一种基于主动学习的众包机制辅助排序方法和系统与流程
本发明涉及大数据分类算法领域,尤其涉及一种基于主动学习的众包机制辅助排序方法和系统。
背景技术:
众包机制是信息时代的产物,众包能够充分利用群众的创造性,成本低廉,深受信息化公司的青睐。但是过多单一性的数据标注任务采用众包的方式,不仅耗费时间,也会耗费大量的人力资源,影响工作的效率。
此外,一些分类算法缺乏主动学习机制,导致分类精度和效率偏低,如何既节省人力又能提高分类精度成为目前大数据领域的一大难题。
技术实现要素:
鉴于以上现有技术存在的问题,本发明提出一种基于主动学习的众包机制辅助排序方法和系统,主要解决现有算法分类不便的问题。
为了实现上述目的及其他目的,本发明采用的技术方案如下。
一种基于主动学习的众包机制辅助排序方法,包括:
收集的答案组成答案对,构成训练数据;
从训练数据中选择一组训练数据输入训练集,得到初始分类模型;
获取高分类贡献度的训练数据进行众包标注;
将标注的数据更新到训练集中,得到新的分类模型;
若所述新的分类模型精度未达到设定值,则继续更新训练集,训练新的分类模型;若更新后的分类模型精度达到设定值,则停止更新;
将测试集输入精度达标的分类模型,对结果进行打分排序。
可选地,所述从训练数据中选择一组训练数据输入训练集具体包括对所述训练数据进行特征提取得到特征向量,通过特征向量训练分类模型。对特征向量进行降维操作或其他降低复杂的的处理,可提高模型的训练效率。
可选地,所述分类模型包括多个子分类器,所述子分类器从训练数据中选出高分类贡献度的训练数据。评价方式可采用投票方式,投票结果结果用于评判训练数据的分类贡献度。
可选地,所述分类贡献度的评判标准为,所述子分类器投票结果不一致占比越高的的训练数据,分类贡献度越高。分类贡献度高的数据用于训练,可提高分类模型的复杂度和精度。
可选地,所述收集的答案彼此不重复成对。防止重复的训练数据提高人工标注成本以及对分类模型产生负面影响。
可选地,所述众包机制对训练数据进行标注,将训练数据发送给特定人员对每个答案在所处答案对中的质量好坏进行评价,形成二分类质量标签。所述特定人员为专家组,对高分类贡献度的数据进行人工标注,提高答案质量评价的准确度,降低错误人工标注的干扰。质量标签用于对训练数据进行排序打分。
一种基于主动学习的众包机制辅助排序系统,包括:
训练数据集,收集答案,构建答案对作为训练数据;
标注模块,对训练数据进行标注;
训练模块,对已标注数据进行特征提取,得到特征向量用于训练分类模型;
选择模块,从训练数据集中选出一组训练数据供评审模块选择;
评审模块,包括多个子分类器,从一组训练数据中选出高分类贡献度的数据,输出给标注模块;
打分排序模块;用于对训练精度达到设定精度的分类模块的输出结果进行评分,并按照分数排序。
可选地,所述选择模块每次决策从训练数据中获取一组数据;通过评审模块对训练数据的质量进行评价,获取获取质量评价不一致占比高的训练数据作为高分类贡献度的数据。
可选地,所述标注模块采用众包机制进行标注,将选择模块得到的高分类贡献度数据发送给特定人员进行人工标注,并将标注的数据发送给训练模块,更新分类模型。
可选地,若分类模型分类精度未达标,则评审模块再获取对选择模块的训练数据进行质量评价,将高分类贡献度数据发送给标注模块,将标注后的数据用于更新训练模块得到新的分类模型,重复迭代动作,直到更新后的分类模型分类精度达到设定值。对初始训练模型进行迭代更新,不断将高分类贡献度的训练数据用于训练分类模型,可以提高分类模型的精度和效率。
如上所述,本发明一种基于主动学习的众包机制辅助排序方法和系统,具有如下的有益效果。
挑选高分类贡献度的样本进行众包标注,减少了人工标注的工作量,提高工作效率。
附图说明
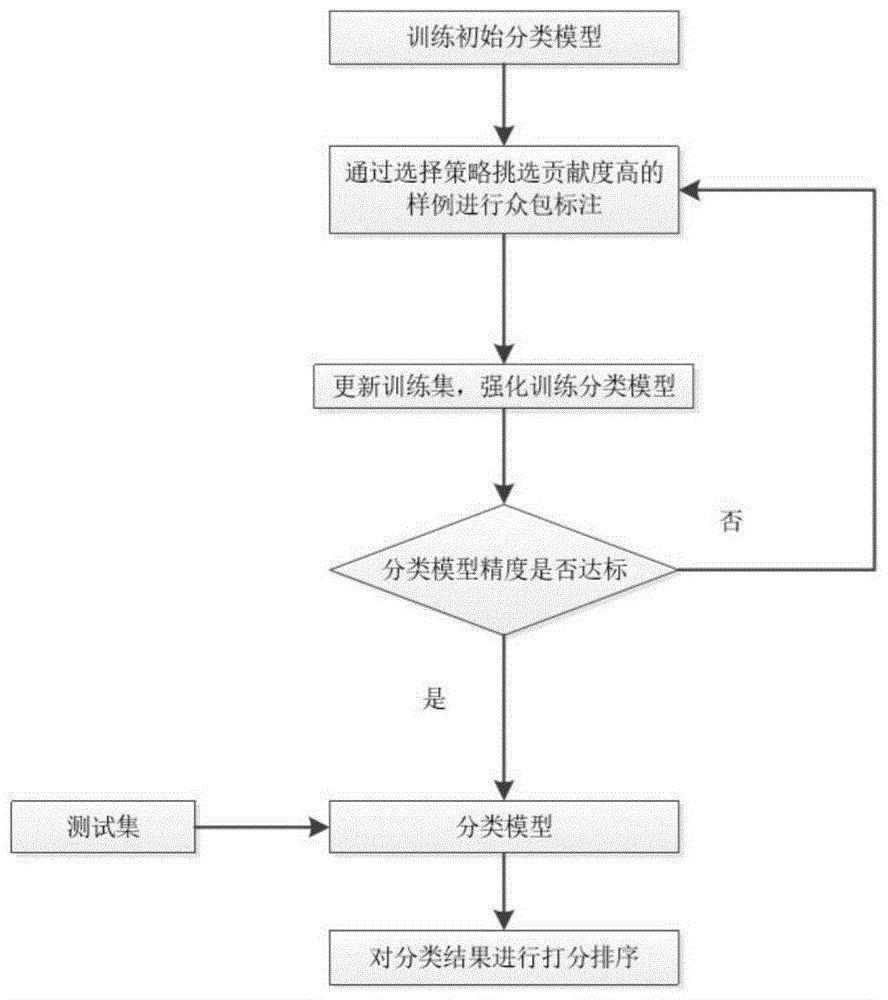
图1为本发明一种基于主动学习的众包机制辅助排序方法的流程图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
请参阅图1,本发明提供一种基于主动学习的众包机制辅助排序方法,包括:
将收集的答案组成答案对,构成训练数据;
从训练数据中选择一组训练数据输入训练集,得到初始分类模型;
获取高分类贡献度的训练数据进行众包标注;
将标注的数据更新到训练集中,得到新的分类模型;
若所述新的分类模型精度未达到设定值,则继续更新训练集,训练新的分类模型;若更新后的分类模型精度达到设定值,则停止更新;
将测试集输入精度达标的分类模型,对结果进行打分排序。
在一实施例中,答案数据可以通过爬取百度、知乎等问答社区的方式获取,将收集的答案组成答案列表。
将答案列表中的答案组成答案对,并保证每个答案对中的数据彼此不重复成对。得到的答案对作为训练数据。
从训练数据中选择设定数量的训练数据,并将选定的数据输入训练集中,对选定的训练数据进行特征提取,得到特征向量。在一实施例中,可以对特征向量进行降维,降低特征向量的复杂度,提高训练效率。
将得到的训练数据对应的特征向量用于训练分类模型,得到初始分类模型。
所述分类模型包含若干个子分类器,所述子分类器根据选择策略从所述一组训练数据中选出高分类贡献度的训练数据。
所述高分类贡献度的评判标准为,所述子分类器投票结果不一致占比越高的的训练数据,分类贡献度越高。这是鉴于越容易分类错误的样本含有的分类信息越丰富。用于度量这种不一致程度的选择策略包括:投票熵(voteentropy)、kl散度(kull-back-leiblerdivergence)、js(jensen-shannon)。
在一实施例中,可以采用投票熵策略,通过子分类器投票的方式选出高分类贡献度的训练数据。输入训练数据e的投票熵定义如下。
其中v(c,e)表示训练数据e被分类为类别c的子分类器的数量。k表示子分类器的总数量,c为分类类别总数,c为具体的类别。
通过所述子分类器通过选择策略选择出训练数据中若干个投票结果最不一致的训练数据,发送给特定的人员进行人工标注。这里的特定人员一般为专家组。由于训练数据分类贡献度高,普通的标注人员很难给出准确的训练数据质量的判断,而错误的标注将对分类模型的训练产生干扰,因此,设置专家组进行人工标注,对训练数据的质量进行评价,有利于提高训练精度和效率。
由于标注人员的差异,对于有争议的标注结果,采用投票机制,选出票数最多的训练数据对应的标注标签,作为训练数据的最终质量标签。
设训练数据为答案对<ai,aj>,令<ai,aj>=1表示答案ai的质量高于答案aj,<ai,aj>=0表示答案ai的质量不高于答案aj。
将标注的训练数据输入训练集,对训练集的特征向量进行更新,并更新后的特征向量训练分类模型,得到新的分类模型。判断新的分类模型的精度是否达到设定值。
若分类模型分类精度未达标,则子分类器再对新选出的训练数据进行质量评价,将高分类贡献度数据发送给专家组进行人工标注,将标注后的数据用于更新训练集得到新的分类模型,重复迭代动作,直到更新后的分类模型分类精度达到设定值。对初始训练模型进行迭代更新,不断根据高分类贡献度的训练数据训练分类模型,可以提高分类模型的精度和效率。
构建测试集,构建测试集的方法与构建训练数据集的方法相同,这里不在赘述。
采用训练好的分类模型对测试集进行预测,预测后将得到0或1质量标签,将0或1转换为[0,100]之间的分数,通过打分函数对分类结果进行打分。在一实施例中,所述打分函数如下。
其中
得到每个测试答案的质量得分后,根据质量得分对答案进行排序。
本发明提供一种基于主动学习的众包机制辅助排序系统,包括:
训练数据集,收集答案,构建答案对作为训练数据;
标注模块,对训练数据进行标注;
训练模块,对已标注数据进行特征提取,得到特征向量用于训练分类模型;
选择模块,从训练数据集中选出一组训练数据供评审模块选择;
评审模块,包括多个子分类器,从一组训练数据中选出高分类贡献度的数据,输出给标注模块;
打分排序模块;用于对训练精度达到设定精度的分类模块的输出结果进行评分,并按照分数排序。
在一实施例中,答案数据可以通过爬取百度、知乎等问答社区的方式获取,将收集的答案组成答案列表。
将答案列表中的答案组成答案对,并保证每个答案对中的数据彼此不重复成对。得到的答案对作为训练数据,构成训练数据集。
从训练数据集中选择设定数量的训练数据,并将选定的数据输入训练模块中,对选定的训练数据进行特征提取,得到特征向量。在一实施例中,可以对特征向量进行降维,降低特征向量的复杂度,提高训练效率。
将得到的训练数据对应的特征向量用于训练分类模型,得到初始分类模型,构成评审模块。
所述初始分类模型包含若干个子分类器。
所述选择模块每次从训练数据集中选出一组训练数据,所述子分类器根据选择策略从所述一组训练数据中选出高分类贡献度的训练数据。
所述高分类贡献度的评判标准为,所述子分类器投票结果不一致占比越高的的训练数据,分类贡献度越高。这是鉴于越容易分类错误的样本含有的分类信息越丰富。用于度量这种不一致程度的选择策略包括:投票熵(voteentropy)、kl散度(kull-back-leiblerdivergence)、js(jensen-shannon)。
在一实施例中,可以采用投票熵策略,通过子分类器投票的方式选出高分类贡献度的训练数据。输入训练数据e的投票熵定义如下。
其中v(c,e)表示训练数据e被分类为类别c的子分类器的数量。k表示子分类器的总数量,c为分类类别总数,c为具体的类别。
通过所述子分类器通过选择策略选择出训练数据中若干个投票结果最不一致的训练数据,将数据输入标注模块,标注模块将得到的训练数据发送给特定的人员进行人工标注。这里的特定人员一般为专家组。由于训练数据分类贡献度高,普通的标注人员很难给出准确的训练数据质量的判断,而错误的标注将对分类模型的训练产生干扰,因此,设置专家组进行人工标注,对训练数据的质量进行评价,有利于提高训练精度和效率。
由于标注人员的差异,对于有争议的标注结果,采用投票机制,选出票数最多的训练数据对应的标注标签,作为训练数据的最终质量标签。
设训练数据为答案对<ai,aj>,令<ai,aj>=1表示答案ai的质量高于答案aj,<ai,aj>=0表示答案ai的质量不高于答案aj。
将标注的训练数据输入训练模块,对训练模块中的特征向量进行更新,并更新后的特征向量训练分类模型,得到新的分类模型。判断新的分类模型的精度是否达到设定值。
若分类模型分类精度未达标,则评审模块再获取对选择模块的训练数据进行质量评价,将高分类贡献度数据发送给标注模块,将标注后的数据用于更新训练模块得到新的分类模型,重复迭代动作,直到更新后的分类模型分类精度达到设定值。对初始训练模型进行迭代更新,不断将高分类贡献度的训练数据用于训练分类模型,可以提高分类模型的精度和效率。
构建测试集,构建测试集的方法与构建训练数据集的方法相同,这里不在赘述。
采用训练好的分类模型对测试集进行预测,预测后将得到0或1质量标签,将0或1转换为[0,100]之间的分数,通过打分函数对分类结果进行打分。在一实施例中,所述打分函数如下。
其中
得到每个测试答案的质量得分后,根据质量得分对答案进行排序。
综上所述,本发明一种基于主动学习的众包机制辅助排序方法和系统,引入选择策略选出高分类贡献度的数据作为训练样本,降低了训练成本的同时提高了训练效率,减少人工标注成本。所以,本发明有效克服了现有技术中的种种缺点而具高度产业利用价值。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!