一种基于用户行为特征的IPTV日志用户识别方法与流程
本发明涉及iptv技术领域和用户识别的交叉技术领域,具体地说是一种基于用户行为特征的iptv日志用户识别方法。
背景技术:
如今社会犯罪每天都在发生,在逃的犯罪嫌疑人往往会对自己的数字行为进行匿名处理,导致其身份的识别和追踪甚难。随着互联网协议电视iptv(internetprotocoltelevision)技术日新月异的发展,iptv开始普及到每个家庭,丰富的iptv用户行为日志为基于iptv用户行为特征进行嫌疑人身份识别成为了可能。
在iptv系统中,用户观看行为特征指不同人观看频道的时长、频率、时段等特征,能够精准地区分不同的用户,而且iptv日志数据可以通过用户家庭的机顶盒进行提取,这给系统运行提供了硬件条件和数据来源。并且,在iptv的用户场景下,普遍为多用户共享一台iptv设备。这就使得日志中参杂着多个用户的特征,使得传统的频率分析正确率不高。
技术实现要素:
本发明的主要目的是针对iptv多用户识别问题而提供的一种基于用户行为特征的用户识别方法。通过此方法可以以较高的准确度定位嫌疑人的身份和确定嫌疑人的地理位置。
一种基于用户行为特征的iptv日志用户识别方法,包括以下步骤:
1.选取连续若干天的日志作为原始数据;
2.通过聚类算法将原始数据打碎为若干个时间段,分析每个时间段中用户对频道的评分,将特征相似的时间段进行合并,得到特征数据:
3.对需要识别的数据重复步骤2,得到预匹配数据;
4.将预匹配数据与特征数据进行匹配,统计重复次数最多的用户作为识别结果输出。
进一步的,所述原始数据包括以下数据结构:用户设备号或用户智能卡卡号,用户当前观看的频道id,开始观看时间以及观看或切台的时刻。
进一步的,所述步骤2的生成特征数据的过程包括如下步骤:
2.1对原始数据中的开始观看时间采用k-平均算法(k-meansclustering)进行聚类,得到k个时间段tk,记作{t1,t2,t3,...,tn,...tk};
2.2对于时间段tn,利用评分公式计算用户user对每个频道的评分向量a(user,channel),评分公式:
其中
2.3对于ta和tb两个不同时间段,采用余弦公式计算相似度,余弦公式:
其中a和b分别表示ta和tb时间段提取的评分向量。
2.4定义阈值β,将相似度小于β的时间段进行合并,并计算合并后的评分向量,所得到的评分向量即为特征数据。
步骤2.4的合并过程具体为:
i.利用公式(2)计算所有时间段之间的相似度,以时间段作为节点,边权为节点之间的相似度,两两连接形成一张完全图;
ii.按照边权从大到小依次合并相似度小于β的两个时间段,并利用公式(1)计算合并后时间段的评分向量,以及该时间段与其它时间段的相似度;
iii.重复步骤ii,直到不存在相似度小于β的时间段为止。
进一步的,步骤4的匹配过程包括如下步骤:
4.1将每一个需要进行匹配的预匹配数据和步骤2中得到的特征数据利用公式(2)计算相似度,对相似度排序后,选取前n个相似度最高的特征数据,提取用户设备号un得到序列{u1,u2,u3,...,un};
4.2统计序列{u1,u2,u3,...,un}中重复次数最多的用户作为识别结果输出。
进一步的,所述预匹配数据和特征数据均为评分向量。
与现有的技术相比,本发明所提出的特征数据提取方法,仅需要获取用户的频道观看记录,且特征数据可以以天为单位长期存储,特征按时间进行分片,因此不会由于数据时间窗口过长而带来识别率下降的问题。
本发明所提出的用户识别系统和方法,将原始数据分片后进行用户匹配,可以有效拆分在同一个设备中的多个用户特征,避免多用户造成特征数据模糊识别率下降的问题。
附图说明
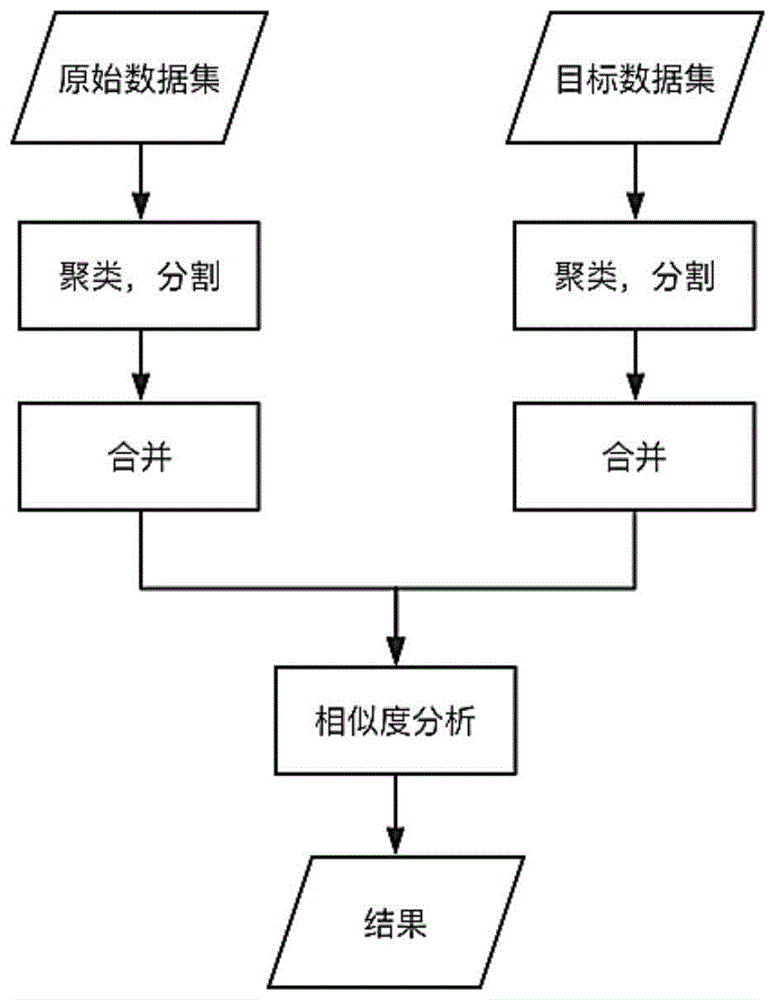
图1为利用用户日志文件进行用户识别的流程图;
图2为利用iptv日志文件特征进行嫌疑人定位的方法示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示的一种基于用户行为特征的iptv日志用户识别方法,首先预处理用户日志文件,根据时间段对每个iptv设备的用户进行分片,将特征相似的时间片进行合并。然后对需要进行识别的用户数据分片,分别与处理后的特征数据进行匹配,其具体步骤如下:
1.按照时间先后顺序排序用户日志文件,选取连续若干天的用户日志作为原始数据。原始数据包括以下数据结构<deviceid,channelid,begintime,endtime>,deviceid表示机顶盒的设备号或用户智能卡卡号,channelid为用户当前观看的频道id,begintime为开始观看的时刻,endtime为结束观看或切台的时刻。
2.通过聚类算法将原始数据打碎为若干个时间片段,分析每个时间片段中用户对频道的评分,将特征相似的时间片段进行合并,得到特征数据,具体包括以下步骤:
2.1对原始数据中的开始观看时间进行聚类,算法可以采用k-平均算法(k-meansclustering),得到k个时间段,记作{t1,t2,t3,...,tk};
2.2对于时间段tn,利用评分公式计算用户user对每个频道的评分,评分公式:
其中
2.3对于ta,tb两个不同时间段,采用余弦公式计算相似度,余弦公式:
其中a,b分别表示ta,tb时间段提取的评分向量
2.4定义阈值β,将相似度小于β的时间段进行合并,并利用公式(1)计算合并后的评分向量,具体过程如下:
i.对所有时间段利用公式(2)计算其相似度,连接形成一张完全图;
ii.按照边权从大到小依次合并相似度小于β的两个时间段,并利用公式(1)计算合并后节点的评分向量,以及该节点与其它节点的相似度;
iii.重复步骤ii,直到不存在相似度小于β的时间段为止。
3.对需要识别的数据重复步骤2得到预匹配数据;
4.将预匹配数据与特征数据进行匹配,确定原始用户设备号:
4.1将每一个需要进行匹配的预匹配数据和步骤2中得到的特征数据计算相似度,相似度计算采用余弦相似度,其计算公式如下:
其中a,b表示任意两个用户数据提取的评分向量;
4.2对相似度排序后,选取前n个相似度最高的特征数据,提取用户设备号un,得到序列{u1,u2,u3,...,un},统计序列{u1,u2,u3,...,un}中重复次数最多的用户作为识别结果输出。
图2所示描述了一种利用iptv日志文件特征进行嫌疑人定位的方法,具体包括以下步骤:
1.划定识别范围,初步确定嫌疑人所处的地区后,选取连续若干天该地区的用户日志作为原始数据;
2.预处理特征数据,通过聚类算法将原始数据打碎为若干个时间片段,分析每个时间片段中用户对频道的评分,将特征相似的时间片段进行合并,得到特征数据;
3.处理嫌疑人数据,从嫌疑人居住地点提取iptv的观看日志,同样通过聚类算法将原始数据打碎为若干个时间片段,将特征相似的时间片段进行合并,得到嫌疑人数据;
4.将嫌疑人数据与特征数据进行比对,对相似度从大到小排序后,取相似度较前的结果得到用户列表{u1,u2,u3,...,un},嫌疑人有较大的可能藏匿在这些用户当中,统计序列{u1,u2,u3,...,un}中重复次数最多的用户作为识别结果输出。如图2中分析得到两个排名较前的可疑设备,与嫌疑人数据的相似度分别为81.8%和18.2%;
以上所述仅为本申请的较佳实施例而已,并不用于限制本申请,凡在本申请的原则和精神之内所作的任何修改、等同替换和改进等,均就包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!