一种视网膜OCT图像分层算法的制作方法
本发明涉及图像处理分析技术领域,具体涉及一种视网膜oct图像分层算法。
背景技术:
目前现在的视网膜分层算法,大多为传统算法,例如dijkstra算法,效率较低,浪费时间,还有部分单纯地利用深度学习算法,但是仅仅依靠深度学习需要大量的训练数据,同时深度学习具有不稳定性,使得分层效果得不到保障,算法鲁棒性及准确率都不理想。
技术实现要素:
本发明的目的在于提供种视网膜oct图像分层算法,以解决现有技术中导致的上述多项缺陷或缺陷之一。
为解决上述技术问题,本发明采用的技术方案为:
一种视网膜oct图像分层算法,包括如下步骤:
采集视网膜oct三维图像并提取b扫描方向的b扫描切片,训练深度学习模型;
对所述视网膜oct三维图像进行内外视网膜边界预测,获取视网膜oct三维图像中第一层、第六层、第七层和第十一层的粗略分层结果;
根据获取的粗略分层结果中所述第一层和第七层的边界信息,对源输入的视网膜oct三维图像在b扫描方向上各个切片图像进行对齐操作,获取对齐的三维视网膜oct图像;
对对齐的视网膜oct三维图像下采样至l2体图像,获取l2体图像第一、二、五、七、十一层的精确分层结果,其中,l2体图像的深度为视网膜oct三维图像深度的1/2,l2体图像中b扫描切片图像的宽为视网膜oct三维图像宽的1/2,高为视网膜oct三维图像高的1/2;
将l2体图像精确分层的结果上采样至l1体图像,获取l1体图像第一、二、六、七、九、十一层精确分层结果,其中,l1体图像的深度为视网膜oct三维图像深度的1/2,l1体图像中b扫描切片图像的宽为视网膜oct三维图像宽的1/8,高为视网膜oct三维图像高的1/8;
将l1体图像的精确分层结果上采样至视网膜oct三维图像,获取对齐操作后的视网膜oct三维图像的精确分层结果,并将精确分层的结果调整到源输入的视网膜oct三维图像,获取源输入的视网膜oct三维图像的精确分层结果。
本发明的优点在于:
1、提出的视网膜oct三维图像分层算法,结合了深度学习模型和动态约束图搜索算法,具有效率高,节约时间和分层效果好的优点;
2、本发明结合了深度学习模型和动态约束图搜索算法,在训练数据的选取上包含了大量的b扫描切片图像,保证了模型应用的稳定性;
3、本发明将深度学习模型和动态图搜索算法相互结合,相辅相成,提高了分层效果;特别是对于各个切片间抖动幅度较大的图像和拍摄模糊的图像,两者结合之后效果有了显著提升。
附图说明
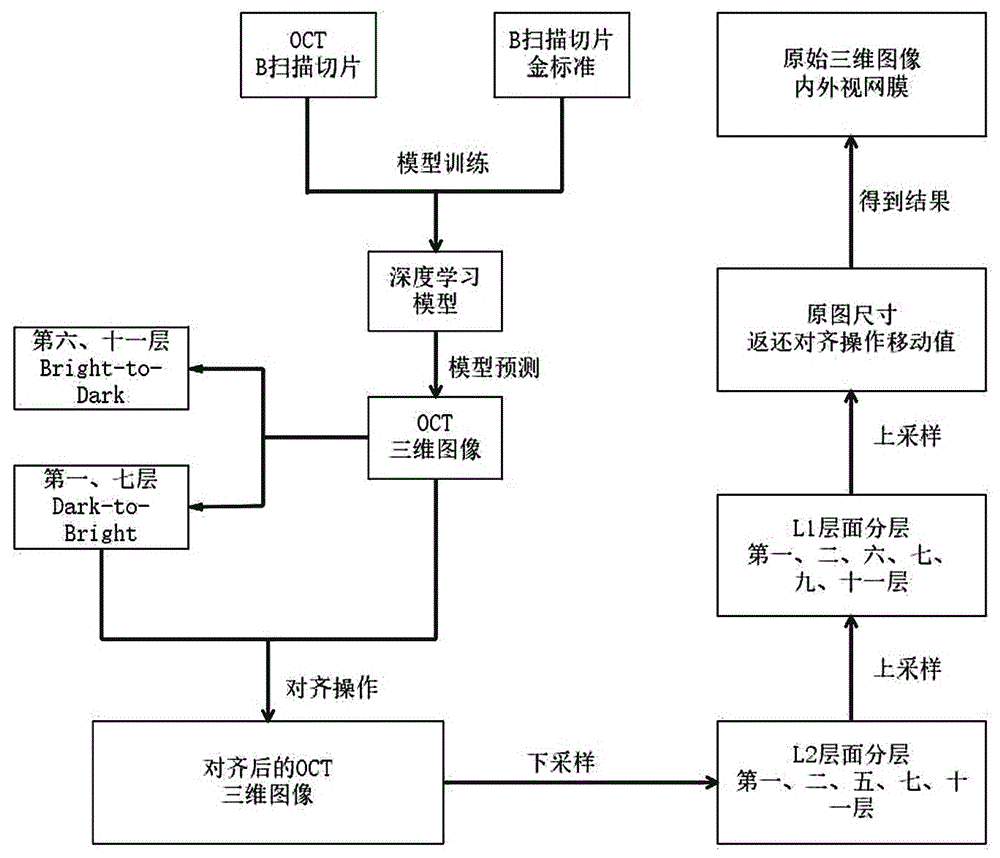
图1为本发明具体实施方式视网膜oct图像分层算法的流程图;
图2为本发明具体实施方式视网膜oct图像分层算法中训练数据的示意图;
图3为本发明具体实施方式视网膜oct图像分层算法中金标准的示意图;
图4为本发明具体实施方式视网膜oct图像分层算法中模型预测的第六层、第十一层的位置示意图;
图5为本发明具体实施方式视网膜oct图像分层算法中模型预测的第一层、第七层的位置示意图;
图6为本发明具体实施方式视网膜oct图像分层算法动态约束示意图;
图7为本发明具体实施方式视网膜oct图像分层算法分层结果示意图。
具体实施方式
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
如图1至图7所示,一种视网膜oct图像分层算法,所述算法包括如下步骤:步骤1:采集视网膜oct三维图像并通过算法提取b扫描方向的b扫描切片以训练模型。获取深度学习训练模型,模型训练过程中,对训练数据的选取上,预先选取大量的视网膜oct三维图像中b扫描切片图像,采集的b扫描切片图像中包含了大量的正常的和患病的视网膜b扫描切片图像,其中包含黄斑区域和视乳头区域的b扫描切片,保证模型应用的稳定性,训练数据的结果如图2所示。训练中以选取预先采集的视网膜oct三维图像中b扫描切片图像作为训练数据,以对应的内外视网膜三值图为训练金标准,金标准示意图如图3所示。其中,内外视网膜三值图包括背景、内视网膜和外视网膜三种像素值。所训练的神经网络分为收缩路径和扩展路径,收缩路径包含四层,每层是每两个3*3的卷积层后会跟一个2*2的最大池化层,并且每个卷积层后面采用relu激活函数对b扫描切片进行下采样操作,其中,b扫描切片是从预先采集的视网膜oct三维图像中提取的,每一次下采样b扫描切片都会增加1倍通道数。下采样是为了计算过程中减少计算量,提高了工作效率。扩展路径有四层,每层在上采样过程中,都有一个2*2的卷积层和两个3*3的卷积层,与此同时,每一步的上采样过程都会加入来自相应收缩路径并经裁剪以保持相同的形状的特征图。在网络的最后一层是一个1*1的卷积层,将64通道的特征向量转换为所需要粗略分层结果。
步骤2:模型预测,使用训练得到的模型对视网膜oct三维图像的内外视网膜边界预测,粗略分割出内外视网膜并通过像素值搜索后处理获取视网膜oct图像中第一层、第六层、第七层和第十一层的粗略分层结果。例如,一个视网膜oct三维图像中b扫描切片中自上而下第一个非零值点即为第一层,再往下第一个非零点为第六层,自下而上同理可得第十一层与第七层。第六层和第十一层的位置如图4所示,第一层和第七层的位置如图5所示。
步骤3:基于视网膜oct三维图像中b扫描切片中视网膜第一层、第七层粗略分割结果对源输入的视网膜oct三维图像进行对齐处理,去除抖动干扰,具体方法为:以深度学习模型预测得到第一、七层信息的每个点的位置的平均值为该b扫描切片的相对位置,在整个三维数据中,以相对位置最大的b扫描切片m的相对位置为基准位置,其他b扫描切片以基准位置与各自相对位置的差值作为移动距离,分别移动至与切片m相同相对位置,以得到各b扫描切片对齐后的三维图像,各b扫描切片相对位置。
步骤4:对对齐的视网膜oct图像进行下采样,下采样至l2体图像,其中,l2体图像的深度为视网膜oct三维图像深度的1/2,l2体图像中b扫描切片图像的宽为视网膜oct三维图像宽的1/2,高为视网膜oct三维图像高的1/2。将大小为x×y×z的视网膜oct三维图像中各个像素点对应为图像数据结构中的各个顶点来建图,每个层表面对应为每一个x和y方向上的z方向值大小,将其表示为f(x,y):其中x∈{0,···,x-1},y∈{0,···,y-1},z∈{0,···,z-1}。基于动态约束图搜索,将模型预测得到的结果用以计算边界能量,对l2体图像视网膜第一、二、五、七、十一层进行精确分层,具体约束方法:首先运用多层搜索算法获取l2体图像第一层、第七层的位置;以二者位置平均值为上界、第七层位置加补偿项(补偿项皆为人工经验值)为下界,运用多层搜索算法获取l2体图像第五层以及更新的第七层的位置;以更新后的第七层的位置为上界,第七层的位置加补偿项为下界,运用单层搜索算法获取l2体图像第十一层的位置;以第五层的位置为上界,第十一层的位置减去补偿值为下界,重新获取更为精确地第七层的位置;以第一层的位置为上界,第五层的位置为下界,获取l2体图像第二层的位置,至此,l2体图像获取视网膜分层结束。
步骤5:将l2体图像分层结果上采样至l1体图像,作为约束参数,基于动态约束图搜索对l1体图像视网膜第一、二、六、七、九、十一层进行精确分层;其中,l1体图像的深度为视网膜oct三维图像深度的1/2,l1体图像中b扫描切片图像的宽为视网膜oct三维图像宽的1/8,高为视网膜oct三维图像高的1/8。具体约束方法:以第七层的位置为上界,第十一层的位置加补偿项为下界,运用单层搜索算法获取第十一层的位置;以第一层的位置为上界,第五层的位置减去补偿项为下界,采用单层搜索算法获取第二层的位置;以第一层的位置减补偿项为上界,第二层的位置加补偿项为下界,运用单层搜索算法获取更为精确的第一层的位置;以第五层的位置为上界,第七层的位置为下界,运用单层搜索算法,获取视网膜第六层的位置;以第六层的位置为上界,第十一层的位置减补偿项为下界,运用多层搜索算法,获取视网膜第七层的位置与第九层的位置,至此l1体图像的视网膜第一、二、六、七、九、十一层获取完成。
步骤6:将l1体图像的精确分层结果上采样至视网膜oct三维图像,并返还视网膜oct三维图像中b扫描切片对齐操作所移动的距离,获取源输入的视网膜oct三维图像的精确分层结果,如图7所示。
如图7所示,本发明提出的视网膜oct三维图像分层算法,结合了深度学习模型和动态约束图搜索算法,具有效率高,节约时间和分层效果好的优点。
由技术常识可知,本发明可以通过其它的不脱离其精神实质或必要特征的实施方案来实现。因此,上述公开的实施方案,就各方面而言,都只是举例说明,并不是仅有的。所有在本发明范围内或在等同于本发明的范围内的改变均被本发明包含。
- 还没有人留言评论。精彩留言会获得点赞!