一种深度卷积神经网络硬件加速器中的可伸缩的并行数据载入装置及其设计方法与流程
本发明属于计算机硬件、人工神经网络算法部署硬件加速的领域,数字集成电路设计领域,具体涉及一种深度卷积神经网络硬件加速芯片的输入数据的关键处理装置,及其设计方法。
背景技术:
深度卷积神经网络算法由多层具体的神经元算法层、隐藏层组成,主要包含有卷积层,主要算子为矩阵或向量的卷积计算。该计算任务的主要特点为输入的数据量大、输入数据具有空间特征信息的耦合,且每次卷积计算的数据往往与已经计算过的数据发生重叠,输入数据往往为从张量格式的数据中以一定空间规律抽取所需要的计算数据。卷积层计算所需算力巨大,所需要的数据更大,存储瓶颈成为了主要的制约因素。
近年来在嵌入式端侧部署人工神经算法已经成为广泛需求,但在相关场景下,加速芯片的性能、成本因素成为制约需求的主要因素。专利文件1(公开号cn105488565a)公开了一种加速深度神经网络算法的加速芯片的运算装置及方法,为克服大量的中间值被生成并需要存储,从而所需主存空间增加的问题,其运算装置中均设置有中间值存储区域,这些区域被配置为随机存储器,运算模块通过一index访问该区域。该装置设计能够减少对主存储器的中间值读取和写入次数,降低加速器芯片的能量消耗,避免数据处理过程中的数据缺失和替换问题。专利文件2(申请公布号cn107341544a)公开了一种基于可分割阵列的可重构加速器及其实现方法,设计了便笺式存储器缓存区,用于实现数据重用。专利文件3(公开号usb0170103316a1)公开了一种卷积神经网络加速器的方法、系统及装置,在其中设计了unifiedbuffer。专利文件4(公开号us20180341495a1)公开了一种卷积神经网络加速器及方法,其中采用cache装置来提供并行加速所需数据。这些发明都非常优秀,已开展在服务器、数据中心以及高端智能手机上的应用,但在嵌入式端侧的应用还有问题。
在嵌入式端侧部署人工神经算法,其需求特征为,由于加速芯片的硬件资源有限,必需要将数据进行分割处理,并尽量减少数据的膨胀;而对于不同领域和产业场景所常用的人工神经网络算法不同,这种处理应为一套简单、便于实现的方法,否则仍难以“落地”。在专利文件1和3所述发明中,由于不同神经网络算法层尺寸不一、数据重用度不同而导致加速器资源的浪费,以至于需要配合其他异构处理器来帮助解决数据相关的问题;专利3所述的存储方式需要备份更多数据,导致buffer尺寸太大;专利2的方法采用可重构计算思想,虽然极为注重节省资源浪费,但其数据分割和排布方法很复杂;专利4的发明与中央处理器的设计过于耦合,同时设计实现复杂度过高。
技术实现要素:
本发明提供一种专用于深度卷积神经网络硬件并行加速器中的,可伸缩的并行数据载入装置及其方法,以降低硬件电路设计的复杂度、降低芯片的面积和功耗,同时还能提供高吞吐率、高性能的并行数据带宽,提高芯片的计算资源与内存带宽利用率,降低应用的复杂度与成本。
为实现上述目的,本发明实施例提供了一种可伸缩的并行数据载入装置,该并行载入装置包括:
并行输入寄存阵列,向并行加速计算单元阵列进行高带宽的数据输入;
并行输入数据访问引擎,对上述并行输入寄存阵列中的数据进行并行访问并连接并行寄存阵列的输出以及并行加速计算单元的输入。
本发明的并行数据载入装置,其中,所述并行输入寄存阵列用于缓存输入缓存中存储的关于深度卷积神经网络算法层之前一隐含层所输出的特征图,该并行输入寄存阵列提供数据重排布的快速寄存区域,简化了输入数据排布的难度;该并行输入寄存阵列可以被反复访问,当其中的数据已经作废时,可重新从输入缓存中快速写入新的数据。
本发明的并行数据载入装置,其中,所述并行输入数据访问引擎对于并行输入寄存阵列中的数据进行区域化的并行访问,而不是串行的、全地址空间的随机访问;对于并行输入寄存阵列中的区域数据进行编址,在区域内能够以一定规律反复访问,利用卷积神经网络算法层输入特征图的区域数据耦合性,提高输入数据的使用次数,降低了输入缓存需要输入的次数与数据带宽;将并行输入寄存阵列区域中的数据固定、并行的输入硬件并行加速计算单元阵列,为其提供快速大吞吐率的输入数据。
本发明实施例还提供一种可伸缩的并行数据载入装置的设计方法,包括以下方法和原则:
所述并行输入寄存阵列的尺寸设计与并行计算单元阵列的例化尺寸相关,满足特定的设计公式
所述并行输入数据访问引擎的电路设计,对并行输入寄存阵列中的区域进行编址访问,而不是全部阵列地址空间的访问;对硬件并行加速计算单元阵列为对应固定访问。
本发明的效果在于:
1、简化了硬件并行计算单元阵列与输入装置之间的连接复杂度
2、简化了输出装置与主存储之间排布数据的空间复杂度
3、简化了软件排布数据、划分数据宏块的地址计算复杂度
4、提高了硬件并行计算单元阵列的实际应用效率
5、更适合在低成本嵌入式asic芯片上实现
附图说明
图1为本发明可伸缩的并行数据载入装置结构图;
图2为本发明可伸缩的并行数据载入装置与并行运算加速执行单元阵列的对应图;
图3为当卷积跳步为2时,并行数据载入装置与并行硬件计算单元阵列的工作对应关系;
图4为本发明并行输入数据访问引擎的数据流与结构示意。
附图标记说明
1并行硬件计算单元阵列(processelementsarray,pea)
101卷积计算单元(processelement,pe)
202并行输入寄存阵列(inputregisterarray,ira)
203并行输入数据访问引擎(iradataaccessengine,ide)
具体实施方式
下面通过附图和实施例,对本发明做进一步的详细描述。
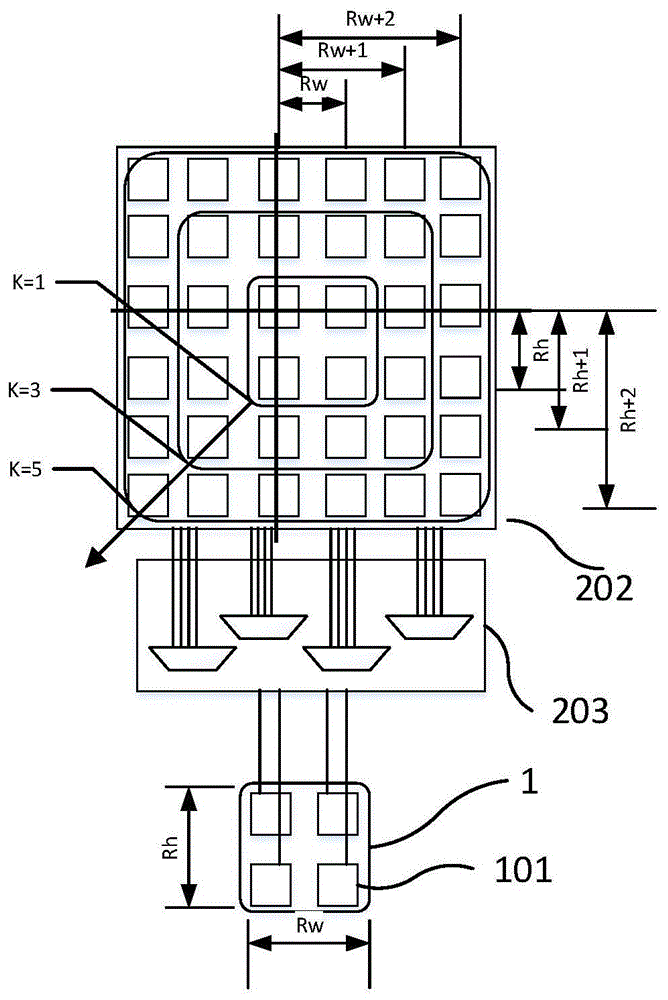
图1为本发明一种深度卷积神经网络硬件加速器中的可伸缩的并行数据载入装置的结构图,该装置包括并行输入寄存阵列(ira)202与并行输入数据访问引擎(ide)203。图中还说明了本发明装置与并行硬件计算单元阵列(pea)1的一种简化连接设计。装置1由若干并行硬件计算单元(pe)101组成,pe与ide的输出之间有一一对应的固定连接,大大化简了电路复杂度与面积、功耗。
并行输入寄存阵列(ira)202由特定数目的寄存器构成,用于提供数据重排布的快速寄存区域,简化了输入数据排布的难度;该并行输入寄存阵列可以被反复访问,当其中的数据已经作废时,可重新从输入缓存中快速写入新的数据。
一实施例中,将pea定为矩形2维阵列结构,pe在其上的例化尺寸分别为宽rw高rh,可并行加速执行尺寸为kw*kh的卷积核,并考虑卷积计算的跳步s,ira也视为2维阵列结构,对应装填输入特征图数据的局部(定义为tile),输入寄存器在其上的例化尺寸分别为宽tw高th,ira可供pea进行卷积的次数为b。本发明对并行输入寄存阵列(ira)202的寄存器例化数目的设计方法为:
依据特定领域的目标算法和常用网络的计算需求,结合行业应用的实时需求,以及并行加速器装置的理论算力区间,估求pea的总体例化尺寸p,p=rw*rh,再根据人工神经网络模型的算法特点,折中选择rw和rh;
依据pe的设计架构可知其最大输出的算力与效能,再结合芯片设计的取舍,选择ira每次更新数据后可供pea完成卷积的次数b=bw*bh
当s=1时,pea需要的输入数据量最大,为n=(bw*rw-1+kw)*(bh*rh-1+kh),就得到了本发明装置中ira总体例化寄存器数目,最后根据人工神经网络模型的算法特点,折中选择tw和th;
对于s>1的情况,本发明提供的设计原则为通过降低b或配合其他数据驻留的方法来处理,在一实施例中,bw和bh都缩小s倍,于是对于该所述情况下,在水平和垂直方向上的跳步分别为sw、sh,则b=(bw/sw)*(bh/sh),对ira总体例化寄存器数目n及tw和th的选择不构成关键的影响。
本发明在上述实施例中提供了一种并行输入寄存阵列(ira)202的设计方法:tw=(bw*rw-1+kw),th=(bh*rh-1+kh),根据这一方法,卷积核k的变化对ira尺寸的影响被化简,ira具有可伸缩性,满足不同的k卷积。
在上述实施例中,假设所设计的2维阵列均为正方形,卷积核也为正方形,并且假设p=4,r=2,k=[1,3,5,7],s=[1,2],b=4,那么根据本发明所述并行输入寄存阵列(ira)202的设计方法,得到t=10。
图1还说明了当s=1时,k=[1,3,5]对ira的影响规律可化简为一层层的增大其例化的寄存器数目。
图2为本发明可伸缩的并行数据载入装置与并行运算加速执行单元阵列的对应图。在上述实施例中,对pe编号为p0、p1、p2、p3,每个pe计算4次卷积,每次卷积所对应的输入数据的中心点被标注在ira阵列202中,用最后一个数字标记,例如p0号pe所计算的4次卷积的中心点分别为p00、p01、p02、p03。中间的方框表示pea进行k=1的b次卷积时所需要的输入数据,而对于其他k取值,所需要的输入数据在一圈圈的向外伸展,说明了当s=1,k=[1,3,5,7]对ira的影响规律,无论ira尺寸如何变化,pea的尺寸不变也可以支持上述不同的卷积核计算。图3说明了当s=2时,k=[1,3,5,7]对ira的影响规律不变,只是每次装填ira所能提供pea执行卷积的次数缩小为b=1。
图4为本发明并行输入数据访问引擎的数据流与结构示意。输入特征图inputmap在图4左侧,根据硬件并行输入装置中ira的尺寸,在图中分割出tile块,被串行逐次的装载进输入寄存器阵列(ira)202中,位于图4右上侧方框所示,其下测中间装置为本发明中的并行输入数据访问引擎(ide)203结构。ide装置203包括地址译码器及多路选择器2031,地址转换器2033。ide对ira分区域的地址编码方法如2032所示。
本发明在上述实施例中提供了一种并行输入数据访问引擎(ide)的设计方法,即对应每个pe的多路选择器2031所访问的ira区域的设计原则与编址方法:以二维方式排列ira区域内的地址,以统一简化区域地址范围的表达和计算规律;第p个pe在ira中对应需要访问的二维坐标(x,y)范围可表示为x∈[(p%r)*2,(p%r)*2+k],
以上述实施例说明ide对ira分区域的地址编码方法,其步骤如下:
根据每个pe最大处理的卷积核k=7,每次装填tile所处理的最大卷积次数b=4,得到一共pe需要访问的数据为8*8=64个,因此,每个pe最大需要访问的数据为2维格式的8*8区域;
该区域在ira中的范围是固定并遵循一定规律的,并且直接对应inputmap中的2维数据格式,图4中以圆角虚线框圈出了p0需要访问的ira区域;
每个pe只需要访问对应的ira区域,而不需要对ira整体全部随机访问;
在对2维格式的8*8区域编址时,采取扫描线顺序进行一维编码。
如图4所示,p0进行首次k=7卷积时,卷积区域的中心点位于r33处,依据本发明所包含的上述规律,则其他三次分别位于r34、r43、r44,虚线框就是p0所需要访问的所有区域,共64个输入数据。虚线箭头表示该区域内64数据连接到64选1的多路选择器2031。根据上述区域编址方法2032,地址转换器2033顺序连续输出地址,经多路选择器2031译码选择其中一个数据,再输出给p0,直到p0完成所有4次卷积。
如图4所示,当p0在进行所对应区域内的计算加速时,其他pe也在并行、同步的进行阵列计算加速。每个pe所对应的ira区域中心点用十字标出。所有pe所访问各自区域的地址、顺序一样,这化简了控制电路的复杂度。
如图4中虚线箭头所示,ide装置203中的地址译码器及多路选择器2031以及地址转换器2033与pea的结构和实现有对应的规律,不受到卷积操作的其他参数影响。
本发明可通过伸缩所述的并行输入寄存阵列(ira)202及配合伸缩并行输入数据访问引擎(ide)203的硬件设计参数,就可以实现数据吞吐性能的成倍提升。
本发明可以在由中央控制器执行的一般或/和扩展指令的一般上下文中描述,例如软件程序。软件程序一般包括执行特定任务或实现特定数据类型的例程、对象、组件、数据结构及参考模型等等。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!