一种互联网金融平台用户评论主题分析系统及方法与流程
本发明涉及自然语言处理领域,尤其涉及一种基于用户印象的互联网金融平台用户评论主题分析系统及方法。
背景技术:
近年来随着互联网技术的发展和普及,传统金融机构与互联网企业结合,利用互联网技术提供金融相关服务,以互联网为平台开展各类金融活动,各类p2p,众筹,第三方支付,网贷,理财等金融平台相继涌现。“门槛低、收益高、投资周期短、风险小等”铺天盖地的营销文案吸引普通投资者纷纷投入到互联网金融的浪潮中。这些金融平台丰富了大众投资渠道的同时,也相应的带来了极大的风险。许多问题平台注销、跑路,致使普通投资者血本无归,给社会造成巨大不良影响。
通过对互联网金融平台的用户评论分析,可以帮助投资者对平台情况有更加全面公正的了解,辅助投资者进行决策,降低投资风险。
目前常见的评论分析技术有情感分析、评论观点提取分析等。情感分析通过情感词典或机器学习等算法分析用户评论内容的情感极性,通常分为正面、负面、中立三类情感极性,无法给出对平台情况的描述。评论观点提取分析方法主要有基于规则的提取、基于lda模型的主题分析、基于聚类的算法等。在基于规则的观点提取方法中,归纳观点陈述句的固定的句式结构规则,通过句法分析工具以及规则可以简单有效地抽取到评论观点。但人工总结规则的方式,无法涵盖所有的观点表述方式。并且,这种方法仅对陈述句有效,而中文中有多种句式表达方式。对于以lda为代表的主题模型和以k-means为代表的传统聚类方法,方法比较成熟,效果也得到了很多场景的验证。但是这类方法直接从用户评论中挖掘主题,主题受评论数据的影响较大,得到的主题没有直观的主题含义,且不能涵盖有助于全面有效了解金融平台整体情况的主题视角。
因此如何高效地对金融平台用户评论进行分析,提取有代表性的用户评论主题是目前需要解决的问题。
技术实现要素:
本发明的目的在于提供一种互联网金融平台用户评论主题分析系统和方法,从而解决现有技术中存在的前述问题。
为了实现上述目的,本发明采用的技术方案如下:
一种互联网金融平台用户评论主题分析系统,包括数据采集模块、金融词向量学习模块、评论主题生成模块、用户评论分类模块和评论主题更新模块,所述数据采集模块采集金融类新闻报道、用户评论和用户印象,并将其汇总后入库;
所述金融词向量学习模块是基于金融平台评论和金融新闻等数据学习金融领域词向量,并定期更新,为金融平台用户评论分析提供基础支撑;
所述评论主题生成模块主要基于用户印象采集模块采集到的用户印象进行相似聚类后得到一系列类簇,作为评论主题t,主题下的用户印象集合记为m;
所述用户评论分类模块主要负责对用户评论进行依存句法分析,对每条评论提取评论的代表短语集合,利用集合中的短语计算评论与每个主题的相似度,发现评论内容所属主题;
所述评论主题更新模块主要负责定期采集金融论坛上新增用户印象,与已有主题去重后,聚类生成新的评论主题,并将其添加到评论主题生成模块中得到的主题集合中。
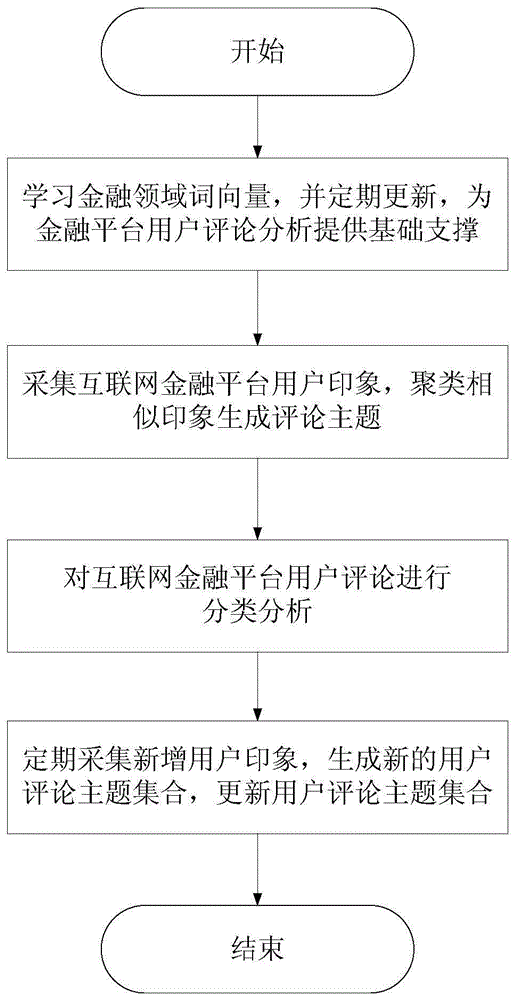
本发明的另一个目的是提供一种互联网金融平台用户评论主题分析方法,包括以下步骤:
s1,使用金融平台评论和金融新闻等数据学习金融领域词向量,并定期更新,为金融平台用户评论分析提供基础支撑;
s2,采集互联网金融平台用户印象,聚类相似印象生成评论主题;
s3,基于步骤s2所得评论主题,对互联网金融平台用户评论进行分类分析;
s4,定期采集金融论坛上新增用户印象,聚类生成新的用户评论主题集合dnew(ti,mi),更新用户评论主题集合d(ti,mi),并对“其它”主题下评论重新分类。
优选地,步骤s1具体包括:
s101,利用网络爬虫采集金融论坛上用户对于金融平台的评论数据、互联网中的金融相关的文本数据;
s102,将s101采集的文本数据进行分词后作为数据集,使用词向量模型学习得到词语在金融领域的分布式词向量集合v;
s103,定期使用词向量模型重新学习更新词向量,已有的词向量集合v可作为初始值和金融数据一起输入到模型中进行学习。
优选地,步骤s2具体包括:
s201,利用网络爬虫采集金融论坛上用户对于平台的用户印象数据;
s202,将s201所述采集到的用户印象进行数据清洗;
s203,将所有用户印象进行相似聚类,得到多个用户印象类簇,作为评论主题;
s204,为s203中得到的评论主题或用户印象类簇选取一个用户印象作为评论主题的代表印象。
优选地,步骤s202中所述数据清洗主要是清除用户印象中包含的无用的字符、表情符以及特殊字符。
优选地,步骤s203中所述聚类的方法包括但不限于层次聚类、k均值聚类和single-pass聚类。
优选地,步骤s3具体包括:
s301,利用自然语言处理工具对采集得到的金融平台的用户评论进行依存句法分析,得到评论文本中词语间的依赖关系类型;选定特定依存关系类型的词语组合作为评论的代表短语,从而得到每条评论di的代表短语集合ci
s302,计算每条用户评论di与所有评论主题tk的相似度
s303,若
优选地,步骤s302中具体包括:
对评论di的代表短语集合ci中的短语
优选地,步骤s4具体包括:
s401,利用网络爬虫,定期采集金融论坛上新增用户印象,记为新增用户印象集合mnew;
s402,对步骤s401采集到的新增用户印象去重,并更新新增用户印象集合mnew;
s403,对mnew进行相似聚类,得到多个用户印象类簇,生成新的评论主题dnew(ti,mi),具体算法步骤按照步骤s203、s204执行;
s404,将新的评论主题dnew(ti,mi)添加到评论主题集合d(ti,mi)中;
s405,基于dnew(ti,mi),重新对“其它”主题下的用户评论进行分类,具体算法过程按照步骤s301、s302、s303执行。
优选地,步骤s4具体包括:采用余弦相似度,计算新增用户印象ml与已有评论主题集合d(ti,mi)中的所有主题ti的相似度sli,若max(sli)大于设定阈值,则删除该用户印象。
本发明的有益效果是:
本发明给出的用户评论主题分析方法不需要进行长期人工干预,借助互联网中易于获取的用户知识(即用户印象)实现稳定的互联网金融平台评论分析及主题提取,分析获得的评论主题较有代表性,从而可以通过分析结果帮助用户更直观了解该互联网金融平台。
附图说明
图1是基于用户印象的互联网金融平台用户评论主题分析方法流程示意图;
图2是根据采集的用户印象生成评论主题的流程示意图;
图3是基于评论主题的金融平台用户评论分类流程示意图;
图4是评论主题更新及未分类评论重新分类流程示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施方式仅仅用以解释本发明,并不用于限定本发明。
实施例1
本实施例提供一种互联网金融平台用户评论主题分析系统,包括数据采集模块、金融词向量学习模块、评论主题生成模块、用户评论分类模块和评论主题更新模块,所述数据采集模块采集金融类新闻报道、用户评论和用户印象,并将其汇总后入库;
所述金融词向量学习模块是基于金融平台评论和金融新闻等数据学习金融领域词向量,并定期更新,为金融平台用户评论分析提供基础支撑;
所述评论主题生成模块主要基于用户印象采集模块采集到的用户印象进行相似聚类后得到一系列类簇,作为评论主题t,主题下的用户印象集合记为m;
所述用户评论分类模块主要负责对用户评论进行依存句法分析,对每条评论提取评论的代表短语集合,利用集合中的短语计算评论与每个主题的相似度,发现评论内容所属主题;
所述评论主题更新模块主要负责定期采集金融论坛上新增用户印象,与已有主题去重后,聚类生成新的评论主题,并将其添加到评论主题生成模块中得到的主题集合中。
实施例2
本实施例提供一种互联网金融平台用户评论主题分析方法,包括以下步骤:
s1,使用金融平台评论和金融新闻等数据学习金融领域词向量,并定期更新,为金融平台用户评论分析提供基础支撑;
s2,采集互联网金融平台用户印象,聚类相似印象生成评论主题;
s3,基于s204所得评论主题,对互联网金融平台用户评论进行分类分析;
s4,定期采集金融论坛上新增用户印象,聚类生成新的用户评论主题集合dnew(ti,mi),更新用户评论主题集合d(ti,mi),并对“其它”主题下评论重新分类。
具体的,步骤s1包括:
s101,利用网络爬虫采集金融论坛上用户对于金融平台的评论数据、互联网中的金融相关的文本数据等;
s102,将s101所述文本进行分词后作为数据集,使用词向量模型(word2vec、glove、hyperwords等)学习得到词语在金融领域的分布式词向量集合v;
s103,定期使用词向量模型重新学习更新词向量,已有的词向量集合v可作为初始值和金融数据一起输入到模型中进行学习。
具体的,步骤s2包括:
s201,利用网络爬虫采集网贷之家、网贷天眼等金融论坛上用户对于平台的用户印象数据;
s202,将s201所述采集到的用户印象进行数据清洗。步骤s202所述数据清洗主要是清除用户印象中包含的无用的字符、表情符以及特殊字符;
s203,将所有用户印象进行相似聚类,得到多个用户印象类簇,作为评论主题,ti表示第i个评论主题,
通常会有大量的相似用户印象,比如“收益比较低”、“收益率低”和“利率低”等,可采用多种常用成熟的聚类方法,如层次聚类、k均值聚类、single-pass聚类等,采用余弦距离计算用户印象两两之间和聚类过程中类簇之间的相似度,用户印象使用其包含的全部词语的词向量的均值进行表示。
s204,为s203中得到的评论主题(用户印象类簇)选取一个用户印象作为评论主题的代表印象。
对采集的所有用户印象进行统计,选取每个主题下出现次数最多的用户印象作为评论主题的代表印象。从而得到d(ti,mi)集合,其中ti为第i个评论主题,mi为第i个评论主题下的用户印象集合。此步的目的是为了使评价主题更为直观易于理解,可辅助人工进行简单筛选;
本实施例中的聚类方法采用层次聚类的方法,步骤如下:
开始:用户印象mi,可i=1,…,n,将每个用户印象mi视为一个的类簇ui,相似度集合s中存放类簇之间的相似度和相似度所关联的类簇标识。
算法步骤:
1.计算每个类簇两两之间的余弦相似度,加入相似度集合s中;
2.若s中相似度的最大值大于设定阈值,那么将其对应的两个类簇合并为一个新的类簇,将与这两个类簇与其他所有类簇之间的相似度从集合s中删除;否则,执行步骤5。
3.计算上一步骤中生成的新类簇与其他类簇之间的相似度,加入集合s中。返回步骤2,停止聚类过程,将聚类得到的类簇作为评论主题输出。
算法中类簇之间的相似度计算分为两种情况:
a,若类簇中只有一个用户印象,那么将两个印象之间的相似度作为类簇之间的相似度;
b,若类簇中有多个用户印象,那么将两个簇中用户印象之间的相似度的均值作为簇之间的相似度。
具体的,步骤s3具体为:
步骤s301,利用自然语言处理工具对从论坛、贴吧等渠道采集得到的金融平台的用户评论进行依存句法分析,得到评论文本中词语间的依赖关系类型。选定几种特定依存关系类型,若两个词语之间存在该依存关系,则将其组合作为评论的一个代表短语c,从而得到每条评论di的代表短语集合ci。可使用多种工具对评论进行依存句法分析,因每种工具对依存关系的定义略有不同,以stanfordcorenlp为例,选取nsubj(名词主语)、advmod(副词修饰)、amod(形容词修饰)、prep(介词修饰)、nn(名词组合形式)、dep(依赖关系)、dobj(直接宾语)等依存关系,使用其他分析工具时根据依存关系的含义进行选取。
步骤s302,计算每条用户评论di与所有评论主题tk的相似度
步骤s303,若
具体的,步骤s4包括:
s401,利用网络爬虫,定期采集金融论坛上新增用户印象,记为新增用户印象集合mnew;
s402,对s401采集到的新增用户印象去重,并更新新增用户印象集合mnew;采用余弦相似度,计算新增用户印象ml与已有评论主题集合d(ti,mi)中的所有主题ti的相似度sli,若max(sli)大于设定阈值,则删除该用户印象;
s403,对mnew进行相似聚类,得到多个用户印象类簇,生成新的评论主题dnew(ti,mi),具体算法步骤按照步骤s203、s204执行;
s404,将新的评论主题dnew(ti,mi)添加到评论主题集合d(ti,mi)中;
s405,基于dnew(ti,mi),重新对“其它”主题下的用户评论进行分类,具体算法过程按照步骤s301、s302、s303执行。
通过采用本发明公开的上述技术方案,得到了如下有益的效果:
本发明给出的用户评论主题分析方法不需要进行长期人工干预,借助互联网中易于获取的用户知识(即用户印象)实现稳定的互联网金融平台评论分析及主题提取,分析获得的评论主题较有代表性,从而可以通过分析结果帮助用户更直观了解该互联网金融平台。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!