基于字符级神经网络与SVM的交通事故文本分类方法和系统与流程
本申请属于智能交通管理领域,具体涉及一种基于字符级神经网络与svm的交通事故文本分类方法和系统。
背景技术:
近年来,为妥善处理交通事故,公平公正的认定事故责任人,每年都要花费大量人力、财力用于道路交通事故的处理。因此,急需一种自动化的交通事故文本分类方法,实现对交通事故数据的分析,从而辅助交通部门发现事故黑点,以便进一步的治理。
对事故进行分类的问题,可归属为文本分类的范畴。人工神经网络(artificialneuralnetworks)是一种按照人脑的组织和活动原理而构造的一种数据驱动型非线性模型。它由神经元结构模型、网络连接模型、网络学习算法等几个要素组成,是具有某些智能功能的系统。在文本分类中,神经网络是一组连接的输入输出神经元,输入神经元代表词条,输出神经元表示文本的类别,神经元之间的连接都有相应的权值。训练阶段,通过某种算法,如正向传播算法和反向修正算法,调整权值,使得测试文本能够根据调整后的权值正确地学习。从而得到多个不同的神经网络模型,然后令一篇未知类别的文本依次经过这些神经网络模型,得到不同的输出值,通过比较这些输出值,最终确定文本的类别。
svm(supportvectormachine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
在此之前很多基于人工神经网络的模型都是使用更高层面的单元对文本或者语言进行建模,比如单词(统计信息或者n-grams、word2vec等),短语(phrases),句子(sentence)层面,或者对语义和语法结构进行分析。例如专利申请号为cn201710573388.8,专利名称为基于超深卷积神经网络结构模型的中文文本分类方法的文献,公开了一种基于单词的分类算法。然而,需要预先采集大量语料来构建词向量模型,分词的质量直接影响后续分类准确度,且只能处理中文。
又如专利申请号为cn201810353803.3,专利名称为基于数据融合和支持向量机的高速路交通事故严重度预测方法的文献,该文献收集交通事故发生时的道路条件、驾驶员情况、车辆情况等变量因素,建立svm模型来预测高速公路事故的严重度。但是关于影响事故严重度特征的选取,过于主观,且其所列出的“道路条件”、“驾驶员情况”等因素也未必能完全表征事故特征。
由此可见,当前交通事故文本分类主要存在以下问题急需解决:
1)传统的交通事故文本分类往往需要人工标定,浪费大量人力、财力,且人工操作难免疏漏,同时也难以满足时效性的要求。
2)现有的卷积神经网络都是基于高层级的单元进行建模(单词、短语或句子),一方面增加了训练复杂度,另一方面也限制了模型的普适性。另外,传统的softmax分类器在准确度上也有待提高。
3)现有的支持向量机模型在特征的提取上缺乏客观依据,往往仅凭人工经验,制约了模型准确性的提升。
技术实现要素:
本申请的目的在于提供一种基于字符级神经网络与svm的交通事故文本分类方法和系统,可避免预训练的开销,且不受语言限制,同时避免了svm模型在特征选取上的盲目性。
为实现上述目的,本申请所采取的技术方案为:
一种基于字符级神经网络与svm的交通事故文本分类方法,所述基于字符级神经网络与svm的交通事故文本分类方法,包括以下步骤:
获取事故原因语料,划分得到训练集和测试集,并将所述事故原因语料拆解为字符,构建字典;
建立字符级神经网络模型,利用所述训练集优化所述字符级神经网络模型,利用优化后的字符级神经网络模型提取训练集中数据的事故文本特征,并利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型;
利用优化后的字符级神经网络模型提取所述测试集中数据的事故文本特征,并将该事故文本特征输入优化后的svm模型,若判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型;
将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,并将所述多维矩阵输入至优化后的字符级神经网络模型中提取事故文本特征,最优的svm模型通过该事故文本特征得到事故文本分类结果。
作为优选,所述的字符级神经网络模型为:从输入层i开始,依次经过卷积层c、池化层m、全连接层f1、全连接层f2、softmax层;
所述事故文本特征为全连接层f1输出的特征。
作为优选,所述利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型,包括:
将所述事故文本特征通过核函数转换到高维空间进行线性分割,所述核函数采用高斯核:
其中,xi为事故文本特征样本,x为核函数中心,σ函数的宽度参数;
利用转换后的事故文本特征,结合所述训练集中各事故原因的标签,通过网格搜索法得到svm模型的最优参数,以完成svm模型的优化;
所述事故原因的标签包括:两机动车、机动车与非机动车、机动车与行人、机动车与固定物、两非机动车、非机动车与行人。
作为优选,所述若判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型,包括:
定义混淆矩阵;
根据所述混淆矩阵,以及svm模型输出的分类结果和测试集中各事故原因及对应标签,计算准确率和召回率;
若准确率>95%且召回率>0.9,则结束训练并输出当前的svm模型作为最优的svm模型;否则继续利用训练集优化svm模型。
作为优选,所述将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,包括:
令待分类的事故原因拆解得到n个字符,所述字典中包含的字符数为m,利用字典中的每个字符映射得到一个m维向量,将待分类的事故原因中的每个字符映射到所述的m维向量中,得到一个n*m维矩阵。
本申请还提供了一种基于字符级神经网络与svm的交通事故文本分类系统,所述基于字符级神经网络与svm的交通事故文本分类系统包括:
语料处理模块,用于获取事故原因语料,划分得到训练集和测试集,并将所述事故原因语料拆解为字符,构建字典;
训练模块,用于建立字符级神经网络模型,利用所述训练集优化所述字符级神经网络模型,利用优化后的字符级神经网络模型提取训练集中数据的事故文本特征,并利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型;
测试模块,用于利用优化后的字符级神经网络模型提取所述测试集中数据的事故文本特征,并将该事故文本特征输入优化后的svm模型,若判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型;
分类模块,用于将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,并将所述多维矩阵输入至优化后的字符级神经网络模型中提取事故文本特征,最优的svm模型通过该事故文本特征得到事故文本分类结果。
作为优选,所述的字符级神经网络模型为:从输入层i开始,依次经过卷积层c、池化层m、全连接层f1、全连接层f2、softmax层;
所述事故文本特征为全连接层f1输出的特征。
作为优选,所述利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型,包括:
将所述事故文本特征通过核函数转换到高维空间进行线性分割,所述核函数采用高斯核:
其中,xi为事故文本特征样本,x为核函数中心,σ函数的宽度参数;
利用转换后的事故文本特征,结合所述训练集中各事故原因的标签,通过网格搜索法得到svm模型的最优参数,以完成svm模型的优化;
所述事故原因的标签包括:两机动车、机动车与非机动车、机动车与行人、机动车与固定物、两非机动车、非机动车与行人。
作为优选,所述若判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型,包括:
定义混淆矩阵;
根据所述混淆矩阵,以及svm模型输出的分类结果和测试集中各事故原因及对应标签,计算准确率和召回率;
若准确率>95%且召回率>0.9,则结束训练并输出当前的svm模型作为最优的svm模型;否则继续利用训练集优化svm模型。
作为优选,所述将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,包括:
令待分类的事故原因拆解得到n个字符,所述字典中包含的字符数为m,利用字典中的每个字符映射得到一个m维向量,将待分类的事故原因中的每个字符映射到所述的m维向量中,得到一个n*m维矩阵。
本申请提供的基于字符级神经网络与svm的交通事故文本分类方法和系统,首先利用神经网络训练学习交通事故文本的特征,进而将该特征输入svm分类器,进行事故分类。这种方式有效地避免了传统的svm模型在特征选取上的盲目性;同时,由于svm在数学上的完备性,避免了传统神经网络容易陷入局部最优的尴尬现象。本申请从执行效率上看,由于不需要对语料进行分词处理,故而降低了时间复杂度,同时也避免了预训练的开销;从鲁棒性上看,cnn和svm相结合的方式提取出的特征,较传统的nlp模型更为健壮,更能表征不同类别的本质性差异,同时由于算法是基于字符级的低层级分类,故分类精度不依赖于分词结果的好坏,也不会受不重要字符的影响,因而鲁棒性更高。
附图说明
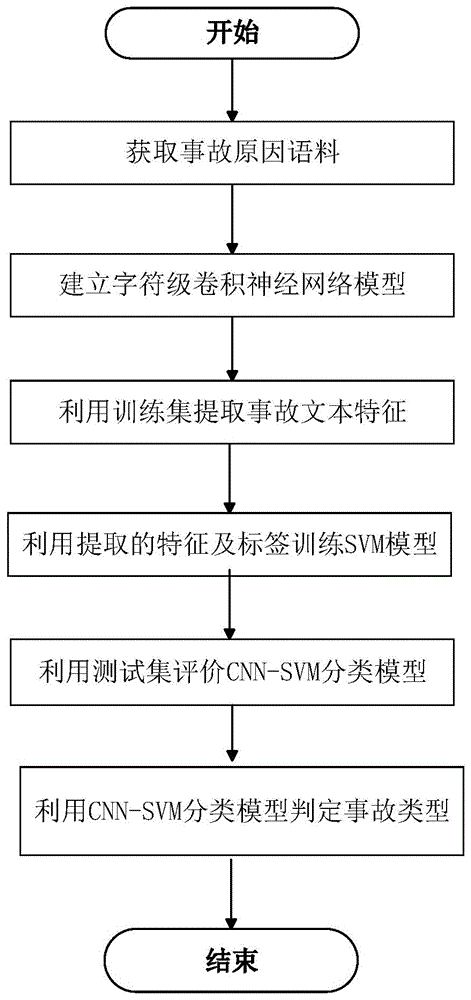
图1为本申请的基于字符级神经网络与svm的交通事故文本分类方法流程框图;
图2为本申请的字符级神经网络模型的一种实施例结构示意图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本申请。
本申请的方法中涉及的步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些子步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
如图1所示,其中一实施例中提供了一种基于字符级神经网络与svm的交通事故文本分类方法,该方法包括以下步骤:
s1、获取事故原因语料,划分得到训练集和测试集,并将所述事故原因语料拆解为字符,构建字典。
s1.1、得到训练集和测试集
事故原因语料可通过接收直接输入的文字内容获得,也可根据关键词自动搜索获得。在对事故原因语料进行划分时,由于训练集的大小在一定程度上会影响后续模型的训练,故本实施例中按照7:3的比例将事故原因语料进行划分得到训练集和测试集。
s1.2、构建字典
根据获取的所有事故原因语料,除去重复字符,得到汇总全部字符后的字符集,并将该字符集作为字典,该字典包括m个字符。在一实施例中,字典包括274个字符,274个字符依次为:
“车人汽,事没两碰电瓶撞。了擦与相伤三轮和1摩托20跟还好未个护叫救已辆不货要行到警报现方跑在院自轿医点知通一后场的我开对子有线里用被柱上机己单杆拉拖主时路面去卡无门停故9着逃送掉7树牌沟5动过墙包浙栓水f:中走公是带色轻受消压防交离栏班口天翻他尾下处小室急二租3(出逸先圾垃前民皮左卫称8砸右隔墩东说西等追看石临砖堍驶才s起员昨)她环微舟脚喝俩症客告广板6障桥载区案七部住来管话都片挂崇把搅觉黑往溜坏漏铲摔长楼队保求濮刮胎生道躺备4得倒半宁孩理断司缆多坡)罐坛大酒t驾堆红铁早挖当黄福安今诊巴第花库瓷这拌南其城海午桶代边分骑另险卖市光能外进心油块厂记”。
s1.3、事故原因分类
对所收集的语料中的各事故原因进行分类,根据分类结果为各事故原因添加标签。需要说明的是,此处对各事故原因进行分类的操作优选采用人工进行,以保证对后续模型训练的有效性。
根据事故常见类型,在一实施例中,事故原因所属的事故类型主要为:两机动车、机动车与非机动车、机动车与行人、机动车与固定物、两非机动车、非机动车与行人。根据这六类对事故原因进行划分,并分别为训练集和测试集中的各事故原因添加标签,即事故原因的标签同样包括:两机动车、机动车与非机动车、机动车与行人、机动车与固定物、两非机动车、非机动车与行人。
s2、建立字符级神经网络模型。
如图2所示,在一实施例中,建立的字符级神经网络模型为:从输入层(embedding)i开始,依次经过卷积层(cnn)c、池化层(maxpooling)m、全连接层(fullyconnected)f1、全连接层(fullyconnected)f2、softmax层。
其中,输入层i:支持同时输入多个字符,每个字符均被one-hot编码为一个m维向量(根据字典中的字符数而定)。图2中的w0~w5即表示输入的字符,仅表示支持同时输入多个字符,不作为对同时输入的字符数的限制。
输入层是待分类的事故原因中字符对应的wordvector依次(从上到下)排列的矩阵。例如在一实施例中,令待分类的事故原因拆解得到n个字符,所述字典中包含的字符数为m,利用字典中的每个字符映射得到一个m维向量,将待分类的事故原因中的每个字符映射到所述的m维向量中,得到一个n*m维矩阵。
卷积层c:卷积操作得到若干个featuremap,卷积窗口的大小为5×m,其中5表示卷积核尺寸,m表示wordvector的维数。通过该卷积窗口,将得到若干个featuremap。
池化层m:从之前一维的featuremap中提出最大的值,代表着最重要的信号。可以看出,这种pooling方式可以解决可变长度的报警内容输入问题(因为无论featuremap中有多少个值,只需要提取其中的最大值)。最终,池化层的输出为各个featuremap的最大值,即一个一维的向量。
全连接层f1:事故文本特征即为全连接层f1输出的特征,该层输出的特征值准确率高。
全连接层f2:将特征图映射成一个固定长度(分类数目)。
softmax层:输出反映事故原因归属于“两机动车,机动车与非机动车,机动车与行人,机动车与固定物,两非机动车,非机动车与行人”这六类的概率分布。
需要说明的是,本申请的交通事故文本分类方法为了克服softmax层准确率不够理想的问题,在进行文本分类预测时,采用全连接层f1的输出作为svm分类器的特征输入,同时可克服svm分类器在特征的选取上依赖人工经验的问题,从而显著提升文本分类的准确性。
而全连接层f2和softmax层在字符级神经网络模型训练阶段有所应用,为了得到全连接层f1输出的特征值,必须依靠全连接层f2和softmax层形成闭环网络,从而采用梯度下降法得到构建特征的权重参数。有关字符级神经网络模型的训练在后续步骤中有详述。
s3、利用所述训练集优化所述字符级神经网络模型,利用优化后的字符级神经网络模型提取训练集中数据的事故文本特征。
将添加过标签的训练集输入至步骤s2中构建的字符级神经网络模型,并利用梯度下降算法不断迭代优化网络参数。
具体地,优化网络参数时:首先将训练集数据在神经网络中进行一次正向传递,得到预测结果y_hat;其次计算输出层神经元的误差梯度(errorgradient)δ;最后更新权重变化δw_i。在完成了一次对整个数据集的遍历之后,将δw_i(权重变化值)和w_i(预设的权重)相加,得到新的权重w_i,即完成一次对权重的更新。
按照上述过程不断迭代更新权值,直至误差满足要求,即得到最优的所述字符级神经网络模型。在一实施例中,字符级神经网络模型不断优化后得到的最优网络参数如下:
embedding_dim=64#词向量维度;
seq_length=100#序列长度;
num_classes=6#类别数;
num_filters=256#卷积核数目;
kernel_size=5#卷积核尺寸,步长为1;
pool_size=2#池化核尺寸,步长为2;
vocab_size=274#词汇表达小;
hidden_dim=128#全连接层神经元;
dropout_keep_prob=0.5#dropout保留比例;
learning_rate=1e-3#学习率;
batch_size=32#每批训练大小;
num_epochs=200#总迭代轮次;
print_per_batch=5#每多少轮输出一次结果;
save_per_batch=5#每多少轮存入tensorboard。
利用优化后的字符级神经网络模型提取训练集中数据的事故文本特征,模型中全连接层f1的输出即为经过神经网络迭代寻优后,最能反应事故属性的事故文本特征。
本实施例采用第一个全连接层后输出的向量,可将将原始的基于softmax对特征进行分类的方法,改进为基于svm的方法,这种自动学习提取特征的方式,也避免了svm在选择特征方面主观性太强的缺点。
即本实施例中的字符级神经网络模型的softmax层输出的概率分布并不直接作为事故文本分类结果,仅供参考用。而字符级神经网络模型主要用于利用第一个全连接层提取出事故文本特征。
s4、利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型。
为了解决事故分类为非线性的问题,通过非线性映射φ:rd→h,将原输入空间的样本映射到高维的特征空间h中,再在高维特征空间h中构造最优分类超平面。在高维空间求解时需要计算样本点向量的点积,运算量非常大,因此采用满足mercer条件的核函数k(x,xi)来代替点积运算。
在一实施例中,将事故文本特征通过核函数转换到高维空间进行线性分割时,核函数采用高斯核(rbf):
其中,xi为事故文本特征样本,x为核函数中心,σ函数的宽度参数。
rbf核函数可将输入的事故文本特征映射到高维特征空间上,解决线性不可分问题。然后利用转换后的事故文本特征,结合所述训练集中各事故原因的标签,通过网格搜索法得到svm模型的最优参数,以完成svm模型的优化。
s5、利用测试集测试svm模型。
利用优化后的字符级神经网络模型提取测试集中数据的事故文本特征,并将该事故文本特征输入优化后的svm模型,判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型。
在判断svm模型输出的分类结果与预设值的关系时,在一实施例中可以是将模型分类结果和测试集样本真实结果作比较,在进行比较时,定义混淆矩阵,根据所述混淆矩阵,以及svm模型输出的分类结果和测试集中各事故原因及对应标签,计算准确率和召回率;若准确率>95%且召回率>0.9,则结束训练并输出当前的svm模型作为最优的svm模型;否则继续利用训练集优化svm模型。
s6、判定事故类型。
将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵。在对事故原因拆解时,采用步骤s2中的方法得到一个n*m维矩阵,并将该n*m维矩阵输入至优化后的字符级神经网络模型中,通过卷积层、池化层、全连接层完成事故文本特征的提取,最后利用最优的svm模型通过该事故文本特征得到事故文本分类结果,即为该待分类的事故原因所归属的事故类型。
本申请以字符为单位进行交通事故文本分类,较传统的基于单词、短语或句子等高层级的分类模式,不需要使用预训练好的词向量和语法句法结构等信息,且不受语言的限制,普适性强。
另外,为了解决神经网络softmax层准确率不够理想,而svm分类器在特征的选取上依赖人工经验的问题。本申请利用神经网络训练学习交通事故文本的特征,进而将该特征输入svm分类器,进行事故分类。这种方式有效地避免了传统的svm模型在特征选取上的盲目性;同时,由于svm在数学上的完备性,避免了传统神经网络容易陷入局部最优的尴尬现象。
本申请从执行效率上看,由于不需要对语料进行分词处理,故而降低了时间复杂度,同时也避免了预训练的开销;从鲁棒性上看,cnn(卷积神经网络)和svm相结合的方式提取出的特征,较传统的nlp模型更为健壮,更能表征不同类别的本质性差异,同时由于算法是基于字符级的低层级分类,故分类精度不依赖于分词结果的好坏,也不会受不重要字符的影响,因而鲁棒性更高。可以辅助交通部门迅速判定事故类别、高效发现事故黑点,为进一步的事故诊断和预防提供意见和参考。
在一实施例中,还提供了一种基于字符级神经网络与svm的交通事故文本分类系统,所述基于字符级神经网络与svm的交通事故文本分类系统包括:
语料处理模块,用于获取事故原因语料,划分得到训练集和测试集,并将所述事故原因语料拆解为字符,构建字典;
训练模块,用于建立字符级神经网络模型,利用所述训练集优化所述字符级神经网络模型,利用优化后的字符级神经网络模型提取训练集中数据的事故文本特征,并利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型;
测试模块,用于利用优化后的字符级神经网络模型提取所述测试集中数据的事故文本特征,并将该事故文本特征输入优化后的svm模型,若判断所述svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型;
分类模块,用于将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,并将所述多维矩阵输入至优化后的字符级神经网络模型中提取事故文本特征,最优的svm模型通过该事故文本特征得到事故文本分类结果。
在另一实施例中,所采用的字符级神经网络模型为:从输入层i开始,依次经过卷积层c、池化层m、全连接层f1、全连接层f2、softmax层;且所述事故文本特征为全连接层f1输出的特征。
具体地,训练模块利用提取的事故文本特征训练svm模型,直至得到优化后的svm模型,在其中一实施例中执行如下操作:
将所述事故文本特征通过核函数转换到高维空间进行线性分割,核函数采用高斯核:
其中,xi为事故文本特征样本,x为核函数中心,σ函数的宽度参数;
利用转换后的事故文本特征,结合所述训练集中各事故原因的标签,通过网格搜索法得到svm模型的最优参数,以完成svm模型的优化;
所述事故原因的标签包括:两机动车、机动车与非机动车、机动车与行人、机动车与固定物、两非机动车、非机动车与行人。
在另一实施例中,测试模块若判断svm模型输出的分类结果误差小于预设值,则得到最优的svm模型;否则继续利用训练集优化svm模型,执行如下操作:
定义混淆矩阵;
根据所述混淆矩阵,以及svm模型输出的分类结果和测试集中各事故原因及对应标签,计算准确率和召回率;
若准确率>95%且召回率>0.9,则结束训练并输出当前的svm模型作为最优的svm模型;否则继续利用训练集优化svm模型。
具体地,分类模块将获取的待分类的事故原因拆解为字符,通过所述字典将拆解得到的字符映射为多维矩阵,在其中一实施例中执行如下操作:
令待分类的事故原因拆解得到n个字符,所述字典中包含的字符数为m,利用字典中的每个字符映射得到一个m维向量,将待分类的事故原因中的每个字符映射到所述的m维向量中,得到一个n*m维矩阵。
关于基于字符级神经网络与svm的交通事故文本分类系统的其他限定,参见上述关于基于字符级神经网络与svm的交通事故文本分类方法的具体限定,在此不再进行赘述。
在一个实施例中,提供了一种计算机设备,即一种基于字符级神经网络与svm的交通事故文本分类系统,该计算机设备可以是终端,其内部结构可以包括通过系统总线连接的处理器、存储器、网络接口、显示屏和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现上述基于字符级神经网络与svm的交通事故文本分类方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!