一种微商城的商品推荐方法与流程
本发明涉及商品的推荐方法,特别是一种微商城的商品推荐方法。
背景技术:
随着科技的进步和网络的发展,网络信息的发布非常方便快捷,其平台也变得多元化,包括各种网站,社交软件等,使得网络信息已经不再匮乏。大量的信息对于用户和管理者都是一个难题,如何在信息海洋中快速过滤冗余信息,获取有效信息成为人们面临的共同问题。在微商城中,商家很难根据每天海量的访问进行有针对性的推送和商品展示。
微商城未来发展不可限量。微商城集产品展示、移动购物、快捷支付与一体,具备品牌传播、在线销售、精准营销等平台优势,为广大企业提供了一种崭新的移动社交电商新模式。其实大家看重微信商城,或者是想要尝试一下微商城,主要是因为看到了电商的未来发展。现在电商网站非常多,但是从流量和影响力上来讲,当然微商城的影响力还是最大的,毕竟现在几乎是全民皆电商。近年来微商城发展迅猛,微商城的优势如下1.费用低,这个是最大的优势了,相比各种电商平台、自建平台而言,微商城费用的优势尤为明显,即便是算上定制打通erp、crm等各种数据后的费用也不过数万元,这对动辄上百万的自建平台费用少了不少,几万元的费用对于连锁超市而言,也不是一笔会伤筋动骨的费用,可以说成本非常低。2.投入小,这里说的投入小不止是费用的投入小,还有人员配置的投入,基本上员工兼职做就足够了,也不用请专门的管理人员,等多配置一两个微商城的营销推广人员。3.互动效果好,微商城是主要还是依附于微信开发的商城平台,现在使用微信的人非常多,微信公众号也支持各种抽奖、问答等直接互动,互动效果好。
微商城的应用场景十分广阔可以适合生鲜行业等符合o2o形式的应用场景;微商城在线下场景的应用主要就是实体店的应用了。在这个场景中可以有两种用法,一种是通过实体店销售员推广微商城二维码给用户第二种用法就是让实体店的销售更加便捷的做法,用户通过扫描二维码就可以将自己在实体店中看中的商品线上下单付款,之后直接到收银台拿取商品即可;在线上场景的应用上,就是纯粹的微信电商了。微商城利用微信这个线上平台去经营商城,它具有独立性,所以有别于一些第三方电商平台,不会受到条条框框的限制,商家可以按照自己的需求与想法去开发微商城、运营微商城。但目前微商城在商品推荐方面存在以下问题:商品的推荐方法仅是盲目地对推荐具有相似度地商品,其推荐的商品,交易成功几率低。
技术实现要素:
本发明的目的在于,提供一种微商城的商品推荐方法。本发明能够提高交易成功几率和提高用户体验。
本发明的技术方案:一种微商城的商品推荐方法,按下述步骤进行:
a.采集商品的实时动态数据;
b.对实时动态数据预处理得到下述预处理数据:消费者对同一类商品属性的判定依据、消费者喜好度高的商品属性、消费者购物倾向;
c.根据预处理数据重构商品属性;
d.将重构的商品属性输入基于内容的推荐算法得到商品相似度数据集;将重构的商品属性输入基于用户的协同滤波算法得到相似喜好用户数据集;
e.用户浏览商品a时,根据商品相似度数据集中消费者对同一类商品的定义,将相似商品b同时推送给用户;
f.用户浏览商品a时,根据相似喜好用户数据集中用户的相似喜好,将商品a推荐给具有相似喜好的其他用户。
前述的微商城的商品推荐方法所述步骤b中,实时动态数据预处理具体为:清洗掉实时动态数中与商品无关的数据及重复数据;之后集成多个含有用户-商品信息的数据源。
前述的微商城的商品推荐方法所述步骤c中,重构商品属性按下述步骤进行:
c1.词频统计:对预处理数据中带有用户感情色彩的词语采用tf-idf技术进频率统计;
c2.重构商品属性:将用户描述一类商品出现频率最高且具有感情色彩的词语通过情感词典判定后整理并标注出来,并用这些词语重新定义商品的属性;所述的属性包括结构化属性与非结构化属性;所述结构化属性为,意义明确,其取值限定在一定范围的属性;所述的非结构化属性为意义模糊,取值无限制的属性;所述的结构化属性直接用于定义商品属性;所述的非结构化属性转化为结构化属性后用于定义商品属性。
前述的微商城的商品推荐方法所述步骤d中,所述的将重构的商品属性输入基于内容的推荐算法得到商品相似度数据集,按下述步骤进行:
d1.找到用户感兴趣的历史商品集合:根据用户实时动态数据判断用户对商品的喜好程度,找到用户感兴趣的历史商品集合;喜好程度根据实时动态数据及历史数据中关键词的权重,关键词权重采用tfidf算法计算;
d2.找到商品集合的具体内容:根据步骤d1中的历史商品集合,统计商品的种类、属性,找到商品集合的具体内容;
d3.抽象商品集合的具体内容的共性;
d4.通过所述的共性查找其他商品并实施推荐:根据用户历史喜欢的商品共同属性,根据相似度找到相似商品集,实现最终推荐。
前述的微商城的商品推荐方法所述步骤d中,所述的将重构的商品属性输入基于用户的协同滤波算法得到相似喜好用户数据集,按下述方法进行:将当前用户对所有商品的偏好作为向量来计算用户之间的相似度;之后基于用户对商品的偏好找到相邻的邻居用户;找到邻居用户后,根据邻居用户的相似度权重及其对商品的偏好,预测当前用户没有偏好的未涉及商品,计算得到一个排序的商品列表作为推荐。
前述的微商城的商品推荐方法所述步骤a中,所述的实时动态数据包括用户评论、问答、点击率和浏览量。
有益效果
与现有技术相比,本发明根据采集的实时动态数据重构商品属性;通过该方法,能够实时掌握商品消费的最新、最准确情况,同时将重构的商品属性分别输入基于内容的推荐算法和基于用户的协同滤波算法,得到商品相似度数据集和相似喜好用户数据集;通过该方法,商家不仅能够得到最受消费者喜爱的商品类型,向用户推荐最受喜爱的商品,而且还能有针对性地将商品推荐给具有共同喜好的其他用户,进而最大程度地挖掘商品的潜在销售价值,加速商品的流通速度,增进商家运营效益,提高交易成功几率。本发明根据相似喜好用户数据集将符合消费者喜好属性的商品推荐给消费者,帮助消费者快速准确的查找自己喜欢的商品,帮助用户从海量内容中快速找到想要阅读的信息,从海量商品中快速找到想要购买的商品,提高用户体验。本发明的数据实时更新,根据用户最近浏览的商品推荐相类似的商品,相关商品按照用户历史浏览购买时间向下推荐,非常容易找到大量浏览喜好的商品,节约了商品寻找时间,帮助用户选择喜欢的商品。本发明利用用户的访问信息(实时动态数据),通过用户群的相似性进行产品推荐,不依赖于内容,仅依赖于用户之间的相互推荐,避免了内容过滤的不足,保证信息推荐的质量。
附图说明
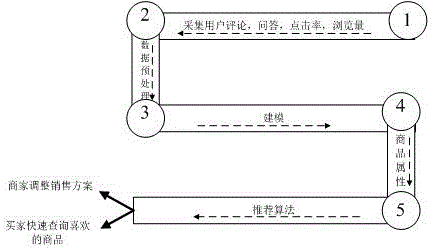
图1是本发明的流程图;
图2是本发明的技术路线图;
图3是推荐算法在商品推荐中的基本流程图;
图4是基于用户的协同滤波推荐算法的基本原理图。
具体实施方式
下面结合附图和实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
实施例1。一种微商城的商品推荐方法,如图1-4所示,按下述步骤进行:
按下述步骤进行:
a.采集商品的实时动态数据;
b.对实时动态数据预处理得到下述预处理数据:消费者对同一类商品属性的判定依据、消费者喜好度高的商品属性、消费者购物倾向;
c.根据预处理数据重构商品属性;
d.将重构的商品属性输入基于内容的推荐算法得到商品相似度数据集;将重构的商品属性输入基于用户的协同滤波算法得到相似喜好用户数据集;
e.用户浏览商品a时,根据商品相似度数据集中消费者对同一类商品的定义,将相似商品b同时推送给用户;
f.用户浏览商品a时,根据相似喜好用户数据集中用户的相似喜好,将商品a推荐给具有相似喜好的其他用户。
前述的步骤b中,实时动态数据预处理具体为:清洗掉实时动态数中与本商品无关的数据及重复数据;之后集成多个含有用户-商品信息的数据源。
前述的步骤c中,重构商品属性按下述步骤进行:
c1.词频统计:对预处理数据中带有用户感情色彩的词语采用tf-idf技术进频率统计;
c2.重构商品属性:将用户描述一类商品出现频率最高且具有感情色彩的词语通过情感词典判定后整理并标注出来,并用这些词语重新定义商品的属性;所述的属性包括结构化属性(structured)与非结构化属性(unstructured);所述结构化属性为,意义明确,其取值限定在一定范围的属性;所述的非结构化属性为意义模糊,取值无限制的属性;所述的结构化属性直接用于定义商品属性;所述的非结构化属性转化为结构化属性后用于定义商品属性。对于非结构化属性,往往其意义不太明确,取值也没什么限制,不好直接使用,所以需要先转化为结构化属性使用。
前述的步骤d中,所述的将重构的商品属性输入基于内容的推荐算法得到商品相似度数据集,按下述步骤进行:
d1.找到用户感兴趣的历史商品集合:根据用户实时动态数据判断用户对商品的喜好程度即购买意愿倾向,找到用户感兴趣的历史商品集合;喜好程度根据实时动态数据及历史数据中关键词的权重,关键词权重采用tfidf算法计算;
d2.找到商品集合的具体内容:根据步骤d1中的历史商品集合,统计商品的种类、属性,找到商品集合的具体内容;
d3.抽象商品集合的具体内容的共性;
d4.通过所述的共性查找其他商品并实施推荐:根据用户历史喜欢的商品共同属性即共性,根据相似度找到相似商品集,实现最终推荐。
通过用户历史感兴趣的信息,抽象信息内容共性,根据内容共性推荐其他信息。基于内容的推荐算法能够很好地解决冷启动问题,并且也不会因为热度商品而受限制,因为它是直接基于内容匹配的,而与浏览记录无关。
前述的步骤d中,所述的将重构的商品属性输入基于用户的协同滤波算法得到相似喜好用户数据集,按下述方法进行:将当前用户对所有商品的偏好作为向量来计算用户之间的相似度;之后基于用户对商品的偏好找到相邻的邻居用户;找到邻居用户后,根据邻居用户的相似度权重及其对商品的偏好,预测当前用户没有偏好的未涉及商品,计算得到一个排序的商品列表作为推荐。
具体地,基于用户对物品的偏好找到相邻的邻居用户,然后将邻居用户喜欢的且当前用户没有表现出对其有偏好的物品推荐给当前用户。在计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到k邻居后,根据邻居的相似度权重及其对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。如下图4给出的例子,根据用户的历史偏好,可得到用户1和用户3为邻接用户,然后将用户3喜欢的商品d推荐给用户1。邻居用户的计算:首先建立用户物品的关联矩阵,行向量为不同的用户,列向量为物品,(x,y)的值则是x用户对y物品的喜好程度,我们可以把每一行视为一个用户对物品偏好的向量,然后计算每两个用户之间的向量距离,这里我们用余弦相似度来算:
然后得出用户向量之间的相似度,值越接近1表示这两个用户越相似。
前述的步骤a中,所述的实时动态数据包括用户评论、问答、点击率和浏览量。
- 还没有人留言评论。精彩留言会获得点赞!