基于大数据和深度学习的专利价值智能评估系统的制作方法
本发明涉及价值评估领域,尤其是一种基于大数据和深度学习的专利价值智能评估系统。
背景技术:
专利的价格评估对于专利的转让、质押、融资等具有重要的意义,目前专利价格的评估基本采用专家评估的方式,这种评估方式很大程度上依赖于专家经验,而这种依赖性给专利价格的评估带来了很大的风险。如果专家经验不可靠或者估计错误,将会给专利的转让等其他交易带来很大的成本。而现有技术中缺乏系统的、面向大众的专利价值评价系统。
技术实现要素:
发明目的:为填补现有技术的空白,本发明提出一种基于大数据和深度学习的专利价值智能评估系统,该系统可以在不依赖专家经验的情况下,准确的评估专利的价格。
技术方案:为实现上述目的,本发明提出以下技术方案:
基于大数据和深度学习的专利价值智能评估系统,包括用户端、专利评估端和专利数据库服务器,专利评估端分别与专利数据库服务器和用户端交互,专利评估端从用户端或专利数据库服务器获取初始文本数据;
专利评估端包括文本向量化模块和专利价格评估模块;其中,
文本向量化模块对获取的初始文本数据进行分词处理,提取出的所有词互不相同,然后将每个词转换为词向量,并计算整个初始文本数据的平均词向量;
专利价格评估模块对平均词向量进行编码,将平均词向量中的每一个元素映射为一个唯一的正整数编码,然后设置一个r×t维的文本矩阵,将各元素的编码按照相应元素在平均词向量中的排序逐一填写在文本矩阵中,填写的顺序为从文本矩阵的第一行首位开始逐行填写,若平均词向量的编码数量大于r×t,则将多出部分删除,若平均词向量的编码数量不足r×t,则将文本矩阵中空出的位置补0;
专利价格评估模块将文本矩阵输入预先训练好的专利价格评估模型,输出初始文本数据对应的专利价格,并将得到的专利价格反馈给用户端;
所述专利价格评估模型为深度神经网络模型,该模型的训练步骤为:
a.获取已知专利价格的专利文本,通过文本向量化模型提取专利文本的平均词向量;
b.通过专利价格评估模块将提取出的平均词向量转化为文本矩阵,在进行训练前,为每个文本矩阵添加专利价格标签,然后以文本矩阵及其相应的价格标签作为训练数据输入深度神经网络模型反复训练,直至满足预设的停止条件,此时深度神经网络模型训练完毕。
进一步的,专利评估端获取待评估专利的方式为:
用户通过用户端向专利评估端上传待评估的专利文本;或
用户通过用户端向专利评估端上传待评估的专利文本的检索信息,专利评估端根据检索信息从专利数据库服务器检索到相应专利文本并下载。
进一步的,文本向量化模块通过预先训练好的文本词向量模型将提取出的词转化为词向量,文本词向量模型的训练方法为:
将作为训练样本的每个词表示成one-hot形式,然后选定一个词向量的维度x,将表示为one-hot形式的训练样本输入神经网络中,经过训练输出指定维度的词向量。
进一步的,所述平均词向量的计算方法为:
vaverage=(v1+v2+…+vn)/n
v1至vn为初始文本数据经过分词处理后提取出的词的词向量,n为提取出的词的总数。
有益效果:与现有技术相比,本发明具有以下优势:
本发明提供了一种用于专利价格评估的工具,这是一种面向大众的专利价值智能评估系统,任何人都可以通过用户端访问专利评估端,对自己所持有的或者别人的专利进行价值评估。整个评估过程不依赖于专家经验,评估速度快,且准确度高。
附图说明
图1为本发明的系统结构图;
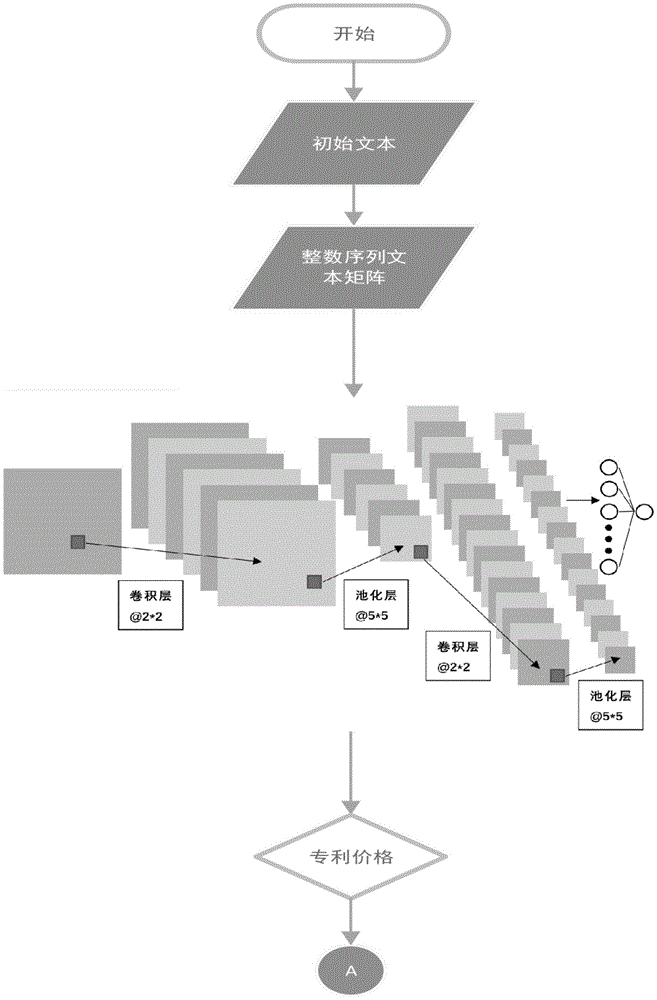
图2为本发明的工作流程图;
图3为cnn卷积神经网络的拓扑图;
图4为resnet的拓扑图;
图5为resnet的残差学习单元拓扑图。
具体实施方式
下面结合附图和具体实施例对本发明作更进一步的说明。
本发明提出了一种基于大数据和深度学习的专利价值智能评估系统,该系统的架构如图1所示,包括:用户端、专利评估端和专利数据库服务器,专利评估端分别与专利数据库服务器和用户端交互,专利评估端从用户端或专利数据库服务器获取初始文本数据。
上述系统的工作流程如图2所示:专利评估端包括文本向量化模块和专利价格评估模块,文本向量化模块对获取的初始文本数据进行分词处理,提取出的所有词互不相同,然后将每个词转换为词向量,并计算整个初始文本数据的平均词向量;专利价格评估模块对平均词向量进行编码,将平均词向量中的每一个元素映射为一个唯一的正整数编码,然后设置一个n×n维的文本矩阵,将编码后的元素按照其在平均词向量中的排序逐一填写在文本矩阵中;专利价格评估模块将文本矩阵输入预先训练好的专利价格评估模型,输出初始文本数据对应的专利价格,并将得到的专利价格反馈给用户端。
上述方案中,专利价格评估模型为深度神经网络模型,该模型的训练步骤为:
a.获取已知专利价格的专利文本,通过文本向量化模型提取专利文本的平均词向量;
b.通过专利价格评估模块将提取出的平均词向量转化为文本矩阵,在进行训练前,为每个文本矩阵添加专利价格标签,然后以文本矩阵及其相应的价格标签作为训练数据输入深度神经网络模型反复训练,直至满足预设的停止条件,此时深度神经网络模型训练完毕。
上述方案中,专利评估端获取待评估专利的方式为:
用户通过用户端向专利评估端上传待评估的专利文本;或
用户通过用户端向专利评估端上传待评估的专利文本的检索信息,专利评估端根据检索信息从专利数据库服务器检索到相应专利文本并下载。
上述方案中,文本向量化模块通过预先训练好的文本词向量模型将提取出的词转化为词向量,文本词向量模型的训练方法为:
将作为训练样本的每个词表示成one-hot形式,然后选定一个词向量的维度x(例如64),将表示为one-hot形式的训练样本输入神经网络中,经过训练输出指定维度的词向量。
下面通过一个具体的实施例对本发明的原理进行进一步阐述。
设文本向量化模块分词处理后提取的词共n个,分别记为w1、w2……wn,则初始文本数据可以表示为:
wo=w1+w2+…+wn
用文本词向量模型将每个词转化为词向量,记得到的n个词向量分别为v1、v2……vn,则有:
f(wo)=∑f(wk)=v1+v2+…+vn
其中,f()表示文本词向量模型的转化函数,wk表示第k个词;
对词向量做向量加法,再把得到的向量的每个维度都除以词的数量,就得到平均词向量:
vaverage=(v1+v2+…+vn)/n
专利价格评估模块对平均词向量进行编码,将平均词向量中的每一个元素映射为一个唯一的正整数编码,设映射函数为g(x),可根据需求设置,g(x)的表达式为:
g(wo)=∑g(wk)=u1+u2+…+un
u1至un分别为平均词向量中的每一个元素的编码。
然后设置一个r×t维(例100*100)的文本矩阵,将各元素的编码按照相应元素在平均词向量中的排序逐一填写在文本矩阵中,填写的顺序为从文本矩阵的第一行首位开始逐行填写,若平均词向量的编码数量大于r×t,则将多出部分删除,若平均词向量的编码数量不足r×t,则将文本矩阵中空出的位置补0;填好的文本矩阵m为:
专利价格评估模块将文本矩阵输入预先训练好的专利价格评估模型,输出初始文本数据对应的专利价格,并将得到的专利价格反馈给用户端;
将平均词向量和价格区间作为特征和标签放入一个深度神经网络进行训练,得到多个回归模型,深度神经网络如图2所示,得到的回归模型为:
v=conv2(w,m,valid)+b
price=φ(v)
其中,conv2表示卷积公式,其卷积的展开式为:
其中,w表示输入,k表示卷积核,m*n为卷积核的大小。
具体的卷积过程如下:类比为图像,我们的文本矩阵是单通道的,假定我们的卷积核是一个4维张量k,它的每一个元素是ki,j,k,l,表示输出中处于通道i的一个单元和输入中处于通道j中的一个单元的连接强度,并且在输出单元和输入单元之间有k行l列的偏置。假定输入由观测数据w组成,它的每一个元素是wi,j,k,表示处于通道i中第j行第k列的值。假定我们的输出z和输入w具有相同的形式,如果输出z是通过对k和w进行卷积而不设计翻转k得到的,那么,有:
这里对所有的l,m和n进行求和是对所有(在求和式中)有效的张量索引的值进行求和。
深度神经网络训练的过程如下:
假设我们想要训练这样一个卷积网络,它包含步幅为s的步幅卷积,该卷积的核为k,作用于单通道的矩阵w,定义为c(k,w,s),如上式。假设我们想要最小化某个损失函数j(w,k)。在前向传播过程中,我们需要用c本身来输出z,然后z传递到网络的其余部分并且被用来计算损失函数j。在反向传播过程中,我们会得到一个张量g,g满足:
为了训练网络,我们需要对核中的权重求导,为了实现这个目的,我们在本实施例中使用一个函数:
如果这一层不是网络的底层,我们需要对w求梯度来使得误差进一步反向传播,我们可以使用如下的函数:
深度神经网络训练结束后,即可用来评价新的专利文本,通过文本向量化模型提取新的专利文本的平均词向量;然后通过专利价格评估模块将提取出的平均词向量转化为文本矩阵,将文本矩阵输入深度神经网络,即可得到专利价格评估结果。
在上述实施例中,深度神经网络采用cnn卷积神经网络,cnn卷积神经网络拓扑图如图3所示,本实施例中采用的cnn卷积神经网络包括但不限于lenet-5、resnet,resnet的结构如图4所示,其中的残差学习单元如图5所示,
残差学习单元执行的计算过程为:
xl+1=relu(yl)
其中,xl和xl+1分别表示第l个残差单元的输入和输出,每个残差单元包含多层结构,f是残差函数,表示学习到的残差,
利用链式规则,可以求得反向过程的梯度:
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!