设备的实时数据及运算结果示意图。
图3为本发明的实施例1的基于多设备乱序数据的实时计算方法的两个设备的实时数据及运算结果示意图。
图4为本发明的实施例2的基于多设备乱序数据的实时计算方法的流程示意图。
图5为本发明的实施例2的基于多设备乱序数据的实时计算方法的两个设备的实时数据及运算结果示意图。
图6为本发明的实施例2的基于多设备乱序数据的实时计算方法的原理示意图。
图7为本发明的实施例3的基于多设备乱序数据的实时计算系统的模块示意图。
图8为本发明的实施例4的基于多设备乱序数据的实时计算系统的模块示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
实施例1
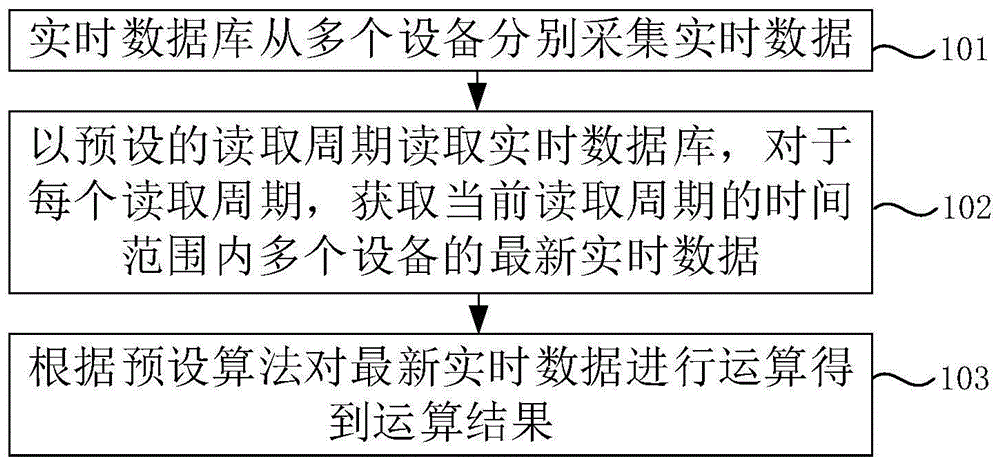
本实施例提供了一种基于多设备乱序数据的实时计算方法,如图1所示,基于多设备乱序数据的实时计算方法的步骤具体包括:
步骤101、实时数据库从多个设备分别采集实时数据。
实时数据库在当前读取周期内,采集并存储来自多个设备的实时数据。
步骤102、以预设的读取周期读取实时数据库,对于每个读取周期,获取当前读取周期的时间范围内多个设备的最新实时数据。
当前读取周期结束时,实时数据库采集到所有需要实时计算的最新实时数据。
步骤103、根据预设算法对最新实时数据进行运算得到运算结果。
针对进行实时计算的最新实时数据,用户可以基于根据实际情况需要设定具体的计算方法,根据设定的计算方法执行计算操作,得到运算结果可根据实际需求进行相应的处理。
实时数据库进入下一个读取周期,继续执行步骤102的操作。
下面对本实施例的方法步骤进行具体描述,准备位于同一网段的三台计算机,在其中两台计算机上分别开启基于modbus(一种串行通信协议)协议的modbusslave(一种串行通信测试工具)测试工具作为设备,两个设备假设分别为moddev1:1与moddev2:2,设置另一台计算机运行实时数据库,实时数据库与两个设备完成通信连接并分别采集实时数据。假设设置读取实时数据库的读取周期为1秒,设置计算方法为进行moddev1:1与moddev2:2的数据加法运算得到morresult运算结果。
(1)实时数据库采集以上两个设备的实时数据。
(2)设置读取实时数据库的周期为1秒,即每秒读取实时数据库,如图2中所示,在2018/11/282:05:40.000时刻至2:05:41.000的1秒的时间段内采集到设备moddev1:1的实时数据为1644,获取设备moddev2:2的实时数据为1621,则对获取到的两个实时数据进行求和运算得到运算结果为3265,然后继续进行下一个周期即2:05:41.000时刻至2:05:42.000的1秒的时间段内的数据读取及运算操作。
通过实时数据库的历史数据模块,可分别导出从moddev1:1、moddev2:2这两个设备采集的实时数据以及计算结果morresult在各个读取周期时间段内的数据,如图2所示,可以看到,虽然moddev1:1与moddev2:2的实时数据分别对应的传输时间不一致,存在数据乱序情况,但是利用本实施例的方法得到了有效的运算结果。
以读取周期为时间段读取实时数据库时,有可能存在读取实时数据库得到多组moddev1:1的实时数据或者多组moddev2:2的实时数据的情况,也有可能出现采集到moddev1:1与moddev2:2均为多组的实时数据的情况,如图3所示,在2018/12/65:14:08.000至2018/12/65:14:09.000的读取周期内采集到了两组moddev1:1的实时数据分别为5:14:08.220时刻的实时数据56,和5:14:08.937时刻的实时数据57,本方法选用最新的实时数据,即moddev1:1在2018/12/65:14:08.937的实时数据57参与计算,与moddev2:2在2018/12/65:14:08.826的实时数据39的实时数据求和,最终得到57+39=96的运算结果。
通过设置读取周期,并以读取周期读取实时数据库,并获取当前读取周期内,从多个设备采集的最新实时数据,将获取到的多个设备的最新实时数据作为同一时间戳数据进行运算,这样就消除了实时数据乱序的问题,并保持了多设备乱序数据的时间一致性,并可简单方便的根据预设算法对同一时间戳数据进行运算并得到运算结果。
实施例2
本实施例提供的是一种基于多设备乱序数据的实时计算方法,本实施例与实施例1相比,如图4所示,其区别在于在步骤102之后还包括:
步骤102’、判断当前读取周期内是否获取到每个设备的最新实时数据,若否,则执行步骤103’,若是则执行步骤103。
步骤103’、将未获取到的最新实时数据的设备的前一个读取周期的时间范围的最新实时数据作为当前读取周期内的最新实时数据,继续执行步骤103。
针对在当前读取周期的时间段内未采集到的实时数据,取用上一个读取周期采集的实时数据进行计算得到运算结果。
如图5所示,可以看到,morresult在2018/12/65:14:07.000至2018/12/65:14:08.000的读取周期内未采集到设备moddev1:1的实时数据,本方法取用上一个读取周期的最新实时数据,即2018/12/65:14:06.911时刻对应的实时数据55参与计算,与moddev2:2在2018/12/65:14:07.721时刻的实时数据38进行相加运算最终得到morresult在2018/12/65:14:07.000的运算结果93。通过实时数据库的历史数据模块,就可导出moddev1:1、moddev2:2及计算结果morresult在指定时间段内的实时数据。
步骤103之后还包括:
步骤104、将运算结果保存于实时数据库中。
实时数据包括实时数据值和与实时数据值对应的时间戳。
运算结果包括运算结果值、与运算结果值对应的时间戳和与时间戳对应的数据质量信息,数据质量信息用于表征运算结果是否准确。
为更清楚的说明实时计算方法原理,图6给出了两个设备的实时数据进行实时最新实时数据计算的示意图,如图中所示,1~2时间段对应步骤102所述情况:在读取周期的时间段内,实时数据库采集到来自设备a与设备b的实时数据,均为最新实时数据,因此在读取周期结束时直接执行计算操作,得到运算结果;3~4时间段在读取周期内,实时数据库采集到来自设备b的两组数据,对当前读取周期而言最新的一组实时数据更为准确。因此,在读取周期结束时,使用设备b的最新一组实时数据与设备a的实时数据进行计算,得到运算结果。
2~3时间段对应步骤102’所述的情况:在读取周期内,实时数据库只采集到来自设备a的实时数据,未采集到来自设备b的实时数据。因此,在读取周期结束时,取用设备b在1~2时间段的实时数据作为设备b的最新实时数据与设备a的最新实时数据进行计算,得到运算结果。
在实时计算方法执行过程中,如果出现步骤102’所述的情况,说明需要采用对应设备上一个读取周期的最新实时数据作为补偿数据来完成实时计算,这会给运算结果带来一定的不准确性。因此,在运算实现的最后一步,除了为新的实时数据赋予数值和对应的时间戳信息(对应的时间戳信息在本实施例中设置为读取周期开始的时刻),还可以增加实时数据的质量信息,如在1~2和3~4的时间段因为获取到了设备的最新实时数据,可表明此运算结果的数据是正确的,但在2~3的时间段内因为取到的是上一周期时间段的最新数据,因此可表明对应读取时刻的数据是不够准确的,采用实时数据的质量信息标明运算结果在哪些时刻的数值可能存在质量问题,为后续可能的离线数据查看和分析提供帮助。
实施例3
本实施例提供了一种基于多设备乱序数据的实时计算系统,如图7所示,基于多设备乱序数据的实时计算系统包括采集模块201、读取模块202和运算模块203。
采集模块201用于利用实时数据库从多个设备分别采集实时数据。
读取模块202用于以预设的读取周期读取实时数据库,对于每个读取周期,获取当前读取周期的时间范围内多个设备的最新实时数据;当前读取周期结束时,实时数据库采集到所有需要实时计算的最新实时数据。
运算模块203用于根据预设算法对最新实时数据进行运算得到运算结果。
针对进行实时计算的最新实时数据,用户可以基于根据实际情况需要设定具体的计算方法,根据设定的计算方法执行计算操作,得到运算结果可根据实际需求进行相应的处理。
实时数据库进入下一个读取周期,返回读取模块的操作。
下面对本实施例的系统进行具体描述,准备位于同一网段的三台计算机,在其中两台计算机上分别开启基于modbus(一种串行通信协议)协议的modbusslave(一种串行通信测试工具)测试工具作为设备,两个设备假设分别为moddev1:1与moddev2:2,设置另一台计算机运行实时数据库,实时数据库与两个设备完成通信连接并分别采集实时数据。假设设置读取实时数据库的读取周期为1秒,设置计算方法为进行moddev1:1与moddev2:2的数据加法运算得到morresult运算结果。
(1)实时数据库采集以上两个设备的实时数据。
(2)设置读取实时数据库的周期为1秒,即每秒读取实时数据库,如图2中所示,在2018/11/282:05:40.000时刻至2:05:41.000的1秒的时间段内采集到设备moddev1:1的实时数据为1644,获取设备moddev2:2的实时数据为1621,则对获取到的两个实时数据进行求和运算得到运算结果为3265,然后继续进行下一个周期即2:05:41.000时刻至2:05:42.000的1秒的时间段内的数据读取及运算操作。
通过实时数据库的历史数据模块,可分别导出从moddev1:1、moddev2:2这两个设备采集的实时数据以及计算结果morresult在各个读取周期时间段内的数据,如图2所示,可以看到,虽然moddev1:1与moddev2:2的实时数据分别对应的传输时间不一致,存在数据乱序情况,但是利用本实施例的系统得到了有效的运算结果。
以读取周期为时间段读取实时数据库时,有可能存在读取实时数据库得到多组moddev1:1的实时数据或者多组moddev2:2的实时数据的情况,也有可能出现采集到moddev1:1与moddev2:2均为多组的实时数据的情况,如图3所示,在2018/12/65:14:08.000至2018/12/65:14:09.000的读取周期内采集到了两组moddev1:1的实时数据分别为5:14:08.220时刻的实时数据56,和5:14:08.937时刻的实时数据57,本系统选用最新的实时数据,即moddev1:1在2018/12/65:14:08.937的实时数据57参与计算,与moddev2:2在2018/12/65:14:08.826的实时数据39的实时数据求和,最终得到57+39=96的运算结果。
通过设置读取周期,并以读取周期读取实时数据库,并获取当前读取周期内,从多个设备采集的最新实时数据,将获取到的多个设备的最新实时数据作为同一时间戳数据进行运算,这样就消除了实时数据乱序的问题,并保持了多设备乱序数据的时间一致性,并可简单方便的根据预设算法对同一时间戳数据进行运算并得到运算结果。
实施例4
本实施例提供了一种基于多设备乱序数据的实时计算系统,本实施例与实施例3相比,其区别在于,如图8所示,基于多设备乱序数据的实时计算系统还包括判断模块204,判断模块204用于判断当前读取周期内是否获取到每个设备的最新实时数据,若否,则将未获取到的最新实时数据的设备的前一个读取周期的时间范围的最新实时数据作为当前读取周期内的最新实时数据。
针对在当前读取周期的时间段内未采集到的实时数据,取用上一个读取周期采集的实时数据进行计算得到运算结果。
如图5所示,可以看到,morresult在2018/12/65:14:07.000至2018/12/65:14:08.000的读取周期内未采集到设备moddev1:1的实时数据,本系统取用设备moddev1:1上一个读取周期的最新实时数据,即2018/12/65:14:06.911时刻对应的实时数据55参与计算,与moddev2:2在2018/12/65:14:07.721时刻的实时数据38进行相加运算最终得到morresult在2018/12/65:14:07.000的运算结果93。通过实时数据库的历史数据模块,就可导出moddev1:1、moddev2:2及计算结果morresult在指定时间段内的实时数据。
基于多设备乱序数据的实时计算系统还包括存储模块205,存储模块205用于将运算结果保存于实时数据库中。
实时数据包括实时数据值和与实时数据值对应的时间戳。
运算结果包括运算结果值、与运算结果值对应的时间戳和与时间戳对应的数据质量信息,数据质量信息用于表征运算结果是否准确。
为更清楚的说明实时计算系统原理,图6给出了两个设备的实时数据进行实时最新实时数据计算的示意图,如图中所示,1~2时间段对应情况为,在读取周期的时间段内,实时数据库采集到来自设备a与设备b的实时数据,均为最新实时数据,因此在读取周期结束时直接执行计算操作,得到运算结果;3~4时间段在读取周期内,实时数据库采集到来自设备b的两组数据,对当前读取周期而言最新的一组实时数据更为准确。因此,在读取周期结束时,使用设备b的最新一组实时数据与设备a的实时数据进行计算,得到运算结果。
2~3时间段对应的情况为:在读取周期内,实时数据库只采集到来自设备a的实时数据,未采集到来自设备b的实时数据。因此,在读取周期结束时,取用设备b在1~2时间段的实时数据作为设备b的最新实时数据与设备a的最新实时数据进行计算,得到运算结果。
在实时计算系统运行过程中,如果出现2~3时间段对应的情况,说明需要采用对应设备上一个读取周期的最新实时数据作为补偿数据来完成实时计算,这会给运算结果带来一定的不准确性。因此,在运算实现的最后一步,除了为新的实时数据赋予数值和对应的时间戳信息(对应的时间戳信息在本实施例中设置为读取周期开始的时刻),还可以增加实时数据的质量信息,如在1~2和3~4的时间段因为获取到了设备的最新实时数据,可表明此运算结果的数据是正确的,但在2~3的时间段内因为取到的是上一周期时间段的最新数据,因此可表明对应读取时刻的数据是不够准确的,采用实时数据的质量信息标明运算结果在哪些时刻的数值可能存在质量问题,为后续可能的离线数据查看和分析提供帮助。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!