基于BIRCH算法的风电出力典型场景生成方法与流程
本发明涉及电力系统领域,特别是涉及一种考基于birch算法的风电出力典型场景生成方法。
背景技术:
近年来,中国的风力发电规模高速增长,成为中国第三大电力来源。风力发电存在抽样场景集规模过大,影响计算效率的问题。因此,进行场景缩减有重要意义。
现有的场景缩减方法有后向缩减法、快速前向选择法、同步回代消除法、场景树构建法等。但目前的场景缩减方法在进行场景缩减时都需要计算出所有可能的距离组合并进行比较,在场景数量较大时存在计算量大、计算效率低等缺点。
如何提高场景缩减的计算效率,是目前风电出力典型场景生成需要深入研究的问题。
技术实现要素:
本发明主要解决的技术问题是采用birch算法,提供一种生成风电出力典型场景的方法。
本发明采用以下的技术方案:
应用birch算法对初始场景集进行迭代缩减、拼合、再缩减,获得典型场景集。
具体的,包括步骤:
应用birch算法对初始场景集进行迭代缩减、拼合、再缩减,获得典型场景集,包括:
风电出力场景是指一天内各时刻的实际风电功率输出曲线。在获得风电出力初始场景集之后,本发明通过birch算法对这些风电出力场景进行聚类。
birch(balancediterativereducingandclusteringusinghierarchies)是一个增量式的层次聚类算法,只需单遍扫描风电场景集即可进行有效聚类。birch算法采用自底向上的策略,并通过迭代重定位改进结果,适用于场景量和类别数较大的情况。其中,聚类特征(clusterfeature,cf)和聚类特征树(cf-tree)是birch算法的两个核心概念。
定义一个包含n个d维风电场景的场景集:{zi}(i=1,2,…,n),则该风电场景集的聚类特征cf是一个三元组:
cf=(n,ls,ss)
式中,n代表风电场景集中的场景数;ls代表风电场景集中场景各维度的向量和
聚类特征cf可以反映风电场景的基本信息。其中,ls可反映场景集中各类场景的聚类中心:
z0=ls/n
式中,z0为风电场景簇的中心,可用于计算各个场景簇之间的距离;ss可反映场景集中各类场景的平均距离:
cf满足线性关系,即:
cfa+cfb=(na+nb,lsa+lsb,ssa+ssb)
该性质说明cf-tree中每个父节点的cf三元组数值等于该父节点所指向的所有子节点的三元组之和,从而可以用来提高cf-tree的更新效率。
cf-tree是反映风电场景聚类情况的平衡树。树的形态由三个参数来反映:非叶节点分支参数b、叶节点分支参数l和风电场景簇最大半径阈值t。其中,b为根节点和非叶节点的个数最大值;l为叶节点和风电场景簇的个数最大值,每个叶节点可包含多个场景簇;t为风电场景簇的最大样本半径,可以保证风电场景簇的紧凑程度。
本发明方法应用birch算法进行场景缩减获得典型风电场景集,可以减少计算时间和存储规模。
本发明提供的技术方案的有益效果:
随着风电等可再生能源的普及率越来越高,电力系统的不确定性也越来越大。在以往的电力系统规划和运行中,通常采用情景分析的方法来解决这一问题,但由于计算量大,其有效性受到了限制。因此,本发明提供了一种基于birch算法的方法来进行风电典型场景生成,即应用birch算法对初始场景集进行迭代缩减,获得典型场景集。本发明所提供的方法能够快速、准确地进行风电出力场景的缩减,相比其它方法,本方法在计算时间和存储规模上都有较大优势。
附图说明
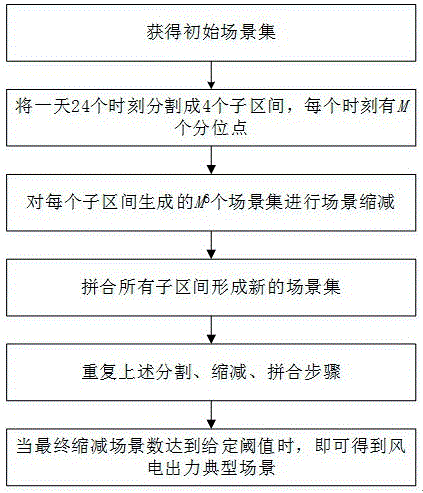
图1为基于birch算法的风电出力典型场景生成方法流程图;
图2为birch算法的cf-tree示意图。
具体实施方式
为了更好地理解本发明的目的、技术方案以及技术效果,以下结合附图对本发明进行进一步的讲解说明。
一种基于birch算法的风电出力典型场景生成方法,其特征是:包括步骤:
获得风电出力初始场景集;
应用birch算法对初始场景集进行迭代缩减、拼合、再缩减,获得典型场景集。
所述应用birch算法对初始场景集进行迭代缩减、拼合、再缩减,获得典型场景集,包括:
风电出力场景是指一天内各时刻的实际风电功率输出曲线;在获得风电出力初始场景集之后,通过birch算法对这些风电出力场景进行聚类;
birch是一个增量式的层次聚类算法,只需单遍扫描风电场景集即可进行有效聚类;birch算法采用自底向上的策略,并通过迭代重定位改进结果,适用于场景量和类别数较大的情况;其中,聚类特征;和聚类特征树;是birch算法的两个核心概念;
定义一个包含n个d维风电场景的场景集:{zi}(i=1,2,…,n),则该风电场景集的聚类特征cf是一个三元组:
cf=(n,ls,ss)
式中,n代表风电场景集中的场景数;ls代表风电场景集中场景各维度的向量和
聚类特征cf可以反映风电场景的基本信息;其中,ls可反映场景集中各类场景的聚类中心:
z0=ls/n
式中,z0为风电场景簇的中心,可用于计算各个场景簇之间的距离;ss可反映场景集中各类场景的平均距离:
cf满足线性关系,即:
cfa+cfb=(na+nb,lsa+lsb,ssa+ssb)
该性质说明cf-tree中每个父节点的cf三元组数值等于该父节点所指向的所有子节点的三元组之和,从而可以用来提高cf-tree的更新效率;
cf-tree是反映风电场景聚类情况的平衡树;树的形态由三个参数来反映:非叶节点分支参数b、叶节点分支参数l和风电场景簇最大半径阈值t;其中,b为根节点和非叶节点的个数最大值;l为叶节点和风电场景簇的个数最大值,每个叶节点可包含多个场景簇;t为风电场景簇的最大样本半径,可以保证风电场景簇的紧凑程度。
为了进一步理解本发明,以下以中国某地区的典型风电数据为例,来解释本发明的实际应用。
在获得该地区的初始场景集后,首先将24个时刻分割成4个子区间,每个子区间包含6个时刻,每个时刻有m个分位点。这样,每个子区间中将只生成m6个初始场景,首先对每个子区间中的m6个初始场景进行缩减,然后再连接这4个子区间,从而形成24个时刻的典型场景集。当最终的缩减后场景数达到给定阈值时,即可得到经典风电出力场景集。为了比较本发明方法与其他方法的优劣,表1分别列出了当场景分别缩减为1000、500、300和100时,基于birch算法、k-means聚类以及凝聚式层次聚类(aggregativehierarchyclustering,ahc)的场景缩减速度。测试环境为windows7,matlab2014awithpython3.7;硬件为corei57400@3.00ghz,ram8gb。分位点数m取6。从表1中可以看出基于ahp的方法始终无法在可接受的时间(<1h)内给出结果,这是因为在ahp的过程中,需要生成66×66的double型距离矩阵,共占用66×66×8=1.74×1010b≈16.2gb,超过了测试电脑的可用内存。基于birch和k-means的方法都可以在有限时间内给出结果,一方面它们只生成若干个66×1的向量,另一方面它们的时间复杂度都为o(n)级别。从表1还可以看出基于birch算法的方法比基于k-means算法更快一些,这是因为birch算法只需要一遍扫描数据集就可以建立起典型场景的聚类特征树,而k-means算法需要反复迭代。
表1与其他方法的速度比较
因此,本发明所提方法和k-means方法在场景缩减的存储空间上大幅优于ahp方法。和k-means方法相比,本发明所提方法在计算速度上更有优势。
- 还没有人留言评论。精彩留言会获得点赞!