一种基于数据治理及血缘关系设计的数据仓库系统的制作方法
本发明涉及计算机互联网数据仓库设计技术,尤其涉及一种基于数据治理及血缘关系设计的数据仓库系统。
背景技术:
数据治理是校验生产业务系统的数据规则以及业务系统和数仓系统的数据一致性;血缘关系是自下而上,全链路展示企业数据仓库系统的数据血缘管理,便于快速对数据进行影响分析。
传统标准化的数据仓库,仅仅是对企业的数据资产进行了沉淀,没有对数据进行系统范畴方面的管理,出现问题后,解决时效差,而且修改的不全面,一个问题可能周边影响的业务比较多。
随着企业业务的发展日新月异,数据资产的积累尤为重要,数据的沉淀、数据治理及数据血缘三者缺一不可。
技术实现要素:
本发明要解决的技术问题是建立一套成熟的企业数据仓库系统,成熟的数据资产体系,可以快速有效的对外提供精准的数据服务。为了解决上述技术问题,本发明提供了一种基于数据治理及血缘关系设计的数据仓库系统,包括数仓管理模块、血缘关系管理模块、元数据管理模块、数据质量管理模块和作业调度管理平台;
其中,在企业数据大量存在的前提下,所述数仓管理模块通过etl(etl:即extract-transform-load,将源数据通过抽取(extract)、转换(transform)、加载(load)的方式至目标的过程)工具采集业务系统(业务系统:即企业数据的源系统)数据、根据传统bi分层设计(业务系统数据沉淀层、主题域分层和标签画像层)、借助报表工具(罗盘、敏捷bi)等,为企业提供数据服务和决策支持。
所述血缘关系管理模块将企业数据资产到数仓管理模块的血缘链路关系可视化,并对数仓管理模块的血缘关系进行管理;
所述元数据管理模块定时收集业务系统和数仓管理模块的元数据信息,业务系统是汇通达把自己的产品推向市场并取得最大化收益的一个企业分系统。以模块划分,业务系统包括营销规划、销售平台、销售进程管理、客户服务管理、客户关系管理、风险防范。数仓管理模块本身并不生产任何数据,数据来源于业务系统,并且开放给外部应用,可以分为三层:业务系统、数据管理模块、数据应用。
元数据管理模块通过自动或者手动两种采集方式定时收集业务系统和数仓管理模块的元数据信息,统一存储到metacube(metacube管理平台是一款基于web方式的元数据管理工具)知识库并集中管理,为上层元数据应用提供数据服务,便于用户浏览及分析元数据;帮助用户了解和管理信息和加工处理过程的来源,也有助于用户理解信息与加工过程之间的关系以及它们如何被使用;
所述数据质量管理模块协同作业调度管理平台,通过配置作业、作业流的方式,按照既定的数据质量管理规则,定时核对业务系统与数仓管理模块的数据,业务数据包括了交易平台、产品平台、帐户平台、用户管理、风控平台、运营、线下管理等场景数据,每个场景的数据都存在着众多复杂的业务逻辑。确保数据的准确性。
所述数仓管理模块包括业务系统数据沉淀层、主题域分层和标签画像层;
所述业务系统数据沉淀层借助etl工具,采用全量数据采集、增量数据采集及特殊业务场景(外部文件、手工填报数据等)定制化数据采集方式采集数据;
所述主题域分层在数仓管理模块已有业务系统数据沉淀层的前提,根据公司业务进行主题域划分,借助etl工具、存储过程、物化视图等分类数据,提高数仓管理模块的分类管理水平,便于开发、管理人员进行有效的查询分析。按照实际用途整合多个业务系统的数据形成比较完整的数据指标库;
所述标签画像层包括高度主题汇总层、数据服务层和敏捷bi(敏捷bi:永洪可视化产品工具)数据集市层,在数仓管理模块已有主题域分层的前提,通过etl工具、存储过程、物化视图等开发汇总数据,借助帆软、敏捷bi等外部工具实现数据可视化,提供数据支持服务。
针对数据量小于百万级的业务系统数据采用全量数据采集方式;针对数据量超过百万级且有更新时间戳的业务系统数据采用增量数据采集方式;针对数据量超百万级但无更新时间戳的业务系统数据采用倒退历史时间增量数据采集方式;
所述血缘关系管理模块用于数据源采集、etl作业采集、存储过程采集和报表血缘关系采集;
所述数据源采集包括数据源配置和采集任务调度配置;
所述etl作业采集包括采集etl数据源配置和执行采集作业;
所述存储过程采集包括采集数据源配置和执行采集作业;
所述报表血缘关系采集包括采集报表数据源配置和执行采集作业。
所述元数据管理模块用于生成元数据采集报告和元数据版本报告,并管理元数据生命周期。
所述数据质量管理模块按照制定的一致性数据对比规则,对比统计周期内的业务系统和数据仓库管理模块的数据一致性,数据一致性包括数据量级、指标数据一致性,质量管理的统计时间频率能够配置到分钟级、小时级、天级。
所述一致性数据对比规则如下:
记录数检核:记录数检核是指各个数据区域相关数据之间的数据总数检核或者数据表中每日数据量的变动检核。
业务约束检核:具体业务约束检核要在项目实施过程中与业务人员共同确定,业务人员提出检核规则,从业务的角度考虑数据的合理性。如:某账目表,建档日期、借贷款日期、还款日期、销账日期等时间的有效性检核。
空值检核:空值检核通过检核一个数据集的特定属性是否为空来衡量数据准确性。
非法值检核:非法值检核通过检查数据的取值是否在一个范围内来衡量其准确性,比如,不同业务系统之间同步数据,小数位保留2-3位四舍五入带来的偏差是允许的。
码值检核:码值检核通过检查字段值在码表中是否真实存在来衡量数据准确性。
主键重复检核:主键重复检核通过对某一张表中的一个或者两个以上联合字段进行检查,通过判断其是否唯一存在来衡量数据准确性。
所述作业调度管理模块包括作业、作业流配置、计划配置、作业重刷机制配置和作业监控管理;作业能够并行调度,也能够串行调度,串行需要配置成作业流,作业流代表了作业执行调度的先后依赖关系,作业流允许失败重刷机制,能够从断点或者重头开始执行作业流调度。
di作业开发:使用普元di工具(kettle)开发转换作业,通过拖拽组件的方式把企业数据从源系统加载到数仓管理模块。
作业配置:普元调度管理系统配置di作业,包括作业名、作业类型、代理服务器、作业服务器、作业部署等。
作业流配置:在作业已配置到服务器的前提,通过拖拽作业,控制作业执行调度的先后依赖关系,作业流允许失败重刷机制
计划配置:选择作业、作业流,设置频度类型(按天、半小时、星期)、激活时间、运行时间段,勾选启用,控制作业执行时间区间以及频率。
作业监控:通过作业、作业流名称、状态(就绪、成功、运行、失败、告警),实时查看作业运行状态,通过重置按钮实现作业重跑。
本发明具有如下有益效果:
1、建立一套成熟的企业数据仓库系统,生产业务系统按照实际用途划分门别类的存储在不同数仓用户下,主题域层按照实际用途整合多个业务系统的数据形成比较完整的数据指标库,高度汇总主题层是为了满足不同部门、不同业务需求整合的快速响应数据指标库,根据数据热度可以灵活的配置数据采集频率,以此满足不同时效性数据服务的支持;
2、建立一套成熟的血缘关系平台,形成自最下层的业务系统->数据仓库->数据服务层(报表、接口等)全链路血缘关系、数据地图、数据拓扑图,既可以快速进行影响分析又可以精确或者模糊匹配查询;
3、建立一套成熟的数据治理平台,针对各种业务,制定不同的数据质量一致性校验规则,满足数据量级、数据值级两个方面的一致性,即生产业务系统和数据仓库平台里面的数据量一致、数据值(例如:销售金额、销售数量等)一致。
附图说明
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述或其他方面的优点将会变得更加清楚。
图1是本发明系统架构图。
图2是日志表结构示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
如图1所示,本发明公开了一个基于数据治理及血缘关系设计的数据仓库系统,该系统是一个比较成熟的数据资产管理系统,包括数据仓库管理模块、血缘关系管理模块、元数据管理模块、数据质量管理模块以及作业调度管理模块。
数仓管理模块:生产业务镜像层、主题域层、高度汇总主题层;
血缘关系管理模块:数据源模块、采集器模块、数据地图、数据影响分析模块;
元数据管理模块:数据源模块、元数据采集调度、元数据版本模块、元数据报告模块;
数据质量管理模块:数据质量定义、数据质量分析、数据质量监控、数据质量报告;
作业调度管理模块:作业管理、调度管理、监控管理。
1、数仓管理模块
负责存储各生产业务系统的数据,数据热度低并且数据量小的场景,每天全量抽取入库;数据热度低并且数据量比较大的场景,每天增量抽取入库(业务系统有增量时间戳就根据时间戳增量抽取,若无,就按照具体的业务形态进行倒推时间来增量抽取);数据热点高并且数据量小的场景,每天可自定义时间段进行高频的数据抽取;数据热点高并且数据量大的场景,则按照具体的业务形态进行高频的增量数据抽取。主题域划分根据企业实际场景划分,例如:财务域、商品域、订单域、会员域、平台域、金融域、活动域、粉丝域。高度汇总主题域针对业务需求、快速响应提供分析的高度汇总的指标数据集。
1.1小于百万级的数据量库表采用全量采集入库;
1.2生产系统有更新时间戳,超过百万级的数据量库表采用增量采集入库;
1.3生产系统无更新时间戳,超过百万级的数据量库表采用倒推历史时间增量采集入库;
1.4大表分割,单表过亿的数据量可拆分成对应的年份小表做存储;
1.5做大表分割的表,里面留存近两年的数据;
1.6数据量超过百万级,必须处理成相应的分区表,提升dml(即datamanipulationlanguage数据操纵语言,包括select、update、insert、delete)效率;
1.7主题域层的设计理念,一个独立的业务一个大宽表设计;
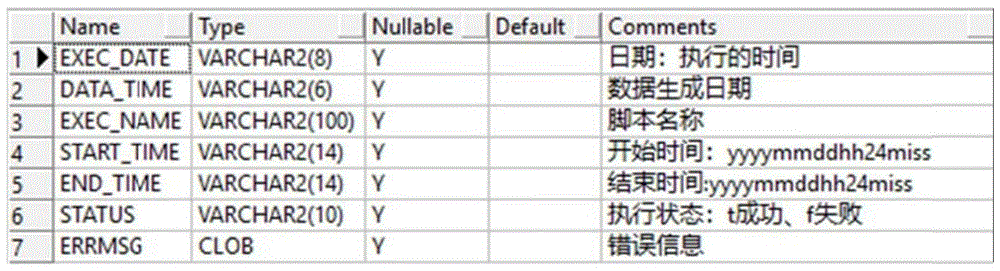
1.8所有操作信息记录日志表,便于巡检查询日志及操作履历,如图2所示,是一个日志表结构,其中各行各列表示的含义如下:
exec_date:存储过程执行时间(格式:yyyymmdd)
exec_name:存储过程名称(pp_xxxx)
start_time:存储过程执行开始时间(格式:yyyymmddhh24miss)
end_time:存储过程执行结束时间(格式:yyyymmddhh24miss)
status:存储过程执行状态(t:成功,f:失败)
errmsg:存储过程错误信息字段(记录存储过程执行错误信息)
2、血缘关系管理模块
负责企业数据仓库的血缘关系管理,包括采集生产业务系统的库表信息、数据仓库的生产业务系统、主题域层、高度汇总主题域层的库表信息、数据服务和报表应用的血缘关系、数据服务和数据接口的血缘关系,对公司整个数据的来龙去脉形成一份完整的数据地图,既可以满足对新人全方位的业务培训,又可以对业务进行更全面的影响分析。
2.1数据源配置:mysql、oracle、sqlserver各种数据库;
2.2采集器配置:数据字典、etl采集、excel采集、报表采集;
2.3采集作业配置:灵活自定义配置,精确到时分秒,可以手工采集,日志跟踪
2.4提供高级查询工具,可以满足精确查询以及模糊匹配查询
2.5血缘分析可以进行粒度切换:全链路分析、影响分析、汇总分析
3、数据质量管理模块
负责1:校验生产业务系统的数据质量,提供灵活可配置的校验规则,如:非空、枚举值、主键约束;负责2:检验生产业务系统和数仓系统数据业务的一致性,最终提供邮件触达的功能。
本发明提供了一种基于数据治理及血缘关系设计的数据仓库系统,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!