一种基于超分辨率对抗生成级联网络的SAR小样本识别方法与流程
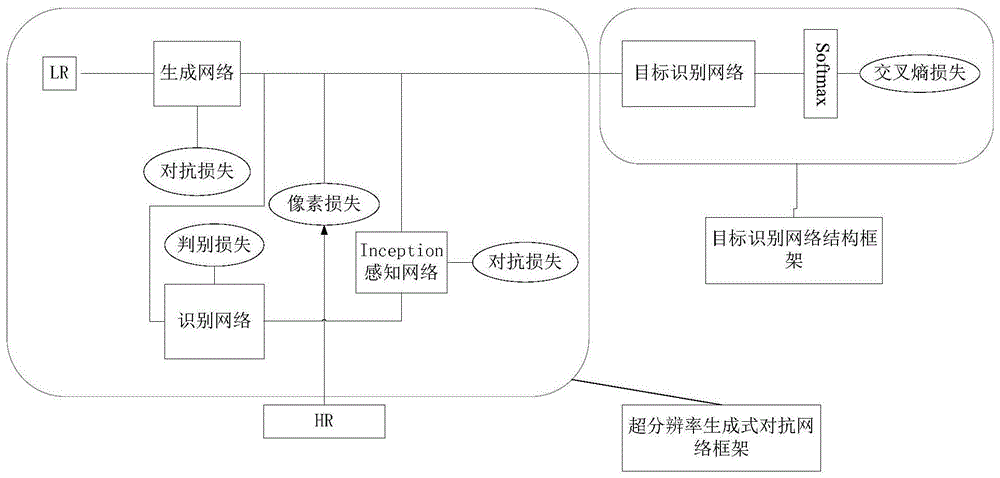
本发明属于雷达数据处理领域,具体涉及一种基于超分辨率对抗生成级联网络的sar小样本识别方法。
背景技术:
合成孔径雷达即sar,是一种主动式微波成像传感器,通过发射宽带信号,结合合成孔径技术,sar能在距离向和方位向上同时获得二维高分辨率图像。与传统光学遥感和高光谱遥感相比,sar具备全天候、全天时的成像能力,还有一定的穿透性,获得的图像能够反映目标微波散射特性,是人类获取地物信息的一种重要技术手段。sar已被广泛应用于民生领域,是实现自然资源普查、自然灾害监测等的重要技术手段。
随着sar技术的日益成熟,其在自然灾害监测等领域得到了较为广泛的应用,具有较高的研究价值。通过对sar图像目标的分类识别,可以快速有效地获取目标信息。sar图像反映了电磁波后向散射强度,同时具有几何特征及电磁特征,是一种高分辨率雷达图像。因此,sar图像解释是一项复杂工程,而利用人工对sar图像进行判别将耗费大量资源,这说明在sar自动目标识别领域需要高效的算法。
sar目标识别是指对目标散射回波信号进行分析,从中提取信号特征与目标属性特征,并对目标的类别与属性进行判别。sar图像不似光学图像那样直观、边缘易于检测,需要通过计算机对获取的目标信息进行处理,再与数据库中已知的目标特征行比较与测量,从而达到自动识别目标的目的。近十几年来,sar目标识别技术在理论研究方面已取得众多成果,但距实际应用还有很大差距。
这是因为虽然sar图像往往拥有超高的分辨率,但是因为sar的囊括的空间尺度巨大,对高分辨率的sar图像进行目标分割后所产生出的目标图像极小,分辨率低。而且由于环境复杂,以及sar存在的相干斑噪声等因素,当需要对图像中的目标进行识别时,通常无法使用常规方法,需要对复杂环境的sar图像进行降噪,并使用目标分割技术将目标从高分辨率sar图像中分割出来,进行相应的目标识别。
目前,深度学习技术的发展,其在诸多领域都取得了令人瞩目的成果,这也加快了深度学习技术在更多复杂场景的应用。而计算机视觉领域的相关问题更是在深度学习技术的加持下取得了长足的发展。深度学习技术是以神经网络为基础的机器学习技术,较为经典的深度学习网络如深度卷积神经网络即cnn,其网络结构使得模型具备了强大的特征提取和分类的能力,已能较好的实现一般情况下的目标的检测与识别。而基于深度学习技术的sar图像分析处理也成为了当前的研究热点,许多研究正利用cnn,来尝试解决sar小样本识别中,低分辨率条件下的目标识别问题。虽然在部分领域取得了较好的效果,但是仍然存在很多不足。这是因为sar小样本识别中存在特征模糊,目标易混淆的特性。
生成式对抗网络,是近年来复杂分布上无监督学习最具前景的方法之一。生成式对抗网络包含两个基本模块:生成模型g和判别模型d;模型的输入为随机高斯白噪声信号z,该噪声信号经由生成模型g映射到某个新的数据空间,得到生成数据g(z);接下来,由判别网络d根据真实数据x与生成数据g(z)的输入来分别输出一个概率值,表示d判断输入是真实数据还是生成其他数据的置信度,以此判断g的产生数据的性能好坏。
本发明创新地提出一种基于超分辨率对抗生成级联网络的sar小样本识别方法。本发明设计一个超分辨率对抗生成网络即srgan,生成对抗网络模型用于分别用于提升sar小样本识别中图像的分辨率,以及一个针对sar图像特点的inception-resnet-v2深度神经网络进行目标识别,在提高样本质量的同时,提高sar小样本识别的准确度。
技术实现要素:
为解决sar小样本识别问题中图像分辨率低,识别准确度低的问题。本发明提供一种基于超分辨率对抗生成级联网络的sar小样本识别方法。
一种基于超分辨率对抗生成级联网络的sar小样本识别方法,该方法包括以下步骤:
步骤1:通过大量的无标签sar地图数据库对srgan预训练进行训练;
步骤2:通过现有的目标识别识别数据库对inception目标识别网络进行预训练;
步骤3:将超分辨率网络和分类网络级联之后,再次使用带有标签的数据对整体网络进行训练;
步骤4:新的sar目标样本通过该网络得到识别结果。
步骤2所述的通过现有的目标识别识别数据库对inception目标识别网络进行预训练,训练生成函数{g(z)}用于生成指定lr输入的hr输出图像,训练inception网络用做感知网络用于提取最终hr图像中的高级特征,包括以下步骤:
步骤1.1:将低分辨率图像lr输入至生成网络中,得到生成的高分辨率图像sr;
步骤1.2:将高分辨率图像sr和原始真实图像hr共同输入至判别网络中,得到判别网络识别图像样本真假的准确率,即识别原始真实图像hr和高分辨率图像sr的准确率;
步骤1.3:反馈至生成模型中;
步骤1.4:生成模型网络和判别模型网络形成对抗。
步骤1.2所述的将高分辨率图像sr和原始真实图像hr共同输入至判别网络中,其中超分辨率使用基于像素的mse损失来训练,基于像素的mse损失的计算方法表示为:
其中,r是放大倍数,w为图像的长像素值,h为图像的宽像素值,
其中,
其中,
步骤2所述的通过现有的目标识别识别数据库对inception目标识别网络进行预训练,利用inception损失来预测感知损失,表示为:
其中,wi,j和hi,j分别表示inception网络中各自特征的维度,φi,j表示在第i个inception模块之后第j个inception模块之前所提取的样本特征,其中ihr表示高清图片,ilr表示低清图片,x,y示图像上的(x,y)坐标点的像素值。
步骤3所述的将超分辨率网络和分类网络级联之后,再次使用带有标签的数据对整体网络进行训练,其中基于inception的感知网络以中间层输出作为输入,目标识别网络以超分辨率生成式对抗网络输出的超分辨图片作为输入,利用超分生成对抗网络以及inception-renet-v2网络,inception-resnet-v2网络包括inception-a、inception-b和inception-c三种inception结构,inception-resnet-v2网络包括stem层、4个inception-a层,reduction-a层、7个inception-b层、reduction-b层、3个inception-c层,最后通过averagepooling层,即平均池化层,和softmax输出结果,同时在网络中使用dropout,认证损失的交叉熵损失计算表示为:
其中,p(m)表示模型输出的标签为m的时候的概率,假设y为真实的id标签,因此对于所有的m≠y,有q(y)=1,q(m)=0,最终,所有的损失函数合并在一块,表示为:
本发明的有益效果在于:
利用超分生成对抗网络以及inception-renet-v2网络,优化其网络结构以及损失函数,使得在提高样本质量的同时,提高sar小样本识别的准确度。
附图说明
图1为本发明的总体技术路线。
图2(a)为本发明的超分辨率生成模型网络。
图2(b)为本发明超分辨率判别模型网络示意图。
图3为inception初始结构。
图4为inception-resnet-v2网络结构图。
图5(a)为inception-a网络结构示意图。
图5(b)为inception-b网络结构示意图。
图5(c)为inception-c网络结构示意图。
图6为基于超分辨率对抗生成级联网络的sar小样本识别方法流程图。
具体实施方式
下面结合附图对本发明做进一步描述。
为解决sar小样本识别问题中图像分辨率低,识别准确度低的问题。本发明提供一种基于超分辨率对抗生成级联网络的sar小样本识别方法。其具体实施方案如下:
(1)通过大量的无标签sar地图数据库对srgan预训练进行训练,具体实施步骤如下:
①将低分辨率图像(lr)输入至生成网络中,得到生成的高分辨率图像(sr)。生成模型结构参考了resnet网络结构。本发明提出的生成模型g,相比前人提出的模型,具有更深的网络结构。共使用了16个具有相同结构的参数块(residualblocks),首先使用了两个卷积核大小为3×3,64个特征映射的卷积层,在每一个卷积层后使用parametricrelu作为激活函数。
②进一步地,将高分辨率图像(sr)和原始真实图像(hr)共同输入至判别网络中,得到判别网络识别图像样本真假的准确率。判别模型d的网络结构包含8个卷积层,每个卷积层采用3×3大小的卷积核,在每一个卷积层后采用批规范化来防止梯度消失,同时加强模型的收敛速度;并采用leakyrelu(α=0.2,设定α为一个可通过反向传播算法学习的变量)作为激活函数。在得到512大小的featuremap后,经过两个全连接层,通过一个sigmoid激活函数,最终获得样本分类的概率,也就是样本是实际图像而不是生成图像的概率。基于像素的mse损失的计算方法如下:
其中r是放大倍数,w,h图像的长宽像素值,
反馈至生成模型中,使生成模型生成图像能力得到提高。
对抗损失:除了上面描述的图像内容的损失之外,本发明添加了一个生成组件。除了判别模型的损失之外,基于所有训练样本上的判别网络的概率来定义对抗性损失。它表示为:
此处
③进而,生成模型网络和判别模型网络形成对抗,互相提升。其中在判别器判别时,会产生判别损失,具体如下:
当判断真实图像
此处
对于生成模型g,它用来生成sar小样本的高分辨率图像(sr)。判别模型d用来评估生成模型g所生成的图像的视觉质量。
(2)通过现有的目标识别识别数据库对inception目标识别网络进行预训练。具体网络模型如图3。
利用inception损失以期达到感知上的相似。感知损失如式:
其中,wi,j和hi,j分别表示inception网络中各自特征的维度,φi,j表示在第i个inception模块之后第j个inception模块之前所提取的样本特征,其中ihr表示高清图片,ilr表示低清图片,x,y示图像上的(x,y)坐标点的像素值。
(3)将超分辨率网络和分类网络级联之后,再次使用带有标签的数据对整体网络进行训练。利用超分生成对抗网络以及inception-renet-v2网络,具体网络模型如图4。inception-resnet-v2网络,其中包括inception-a、inception-b和inception-c三种inception结构,如图5(a)、图5(b)和图5(c)。
相比最初版本的inception结构,inception-resnet-v2主要有以下几点不同:
a)在每个inception结构中的卷积层前增加了一个1×1大小的卷积层,从而减少权重大小和特征维度;
b)使用两个3×3大小的卷积层代替了原有inception中5×5的卷积层,从而实现网络深度的增加;
c)提出了卷积分解,将7×7的卷积核分解为1×7和7×1两个卷积核,这样使得网络深度进一步增加,同时增加了网络的非线性;
d)对于inception结构中每一个卷积结构,都使用了残差连接,使得训练加速,收敛速度更快,精度更高。
inception-resnet-v2网络包括stem层、4个inception-a层,reduction-a层、7个inception-b层、reduction-b层、3个inception-c层,最后通过averagepooling层(平均池化层)和softmax输出结果,同时为了减小过拟合的风险,在网络中使用dropout。
给出一个原始图像
为了简化这一方程,本发明忽略了m和i之间的关联。认证损失的交叉熵损失计算如式:
其中p(m)表示模型输出的标签为m的时候的概率,假设y为真实的id标签,因此对于所有的m≠y,有q(y)=1,q(m)=0。在这种情况下,最小化识别损失等同于最大化被分配到真实样本类的可能性。
最后,基于inception网络的目标识别网络用作目标判别网络训练的时候使用了交叉熵损失
为了方便,这些损失之间的权重本发明采用一样的均值来平衡。
(3)新的sar目标样本通过该网络得到识别结果。
本发明首先通过大量的无标签sar地图数据库对srgan预训练,之后通过现有的目标识别识别数据库对基于inception的目标识别网络进行预训练,将超分辨率网络和分类网络级联之后,再次使用带有标签的数据对整体网络进行训练。其中基于inception的感知网络以中间层输出作为输入,目标识别网络以超分辨率生成式对抗网络输出的超分辨图片作为输入。
本发明利用超分生成对抗网络以及inception-renet-v2网络,优化其网络结构以及损失函数,使得在提高样本质量的同时,提高sar小样本识别的准确度。
- 还没有人留言评论。精彩留言会获得点赞!