基于图像识别物体的方法、智能设备及应用与流程
本发明涉及图像识别技术领域,具体涉及基于图像识别物体的方法、智能设备及应用。
背景技术:
传统烤箱无法分辨烘烤食物的种类、数量与重量,所以无法主动的控制食材的加热温度、时间等加热过程,需要用户手动设置。又由于食材的多样性使得用户很难精确的控制加热过程,导致烘烤失败。已有的解决方案是通过添加摄像头,使用计算机视觉方法识别食物的种类;然后添加重量传感器获取食物的重量。此方案的成本较高,且重量传感器的校准较为复杂。
技术实现要素:
本申请提供一种基于图像识别物体的方法、智能设备及应用,可以实现无需重量传感器也能识别物体重量的目的,以解决利用重量传感器成本较高、校准复杂的问题。
根据第一方面,一种实施例中,提供一种基于图像识别物体的方法,所述识别方法应用在对智能设备腔体内的物体进行识别,所述智能设备腔体内安装有图像采集装置,所述图像采集装置用于采集所述智能设备腔体中待识别物体的图像,所述识别方法包括步骤:
获取所述图像采集装置采集智能设备腔体内待识别物体的图像;
将所述图像输入至深度卷积神经网络模型,利用所述深度卷积神经网络模型对所述图像进行识别获得待识别物体的种类、重量、数量和/或位置。
一种实施例中,还包括采集训练数据集,利用采集的训练数据集对所述深度卷积神经网络模型进行训练的步骤,其中,采集训练数据集包括步骤:
创建模拟腔体,所述模拟腔体的大小、形状与智能设备腔体的大小形状相同;
在所述模拟腔体内安装图像采集装置,所述模拟腔体内的图像采集装置的参数与所述智能设备腔体内的图像采集装置的参数相同,及所述模拟腔体内的图像采集装置的安装位置与所述智能设备腔体内的图像采集装置的安装位置、角度相同;
利用所述模拟腔体内的图像采集装置对模拟腔体内的物体进行图像采集;
对采集的图像进行特征值标定,标定的特征值作为训练数据,所述标定的特征值为物体种类、物体重量、物体数量和/或位置。
一种实施例中,所述深度卷积神经网络模型为mobilenetv2网络结构,所述标定的特征值为物体种类、物体重量和数量,所述mobilenetv2网络结构的损失函数为:loss(cls)+αloss(wt)+βloss(num),其中,loss(cls)为物体类别的损失函数,α和β为平衡参数,loss(wt)为物体重量的损失函数,loss(num)为物体数量的损失函数。
一种实施例中,所述深度卷积神经网络模型为ssd网络结构,所述标定的特征值为物体种类、物体重量和物体在模拟腔体内的位置,所述ssd网络结构的损失函数为:loss(cls)+αloss(loc)+βloss(wt),其中,α和β为平衡参数,loss(cls)为物体类别的损失函数,loss(loc)为物体位置的损失函数,loss(wt)为物体重量的损失函数。
一种实施例中,所述深度卷积神经网络模型为ssd网络结构,所述标定的特征值为物体种类和物体外接矩形框,所述ssd网络结构识别待识别物体重量的步骤为:
计算图像坐标到智能设备腔体内用于承载物体的承载体坐标的映射关系表;
将承载体划分成m*n的网格;
统计不同物体覆盖网格面积、网格形状与物体重量的关系,并绘制重量关系表;
依据映射关系表,将物体的外接矩形框映射到承载体坐标;
根据物体的种类、映射后的物体坐标和重量关系表,得到物体的重量。
一种实施例中,所述深度卷积神经网络模型为multi-viewcnn网络结构,所述标定的特征值为物体种类、物体重量和数量,所述multi-viewcnn网络结构的损失函数为:loss(cls)+αloss(wt)+βloss(num),其中,loss(cls)为物体类别的损失函数,loss(wt)为物体重量的损失函数,loss(num)为物体数量的损失函数,α和β为平衡参数。
根据第二方面,一种实施例中,提供一种基于图像识别物体的智能设备,包括图像采集装置和识别装置;
所述图像采集装置安装于智能设备的腔体内,用于采集腔体中待识别物体的图像,并将采集的图像输入至所述识别装置;
所述识别装置被配置有深度卷积神经网络模型,所述深度卷积神经网络模型采用上述的方法对所述图像进行识别获得待识别物体的种类、重量、数量或/和位置。
根据第三方面,一种实施例中,提供一种上述的方法在烤箱中的应用,烤箱的炉腔内安装有图像采集装置,所述图像采集装置用于采集烤箱中待识别物体的图像,包括步骤:
获取所述图像采集装置采集烤箱炉腔内待识别食物的图像;
将所述图像输入至深度卷积神经网络模型,利用所述深度卷积神经网络模型对所述图像进行识别获得待识别食物的种类、重量、数量和/或位置;
根据获取的食物种类、重量、数量和或/位置信息自动控制烤箱对食物的加热温度、加热时长,以实现自动化控制烤箱对食物的加热过程。
依据上述实施例的基于图像识别物体的方法,由于通过图像采集装置和深度卷积神经网络模型相结合识别出物体的种类、重量、数量和/或位置,因此,避免了使用重量传感器,降低了成本。
附图说明
图1为识别物体流程图;
图2为multi-viewcnn模型的原理图;
图3为控制烤箱智能加热流程图。
具体实施方式
下面通过具体实施方式结合附图对本发明作进一步详细说明。
一些智能设备,如微波炉、蒸箱等类似设备,一般需要通过识别食物的种类、重量等参数实现智能加热,其中,识别食物的种类是通过图像识别,识别食物的重量是通过重量传感器识别;但是增加重量传感器会导到微波炉等类似设备的成本增加,且重量传感器的精度较难校准。
目前,也有通过目标食物图像计算目标食物面积,然后通过得到的面积数据和获取到的目标食物密度计算出目标食物的重量,但是这种是通过一定的运算计算得到的目标食物面积,运算过程需要消耗时间,而微波炉等需要及时对食物加热,因此,通过一定时间计算得到食物重量的方法在微波炉、烤箱、微蒸烤一体机等类似设备中并不是一个好方法。
因在微波炉、微蒸烤一体机等类似设备中已安装有摄像头,基于此,本申请提出摄像头与深度卷积神经网络模型相结合直接识别食物的种类、重量、数量和/或位置,识别速度快,且精确度高。
实施例一:
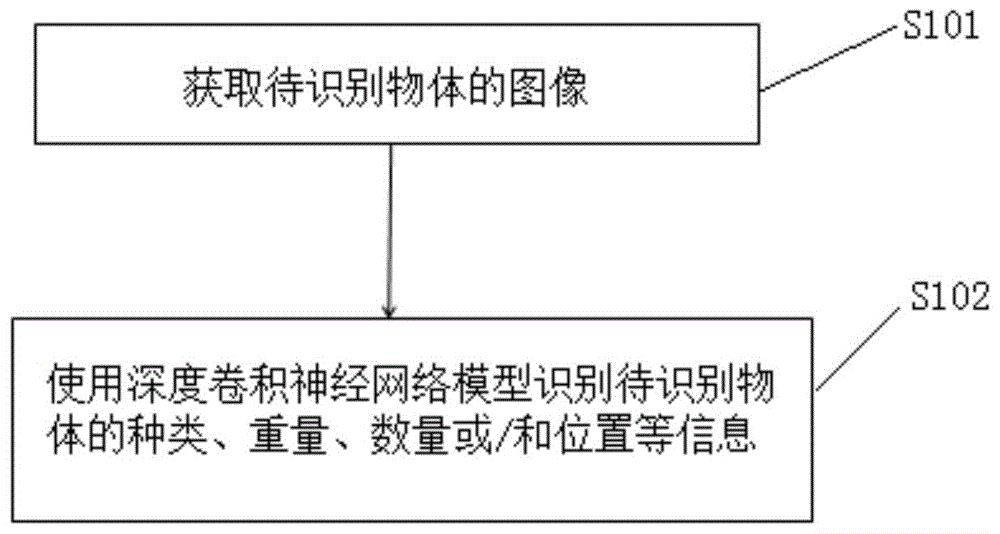
为不失一般性,基于上述构思,本例提供一种基于图像识别物体的方法,该方法应用在对智能设备腔体内的物体进行识别,智能设备腔体内安装有图像采集装置,图像采集装置具体为摄像头,用于采集智能设备腔体中待识别物体的图像,本例的方法流程图如图1所示,具体包括以下步骤。
s101:获取图像采集装置采集智能设备腔体内待识别物体的图像;
s102:将图像输入至深度卷积神经网络模型,利用深度卷积神经网络模型对图像进行识别获得待识别物体的种类、重量、数量和/或位置。
因本例是采集摄像头结合深度卷积神经网络模型识别物体的种类、重量、数量和/或位置,在利用深度卷积神经网络模型进行识别之前需要先对深度卷积神经网络模型进行训练,因此,需要采集对深度卷积神经网络模型进行训练的训练数据。
以物体为食物为例,有多种类型的食物,且摄像头在拍摄食物图像时,摄像头距离食物的远近不同所拍摄的图像中食物的大小也不同,及不同类型设备或不同系列设备其内部空间设备也不同,摄像头安装在设备中的位置也不同,为了解决这些不同,及采集到精确的训练数据,本例采集训练数据集时采用的基本方案是:
创建与实际产品设备镜像的模拟腔体,也即是,模拟腔体的大小、形状与实际生产的智能设备腔体的大小、形状相同;
将摄像头安装在模拟腔体内,同样的,模拟腔体内安装的摄像头的安装位置与实际智能设备腔体内安装的摄像头的安装位置、角度相同,模拟腔体内安装的摄像头的参数与实际智能设备腔体内的摄像头的参数相同,如,分辨率、fov(视场角)等参数相同;
利用模拟腔体内的图像采集装置对模拟腔体内的物体进行图像采集;
对采集的图像进行特征值标定,标定的特征值作为训练数据,标定的特征值为物体种类、物体重量、物体数量和/或位置。
通过上述设计,使模拟腔体内实际智能设备腔体镜像,这样利用模拟腔体得到的训练数据去训练相对应的实际智能设备中的深度卷积神经网络模型才具有意义;也即是,每一类型的智能设备配套有相对应的深度卷积神经网络模型,及相对应的训练数据集,使得,智能设备实际应用中,通过训练好的深度卷积神经网络模型能快速识别出摄像头采集的食物图像的食物种类、食物重量、食物数量和/或位置;从而实现不需要重量传感器,通过摄像头结合深度卷积神经网络模型识别食物重量的目的。
需要说明的是,为了使采集的训练数据集精准,本例在具体采集训练数据集时,还在模拟腔体内安装多个辅助摄像头,该多个辅助摄像头的安装位置与该模拟腔体内原有的摄像头的安装位置不同,采用多个摄像头进行图像采集,其中,辅助摄像头安装位置应该以能够观测到待识别物体的全部为准,通过多个辅助摄像头能采集到物体可能随机放置的位置、数量和不同形状,因此,通过辅助摄像头和模拟腔体内原有摄像头共同采集的数据能表征出待识别物体的不同特征,以提供训练数据的完整性。
另外,为了提高训练数据的采集效率及扩展物体的各个采集视角,还可以采用特定的旋转装置,使待识别物体随机旋转,以此提高采集效率及扩展采集视角。
下面本例提供几种深度卷积神经网络模型,但并不限于下述几种类型。
第一种类型:深度卷积神经网络模型为mobilenetv2网络结构。
针对mobilenetv2网络结构,标定的特征值为物体种类、物体重量和数量,也即是,mobilenetv2网络结构通过摄像头采集的图像能识别出物体种类、物体重量和数量。
本例中,mobilenetv2网络结构的损失函数为:loss(cls)+αloss(wt)+βloss(num),其中,loss(cls)为物体类别的损失函数,优选的,loss(cls)使用交叉熵损失函数或二元交叉熵损失函数;α和β为平衡参数,当α或β为0时表示不考虑重量或数量因素;loss(wt)为物体重量的损失函数,loss(num)为物体数量的损失函数,优选的,本例使用smoothl1loss。
通过计算loss反传梯度对模型参数进行更新,不同的loss可以使模型更加侧重于学习到数据某一方面的特性,因此loss对于网络优化有导向性的作用。通过联合物体种类、重量和数量的loss可以使模型更好的学习三者之间的联系,平衡三者之间的关系。
优选的,当物体为食物时,由于食物重量的相对误差对烤箱的加热时间影响更大,本例loss(wt)使用的smoothl1loss使用的是预测值与真实值间的差与真实值的比值loss=wtpred-wttarg/wttarg,而不是直接使用预测值与真实值之间的差值loss=wtpred-wttarg。
该方式适用于标注了食材种类、数量和重量的数据集,通过深度卷积神经网络可以直接得到食材的种类、数量和重量。
第二种类型:ssd网络结构。
针对ssd网络结构,标定的特征值为物体种类、物体重量和物体在模拟腔体内的位置。
这种ssd网络结构的损失函数为:loss(cls)+αloss(loc)+βloss(wt),其中,α和β为平衡参数,loss(cls)为物体类别的损失函数,优选的,本例使用交叉熵损失函数或二元交叉熵损失函数;loss(loc)为物体位置的损失函数,优选的本例使用smoothl1损失函数;loss(wt)为物体重量的损失函数,优选的本例使用优化后的smoothl1损失函数。
通过加入loss(cls)可以使模型更多的注意到图像中的食材,进而提高食材类别和重量的精度,但该方法的标注成本大于第一种类型。该方式适用于标注了食材种类、重量和外接矩形框的数据集,通过深度卷积神经网络可以直接得到食材的种类、重量和大小、位置。
第三种类型,ssd网络结构。
针对这种ssd网络结构,标定的特征值为物体种类和物体外接矩形框,这种类型的ssd网络结构以适应没有直接标注重量但标注了种类和外接矩形框的数据。
通过深度卷积神经网络可以直接得到物体的种类和外接矩形框,然后利用物体的密度,估计物体的重量。具体步骤如下:
计算图像坐标到智能设备腔体内用于承载物体的承载体坐标的映射关系表;
将承载体划分成m*n的网格;
统计不同物体覆盖网格面积、网格形状与物体重量的关系,并绘制重量关系表;
依据映射关系表,将物体的外接矩形框映射到承载体坐标;
根据物体的种类、映射后的物体坐标和重量关系表,得到物体的重量。
以物体为食物,智能设备为烤箱为例,估计食物重量方法如下:
1,计算烤箱图像坐标到烤箱烤盘坐标的映射关系表;
2,将烤箱的烤盘划分成mxn的网格;
3,统计不同食材覆盖网格面积、网格形状与食材重量的关系,并绘制重量关系表;
4,依据映射关系表,将食材的外接矩形框映射到烤盘坐标;
5,根据食材的种类、映射后的食材坐标和重量关系表,估计得到食材的重量。
第四种类型:multi-viewcnn网络结构。
针对multi-viewcnn网络结构,标定的特征值为物体种类、物体重量和数量。
multi-viewcnn网络结构的损失函数为:loss(cls)+αloss(wt)+βloss(num),其中,loss(cls)为物体类别的损失函数,优选的,本例使用交叉熵损失函数或二元交叉熵损失函数;loss(wt)为物体重量的损失函数,loss(num)为物体数量的损失函数,优选的本例使用smoothl1loss;α和β为平衡参数,当α或β为0时表示不考虑重量或数量因素。
优选的,本例使用multi-viewcnn模型的训练步骤如下,其原理图如图2所示:
1.对每个视图训练一个独立的cnn模型(cnn1-cnnn),每个模型都可以相互独立的识别食材种类、数量和重量。n为cnn模型的个数,也是多视图的个数、摄像头的个数。
例如,有两个摄像头,则需要训练两个单独的cnn模型;
2.固定cnn1-cnnn模型不变,将训练好的多个模型的某层特征图融合成一个新的特征图,并将其作为cnnn+1的输入,然后训练cnnn+1,最终获得训练好的multi-viewcnn模型;当将新采集的物体图像输入到multi-viewcnn模型中即可得到物体的种类、重量以及位置等信息。
通过上述方法,利用深度卷积神经网络模型识别图像获得待识别物体的种类、重量、数量和/或位置,不需要使用重量传感器,降低了成本。
下面本例基于上述方法还提供一种基于图像识别物体的智能设备,该智能设备可以是微波炉、烤箱、微蒸烤箱、蒸烤箱、微蒸烤一体机等,该智能设备包括图像采集装置和识别装置;
图像采集装置和识别装置可以无线通讯连接,也可以有线连接,其中,图像采集装置安装于智能设备的腔体内,用于采集腔体中待识别物体的图像,并将采集的图像输入至识别装置;
识别装置被配置有深度卷积神经网络模型,深度卷积神经网络模型采用上述的方法对图像进行识别获得待识别物体的种类、重量、数量或/和位置。
实施例二:
基于实施例一,本例提供一种实施例一中的识别方法在烤箱中的应用,烤箱的炉腔内安装有图像采集装置,图像采集装置用于采集烤箱中待识别食物的图像,其流程图如图3所示,包括步骤:
获取图像采集装置采集烤箱炉腔内待识别食物的图像;
将图像输入至深度卷积神经网络模型,利用深度卷积神经网络模型对图像进行识别获得待识别食物的种类、重量、数量和/或位置;
根据获取的食物种类、重量、数量和或/位置信息自动控制烤箱对食物的加热温度、加热时长,以实现自动化控制烤箱对食物的加热过程。
本例通过在烤箱中添加摄像头的方法,获取烤箱内食物图像;然后使用深度卷积神经网络模型识别待加热或正在加热的食物的种类、重量、数量与位置;然后根据识别的结果智能控制加热过程。该发明简化了用户的操作,且提高了烘烤的成功率,提高了用户体验。相比于已有的解决方案,本发明降低了成本,且可以长时间使用并无需校准。
基于上述的应用,本例还提供一种智能烤箱,该智能烤箱包括图像采集装置、识别装置和控制装置;
图像采集装置安装于智能设备的腔体内,用于采集腔体中待识别物体的图像,并将采集的图像输入至所述识别装置;
识别装置被配置有深度卷积神经网络模型,深度卷积神经网络模型采用实施例一的方法对图像进行识别获得待识别食物的种类、重量、数量或/和位置;
控制装置根据获取的食物种类、重量、数量和或/位置信息自动控制烤箱的加热部对食物的加热温度、加热时长,以实现自动化控制烤箱对食物的加热过程。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属技术领域的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。
- 还没有人留言评论。精彩留言会获得点赞!