一种融合表示学习和分治策略的大规模本体合并方法与流程
本发明属于面向网络数据的知识库构造和合并的相关技术,具体涉及一种融合表示学习和分治策略的大规模本体合并方法。
背景技术:
知识库是采用某种知识表示方式组织和管理的互相联系的知识集合。虽然知识的定义在认知论中仍然是一个争论不止的问题,但是在知识工程领域,知识描述的要素一般包括分类、实体、关系、属性等要素。而本体是指一种形式化的、对于共享概念体系的明确而又详细的说明,它包含类别、类别属性以及类别之间的关系等要素,用于对知识库中的知识项进行语义分组或语义标注。本体合并的主要作用是将描述知识的两个概念体系进行集成,实现知识的复用和共享,其关键在于对概念体系进行匹配:发现对齐概念体系中共同的元素,从而完成两个概念体系的合并。近年来,本体合并由于其在知识库构建和合并等方面的广泛应用,国内外工业界和学术界开展了大量的研究工作。这些研究工作大部分是利用本体自身的信息来计算两个本体之间元素的相似度,例如类别的名称、属性或类别在本体中的结构信息等。目前,现有的本体合并工作根据其使用的策略的不同主要分为以下几类:
(1)基于词汇表示的策略,通过计算本体要素之间的字符串相似度判断要素之间的等价关系。这种策略计算简单、直接。然而,这种策略完全取决于词汇表示,难以区分同义和多义表达的情况。
(2)借助外部词典或本体背景知识的策略,通过外部信息丰富本体要素的上下文信息,但这种策略受限于词典的覆盖率或背景知识的丰富程度。
(3)基于结构信息的策略,通过计算本体要素之间近邻结构的相似度判断要素之间的等价关系,这种策略适用于结构相似程度高的本体之间的合并。
(4)基于上述策略组合的方法,通过组合两种或多种信息度量本体要素之间的等价关系,这种方法在一定程度上提升了本体合并的准确性。
然而,目前大部分工作还只能在特定领域发挥作用,而且无法有效地处理大规模的本体。导致这一问题的原因在于:不同的本体通常使用不同的词汇和层级结构来表示自己的类别,而且其对应的可能的匹配空间随本体中类别的规模的增加呈现指数级增长。特别是,随着网络大数据的发展,本体变得越来越庞大和复杂。基于贪心的方法对处理大规模的本体合并任务可能是一种有效的方法,但由于其贪心的性质,它在合并决策时难以修正之前的错误,导致该方法无法保证两个本体获得全局最优的合并结果。
综上所述,目前,对于面向大规模本体合并的问题仍然缺乏很有效的方法,尤其是在保证本体合并准确性的前提下,降低大规模本体合并的执行时间,适应大规模本体合并的可扩展性需求。
技术实现要素:
本发明的目的在于提供一种面向大规模本体合并的方法,该方法能够实现在保证本体合并的准确性的情况下解决大规模本体合并的性能问题,降低大规模本体合并的执行时间,适应本体合并的可扩展性需求。
为达到以上目的,本发明采用的技术方案是:一种融合表示学习和分治策略的大规模本体合并方法,其特点在于:(1)通过表示学习方法,利用统一的语义模型学习本体组成要素在假设的公共语义空间(即连续低维向量空间)中的语义表示(即实值向量表示),提升本体组成要素之间相似度度量的准确性;(2)基于分治策略,将大规模本体划分为规模相对较小的块的集合,通过块之间的匹配,实现大规模本体之间的匹配,从而发现本体之间的对齐;(3)基于本体之间的对齐,采用目标驱动的本体合并算法来计算两个本体合并的结果,在合并过程中重点维护目标本体的结构信息。
该方法通过本体编码器、本体分割器、本体匹配器和本体合并器处理大规模本体的合并,步骤包括:
1.首先,利用本体编码器学习待合并的本体的类别、类别关系等本体组成要素在假设的公共语义空间中的语义表示。
2.其次,利用本体分割器,根据本体层级结构的特性,采用凝聚算法,将每一本体中的所有类别划分为若干不相交的类别簇,根据同一类别簇中的类别在原始本体中的层级结构,恢复该类别簇中类别之间的关系,生成本体划分的块集合,得到n个类别簇,则对应生成n个块集合。
3.然后,对步骤2生成的两个本体划分的块集合,利用本体匹配器,采用启发式方法生成两个本体之间的块映射,并基于步骤1中学习到的本体要素的语义表示,采用最大权匹配算法发现每个块映射中块之间的对齐(即发现具有块映射关系的块,对其进行对齐),从而获取两个本体之间的对齐。
4.最后,根据步骤3产生的本体对齐,利用本体合并器,采用目标驱动的本体合并算法区分源本体和目标本体,将源本体和目标本体之间等价的类别合并成一个公共的类别,然后在这个合并的本体中正确地放置剩下的源本体中的类别信息,从而获得两个本体合并的结果,在合并过程中,重点维护目标本体的结构信息。
本体编码器对本体的语义表示分为两个过程:语义表示模型构建和模型学习。具体执行步骤如下:
1)语义表示模型构建:基于能量模型(energy-basedmodel),利用k-维的向量空间建模类别和类别之间的关系,采用基于结构的表示和基于属性的表示两种方式学习本体中的类别在该k-维的向量空间中的向量表示。给定本体o中两个类别ch和ct,ch与ct之间的关系为r,则能量函数(energyfunction)为:
f(ch,r,ct)=fs(ch,r,ct)+fa(ch,r,ct),
其中,
fa(ch,r,ct)=faa(ch,r,ct)+fas(ch,r,ct)+fsa(ch,r,ct),
其中,
2)模型学习:通过在训练集上求解一个使得基于边际风险排名准则最小化的值学习本体中类别和关系的向量表示。具体采用基于边际的得分函数为训练目标,目标函数为:
其中,[x]+表示x的正部分;γ是一个边际超参数,并且γ>0;s是由若干类别-关系元组(ch,r,ct)组成的训练样本集合;s'是基于s构造的反例集合,构造方式为:
s'={(c'h,r,ct)|c'h∈c}∪{(ch,r,ct')|ct'∈c},
其中,c表示训练数据中类别的集合,s'是通过随机选择c中的一个类别替换训练集合s中元组的头部类别ch或者尾部类别ct(但不是同时)所形成的集合,c'h和ct'为集合c中的类别,c'h∈c,ct'∈c。在模型学习过程中,采用随机梯度下降的方法学习模型的参数。
本体分割器对本体的分割分为两个过程:类别簇划分和块构造。具体执行步骤如下:
1)类别簇划分:根据类别在本体中的层级结构,采用类别之间的结构邻近度(structuralproximities)计算类别簇本身的内聚度(cohesion)和类别簇之间的耦合度(coupling),基于凝聚划分算法将本体o的类别集合c划分为一组不相交的簇c1,c2,…,cn,满足:
2)块构造:对步骤1)生成的每一个本体类别簇,根据类别在原始本体中的层级结构,恢复类别簇中类别之间的关系,生成本体块,从而获得本体划分的块集合。
本体匹配器发现本体对齐分为两个过程:块映射和对齐发现。具体执行步骤如下:
1)块映射:直接基于字符串比较的方法计算两个类别c和c'之间的相似度sim(c,c')(sim(c,c')∈[0,1])快速发现两个块之间候选匹配的类别对,并基于两个块之间的匹配的类别对的数量计算块之间的相似度,生成块映射。其中,给定两个本体o和o',利用本体分割器生成的块集合分别为b和b',已知两个块b∈b、b'∈b',b和b'块之间相似度记为:
其中,#(·)表示两个块之间候选匹配的类别对的数量,bi为b中的第i个本体块,bi'为b'中的第i个本体块。
2)对齐发现:对步骤1)发现的块映射,基于本体编码器学习到的类别的语义表示,利用二部图模型,构建块映射中两个块之间的候选匹配的类别对之间的关系,执行最大权匹配算法剪枝选择两个块之间可能的候选匹配类别对,产生块映射最终的对齐结果。
进一步,为了使本体匹配器获取更好的效果,在步骤1)中,如果两个类别的相似度大于预先设定的阈值μ(0≤μ≤1),则将该类别对作为候选匹配的类别对;如果两个块之间的相似度大于预先设定的阈值λ(0≤λ≤1),则这两个块构成块映射。
本体合并器对本体的合并分为两个过程:类别图构建和类别图遍历。具体执行步骤如下:
1)类别图构建:基于本体匹配器获取的两个本体的对齐结果,指定源本体和目标本体,合并源本体和目标本体中等价的类别,生成两个本体之间集成的类别图。
2)类别图遍历:遍历步骤1)生成的集成的类别图,对该类别图中来自源本体的源边和来自目标本体的目标边进行翻译,移除图中存在的环,对集成的类别图中所有的目标边在本体合并的结果中创建类别的关系,保留目标本体在集成的本体中的结构信息,并获得集成的类别图中与源边关联的所有的叶子顶点,在该类别图中查找与这些叶子顶点关联的源边,将源本体中剩余的类别根据类别关联关系正确集成到最终的合并结果中。
与现有技术相比,本发明的积极效果为:
上述的融合表示学习和分治策略的大规模本体合并方法,能够通过表示学习方式获取本体组成要素在语义空间中的一种精细的语义表示,提升本体要素之间相似度度量的准确性,从而提升对齐发现的正确性,并且该方法通过分治策略,将大规模本体匹配的问题转化为小规模本体匹配的问题,降低大规模本体合并的执行时间,适应大规模本体合并的可扩展性需求。
附图说明
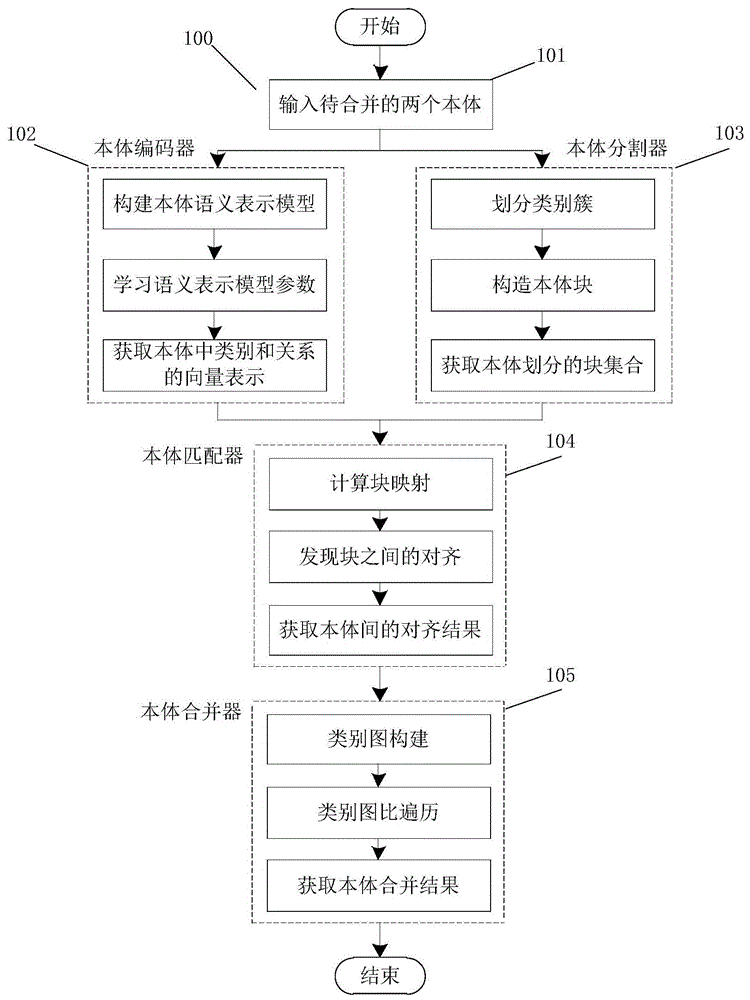
图1是本发明的方法的整体流程图;
图2是本发明的方法中本体编码器学习类别向量表示的流程图;
图3是本发明的方法中本体编码器基于结构的类别-关系语义表示模型;
图4是本发明的方法中本体编码器基于属性的类别-关系语义表示模型;
图5是本发明的方法中本体编码器基于随机梯度下降算法学习类别-关系语义表示模型的流程图;
图6是本发明的方法中本体分割器生成本体块的流程图;
图7是本发明的方法中本体匹配器生成本体块对齐结果的流程图;
图8是本发明的方法中本体合并器生成本体合并结果的流程图。
具体实施方式
下面结合附图及实施例对本发明做进一步地描述。
如图1所示,是本发明的方法的整体流程图。该方法主要分为下面五步来完成大规模本体的合并:
步骤101,选择用于合并的两个本体,初始化待合并的本体,指定源本体和目标本体;
步骤102,利用本体编码器,通过构建本体语义表示模型,自动在指定的语义空间中分别学习两个本体的类别、关系的含义,获取本体组成要素在语义空间中的一种精细的向量表示;
步骤103,通过本体分割器,分别将每个本体的类别集合划分为一组不相交的类别簇,并根据类别在本体中的结构,创建类别簇中类别之间的关系,获取本体划分的块集合;
步骤104,利用本体匹配器采用启发式方法对步骤103获取的两个本体的块集合构建块映射,筛选进一步进行块对齐计算的候选块集合,然后基于步骤102获取的本体组成要素的向量表示,获取每个块映射中块之间的对齐,从而获取两个本体之间的对齐结果;
步骤105,基于步骤104获取的两个本体的对齐结果,通过本体合并器采用目标驱动的合并方法将源本体和目标本体中等价的类别进行合并,并在合并的本体中正确地放置剩下的源本体中的类别信息。
进一步,在步骤101中,本体(ontology)是指一种形式化的、对于共享概念体系的明确而又详细的说明,它包含类别、类别属性以及类别之间的关系等要素,用于对知识库中的知识项进行语义分组或语义标注,采用无环的层级结构表示。因此,将本体o建模成如下形式:
o=<c,p,r>,
其中,c表示本体中包含的类别集合,p表示类别的属性集合,r是定义本体组成要素类别与类别、类别与属性、属性与属性之间的关系类型映射函数,满足每一对要素最多被分配给一个关系。关系的类型有三种取值:hypernymy,hyponymy,meronymy,分别表示上位关系、下位关系和整体-部分关系。其中,关系类型hypernymy和hyponymy用来描述两个类别的关系,关系类型meronymy用来描述类别与属性、属性与属性之间的关系。给定两个类别ch和ct,ch和ct之间的关系为r,如果r的取值为hypernymy,则表示ch是ct的父节点;如果为r的取值为hyponymy,则表示ch是ct的孩子节点。对于集合c中的每一个类别c的属性集合pc和与其关联的类别集合nc可以通过本体o的关系映射函数r求得,满足
进一步,在步骤102中,本体编码器基于能量模型,利用k-维的向量空间建模类别和类别之间的关系,自动学习类别在该空间中的向量表示,获取一种精细的语义特征度量,以便提升本体合并的准确率。利用本体编码器学习本体的类别、类别关系在向量空间中的语义表示的过程如图2所示,包括:
步骤201,输入待编码的本体o=<c,p,r>;
步骤202,基于能量模型,构建本体中类别及其关系的语义表示模型。利用k-维的语义空间建模类别-关系,采用基于结构的表示和基于属性的表示(在本实施例中,基于结构的类别-关系语义表示模型如图3所示,基于属性的类别-关系语义表示模型如图4所示)两种方式为本体o中的两个类别ch、ct及其它们之间的关系为r建模其在k-维的语义空间中的向量表示,表示形式如下:
f(ch,r,ct)=fs(ch,r,ct)+fa(ch,r,ct),
其中,
fa(ch,r,ct)=faa(ch,r,ct)+fas(ch,r,ct)+fsa(ch,r,ct),
其中,
为了计算基于属性的类别的向量表示,在本实施例中,采用连续词袋模型(continuousbag-of-words,cbow)将每个类别的属性词作为输入计算类别的向量表示。具体计算如图4所示:首先属性包含的每个词的向量表示相加获得该属性的向量表示;然后将类别的所有属性的向量表示相加获取类别的向量表示。注意,在基于属性词计算属性的向量表示时忽略属性词的顺序,同样在计算类别的表示时忽略类别的属性顺序。具体地,指定本体o中的一个类别c,通过本体o的关系映射函数r获得类别c的属性集合pc,则类别c基于属性的表示ca为:
ca=p1+l+pn,
其中,pi是类别c的第i个属性pi的向量表示(1≤i≤n,n=|pc|);pi=x1+l+xm,xj是组成属性pi的第j个词的向量表示,在本实施例中,xj是基于维基百科语料采用word2vec(https://code.google.com/archive/p/word2vec/)训练获得的向量表示。
步骤203,对步骤202中的语义表示模型进行训练,学习模型的参数。具体采用基于边际的得分函数为训练目标,目标函数为:
其中,[x]+表示x的正部分;γ是一个边际超参数,并且γ>0;s是训练样本集合;s'是基于s构造的反例集合,构造方式为:
s'={(c'h,r,ct)|c'h∈c}∪{(ch,r,ct')|ct'∈c},
其中,c表示训练数据中类别的集合,s'是通过替换训练集合s中元组的头部类别ch或者尾部类别ct(但不是同时)所形成的集合。在模型学习过程中,采用随机梯度下降的方法学习模型的参数。
步骤204,基于步骤203学习到的模型参数,获取本体o=<c,p,r>中包含的所有类别和类别关系的向量表示。
进一步,在步骤203中,采用随机梯度下降的方法学习模型的参数的过程如图5所示,包括:
步骤301,选择本体o中用于模型学习的训练数据集s={(ch,r,ct)},初始化算法输入:本体类别集合c和关系集合l,设置模型学习参数:包括语义空间维数k,算法训练最小批处理块大小b,边际超参数γ,模型学习率λ,训练样本最大运算次数epochs(本实施例中k为50,b为100,γ为1,λ为0.01,epochs为1000);
步骤302,初始化基于结构和基于属性的类别-关系向量表示。具体地,采用均匀分布方式初始化类别、关系基于结构的向量表示:
步骤303,规范化类别、关系的向量表示:
步骤304,基于最小批处理块sbatch按照等概率均匀分布方式,对
步骤305,基于梯度下降步长(模型学习率)λ更新模型的参数:
步骤306,判断当前训练样本运算次数t是否满足t<epochs,若满足,则执行步骤303;若不满足,则模型训练完成,至此学习到模型的所有参数,算法结束。
进一步,在步骤103中,利用本体分割器,根据本体层级结构的特性,采用凝聚算法将本体中的所有的类别划分为一组不相交的类别簇,并根据类别在原始本体中的结构恢复类别簇中类别之间的关系,生成本体块,获得本体划分的块集合。利用本体分割器,获得本体划分的块集合的算法流程图如图6所示:
步骤401,输入待分割的本体o=<c,p,r>,初始化类别簇划分集合:将每一个类别作为一个类别簇;
步骤402,根据类别在本体中的层级结构,计算本体中所有类别之间的结构邻近度。本实施例中,采用类别在本体中的hypernymy和hyponymy关系的关联程度来计算。具体地,给定o中的两个类别ci和cj,ci和cj之间的结构邻近度如下:
其中,cij表示ci和cj的共同的父类;depth(c)表示c在本体o中的层次深度。值得注意的是在本体的层级结构中,若c的深度并不唯一,则选在最大值作为c的深度;同样,若ci和cj的共同的父类也不唯一,则选择具有最大深度的类作为它们共同的父类。为了降低计算的复杂度,在本实施例中只计算深度满足|depth(ci)-depth(cj)|≤1的两个类别的结构邻近度。
步骤403,基于类别的结构邻近度,通过考虑聚类之间的连通性度量两个簇之间的距离,以此计算类别簇内的内聚度和类别簇之间的耦合度。给定两个类簇ci和cj,矩阵a表示本体类别之间的结构邻近度,本实施例中定义以下准则函数计算内聚度和耦合度:
其中,若ci=cj,则为类别簇的内聚度cohesion(ci)=func(ci,ci);否则为ci和cj之间的耦合度coupling(ci,cj)=func(ci,cj)。
步骤404,选择具有最大内聚度的簇ci,并查找与ci具有最大耦合度的簇cj进行合并,得到新的类簇ck,并更新ck的内聚度:
cohesion(ck)=cohesion(ci)+coupling(ci,cj)+cohesion(cj),
在此过程中,若ci是独立的簇(即不存在簇cj满足coupling(ci,cj)>0),则将ci的内聚度置为0,表示不合并该簇,并将该簇作为最终划分的簇集合中的一个类簇。
步骤405,判断类别簇中是否存在内聚度大于0的簇,若存在,则继续执行步骤403进行类别簇划分;若不存在,则说明本体的类别已完全分开,类别簇划分结束,从而获得本体o的一组不相交的类别簇c1,c2,…,cn;
步骤406,根据类别在本体o中的结构,恢复每一个类别簇ci中类别之间的关系,生成本体块bi,从而获得本体划分的块集合b。
进一步,在步骤104中,基于本体块划分结果,通过本体匹配器获取两个本体之间的对齐结果的算法流程图如图7所示:
步骤501,输入待合并的两个本体划分的块集合b和b';
步骤502,计算两个本体块之间的相似度,查找块映射。具体地,对于
其中,#(·)表示两个块之间候选匹配的类别对的数量。
步骤503,若两个块b和b'的相似度大于预先设定的阈值λ(sim(b,b')>λ,0≤λ≤1,本实施例中为0.1),则认为块b和b'构成块映射,执行步骤504;否则终止块映射之间的对齐发现;
步骤504,构造二部图g=(v,e,w)建模块b和b'之间候选匹配的类对之间的关系,g是一个无向加权图,其中,v是由b中包含的|cb|个类别和b'中包含的|cb'|个类别组成的顶点集合;e是cb和cb'之间所有候选匹配类对的之间边的集合;w:e→r(r是实数)是对e中每条边进行权重赋值的函数。具体地,对于块b中的每个类别c∈cb,建立其与块b'中可能与其匹配的类别之c'∈cb'间的映射(c,c',w),其中权重w是基于类别的向量表示计算。对每个(c,c',w)三元组,将c和c'添加到g的顶点集合v中并且将边(c,c')添加到e中,设置权值函数w(c,c')=w,其中w(c,c')的计算如下:
其中,c和c'是基于步骤102的本体编码器学习到的类别c和c'的语义表示。
步骤505,通过构建的块b和b'的二部图g=(v,e,w),执行二部图最大权匹配算法获得最大权匹配,本实施例中采用匈牙利算法计算g中的最大权匹配,从而获得块b和b'之间的类别的对齐结果;
通过对两个本体划分的块集合b和b'执行步骤502~步骤505,获得所有块映射的类别的对齐结果,从而获得两个本体的类别对齐结果。
进一步,在步骤105中,基于本体对齐结果,利用本体合并器合并两个本体的算法流程图如图8所示:
步骤601,输入待合并的源本体os=<c,p,r>和目标本体ot=<c',p',r'>,以及os和ot的类别对齐结果ast={<c,c'>|c∈os,c'∈ot};
步骤602,构造源本体os和目标本体ot之间集成的类别图。具体地,根据os和ot之间等价匹配的类别映射ast={<c,c'>|c∈os,c'∈ot}合并其中等价的类别,生成集成的类别图ig=(v,e),其中,v是本体os和ot中包含的所有的类别的并集,ast中等价的类别在ig中用一个顶点表示;e是由输入的本体中所有的类别的关系组成的边的集合,根据类别关系的来源在图ig中分别产生标记为s-edges的源边和标记为t-edges的目标边。
步骤603,遍历集成的类别图ig,对图中标记为s-edges的源边和标记为t-edges的目标边进行翻译,从而生成合并的本体om=<c”,p”,r”>。具体来说,分别按照以下三步遍历类别图ig:
第一步:判断图ig中是否存在环,若存在环则将环移除。由于输入的本体是无环的,所以ig中任何一个环都无法只包含s边(即标记为s-edges的源边)或者t边(即标记为t-edges的目标边)。因此,通过删除环中的一条s边的方式解除环,之所以选择这种方式是为了在最终的本体合并结果中维护目标本体的结构,而移除s边并不会改变目标结构。在这个过程中,按照如下方式选择环中需要删除的s边:如果环中抽象层级最高的类别来自于目标本体并且存在与之关联的s边,则删除该s边;否则,随机选择环中的一条s边删除。
第二步:对图ig中所有的t边进行翻译。对每条t边t=<v1,v2>(v1,v2∈v,为类别c1,c2对应的顶点),我们在v1,v2对应的集成的类别c1,c2之间创建父子关系r”(c1,c2)=hyponymy表示c1是c2的上位关系,c2是c1的下位关系,通过这种方式维护目标本体在合并的本体中的结构信息。值得注意的是,如果在ig中t边关联的顶点v1,v2之间存在一条仅包含s边的路径p并且p的长度大于1,在这种情况下,不创建c1,c2之间的关系,而是标记p中包含的所有的s边,然后按照下一步中ig中s边的翻译方式对这些边进行处理。这样做的原因在于,要在最终合并的结果中维护目标本体的结构,但是在源本体中,如果两个类别之间比其在目标本体中具有更详细的结构划分,则可以利用这种划分扩展合并的本体中c1,c2之间的结构信息。
第三步:对集成图ig中的s边进行翻译。s边的翻译是本体合并中最重要的一步,这是因为s边翻译的目的是将源本体中的剩余的类别正确集成到最终的合并结果中。具体地,首先获得ig中与s边关联的所有的叶子顶点的集合l,对于l中的每一个顶点,查找图ig中包含该叶子顶点的仅含s边的路径集合sp,对
本发明提出了一种融合表示学习和分治策略的大规模本体合并方法,能够通过表示学习方式获取本体组成要素在语义空间中的一种精细的语义表示,提升本体要素之间相似度度量的准确性,从而提升对齐发现的正确性,并且该方法通过分治策略,将大规模本体匹配的问题转化为小规模本体匹配的问题,降低大规模本体合并的执行时间,适应大规模本体合并的可扩展性需求。
当然,本发明还可以有其它多种实施例并不仅限于具体实施方式中所述的实施例,只要是本领域技术人员根据本发明的技术方案提出的其他的实施方式,同样属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!