基于迁移网络的无监督图像视频行人重识别的方法及系统与流程
本发明属于行人重识别技术领域,尤其涉及一种基于迁移网络的无监督图像视频行人重识别的方法及系统,具体涉及一种利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法。
背景技术:
目前,业内常用的现有技术是这样的:
现有的图像到视频的行人重识别模型利用的数据集是有标签的,zhu等人提出了一种结合特征映射矩阵和异质字典对学习的方法,该方法能够对视频内映射矩阵和异质图像视频字典进行学习。zhang等人提出了一种时间记忆的相似性学习神经网络,包括一个特征表示子网和一个相似性子网,前者使用卷积神经网络提取图像的特征并使用长短期记忆网络提取其时间特性,后者用于学习距离度量。wang等人则设计了一种点到集合的网络,该网络首先用k近邻-三元组模式作为降噪器,再将视频和图像作为深度神经网络的输入,共同学习出统一的特征表示和点到集合的距离度量。
行人重识别作为计算机视觉领域里的重要研究问题,兼具实用性和挑战性,能够不受时间和空间限制进行目标行人的跟踪、身份识别以及失踪人口定位等。近年来,行人重识别技术不断发展成熟,在图像到视频的行人重识别问题上,需要根据行人的图像检索出跨设备下该行人的视频,由于学习的图像和视频样本将分别来自不同的特征空间,因此学习它们的映射度量要比图像到图像、视频到视频的同一个特征空间内的度量学习更加困难。
现有的图像到视频的行人重识别模型都基于有监督的框架,并且需要大量的带有标记的图像视频对用于学习映射度量,这对这些模型的现实应用提出了挑战。首先,视频来源可能是城市、乡村或其他任意地方的不可期的摄像设备,这些设备产生的视频样本可能不具有任何标记。除此之外对于类似可疑目标追踪和失踪人口定位的应用场景,往往需要根据给定的图像对监控视频进行快速的检索,但是对大规模的样本进行标记需要付出昂贵的人力和时间代价。因此使用无监督的方法进行图像到视频的行人重识别具有重要的现实意义。
综上所述,现有技术存在的问题是:
(1)现有的图像到视频的行人重识别模型都基于有监督的框架,并且需要大量的带有标记的图像视频对用于学习映射度量,而在不带标记的视频集上无法直接利用度量学习并进行匹配。实际情况中,视频来源可能是城市、乡村或其他任意地方的摄像设备,这些设备产生的视频样本可能不具有任何标记。此外对于需要根据给定的图像对监控视频进行快速检索的应用场景,对大规模的样本进行标记需要付出昂贵的人力和时间代价,因此有监督的行人重识别方法在这些视频集上实现的应用受到了挑战。
(2)现有的行人重学习方法不能处理数据之间的异构性,这些方法仅使用聚类或迁移学习的方法,用于解决图像到图像、视频到视频等同构数据之间的行人重识别问题。而行人图像和视频往往由不同的特征表示,例如,图像使用外观特征表示,包含更多时序信息的视频由时空特征表示,probe图像和gallery视频集的特征之间往往存在极大的鸿沟,阻碍图像与视频之间的距离度量和匹配。
解决上述技术问题的难度:
如何根据已知标记的源域数据进行迁移,使得目标域中的图像和视频之间也进行度量学习。目标数据由于缺乏标记,往往不能直接进行度量学习,例如,若使用三元组损失,需要根据数据标记分别找到一个与anchor有相同标记的样本使得它们之间的距离尽可能近,以及一个不同标记的样本,使得它们的距离尽可能远。
如何消除异构的图像视频数据之间的鸿沟。行人重任务中,图像数据由外观特征表示,而视频数据由于额外包含时间信息,由时空特征表示,两者在特征数量和特征度量上都具有很大的不同,因而需要将两种数据转化到同一特征空间中,转化后的目标域数据仍然需要保持原有空间中的相对关系,然后再进行相似度计算。
解决上述技术问题的意义:
目标域的图像和视频数据由于不包含标记信息,通常无法直接进行度量学习。根据源域数据进行迁移之后,可以利用源域中图像和视频的标记比如使用三元组损失进行度量学习,再使用学习到的特征提取网络,分别提取目标域中源域和目标域的特征。最后得到的目标域中图像和视频的特征也能分别具有相应的距离关系,更加具有鉴别能力。
图像特征和视频特征通过消除彼此之间的异质性,在同一个特征空间对图像和视频之间的关系进行讨论。通过共同子空间的映射,使得目标域中未标记的图像视频数据能够尽可能的与源域中已标记的图像视频相似,并且保留目标域自身的结构特征。映射时往往以视频特征为主,这是由于视频包含更丰富的时空信息,映射之后有效信息丢失可以降到最小。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于迁移网络的无监督图像视频行人重识别的方法及系统。
本发明是这样实现的,一种利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法包括以下步骤:
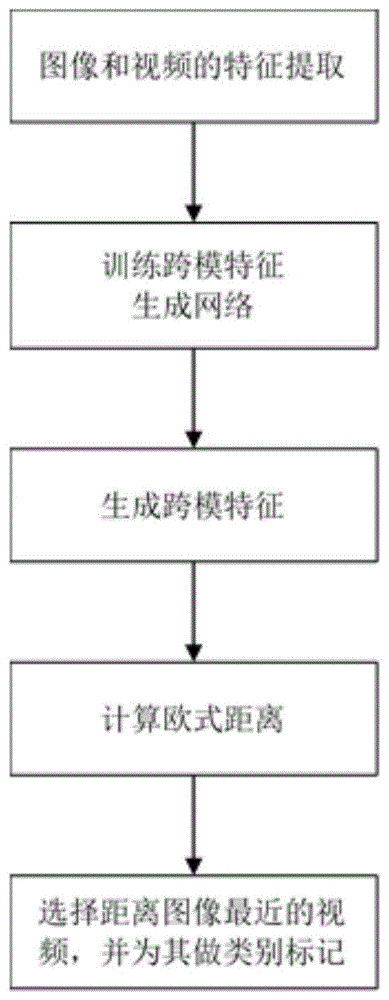
步骤1、将源域中图像和视频数据集x={(is,vs)}用改进后的三元组网络分别进行特征提取。
步骤2、使用源域数据集和目标域训练集训练生成对抗网络,同时考虑跨模特征生成和目标域信息保留。
步骤3、根据目标训练集中待识别的行人图像iti使用步骤2训练好的生成对抗网络,生成深度特征g(f2d(iti))。
步骤4、计算图像的深度特征g(f3d(vtj))与目标域中视频的深度特征g(f3d(vtj))之间的欧氏距离。
步骤5、选择与查询图像距离最近的视频,打上与图像相同的类标记c。
进一步,在步骤1中,假设
为了使模型更快收敛,往往会选择更“难”的三元组,即给定
进一步,在步骤2中,给定一组源域s中带标记的行人图像视频对,训练出的跨模子网包括:提取函数f2d用于提取图像的2d特征,提取函数f3d用于提取视频的3d特征,生成器g用于生成中间的跨模特征,以及判别器d用于辨别特征是来自源域还是目标域。学习出的f2d,f3d,g和d使得整体的跨模迁移损失l达到最小。l的定义如下:
l=lgan+αlcross-modal+βltarget-preserving(2)。
其中,lgan表示生成的迁移网络将目标域内未标记样例特征迁移至源域,并且使得每个判别器无法辨别是源域特征还是g生成的目标域特征。在这种情况下,生成器能够将目标域特征有效地转化至源域,并且与源域分布相同。lgan定义如下:
ex~s表示x来自源域,ey~t表示y来自目标域,d是用于生成特征的二分类函数,d(f(ii))和d(f(vi))分别是样例ii∈s以及vi∈s的可能性,f的选择如下:
lcross-modal学习出一个共享空间,用于从2d和3d特征中生成跨模特征。由于行人视频中的3d特征比图像的2d特征包含更多信息,比如时空信息等,因此生成的特征向量需与f3d(v)相似。lcross-modal定义如下:
lcross-modal=e(i,v)~s||g(f2d(i))-f3d(v)||2+||g(f3d(v))-f3d(v)||2(4)
ei,v~s表示i,v来自源域。
ltarget-preserving能够使迁移生成的g(f2d(it))仍保持目标域中图像的2d判定信息,同样的,生成的g(f3d(vt))保持原有视频的3d判定信息。这是因为目标数据没有标记,其图像和视频之间的相关性也未知。ltarget-preserving定义如下:
ltarget-preserving=e(i,v)~t||g(f2d(i))-f2d(i)||2+||g(f3d(v))-f3d(v)||2(5)
ei,v~t表示i,v来自目标域。
cmgtn可以使用后向传播进行优化,网络中各部分f2d,f3d,g和d的更新过程如下:
输入训练集x={(is,vs)}和y={it,vt},权重参数α和β,并使用改进后的三元组网络对gan中的变量wl,bl进行初始化。经过m次迭代,每次迭代分别选取一批源域和目标域数据{(vsi,isi)∈x,(vti,itj)∈y},使用公式2-5的梯度下降更新特征提取器f2d和f3d,使用公式2的梯度下降更新判别器d。其中,经过n个样本的循环,每次分别采集一批源域和目标域数据{(vsi,isi)∈x,(vti,itj)∈y},使用修改后的判别器d和公式2-5的公式更新生成器g。
进一步,在步骤5中,通过欧式距离度量得到的图像视频对,选择其中与查询图像距离最小的视频作为图像的同类,打上与图像相同的类标记c。其约束如下:
本发明的另一目的在于提供一种利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别控制系统。
本发明的另一目的在于提供一种实现所述利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法的计算机程序。
本发明的另一目的在于提供一种实现所述利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法的信息数据处理终端。
本发明的另一目的在于提供一种计算机可读存储介质,包括指令,当其在计算机上运行时,使得计算机执行所述的利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法。
综上所述,本发明的优点及积极效果为:
本发明使用无监督的方法,缓解了图像到视频的行人重识别任务中经常标签大量缺失的困境,大大节省了标记成本。
本发明利用迁移学习,将源域的度量学习迁移到目标域中,并利用生成对抗网络,学习出的生成器能够将目标域内未标记的样本特征转化至源域,并尽可能的保留目标域的信息。经过迁移后,大量未标记的目标域数据能够获得与源域中已标记数据相似的特征,最终提升图像和视频的匹配准确率。
本发明考虑图像和视频特征之间存在的数据异构性,以包含更多有效信息的视频特征为主进行子空间学习,并且转化后的特征能够保持原域中的结构,消除了图像和视频之间的鸿沟,有效提高了跨模识别的效率。
附图说明
图1是本发明实施例提供的利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法流程图。
图2是本发明实施例提供的dukemtmc-reid数据集作为目标域的cmc曲线图。
图3是本发明实施例提供的mars数据集作为目标域的cmc曲线图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
现有的图像到视频的行人重识别模型都基于有监督的框架,并且需要大量的带有标记的图像视频对用于学习映射度量,而实际场景中数据通常都是无标记的,因此对这些模型的现实应用如度量学习提出了挑战。
视频来源可能是城市、乡村或其他任意地方的不可期的摄像设备,这些设备产生的视频样本可能不具有任何标记。除此之外对于类似可疑目标追踪和失踪人口定位的应用场景,往往需要根据给定的图像对监控视频进行快速的检索,但是对大规模的样本进行标记需要付出昂贵的人力和时间代价。
为解决上述技术问题,下面结合技术方案对本发明做详细描述。
如图1所示,本发明提出的利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别的方法,包括以下步骤:
步骤1、假设
为了使模型更快收敛,往往会选择更“难”的三元组,即给定
步骤2、使用源域数据集和目标域的训练集训练生成对抗网络。给定一组源域s中带标记的行人图像视频对,训练出的跨模子网包括:提取函数f2d用于提取图像的2d特征,提取函数f3d用于提取视频的3d特征,生成器g用于生成中间的跨模特征,以及判别器d用于辨别特征是来自源域还是目标域。学习出的f2d,f3d,g和d使得整体的跨模迁移损失l达到最小。l的定义如下:
l=lgan+αlcross-modal+βltarget-preserving(2)
其中,lgan表示生成的迁移网络将目标域内未标记样例特征迁移至源域,并且使得每个判别器无法辨别是源域特征还是g生成的目标域特征。在这种情况下,生成器能够将目标域特征有效地转化至源域,并且与源域分布相同。lgan定义如下:
ex~s表示x来自源域,ey~t表示y来自目标域,d是用于生成特征的二分类函数,d(f(ii))和d(f(vi))分别是样例ii∈s以及vi∈s的可能性,f的选择如下:
lcross-modal学习出一个共享空间,用于从2d和3d特征中生成跨模特征。由于行人视频中的3d特征比图像的2d特征包含更多信息,比如时空信息等,因此生成的特征向量需与f3d(v)相似。lcross-modal定义如下:
lcross-modal=e(i,v)~s||g(f2d(i))-f3d(v)||2+||g(f3d(v))-f3d(v)||2(4)
ei,v~s表示i,v来自源域。
ltarget-preserving能够使迁移生成的g(f2d(it))仍保持目标域中图像的2d判定信息,同样的,生成的g(f3d(vt))保持原有视频的3d判定信息。这是因为目标数据没有标记,其图像和视频之间的相关性也未知。ltarget-preserving定义如下:
ltarget-preserving=e(i,v)~t||g(f2d(i))-f2d(i)||2+||g(f3d(v))-f3d(v)||2(5)
ei,v~t表示i,v来自目标域。
cmgtn可以使用后向传播进行优化,网络中各部分f2d,f2d,g和d的更新过程如下:
输入训练集x={(is,vs)}和y={it,vt},权重参数α和β,并使用改进后的三元组网络对gan中的变量wl,bl进行初始化。经过m次迭代,每次迭代分别选取一批源域和目标域数据{(vsi,isi)∈x,(vti,itj)∈y},使用公式(5)的梯度下降更新特征提取器f2d和f3d,使用公式2的梯度下降更新判别器d。其中,经过n个样本的循环,每次分别采集一批源域和目标域数据{(vsi,isi)∈x,(vti,itj)∈y},使用修改后的判别器d和公式(5)的公式更新生成器g。
步骤3、根据目标训练集中待识别的行人图像iti使用步骤2得到的生成对抗网络,生成深度特征g(f2d(iti))。
步骤4、计算由步骤3生成的图像特征g(f3d(vtj))与目标域中视频的深度特征g(f3d(vtj))之间的欧氏距离。
步骤5、通过欧式距离度量得到的图像视频对,选择其中与查询图像距离最小的视频作为图像的同类,打上与图像相同的类标记c。其约束如下:
在本发明实施例中,本发明提供一种利用跨模特征生成和目标信息保留的迁移网络的无监督图像视频行人重识别控制系统。
下面结合具体实验对本发明作进一步描述。
为了验证本发明应用无监督的方法在解决图像视频行人重识别问题上的有效性,将提出的cmgtn与另外5种无监督行人重识别模型ucdtl、grdl、camel、dgm和pul进行比较。由于现有无监督方法只适用于单模态,因此需要基于对比方法做一定的修改,这里对比方法的图像特征提取使用jstl特征,视频使用ide特征。并且为了与改进后的三元组网络比较,cmgtn+cm表示使用三元组网络进行特征提取,cmgtn+iv表示分别使用jstl和ide进行图像和视频的特征提取。
实验在mars和dukemtmc-reid数据集上进行,并且使用累积匹配曲线cmc和排名k匹配率评价实验结果。在训练和测试mars时,使用dukemtmc-reid作为源域数据,同理,训练和测试dukemtmc-reid时,mars会被作为源域数据。
dukemtmc-reid数据集作为目标域的cmc曲线如图2。mars数据集作为目标域的cmc曲线如图3。
通过分析实验结果数据可以得到,本发明提出的cmgtn方法在任一排名数量上的匹配度比5种对比方法都要高。以排名为1的匹配率为例,cmgtn方法在dukemtmc-reid数据集上的结果,使得平均匹配率的提升至少为10.6%(=28.6%-18%)。
下面结合取排名前1-20的匹配准确率的实验结果对各方法进行更加详细的比较对本发明作进一步描述。
取排名前1-20的匹配准确率的实验结果对各方法进行更加详细的比较,比较结果如下:
两个数据集上实验结果显示,本发明提出的cmgtn方法比现有的基于聚类的无监督方法和现有的基于迁移学习的方法匹配率更高,在dukemtmc-reid数据集上比现有的最好方法rank-20指标上,最高提升18.3%(53.2%-34.9%),在mars数据集上能够比现有最好的方法同样的指标,最高提升20.3%(65.3%-45.0%)。
并且实验结果验证了使用本发明方法的特征提取网络(cmgtn+cm)能够在所有指标上优于现有的jstl图像特征和ide视频特征方法,在mars数据集上使用本发明方法提出的特征提取网络,能够提升rank-15指标最高16.1%(62.7%-46.6%)。
本发明使用无监督的方法,利用跨模特征生成和目标信息保留的迁移网络,对多种模态的图像和视频进行学习,有效提高了跨模识别的效率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!