一种基于全卷积神经网络的单目相机室外三维重建方法与流程
本发明属于计算机视觉、计算机图形学技术领域,特别地,本发明涉及一种基于全卷积神经网络的单目相机室外三维重建方法。
背景技术:
三维重建是计算机视觉与计算机图像学领域中一个重要且基础的问题,它在农业、医疗、航天、军事、环境观测、地形勘探等领域有着非常广泛的应用。而其中的一个小分支——对城市场景进行室外三维重建则可在地图导航、城市规划等领域起到重要作用。在过河城市的三维地图后,人们可以通过各种电子设备很方便地查看城市任何一个角落的样子,谷歌地图在这方面就是一个很成功的例子。通过与虚拟现实和增强现实技术相结合,再集成生活资讯、电子商务、虚拟社区等功能与服务,可以带给人们更加沉浸式的体验。因此,室外三维重建的研究具有极高的科研和应用价值。
在计算机图形学领域,单目相机的三维重建一直是一个重要且具有挑战性的问题。虽然单目相机不能像双目相机和深度相机那样通过三角测距或者tof、结构光原理直接获取每一个像素的深度信息,但是经过长期发展,单目相机的技术相对成熟,成本较低,结构简单,对计算资源的要求不高,更容易商业化,比如人手一只的智能手机标配的摄像头就是很好的单目相机。因此,本发明的方法利用经过监督学习的方式训练好的全卷积神经网络对单目相机获取的每一张图片进行深度估计,然后将其融合成一个完整的三维模型,从而完成三维重建。
技术实现要素:
本发明旨在提供一种有用的解决方案。为此本发明的目的在于解决单目相机的三维重建问题,其输入为多张由单目相机拍摄的室外场景的图片,发明中的方法分别单独对每一张图片进行深度估计,最后融合成一个完整的三维模型。
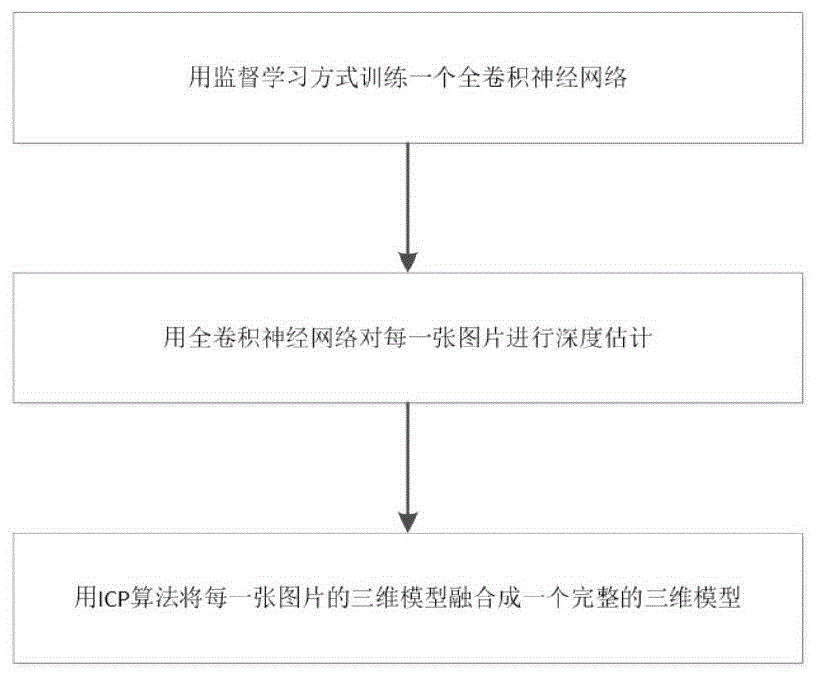
本发明提实现的过程包括以下步骤:
步骤1、利用监督学习的方式训练全卷积神经网络;
步骤2、用全卷积神经网络对每一张图片进行深度估计;
用单目相机拍摄一系列室外场景的连续的图片,然后将每一张图片作为输入,用前面已经训练好的全卷积神经网络对图片进行深度估计,得到其的三维点云模型;
步骤3、用icp算法将每一张图片的三维模型融合成一个完整的三维模型;
所述的步骤1具体实现如下:
1-1.准备大量训练图片用于训练网格参数;
每一组训练图片包括对某一角度的室外场景拍摄的一张普通的彩色图片、以及该彩色图片对应的深度图片和像素级的语义分割信息;通过synthia数据集中像素级的语义分割信息剔除冗余数据;
1-2.对图片数据进行数学建模;用
q=di(q)·k-1q公式1
假设三维空间中的一个平面的法向量为
假设彩色图片ii中有m个平面,则对彩色图片构建一个像素概率矩阵si;其中的si(q)是一个(m+1)维的向量,它的第j个元素记为
其中,
对于正则项
其中
将数据集中的语义信息分成两类:“保留”={建筑,马路,人行道,车道线}和“舍弃”={行人,汽车,天空,自行车};如果一个像素点属于“保留”类的话,则令z(q)=1;如果属于“舍弃”类的话,则令z(q)=0;于是将上面的正则项公式重写为:
全卷积神经网络分成两大部分:一个部分用来分割图片中的平面;另一部分则是用来生成图片的三维点云模型的;两个部分共享相同抽象的特征图。
步骤3所述的用icp算法将每一张图片的三维模型融合成一个完整的三维模型,具体实现如下:
3-1.求解出两个点云的重叠部分;
首先使用sift算法提取和匹配两张图片的特征点,得到匹配点集q和q′;对于这两个点集之间的变换,求得其单应矩阵h,即q′=h·q;
然后计算配准图的四个顶点坐标,接着进行图像配准,进而得到两张图片中重叠区域的像素集合,再通过语义信息仅保留其中归属于“保留”类别的像素,最终得到像素集合n′={1,…,n′};
对于两个已知的点云,其重叠区域可分别表示成:
p={p1,...,pn′}p′={p′1,...,p′n′}公式9
3-2.找到一个欧式变换的旋转矩阵r和平移矩阵t,将两个点云进行匹配,即:
应用icp算法求解出r和t,通过使误差平方和达到极小求得r和t,即
首先计算旋转矩阵r,两组点云的质心位置;
然后计算每组点云中点的去质心坐标qi和q′i:
qi=pi-p,q′i=p′i-p公式13
定义矩阵
w=u∑vt
则r为
r=uvt
然后计算平移矩阵t
t=p-rp′;
3-3.得到平移、旋转变换后,用如下公式将p′中的点云变换到p坐标系下:
从而实现两个点云的融合
本发明的特点及有益效果:
本发明实现了一种基于全卷积神经网络的单目相机室外三维重建方法,对三维重建有较大意义。本发明利用监督学习的方式训练全卷积神经网络,可直接对彩色图片进行深度估计得到其三维点云模型,再对所有的点云模型进行融合,完成对室外场景的三维重建。
与双目相机和深度相机相比,单目相机经过长期发展,技术相对成熟,成本较低,结构简单,对计算资源的要求不像双目相机所需的三角测距那样高,更容易商业化。例如,现在几乎人手一只的智能手机上都标配的摄像头就是单目相机,而且相机的成像效果不错,可以直接拿来使用。
此技术可以在普通pc机或工作站等硬件系统上实现。
附图说明
图1为本发明方法总体流程图。
图2为本发明所用到的全卷积神经网络的模型。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,一种基于全卷积神经网络的单目相机室外三维重建方法,包括以下步骤:
步骤1、利用监督学习的方式训练全卷积神经网络:
同其他的神经网络模型一样,首先需要准备大量的训练图片用于训练网格参数。每一组训练图片包括对某一角度的室外场景拍摄的一张普通的彩色图片、以及该彩色图片对应的深度图片和像素级的语义分割信息。由于数据集的人工收集与标记会花费大量的时间与精力,可以使用synthia数据集。虽然其中的数据全部来自于虚拟的城市,但电脑模拟出的效果与真实世界有一定的相似性。需要注意的是,这个数据集最初的目的是用于自动驾驶,其采集数据的方式是模拟一辆在真实交通状态下行驶的汽车,隔一定的时间从车上一固定位置与角度拍摄照片。所以数据集中会有很多组几乎相同的图片。可以通过车速来剔除冗余的数据,从而避免无谓的计算量。除此之外,还需要剔除图片中不需要的部分。图片中的行人、汽车等信息是不需要包括在重建好的三维模型中的,而道路、建筑表面等信息则必须保留。通过synthia数据集中像素级的语义分割信息可以完成这个步骤,具体过程将在下面的正则项中体现出来。
在介绍神经网络模型之前,需要对图片数据进行数学建模。用
q=di(q)·k-1q公式1
由于在三维重建的过程中几乎所有的数据都是关于平面信息的。假设三维空间中的一个平面的法向量为
假设彩色图片ii中有m个平面,则对彩色图片构建一个像素概率矩阵si。其中的si(q)是一个(m+1)维的向量,它的第j个元素记为
其中,
对于正则项
其中
本发明中使用的全卷积神经网络模型是从完全公开的tensorflow框架从头训练得到的,网络结构见图2。整个神经网络框架分成两大部分。一个部分用来分割图片中的平面,因为在整个三维重建的过程中,室外场景的平面占据了很大一部分的数据,所以要单独对其计算,以保证最后结果的准确性。其中除了预测层的激活函数用的是softmax函数,其他所有层的都是relu函数。另一部分则是用来生成图片的三维点云模型的。这个部分和前面那个部分共享相同抽象的特征图。其包含两个stride-2的卷积层(3*3*512),然后紧跟着一个输出m个平面参数的1*1*3m的卷积层,然后使用一个全局平均池化。除了最后一层什么激活函数都不用,其他用的都是relu函数。在最终的参数设计上,α=0.1,平面数量m=5。训练模型的时候,可以采用adam优化算法,β1=0.99,β2=0.9999,学习速率为0.0001,批尺寸为4。
步骤2、用全卷积神经网络对每一张图片进行深度估计。
用单目相机拍摄一系列室外场景的连续的图片,然后将每一张图片作为输入,用前面已经训练好的全卷积神经网络对其进行深度估计,得到其的三维点云模型。
步骤3、用icp算法将每一张图片的三维模型融合成一个完整的三维模型。
在得到每一张图片的三维点云模型后,就需要将其融合成一个点云模型。迭代最近点(iterativeclosestpoint,下简称icp)算法是一种点云匹配算法,用来解决3d-3d的位姿估计问题。取拍摄时间相临近的两张图片的点云,由于其拍摄时间相近,则其差异不大,它们的三维点云重叠部分很大,更适合用来匹配与融合。
但是在应用icp算法之前,需要求解出两个点云的重叠部分。由于点云模型是从彩色图片中估计得来,为了保证重叠像素集合计算的准确度,这里直接计算两张彩色图片的重叠区域。首先使用sift算法提取和匹配两张图片的特征点,得到匹配点集q和q′。对于这两个点集之间的变换,可以求得其单应矩阵h,即q′=h·q。然后计算配准图的四个顶点坐标,接着就可以进行图像配准,进而得到两张图片中重叠区域的像素集合,再通过语义信息仅保留其中归属于“保留”类别的像素,最终得到像素集合n′={1,…,n′}。
对于两个已知的点云,其中重叠区域可分别表示成:
p={p1,...,pn′}p′={p′1,...p′n′}
如果找到一个欧式变换的旋转矩阵r和平移矩阵t,则可以将两个点云匹配上,即:
应用icp算法可以求解出r和t,本发明使用的是线性代数的求解方式,目的就是通过使误差平方和达到极小求得r和t,即
首先计算旋转矩阵r,两组点云的质心位置,然后计算每组点云中点的去质心坐标qi和q′i:
qi=pi-p,q′i=p′i-p
定义矩阵
w=u∑vt
则r为
r=uvt
然后可与计算平移矩阵t
t=p-rp′
得到平移、旋转变换后,用如下公式将p′中的点云变换到p坐标系下:
这样就实现了两个点云的融合
- 还没有人留言评论。精彩留言会获得点赞!