一种跨数据库的大数据分析系统和分析方法与流程
本发明涉及大数据分析领域,例如政务大数据分析、智慧城市大数据分析等,具体涉及一种跨数据库的大数据分析系统和分析方法。
背景技术:
数据孤岛是指各个数据库中的数据无法(或者极其困难)连接互动,即数据间缺乏关联性,数据库彼此孤立、无法兼容。数据孤岛分为物理性和逻辑性两种。物理性的数据孤岛指的是,数据在不同部门相互独立存储,独立维护,彼此间相互独立,形成了物理上的数据隔离。逻辑性的数据孤岛指的是,不同部门站在自己的角度对数据进行理解和定义,使得一些相同的数据被赋予了不同的含义,无形中加大了跨部门数据合作的沟通成本,使原本可以相互关联、彼此连动的数据,变成了毫不相关、各自孤立的数据。
数据孤岛问题在企业内部普遍存在,企业发展到一定阶段,出现多个事业部,每个事业部都有各自数据,事业部之间的数据往往都各自存储,各自定义。尤其是集团化的企业就更加明显,大部分集团企业的部门划分以功能型为主,部门与部门之间相对独立,企业中每个部门都会产生相应的数据,但各部门对数据的理解角度不同,对数据的使用和定义有比较大的差异,导致数据无法互通,形成孤岛。另一方面,许多企业中的信息部门建设比较晚,信息系统建设的标准不统一,使日后的数据互通存在较大的阻碍。
消除数据孤岛是一项长期艰难的工作,最常见的方法是数据关联,使本来毫不相关的数据,随着关联数据的增多,数据维度增加,可挖掘的价值变大,从而使原来看不到太大价值的数据,产生巨大价值。但是,数据关联往往存在众多障碍,其中最大阻碍是,每个数据库、表结构都与应用程序关系密切、紧密耦合,当数据库中的数据脱离了原来的生存环境,发送到其它信息系统之后,由于接收数据的信息系统中与该数据之间没有相应的表结构,也没有相应的耦合关系,数据就成了无意义的、无价值的数据。
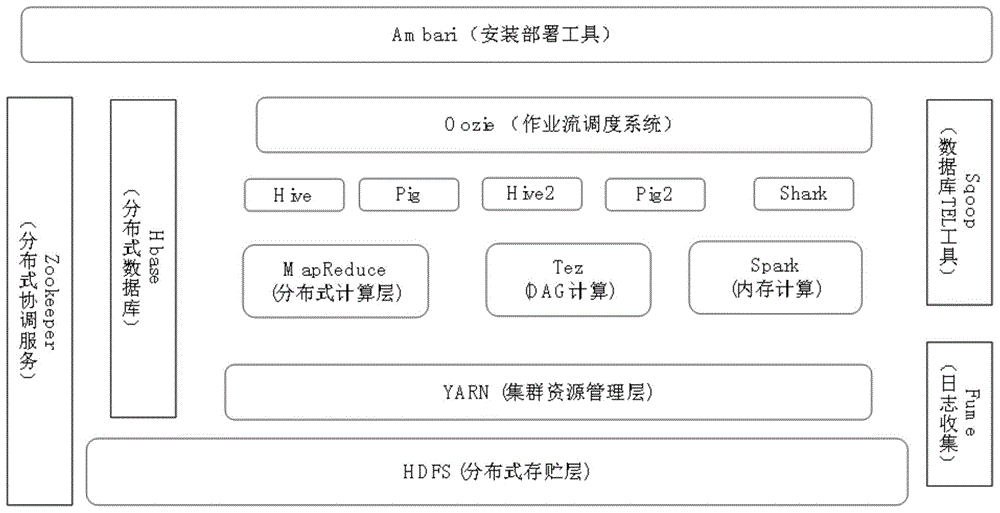
消除物理性的数据孤岛在技术上较为成熟,消除方法即将这些数据集中或分布式统一管理。如图1所示,基于标准的大数据hadoop平台是选择之一,hadoop是一个能够对海量数据进行分布式处理的软件框架,hadoop以一种可靠、高效、可伸缩的方式进行数据处理,提供数据的分布式存贮、分布式计算、分布式数据库等,可统一存贮、管理隔离的数据,消除数据之间的物理隔离。但是,这种存储方式无法消除数据的逻辑性隔离,不同数据库中的数据的理解和定义仍然不同,数据库之间的关联、数据对应用的反应无法得到满足,数据无法成为有价值的、可直接提供服务的应用数据。
技术实现要素:
针对以上不足,本发明提供了一种跨数据库的大数据分析系统和分析方法,用于解决数据的逻辑性隔离和对应用服务的反应问题。本发明从自然语言理解角度,赋予相互孤立数据库中的数据以共同意义和相似度,将相似服务关联融合、聚合在一起,为上层应用提供跨数据库的直接服务。
本发明的技术方案为:
一种跨数据库的大数据分析系统,包括服务理解模块、服务生成模块和服务数据库,所述服务理解模块用于通过深度学习法生成智能服务模型,聚合各个孤立数据库所提供的服务,将可提供的服务录入所述服务数据库,所述服务生成模块用于响应新的服务请求,从服务数据库中选择相应的服务进行推送,所述服务数据库用于存储聚合后的新的服务。
还包括人工干预模块,所述人工干预模块用于对服务生成模块所选择的服务进行人工修改,并将修改的内容提供给服务理解模块,对智能服务模型进行更新。
所述深度学习法为机器学习自然语言的方法,该方法将所有孤立数据库提供的服务在语义上聚类,将相近服务聚合在一起,提供跨数据库的服务。
所述智能服务模型采用词向量嵌入法表示。
所述智能服务模型由自然语言处理深度学习模型、服务词模型和服务聚类模型组成。
一种跨数据库的大数据分析方法,包括以下步骤:
s1:初始化服务,建立可提供服务的初始化列表;
s2:初始化服务理解模块的深度学习词典,将多个孤立数据库的主键、关键词纳入词典中,形成扩展词典;
s3:服务理解模块对多个数据库运行语法分析、词性分析,形成可提供服务的关键词向量数据列表;
s4:服务理解模块采用词向量嵌入法建立智能服务模型;
s5:服务理解模块计算各个关键词向量间的距离,在词向量间建立相似度度量;
s6:服务理解模块根据预先设定的相似度阈值,将各个词向量间的相似度与阈值作比较,将相似度大于阈值的相似服务键值合并;
s7:服务理解模块对各个相似服务所对应的数据库进行数据分析,将合并后的新的服务信息存入服务数据库;
s8:智能服务模型接收到上层应用发出的新的服务请求,通过语法分析、词性分析、关键词切分,得到服务请求的关键词向量列表;
s9:服务生成模块将服务请求的关键词向量与服务数据库中服务的键值词向量作比较,计算两者之间的相似度;
s10:服务生成模块将相似度从大到小排序,选择相似度靠前的设定数目的多个服务作为候选服务;
s11:服务生成模块将候选服务推送给上层应用。
所述步骤s9的比较过程具体为:将服务请求的关键词向量与服务数据库中所有服务的键值词向量作比较。
所述步骤s9的比较过程具体为:建立服务数据库键值搜索树,采用搜索树检索服务数据库中的服务键值,将服务请求的关键词向量与检索到的键值词向量作比较。
所述步骤s10和s11之间还包括以下步骤:所述人工干预模块对服务生成模块所选择的候选服务进行人工修改,将修改后的服务作为候选服务。
所述人工干预模块对服务生成模块所选择的候选服务进行人工修改后,将修改内容提供给服务理解模块,对智能服务模型进行更新。
本发明的跨数据库的大数据分析系统和分析方法,通过深度学习法生成智能服务模型,智能服务模型通过机器学习、数据挖掘、统计分析、检索等方式处理各个孤立数据库中的服务数据,将新的、有价值的、可直接提供服务的可服务数据存储到服务数据库。利用智能服务模型来处理服务请求,通过对服务关键词向量的一致性测量,使服务关键词、数据库键值等在向量相似度上获得语义的一致性,将相似的服务推送给上层应用,打破各个独立数据库之间的不相关,建立数据之间在服务上的关联性。
本发明的大数据分析系统和分析方法还具有人工干预功能,根据用户的反馈,对选择的服务进行人工修改、优化,使提供的服务更加贴进用户深层的、隐含的需要。人工干预结果同时对智能服务模型进行迭代更新,使包含可服务数据的服务数据库不断契合用户的实际需求,同时也为底层数据的关联、提取可服务数据提供了关联线索和方向。
附图说明
图1为hadoop分布式系统基础架构图;
图2为本发明跨数据库的大数据分析系统架构图;
图3为本发明服务理解模块的工作关系图;
图4为本发明服务理解模块的工作步骤图;
图5为本发明服务生成模块的工作步骤图;
图6为本发明服务关键词检索示意图。
具体实施方式
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分地了解本发明的目的、特征和效果。
参考图2,本发明的跨数据库的大数据分析系统,包括服务理解模块、服务生成模块、服务数据库和人工干预模块。服务理解模块用于通过深度学习法生成智能服务模型,聚合各个孤立数据库所提供的服务,并将可提供的服务录入服务数据库。服务生成模块用于响应新的服务请求,从服务数据库中选择相应的服务进行推送。服务数据库用于存储聚合后的新的服务。人工干预模块用于对服务生成模块所选择的服务进行人工修改,并将修改的内容提供给服务理解模块,对智能服务模型进行更新。
如图2所示,数据库1,数据库2,…,数据库n为各个孤立的数据库,所提供的信息服务内容不尽相同,每个数据库包括主键及所提供的独立服务,均以文本字符串形式输入。在文字的表达方式上,即使包含同样的含义,其文字的表现方式仍然可能有所区别。如“气象”、“天气”、“天气预报”等相似键值词,其所提供的信息服务均为“天气数据”。
参考图3和图4,服务理解模块的深度学习法为机器学习自然语言的方法,利用该方法来处理各个孤立数据库所提供服务的关键词、数据库键值等,通过相似度测量,将服务在语义上聚类,将相近服务聚合在一起。打破各个独立数据库之间的不相关,建立数据之间的在服务上的关联,在此关联数据集的基础上,通过机器学习、数据挖掘、统计分析、检索等方法处理自然语言,生成新的、有价值的可服务数据。
智能服务模型由自然语言处理深度学习模型、服务词模型和服务聚类模型组成,并采用词向量嵌入法表示。对于文字数据来说,如果采用标签编码器方式(labelencoder)来编码,不同词汇的id取值如果非常接近,并不能有实际的意义表示。如果采用离散型特征编码方式(onehot)来编码,则会导致向量维度过高,过于稀疏,同时也依然难以在数值上表示出不同词之间的关系。
词向量嵌入法可以从原始文本(语料库)中读取词语然后生成词向量,找到一种词与向量的映射关系,使得向量维度不需要过大,而且词向量在向量空间中所表示的点具有实际的意义,也就是相似含义的词在空间中的距离更近。从本发明来说,词向量嵌入法可以更好地计算服务关键词在空间中的距离,从而找到相互距离较近的、相似的若干服务。
本发明的服务理解模块所生成的智能服务模型,不仅用于对多个孤立数据库所提供的相似服务聚合在一起,将聚合后的相似服务纳入服务数据库,使服务数据库存储合并后的、有价值的、可直接提供服务的可服务数据。同时,智能服务模型还用于对接收上层应用发出的、新的服务请求,通过语法分析、词性分析、关键词切分,得到服务关键词向量列表。
参考图5,本发明的服务生成模块用于将服务请求的关键词向量与服务数据库中存储的服务的键值词向量作比较,计算两者之间的空间距离,找到空间距离较近的、较相似的服务,将相似度从大到小排序,根据预先设定的服务推送数目,匹配靠前的多个服务作为候选服务,推送给上层应用。
如图6所示,在匹配过程中,服务请求的关键词列表不一定在服务数据库中完全对应,例如服务请求关键词是“大楼价格、楼房市值”,而服务数据库中没有对应键值,但是有相关的“大楼资产”等键值,因此需要服务检索树将“大楼价格、楼房市值”变换到键值“大楼资产”,才能从服务数据库中选取出相应的服务。
如果服务数据库规模较小,键值规模小,可以采取全匹配方法,计算服务数据库中所有服务键值词与服务请求关键词向量的相似度。如果服务数据库规模较大,键值规模大,可以建立服务数据库键值搜索树,采用搜索树检索服务键值,然后仅将检索出的服务键值词与服务请求关键词作比较,加快检索和比较速度。
人工干预模块可以对服务生成模块选择的服务进行人工修改、优化,模块设有信息交互接口,人工通过信息交互接口与系统进行信息交互。修改数据来源于上层应用用户的反馈,根据用户的反馈意见对选择结果进行修改,使大数据分析系统提供的服务更加贴进用户深层的、隐含的需要。人工干预结果同时对智能服务模型进行迭代更新,使包含可服务数据的服务数据库不断契合用户的实际需求,同时也为底层数据的关联、提取可服务数据提供了关联线索和方向。
服务数据库用于存储聚合后的服务,服务请求与可服务数据之间是多对多的关系,一个服务请求可能需要多条可服务数据,一条可服务数据可以为多种不同的应用场景提供服务。可服务数据有即时性、可重复利用的特点,可快速组合、切换,提供即时性服务,满足等现场服务(例如应急指挥)的实时性要求。
一个可服务数据的示例如下:
服务数据库支持多种用户的需求描述,包括底层数据统计分析结果、业务对某些数据的需求描述、以及对数据本身管理的管理数据,特别支持数据的自然语言描述。通过将用户的需求映射到服务数据库,打通了用户对数据的消费。将映射的可服务数据推送给上层应用用户,上层应用包括协助指挥检测、演示汇报、生产运行、应急指挥等多种应用场景,都通过可视化的方式展现给用户,让用户看到数据、理解数据,打通数据孤岛,最大化发挥数据的作用,使原本无意义的数据,变得有意义、有价值。
本发明的跨数据库的大数据分析方法,包括以下步骤:
s1:初始化服务,建立可提供服务的初始化列表,一般根据运营商以往的运营经验来确定可以提供的服务;
s2:初始化服务理解模块的深度学习词典,将多个孤立数据库的主键、关键词纳入词典中,形成扩展词典;
s3:服务理解模块对多个数据库运行句法分析、词性分析,形成可提供服务的关键词向量;
s4:服务理解模块采用词向量嵌入法建立智能服务模型;
s5:服务理解模块计算各个关键词向量间的距离,在词向量间建立相似度度量,词向量支持各种距离,例如欧式距离、曼哈顿距离、切比雪夫距离、闵可夫斯基距离、马氏距离和夹角余弦距离等;
s6:服务理解模块根据预先设定的相似度阈值,将各个词向量间的相似度与阈值作比较,将相似度大于阈值的相似服务键值合并;如果孤立数据库的数量较多、服务键值数量也较多,词向量相似度的计算可以采用机器学习的聚类算法,完成同一类服务的聚合;
s7:服务理解模块对各个相似服务所对应的数据库进行数据分析,将合并后的新的服务存入服务数据库;如果某个服务依赖的原始数据经过服务理解模块分析后,聚合了跨数据库的新的数据集,新的数据集提取了原始数据的内容,直接存贮在服务数据库上;如果新服务依赖的数据是原始数据,服务数据库则提供原始数据库路径,引导服务生成模块找到所对应的服务;
s8:智能服务模型接收到上层应用发出的新的服务请求,通过语法分析、词性分析、关键词切分,得到服务关键词向量列表;
s9:服务生成模块将服务请求的关键词向量与服务数据库中的服务键值词向量作比较,计算两者之间的相似度;对于规模较小的服务数据库,采取全匹配方法,计算服务数据库中所有服务键值词与服务请求关键词向量的相似度;对于规模较大的服务数据库,建立服务数据库键值搜索树,采用搜索树检索服务键值,加快检索速度;
s10:服务生成模块将计算出的相似度从大到小排序,根据预先设定的推送数目,选择相似度靠前的多个服务作为候选服务;同时,服务生成模块也接受人工干预模块的干预,对服务生成模块所选择的候选服务进行人工修改,将修改后的服务作为候选服务;人工干预模块对服务生成模块所选择的候选服务进行人工修改后,将修改内容提供给服务理解模块,对智能服务模型进行更新;
s11:服务生成模块将候选服务推送给上层应用。
本发明的跨数据库的大数据分析系统和分析方法,从自然语言理解角度,赋予相互孤立数据库中的数据以共同意义和相似度,将相似服务关联融合、聚合在一起,为上层应用提供跨数据库的直接服务。本发明解决了数据的逻辑性隔离和对应用服务的反应问题,让各个孤立数据库彼此兼容,让数据库中的数据相互具有关联性,更加互动,更有价值。
以上公开的仅为本发明的实施例,但是,本发明并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!