本发明涉及神经计算、模式识别、计算机视觉领域,特别涉及神经网络进行权值修剪以增强其泛化能力、降低存储量、加快运行速度的方法。
背景技术:
近年来,卷积神经网络(convolutionalneuralnetwork,cnn)在分类、检测和分割任务方面的性能越来越优于传统的计算机视觉方法。然而,cnn也带来了大量的计算和存储消耗,从而阻碍了它在移动和嵌入式设备上的部署。神经网络参数稀疏通过剔除对输出结果贡献不大的冗余参数,在cnn加速方面表现出了较好的性能。但由于非结构化的修剪会导致不规则稀疏,使得在一般的硬件平台上难以实现加速。即使使用稀疏矩阵核,加速效果也非常有限。为了解决这一问题,结构化稀疏获得了越来越多的关注,它可以将网络压缩成更细的网络,从而使修剪后的网络更加高效。
目前,结构化稀疏主要分为结构化行稀疏和结构化列稀疏两种方式,针对张量展开得到的二维权值矩阵,现有的结构化稀疏策略主要是根据一些重要性准则对行(卷积核级别)进结构化行修剪,而在大多数情况下,矩阵的行要远小于矩阵的列。因此,在同样的稀疏度和结构化稀疏的需求下,在列维度下选取需要稀疏的权值,比起在行维度下选取需要稀疏的权值,会有更大的选择空间。另外,对行的修剪即是对卷积核进行修剪,由于卷积核是粒度较大的单位,因此该修剪方法可能会导致模型精度的明显下降。
技术实现要素:
为了克服上述神经网络结构化行稀疏方法中对卷积核修剪的局限性,以及获得更好的模型性能,本发明提供了一种基于权重显著性的神经网络列稀疏方法。该方法在稀疏过程中,基于用户指定的压缩加速比例,设定权值重要性标准和压缩率,对张量展开后的二维权值矩阵的列进行稀疏。如图3(a)与图3(b)中行、列稀疏化的对比,相对于行的稀疏,列的稀疏有更大的修剪空间,解决了结构化行稀疏策略中修剪空间较小的局限性问题。同时,结构化列稀疏可以达到与结构化行稀疏同样的加速比例,而对列的稀疏进一步优化了传统结构化行稀疏算法中直接修剪卷积核所带来的精度下降较为明显的问题。本发明方法解决了以卷积神经网络为代表的深度学习模型存储量大、计算量大的问题,而且在其他结构化行稀疏工作中存在的由于选择空间较小而导致精度下降较多的问题上进行改进,提出了结构化列稀疏的加速压缩方法。该发明使得深度学习模型可以在移动和嵌入式设备上的部署,并获得一定的实际加速效果,推广智能算法在移动端的应用。
本发明的目的可以通过以下的技术方法实现:一种基于权重显著性的神经网络列稀疏方法,具体包括以下步骤:
(1)对于待稀疏的神经网络模型,准备训练的数据集、网络结构配置文件、训练过程配置文件,所使用的数据集、网络结构配置、训练过程配置均与原训练方法保持一致;
(2)结构化列稀疏:
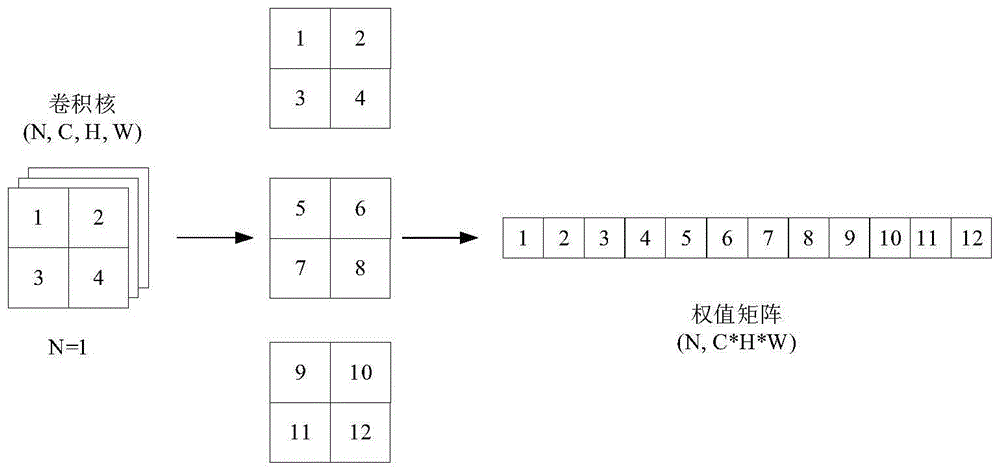
(2.1)对于模型的各个卷积层,使用张量展开方式,将该层中的四维权值张量wn*c*h*w展开为二维的w′n*(c*h*w)形式,其中n表示卷积核的个数,c表示卷积核的通道数,h、w分别表示卷积核的高和宽,并将w′每一列参数组合成一个独立的列参数组;
(2.2)对网络权值矩阵w′中的每个参数组设定稀疏的重要性标准,得到一个用于表征参数组重要性的向量w′_ln;
(2.3)根据用户指定的对模型的压缩加速比例,利用模拟删除网络参数的方法,确定网络模型各层所需设定的稀疏率;
(2.4)根据各层的稀疏率和每个列参数组的重要性顺序,将重要性较低的参数组进行删除操作,当模型各层均完成删除操作后,将权值矩阵还原成四维的张量形式,获得稀疏模型;所述重要性较低的条件,由以下规则确定:对向量w′_ln中的元素进行从小到大排序,根据稀疏率,选取相应比例的数值较低的元素,标记为重要性低,作为后续优先删除的对象。
(3)对稀疏后的模型进行重训练,固定已经删除的权值不进行更新,而其他参数进行网络的迭代训练,并对模型的准确率进行监测,当再训练的模型准确率不再上升时,得到稀疏后的神经网络模型。
进一步的,所述步骤(2.1)中具体流程为,对四维的权值张量进行二维展开操作得到权值矩阵w′,权值矩阵的行维度为卷积核的个数n,列维度为卷积核的通道数c、卷积核的高h、卷积核的宽w的乘积,再令矩阵的每一列参数组合成为一个独立的列参数组,因此共有c*h*w个参数组。
进一步的,所述步骤(2.2)具体为,对网络权值矩阵w′各列参数划分成的独立参数组,为评价其重要性顺序而设定标准,此时使用ln范数(n∈(0,∞))作为标准,每层得到一个c*h*w维度的向量w′_ln,向量中各元素的数值用于表征各个参数组的重要性情况。
进一步的,所述步骤(2.3)中模拟删除网络参数的具体方法是,在接收到用户指定的压缩加速比例后,先计算模型中各个参数层的每秒浮点操作次数(gflops),并设定一个初始的压缩率α;然后对网络中各层的参数进行压缩率为α的模拟稀疏,得出在α压缩率下gflops的减少量,并判断当前总体稀疏率是否符合用户指定的压缩加速比例,若未达到则以β为步长增大压缩率α,重复进行模拟稀疏、统计总体稀疏率的操作;
当稀疏率接近指定压缩加速比例时,将压缩率的增量步长减少至γ,进一步可以考虑前n个具有较大gflops值的层,将其压缩率增量步长减少至0,以确保最后实现的稀疏率能准确达到用户指定的数值。
进一步的,所述步骤(2.4)具体如下:
a、获得当前层的权值矩阵w′、参数组重要性表征向量w′_ln、当前层的稀疏率δ;
b、根据稀疏率δ,对向量w′_ln中重要性较低的参数组标记为需要被稀疏的对象;
c、将向量w′_ln中被标记的对象反向映射到权值矩阵中对应的列,再对这些列进行删除;
d、将权值矩阵w′还原成当前层所需的四维张量形式,并覆盖本层原本的四维张量数值;
e、当网络中存在未稀疏化处理的层时,对各个未稀疏化的层重复a-d的操作,直至完成所有参数层的稀疏,获得稀疏模型。
与现有技术相比,本发明具有如下优点:
(1)本发明使用步进式模拟删除参数的方式来获得模型各层的稀疏率,即通过设定基础压缩率和压缩率增量,不断模拟计算稀疏度和调整模型的各层的压缩率,相比于人为直接设置为某值的确定压缩率的方法,能综合考虑到模型不同层的冗余度信息,有效计算模型各层所需的稀疏度,准确达到用户指定的压缩加速率。
(2)本发明在张量展开的矩阵运算方式下,基于给定的稀疏率,根据权值重要性准则对权值矩阵的列(即同一层中不同卷积核中相同位置)进行结构化稀疏,相对于结构化行稀疏直接修剪卷积核的操作,结构化单元更小,因此有更大的修剪空间,修剪后所带来的精度下降更少,见图3(a)与图3(b)中行、列稀疏化的对比。
(3)本发明在同样的稀疏度和结构化稀疏需求下,结构化列稀疏修剪删除的列数会明显多于结构化行稀疏修剪删除的行数。因此,在使用结构化列稀疏模型进行实际运算时,时间上的加速效果要优于结构化行稀疏模型。
附图说明
图1为本发明实施例中张量展开方式图;
图2为本发明实施例中模型稀疏化流程图;
图3(a)为本发明实施例中行/滤波稀疏图;
图3(b)为本发明实施例中列/形状稀疏图。
具体实施方式
结合下面的实施例子,对本发明进行进一步的详细说明。但是本发明提出的神经网络结构化列稀疏算法并不限于这一种实施方法。
(1)准备工作
对于待稀疏的神经网络模型,准备训练的数据集、网络结构配置文件、训练过程配置文件,所使用的数据集、网络结构配置、训练过程配置均与原训练方法保持一致;在resnet-50的神经网络结构化列稀疏实验中,所使用的数据集为imagenet-2012,所使用的网络结构配置等文件均为resnet-50原模型所使用的文件(下载链接:https://cloud6.pkuml.org/f/06997cf3f3fc48018d61/)。
(2)结构化列稀疏
整体网络模型稀疏化流程如图2所示。
(2.1)对于模型的各个卷积层,使用图1的张量展开方式,将该层中的四维权值张量wn*c*h*w展开为二维的w′n*(c*h*w)形式,其中n表示卷积核的个数,c表示卷积核的通道数,h、w分别表示卷积核的高和宽;再令权值矩阵中每一列参数组合成为一个独立参数组,因此对于每一层有c*h*w个参数组。如图3(b)所示,在二维的权值矩阵中,颜色加深的一列为某个参数组的示例,该参数组包含4个权值参数。
(2.2)对网络权值矩阵w′的每个参数组设定稀疏的重要性标准,即删除的先后顺序。在resnet-50的实验中,以ln范数中的l1范数为例作为衡量权值矩阵各个参数组重要性的标准,分别对各个参数组进行求l1范数的操作,每层得到一个c*h*w维向量w′_l1。然后将向量w′_l1按照从小到大的顺序进行排序,得到权值矩阵中各个参数组重要性/稀疏顺序。
(2.3)根据用户指定的对模型的压缩加速比例,利用模拟删除网络参数的方法,确定网络模型各层所需设定的稀疏率;在resnet-50的实验中,指定2倍的压缩加速指标,设定基础稀疏率α为0.2,增量步长β为0.03,重复对网络各层的权值进行模拟稀疏,并统计总体稀疏率的操作。当稀疏率接近2倍时,将增量步长下调到γ值0.01,最后得到在2倍压缩加速比例下,待稀疏的网络模型各层的稀疏率设置为0.3;
(2.4)按照各层设定的稀疏率,对各层各自的向量w′_l1中符合要求的参数组标记为需要被稀疏的对象。接着将向量w′_l1中被标记的对象反向映射到权值矩阵中对应的列,再对此些列参数进行删除。最后将权值矩阵还原为四维的张量形式并替换原本层数值,获得稀疏模型;(3)对稀疏完成的模型进行再训练,其中已删除的参数不进行更新,并用测试集(如果没有测试集,则使用验证集)对模型的准确率进行监测。当再训练的模型准确率不再上升时,算法终止,得到稀疏后的神经网络模型。在模型为resnet-50的结构化稀疏实验中,原始的resnet-50模型在imagenet验证集的top-5准确率为91.2%,使用图3(a)形式的行稀疏剪枝算法,设定2倍的加速比例并完成压缩与再训练后,在imagenet验证集上面的准确率为89.5%,而使用本文所述图3(b)形式的列稀疏算法剪枝,设定2倍加速比例并完成压缩与再训练后,在imagenet验证集上面的准确率为90.7%,可以看到结构化列稀疏的性能优于结构化行稀疏。