一种基于深度学习的便利店销量预测方法与流程
本发明属于计算机科学计算领域,主要为深度学习回归预测算法的改进。
背景技术:
在大数据时代,预测分析技术已经逐渐在商业社会中得到广泛应用。在新零售的热潮下,便利店行业以时间上、空间上和商品上便民特点,加之政策的支持和投资的推动,成为了新的风口。便利店企业在激烈的市场竞争中,要做到合理配置商品库存,利用大数据分析技术对销售量的预测是重要的一个环节。
连锁便利店地点复杂、需求多样、季节影响等因素增加了其销量预测的困难。以前,预测只是人为的凭着经验做预测,没有对此多做研究。现在,虽然有许多采用传统的回归预测算法进行销量预测的研究与应用,但存在诸多缺点,如线性回归算法对于非线性数据难以建模,难以表达高度复杂的数据;bp神经网络的模型过于复杂,难以解释,训练过程耗时,对数据量依赖大,易陷于局部最优;决策树有过拟合的倾向等等;而且它们在精度方面都有所欠缺。所以,研究一种精确且可靠的销量预测算法来提高品牌的竞争力是很有意义的。
技术实现要素:
本发明要解决的技术问题是,提出一种基于深度学习的销量预测方法。该方法主要采用了深度信念网络dbn模型。dbn网络本质上是由多个限制玻尔兹曼机rbm堆叠而成的结构,这里将dbn网络顶层输出与svr回归机进行连接,建立了新的回归模型,引入了对于易腐败变质商品的评价指标,目的是为了提高连锁便利店容易变质商品的销量预测精度。
为实现上述目的,本发明所述预测方法包括以下步骤。
步骤1.预处理。对便利店的历史销量数据进行清洗、插值、集成操作。
步骤2.构建dbn和svr组合模型。自底向上设置每一层rbm模型可视层和隐藏层神经元节点个数,将顶层rbm隐藏层作为输出层与svr模型输入层连接。
步骤3.训练组合模型。组合模型训练包括两步:
s1.预训练,用训练集数据对每层rbm逐层进行预训练,使得每层rbm参数达到局部最优。
s2.有监督微调,将dbn和svr组合模型使用bp反向传播算法,使用训练集数据对其进行有监督训练,微调各层参数,直到收敛。
步骤4.评估模型。使用模型评价指标评估模型性能。
附图说明:
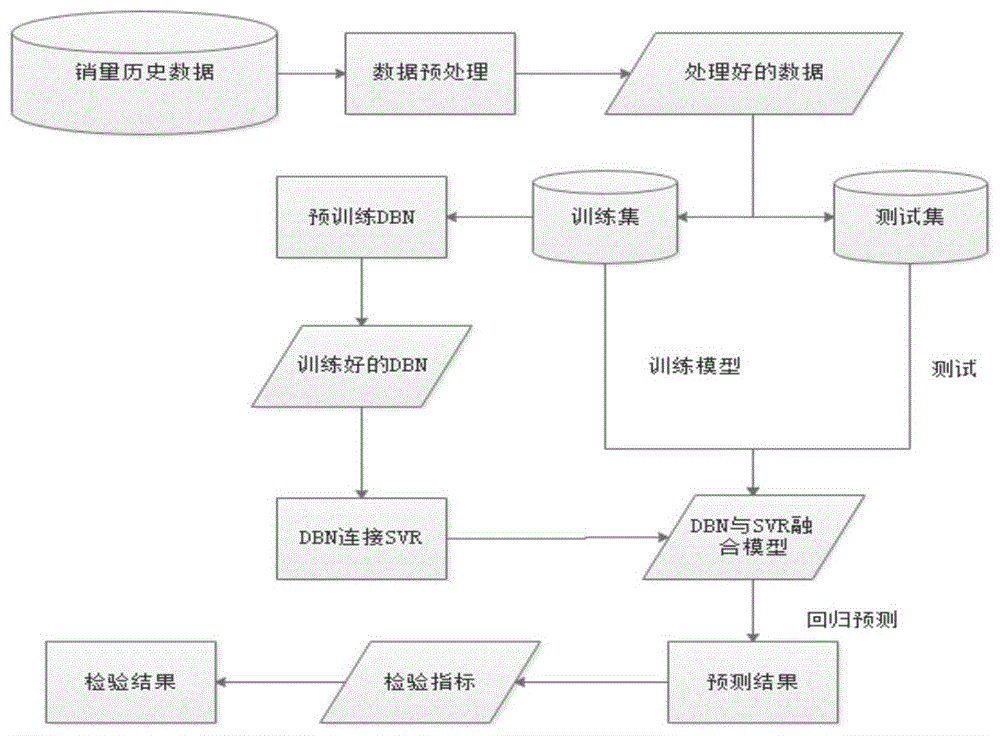
图1为本发明所涉及方法的流程图;
图2为本发明所涉及的数据集表结构图;
图3为本发明所涉及的深度信念网络dbn模型结构图。
图4为本发明设计的dbn与svr融合模型的结构图;
图5为本发明所涉及的dbn与svr融合模型的训练流程图;
图6为本发明所涉及的支持向量回归最优分类线图;
具体实施方式
下面结合附图对本发明方法做进一步说明:
如图1所示,本发明所述预测方法包括以下步骤:
步骤1.数据预处理。
s1.数据清洗。去除kaggle数据集中与目标没有关联的噪声数据表(石油价格表、假期表、商店总交易量表)。
s2.缺失值填充。时间序列数据少数销量数据为空,数据量比较大,采用线性内插法填充缺失值。
s3数据集成。数据地区信息按多级(如图2所示)给出,将列state和列city合并成一列,并用唯一标识area_id编码。
步骤2.构建dbn和svr组合模型。深度信念网络dbn由多层限制玻尔兹曼机rbm组成,如图3所示的dbn网络是由3个rbm模型堆叠而成,每个rbm由两层网络组成,即可视层(v)和隐藏层(h),层与层之间通过权值(w)连接。自底向上,第一层可视层(v1)为输入的初始数据,和第一个隐藏层(h1)组成第一个rbm(rbm1);第一个隐藏层(h1)作为第二可视层(v2),并和第二隐藏层(h2)组成第二个rbm(rbm2);第二隐藏层作为第三个可视层(v3),并和第三隐藏层(h3)组成第三个rbm(rbm3)。
本实施例中dbn和svr融合模型结构如图4所示,3层rbm组成dbn网络,dbn网络顶层输出与svr模型相连。底层rbm1可视层有7个神经元节点对应输入数据7种属性:时间、地区、商品id、商品类别id、商店id、是否容易变质、保质期。样本数据在经过每一层rbm都会进行特征提取并降低维度。rbm3输出层输出数据作为支持向量回归机svr的输入,经过svr回归模型运算后得出预测结果。
步骤3.dbn和svr组合模型的训练流程如图5所示。首先用训练集数据对每层rbm逐层进行预训练。rbm是无监督学习模型,无监督学习是指根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题。rbm模型是通过重构之后得到的对样本的估计与样本的真实值之间的误差进行学习的。rbm学习过程如下:
s1.样本x通过输入层输入,经过前向运算得到激活值y=f(wx+b),w为权值b为偏置值,f(x)是激活函数,这里采用sigmoid激活函数。
s2.将得到激活值y从隐藏层向输入层反向运算,使用相同的连接权值w和可视层偏置a用公式x′=f(wx+a)反向运算得到重构值x'。rbm的隐藏层的神经元个数比可见层的神经元个数少,在反向运算中,较少神经元的隐藏层又能够近似复现原始可见层的输入,因此,可以认为前向运算是对输入信号的编码,特征提取的过程,而反向运算是解码的过程。
s3.重构值x'代入公式y'=f(wx'+b)正向运算得到重构值y',然后z=x*y,z'=x'*y',可更新连接权值w=w+α*(z-z'),更新隐含层偏置b'=b+α*(y-y'),更新可视层偏置a'=a+α*(x-x'),α为学习率,这里设置为1.0。
s4.更新权值和偏置后,重复s1、s2、s3计算直到样本重构值与样本值均方误差mse<0.1或者迭代次数达到10次作为终止条件。
rbm1预训练完成后,训练样本通过输入rbm1得到输出作为rbm2输入层的输入数据进行rbm2的预训练。rbm全部完成预训练后,顶层svr回归模型将接收顶层rbm的输出特征向量作为它的输入特征向量,训练svr回归模型。
svr回归模型:
给定一个训练样本d={(x1,y1),(x2,y2)……(xn,yn)},yi∈r,r是实数集,n是样本总量,i为样本索引,希望学得一个f(x)使得其与y尽可能的接近,w、b是待确定的参数。在这个模型中,只有当f(x)与y完全相同时,损失才为零,而支持向量回归假设我们能容忍的f(x)与y之间最多有ε的偏差,当且仅当f(x)与y的差别绝对值大于ε时,才计算损失,此时相当于以f(x)为中心,构建一个宽度为2ε的间隔带,若训练样本落入此间隔带,则认为是被预测正确的,如图6所示,svr回归问题可以转化为求解下列约束规划问题:
上式中c为正则化常数,是人为设置的经验参数,这里设置为c=1。间隔ε设置为1,m为样本总量,i为样本索引,f(xi)是样本xi的预测值,yi是真实值,εi是样本xi的超平面上间隔松弛变量,
svr模型训练完成后,每一层rbm网络只能确保自身层内的权值对该层特征向量映射达到最优,并不是对整个dbn和svr融合模型的特征向量映射达到最优,所以预训练样本的标签信息通过顶层svr模型自顶向下传播至每一层rbm,迭代更新微调整个dbn网络的权值和偏置,直至收敛,模型的训练完成。
rbm网络训练模型的过程可以看作对一个深层bp网络权值参数的初始化,使dbn克服了bp网络因随机初始化权值参数而容易陷入局部最优和训练时间长的缺点。这可以很直观的解释,基于dbn网络结构的bp算法只需要对权值参数空间进行一个局部的搜索,相比前向神经网络来说,训练速度快,收敛时间短。
步骤4.在大量训练集采用步骤3中方法训练好模型dbn_svr后,用测试集检验预测模型对连锁便利店销量的预测能力以及模型的泛化能力,使用评价指标为加权均方根对数误差nwrmsle。
上式中i是商品的索引数值,n为测试集总的样本数,
如前所述,本发明的优势在于:
1.将连锁便利店的销量预测和深度学习、机器学习算法相结合,对比以前人们采用主观经验的方式预测销量会有更加科学有效。
2.将深度信念网络算法(dbn)与支持向量回归机(svr)技术相结合,解决连锁便利店销量预测的问题。对比一些传统销量预测方法精度不高、收敛慢、易陷入局部最优解等缺点,本方法在连锁便利店保质期短的食品类商品销量预测方面有显著效果。
以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!