一种基于行为时间序列大数据的用户对象识别方法及系统与流程
本发明涉及行为计算机领域中的识别技术领域,尤其涉及一种基于行为时间序列大数据的用户对象识别方法及系统。
背景技术:
随着互联网通信技术的发展以及社会形态的不断变化,“互联网+”成果和思维已日渐深入人们的日常生活,越来越多的传统生活习惯已转变为网络虚拟行为,并以各种行为数据的形式被各互联网运营商采集存储,如网络购物行为、网页浏览行为、音视频播放行为等。其次,伴随着数据挖掘和机器学习技术的兴起,基于网络用户大数据的身份识别技术也应运而生,如各大电商基于用户画像的用户性别、职业、购物偏好等身份类型识别技术。
在现有技术中,基于web等非图像数据的身份识别技术大都限于用户身份类型的识别,这也导致了大量的用户非图像行为数据无法用于用户身份的确切识别。因此,在各种数据分析和机器学习技术成熟的条件下,对用户的行为数据进行深度挖掘实现对用户身份的定点识别可以极大地拓展当前身份识别几乎仅限于图像数据的情况。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于行为时间序列大数据的用户对象识别方法。本发明能够利用用户身份信息中被隐藏或污染的数据实现精确的身份识别。
本发明的目的能够通过以下技术方案实现:
一种基于行为时间序列大数据的用户对象识别方法,包括步骤:
获取历史数据及待识别数据,并根据清洗规则对历史数据及待识别数据进行清洗;
根据清洗后的数据生成结构统一的记录;
根据数据特征类型选取特征,构造特征集;
根据特征集构造特征向量或特征向量组;
根据历史数据的特征向量或特征向量组分别生成相似判别矩阵或机器学习判别模型;
根据相似判别矩阵或机器学习判别模型对待识别数据生成的特征向量进行用户识别,获得识别结果。
具体地,历史数据来源为静态数据库,用于生成判别模型;待识别数据为新生成数据,来源可以为静态数据库和动态数据流,作为目标数据。
所述数据清洗规则包括用户过滤、字段过滤和时间过滤。用户过滤表示根据数据量和数据来源过滤掉无效用户;字段过滤表示去除行为无关的数据属性;时间过滤表示筛选指定时间区间数据,并保证数据的时序性,去除时序错乱的数据。
具体地,所述根据清洗后的数据生成结构统一的记录的步骤中,包括:
将数据的行为字段进行数值化,对每条数据添加时间戳(timestamp)以及用户标签(userid);数值化表示将行为类型映射为指定范围内的整数值;时间戳表示记录采集到的时间距某指定日期的秒数,为整数值;用户标签表示对用户的编号,为整数值。得到的每条数据生成的统一记录表示为:
record=<userid,timestamp,operation1,operation2,…,operationn>
其中,operation表示用户记录的操作行为。
具体地,所述数据特征类型分为行为特征和行为的时序序列特征。第i个特征记做fi。
行为特征表示行为的具体类型本身作为一种特征,第i个行为特征记做gi,gi=type(operationa),表示operationa的某种具体行为作为特征。
行为的时序序列特征表示在不同行为类型间的切换作为一种特征,第i个行为的时序序列特征记做hi,hi=(type(operationa)→type(operationb)),表示某两种operationa和operationb的具体类型之间的切换行为。
具体地,所述选取的特征是根据特征在数据区间内的频率热度和tf-idf热度。
特征的频率热度是在某时间区间内指定特征出现次数的归一化值,特征fi的频率热度计算公式为
其中,
特征的tf-idf热度表示将指定特征在数据区间内的tf-idf值作为热度,特征fi的tf-idf热度计算方式为
其中,
对每个用户的所有特征f计算热度,并选取热度最高的top-k作为该用户的特征集,第i个用户的特征集表示为featureui={fi,1,fi,2,…,fi,k}。
合并u个用户的特征构成尺度一致的特征集:
feature=featureu1∪featureu2∪…∪featureuu
所有用户特征共count(features)=m个特征元素,即feature={f1,f2,…,fm}。
具体地,根据特征集feature构造用户特征向量或特征向量组,包括:
将提取的m个整体特征作为分量组成用户特征向量,每个分量值为对应特征之于用户u的热度值,即
uservector=<phu,1,phu,2,…,phu,m>
其中,ph表示热度值。
当数据量足够时,对每个用户的数据按照时间区段划分为多段,分别对每段生成一个特征向量,所有特征向量组成一个特征向量组。
具体地,所述根据历史数据的特征向量或特征向量组分别生成相似判别矩阵或机器学习判别模型的步骤中,
如果生成的为特征向量,所有用户的特征向量可组成u*m的判别矩阵:
simmatrix=<uservector1;uservector2;…;uservectoru>
如果生成的为特征向量组,使用特征向量的每个特征分量作为属性输入,对应的用户编号userid作为标签进行机器学习训练得到机器学习判别模型п。机器学习方法可选择knn、决策树、随机森林、
具体地,所述根据相似判别矩阵或机器学习判别模型对待识别数据生成的特征向量进行用户识别,获得识别结果的步骤中,
如果使用相似判别矩阵,使用待识别特征向量identifyvector和相似判别矩阵simmatrix中的每个特征向量进行相似性度量,选择特征最相似的前top-n个用户作为候选识别结果。所述相似性测度采用欧式距离、余弦相似性或皮尔逊相关性系数。
如果使用机器学习判别模型п,使用待识别特征向量identifyvector的每个特征分量作为机器学习判别模型п的属性输入,模型п计算输出(命中概率)的前top-n个值所对应的用户编号作为候选识别结果。
本发明的另一目的在于提供一种基于行为时间序列大数据的用户对象识别系统。
本发明的另一目的能够通过以下技术方案实现:
一种基于行为时间序列大数据的用户对象识别系统,包括数据采集模块、特征构造模块、模型生成模块和用户识别模块;
所述数据采集模块包括从数据源获取用户数据,并根据特定过渡规则对数据进行清洗,保留有意义数据,形成按时间内戳增序排列的用户行为记录;
所述特征构造模块,根据采集的数据计算用户行为的分布特征,并构造尺度一致的特征向量,其中特征向量的每个特征元素值为对应特征行为的热度;
所述模型生成模块,根据用户历史特征行为数据构造特征矩阵,或根据用户历史特征行为数据训练得到机器学习判别模型;
所述用户识别模块,由待识别数据驱动所述用户历史行为数据特征矩阵进行相似性度量获得识别结果,或者由待识别数据驱动机器学习判别模型获得识别结果。
用户对象识别系统工作步骤具体为:
数据采集模块从历史数据源获取用户历史数据,并根据特定规则对数据进行清洗,仅保留有意义数据,同时生成具有统一数据结构的;
特征构造模块对生成的数据按照行为或行为时序序列进行热度计算,选取热度最高的行为或行为序列作为特征集合,并根据特征集合对每个用户构造特征向量;
模型生成模块根据用户特征向量生成用户相似判别矩阵或者根据特征向量组训练得到机器学习判别模块п;
数据采集模块从待识别数据源获取待识别数据,并根据特征构造模块提取的特征集合生成待识别特征向量;用户识别模块对待识别特征向量使用对应的判别模块进行用户识别,并选取top-n作为识别结果。
本发明相较于现有技术,具有以下的有益效果:
本发明可以根据用户数据量灵活地选择相似判别矩阵或机器学习判别模型,并且在用户识别过程中引入了用户行为的时序特征,能够有效地提高用户识别的正确率。
附图说明
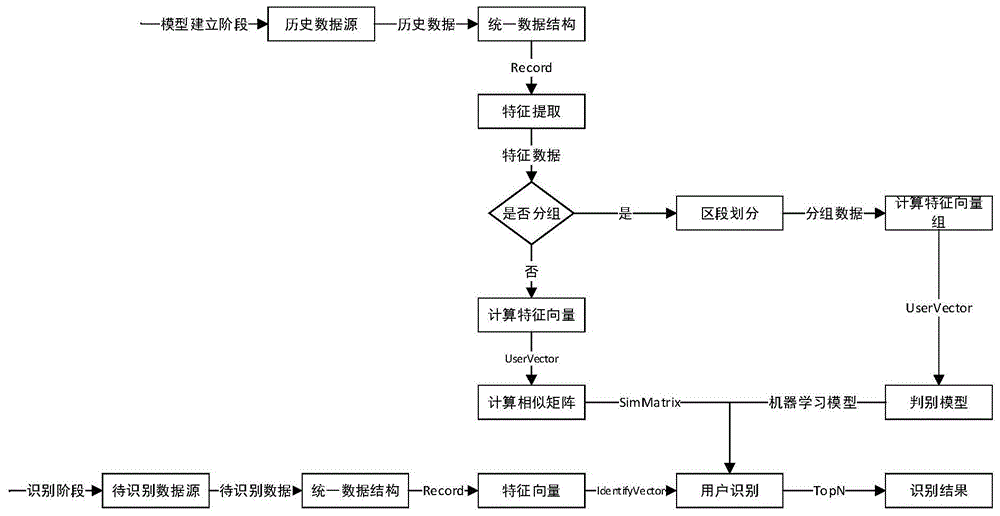
图1是一种基于行为时间序列大数据的用户对象识别方法的流程图。
图2是本发明实施例中根据特征类型选取特征,构造特征集的流程图。
图3是本发明实施例中基于相似性判别矩阵识别的流程图。
图4是本发明实施例中基于机器学习模型识别的流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例
如图1所示为一种基于行为时间序列大数据的用户对象识别方法的流程图,包括步骤:
s1、获取历史数据及待识别数据,并根据清洗规则对历史数据及待识别数据进行清洗;
在本实施例中所述数据采集模块中,历史数据和待识别数据使用某用户音乐播放记录数据集,均从静态数据库中获取。
从静态数据库中获取用户历史数据集,源数据每条记录为source=<date,time,user,cursong,artist,stag,rtag,nextsong>,其中date,time,user分别表示记录的日期、时间和对应用户,cursong,nextsong表示用户正在听的音乐和下一次听的音乐,artist,stag表示音乐的歌手及类型,rtag表示用户对音乐的收藏、分享、评论、点赞操作。其中cursong,stag,rtag,nextsong包含行为信息。
s2、根据清洗后的数据生成结构统一的记录;
按照规则对数据进行格式化,保留cursong,stag,rtag,nextsong的行为信息并分别映射为数值类型,记为operation1,operation2,operation3,operation4,同时添加时间戳,对用户进行编号,得到规则化数据,每条记录为data=<userid,operation1,operation2,operation3,operation4,timestamp>。
s3、根据数据特征类型选取特征,构造特征集,具体流程如图2所示;
在本实施例中,所述行为分析模块在特征提取时使用用户行为直接作为特征,使用特征频率热度作为选择标准。
选择每个用户的所有operation1,operation2,operation3,operation4包含的所有类型作为特征,记为f,计算每个类型对该用户的频率热度,计算方法为
对每个用户的所有f类型按照热度选取top-k,第i个用户的特征表示为featureui={fi,1,fi,2,…,fi,k},合并u个用户的特征构成尺度一致的特征集:feature=featureu1∪featureu2∪…∪featureuu,所有用户特征共count(features)=m个特征元素,即feature={f1,f2,…,fm}。
s4、根据特征集构造特征向量或特征向量组;
在本实施例中,对每个用户计算m个特征的频率热度值并组成该用户的特征向量,得到
uservector=<phu,1,phu,2,…,phu,m>
s5、根据历史数据的特征向量或特征向量组分别生成相似判别矩阵或机器学习判别模型;
所有用户的uservector组成u*m的相似性判别矩阵为:
simmatrix=<uservector1;uservector2;…;uservectoru>
s6、根据相似判别矩阵或机器学习判别模型对待识别数据生成的特征向量进行用户识别,获得识别结果。
基于相似判别矩阵以及机器学习模型的识别方法的流程图分别如图3和图4所示。在本实施例中进行相似性识别时测度方法采用余弦相似性测度。根据获得的待识别特征向量identifyvector,计算identifyvector和simmatrix中的每个特征向量uservector的余弦相似性距离,计算方法为
一种基于行为时间序列大数据的用户对象识别系统,包括数据采集模块、特征构造模块、模型生成模块和用户识别模块;
所述数据采集模块包括从数据源获取用户数据,并根据特定过渡规则对数据进行清洗,保留有意义数据,形成按时间内戳增序排列的用户行为记录;
所述特征构造模块,根据采集的数据计算用户行为的分布特征,并构造尺度一致的特征向量,其中特征向量的每个特征元素值为对应特征行为的热度;
所述模型生成模块,根据用户历史特征行为数据构造特征矩阵,或根据用户历史特征行为数据训练得到机器学习判别模型;
所述用户识别模块,由待识别数据驱动所述用户历史行为数据特征矩阵进行相似性度量获得识别结果,或者由待识别数据驱动机器学习判别模型获得识别结果。
本实施例的数据采集模块中,历史数据和待识别数据使用某用户音乐播放记录数据集,均从静态数据库中获取;
所述行为分析模块在特征提取时使用用户时序行为序列作为特征,使用特征的tf-idf热度作为选择标准;
所述用户分析模块进行数据区段划分并计算用户的特征向量组。
所述模型生成模块建立机器学习模型;
所述用户识别模块使用建立完成的decisiontree进行用户识别。
在本实施例中,所述系统的具体工作流程如下:
从静态数据库中获取用户历史数据集,源数据每条记录为source=<date,time,user,cursong,artist,stag,rtag,nextsong>,其中date,time,user分别表示记录的日期、时间和对应用户,cursong,nextsong表示用户正在听的音乐和下一次听的音乐,artist,stag表示音乐的歌手及类型,rtag表示用户对音乐的收藏、分享、评论、点赞操作。其中cursong,stag,rtag,nextsong包含行为信息。
按照规则对数据进行格式化,保留cursong,stag,rtag,nextsong的行为信息并分别映射为数值类型,记为operation1,operation2,operation3,operation4,同时添加时间戳,对用户进行编号,得到规则化数据,每条记录为data=<userid,operation1,operation2,operation3,operation4,timestamp>。
选择每个用户的所有operation1类型和operation4类型之间的<operation1,operation4>切换对作为特征,记为f,计算每个f对该用户的tf-idf热度,计算方式为
对每个用户的f按照热度选取top-k,第i个用户的特征集表示为featureui={fi,1,fi,2,…,fi,k},合并u个用户的特征构成尺度一致的特征集:feature=featureu1∪featureu2∪…∪featureuu,所有用户特征共count(features)=m个特征元素,即feature={f1,f2,…,fm}。
对每个用户的数据按照时间区段进行划分,每个用户的数据划分为p段。
对每个用户的每个区段计算m个特征的频率热度值并组成该用户的特征向量,uservectorp=<phu,1,phu,2,…,phu,m>表示该用户第p个区段的特征向量。
将所有用户的每个特征向量作为属性输入,用户编号userid作为标签进行decisiontree训练,并选择合适的训练参数。训练完成后得到decisiontree判别模型。
根据获得的待识别特征向量identifyvector,将identifyvector作为decisiontree的属性输入,计算输出(命中概率)的前top-n个值所对应的用户编号userid作为候选识别结果。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!