一种人脸角度及人脸模糊度分析方法、系统和计算机设备与流程
本发明涉及智慧安防终端红外活体检测技术领域,特别是一种人脸角度及人脸模糊度分析方法、系统和计算机设备。
背景技术:
目前在我们日常生活中随处可见各式各样的摄像头,其中有大部分摄像头都有存储功能,每天产生大量的数据,这些数据可以进行各式各样的视频结构化分析,但是各式各样的摄像头安装在不同的环境中,过度曝光、欠曝光、聚焦没聚好而导致的失焦以及运动模糊等诸多问题会造成成像质量参差不齐,这也为后期的数据检测和分析造成麻烦,例如在人证自动比对一体机中,将一张成像质量较差的人脸图片与身份证图片进行人证比对,经常会导致结果误判为非本人,不但没有增加门禁安全检测效率反而造成了阻塞,因此,为了解决上述问题,本发明人提出一种基于头部照片的人脸角度和人脸模糊度分析方法。
技术实现要素:
本发明为解决上述技术问题,本发明提供了一种人脸角度及人脸模糊度分析方法、系统和计算机设备,其能够快速有效且准确地检测视频或/和图片内人脸角度和人脸模糊度,进而统计分析各种场景下摄像头内的人脸角度和人脸模糊度信息,提取出高质量的照片,以便基于高质量图片进行各种数据分析和比对等操作,提高后续分析预测的准确率。
为实现上述目的,本发明采用的技术方案为:
第一方面,本发明提供的一种人脸角度及人脸模糊度分析方法,包括以下步骤:
s1.神经网络模型训练:包括训练用于人脸检测的基于深度学习的第一神经网络模型和用于人脸角度和人脸模糊度分析的第二神经网络模型;
s2.待检测图片提取:获取各种场景下摄像头内图片或/和视频数据(可存于数据库),从(数据库)中提取待检测的单张图片;
s3.图片的人脸检测与矫正:通过训练好的第一神经网络模型对单张图片进行人脸检测,获取人脸框位置和面部特征点位置;根据人脸框位置和面部特征点位置进行图片矫正和截取,获得矫正标准化的人脸图片;
s4.人脸角度和模糊度预测:通过训练好的第二神经网络模型对矫正标准化的人脸图片进行人脸角度和人脸模糊度分析,预测人脸角度分类的置信度及人脸模糊度的回归值;
s5.属性输出:根据预设的人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度和人脸模糊度的回归值。
进一步的,所述步骤s1神经网络模型训练包括:
s11.第一神经网络模型训练:通过采集各种人物在各种场景下摄像头内的图片和视频,然后采用外接矩形框人工标定出人脸区域及面部的左眼瞳孔、右眼瞳孔、鼻尖、左边嘴角和右边嘴角五个特征点,将标定好的数据及相对应的标签输入第一神经网络模型中进行训练,得到可精准检测人脸框以及面部特征点的深度学习第一神经网络模型;该第一神经网络模型采用mtcnn模型,所述mtcnn模型包括p-net网络、r-net网络和o-net网络;
s12.第二神经网络模型训练:通过第一神经网络模型预测出的两个眼睛瞳孔的位置,计算双瞳孔的连线与水平线的夹角,进行逆向旋转,得到一张双瞳水平的照片;
对获取的人脸框的位置进行预设比例的放大,然后进行剪切,再经过定中心点进行逆向旋转得到大量校正后的人脸照片,然后给到数据标注人员进行人脸角度和人脸模糊度标注,得到大量具有人脸角度和人脸模糊度标签的数据,提取出全部的人脸模糊度标签为清晰的数据,然后使用基于然后使用基于opencv(基于bsd许可(开源)发行的跨平台计算机视觉库)的motionblur(运动模糊添加)和gaussianblur(运动模糊消除)将抽取出的清晰并且带有标注的人脸角度数据制造分不同程度可量化的模糊数据,即得到第二神经网络模型的训练数据;
接着将模糊数据及相对应的人脸角度和人脸模糊度量化标签送入第二神经网络模型中进行训练,得到能够精确预测人脸角度和人脸模糊度的模型。
进一步的,所述第一神经网络模型的损失函数表示如下:
其中,n是预设人脸框的正样本数量;αdet、αbox和αlandmark表示分别表示人脸分类损失、人脸框和面部特征点损失的权重;
进一步的,所述第二神经网络模型采用lightcnn模型作为特征抽取层,使用预设大小的彩色图片作为输入,经过lightcnn抽取特征后,分出两个分支,第一个分支对接全连接层最终输出若一个[0,1]的概率值来表示人脸模糊度的回归值,第二个分支对接全连接层最终输出5个和为1的区间在[0,1]的概率值(概率和为1)来表示人脸角度分类的置信度。
进一步的,所述根据人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度,包括:
将人脸角度属性归类为互斥类;互斥类的所有分支概率和为1.
输出互斥类中置信度最大的属性及对应的置信度。
进一步的,对于所述互斥类,采用交叉熵作为损失函数,如下:
对于模糊度回归,采用均方差作为损失函数,如下:
其中,
第二方面,本发明还提供了一种人脸角度和人脸模糊度分析系统,其包括:
模型训练模块,用于训练人脸检测的基于深度学习的第一神经网络模型和人脸角度和人脸模糊度分析的第二神经网络模型;
图片提取模块,用于获取摄像头内图片或/和视频数据,从中提取单张待检测图片;
人脸检测与矫正模块,用于通过训练好的第一神经网络模型对单张图片进行人脸检测,获取人脸框位置和面部特征点位置;根据人脸框位置和面部特征点位置进行图片矫正和截取,获得矫正标准化的人脸图片;
角度及模糊度分析模块,用于通过训练好的第二神经网络模型对矫正标准化的人脸图片进行人脸角度和人脸模糊度分析,获得人脸角度分类的置信度及人脸模糊度的回归值;
属性输出模块,用于根据预设的人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度和人脸模糊度的回归值。
第三方面,本发明还提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时以实现上述的人脸角度和人脸模糊度分析方法。
采用上述技术方案后,本发明相比于现有技术具有以下优点:
(1)本发明先通过基于深度学习的第一神经网络模型能够快速检测到图片中的人脸框和面部特征点,并输出人脸框位置和面部特征点位置;对人脸框进行校正和扩增后截取矫正标准化的人脸图片;再通过第二神经网络模型对截取的矫正标准化的人脸图片进行基于头部照片的人脸角度和人脸模糊度分析,获得人脸角度分类的置信度及人脸模糊度的回归值,解决了针对失焦以及运动模糊等低质量图像分析问题;
(2)通过本发明的方法能有效快速准确的检测视频或/和图片内人脸位置及特征点并预测出其人脸角度和人脸模糊度,且可根据预测和输出的结果制定相应策略,以满足一些需要判断人脸角度和人脸成像质量的需求场景,即输出的人脸角度和人脸模糊度属性可用于一些对人脸质量有要求的项目或者场景进行人脸图片质量分析,进而可以更好的分析和利用相关数据提取高质量图片。
附图说明
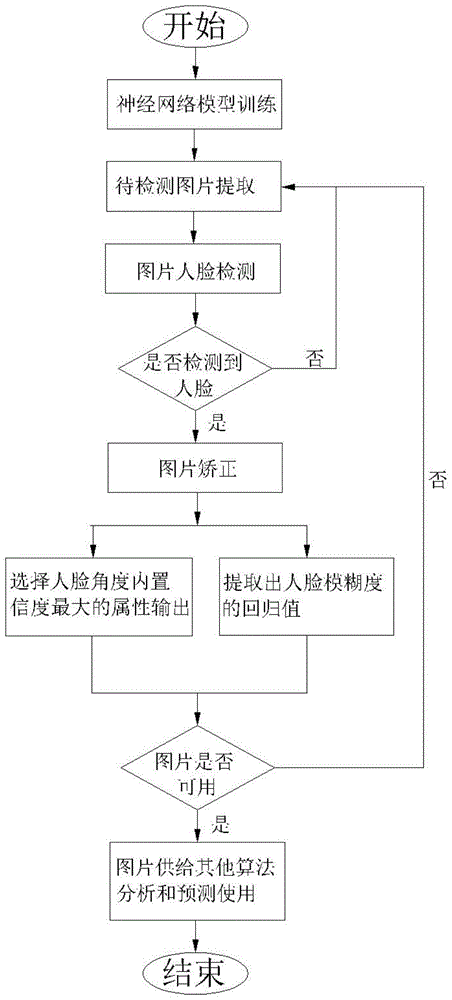
图1为本发明的人脸角度和人脸模糊度分析方法整体流程图;
图2为本发明实施例的第一神经网络模型的p-net网络结构图;
图3为本发明实施例的第一神经网络模型的r-net网络结构图;
图4为本发明实施例的第一神经网络模型的o-net网络结构图;
图5为本发明实施例预测的人脸角度和人脸模糊度分析图;
图6为本发明的一种人脸角度和人脸模糊度分析系统框图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,本发明揭示的一种人脸角度及人脸模糊度分析方法、系统和计算机设备,其包括以下步骤:
s1.神经网络模型训练,包括s11.第一神经网络模型训练,第一神经网络模型用于人脸检测的基于深度学习型,s12.第二神经网络模型训练,第二神经网络模型用于人脸角度和人脸模糊度分析;
具体的,s11.第一神经网络模型训练包括:通过采集各种人物在各种场景下摄像头内的图片和视频,然后采用外接矩形框人工标定出人脸区域及面部的左眼瞳孔、右眼瞳孔、鼻尖、左边嘴角和右边嘴角五个特征点,将标定好的数据及相对应的标签输入第一神经网络模型中进行训练,得到可精准检测人脸框以及面部特征点的深度学习第一神经网络模型;该第一神经网络模型采用mtcnn(multi-taskcascadedconvolutionalnetworks,多任务级联卷积网络)模型,该mtcnn模型包括p-net网络、r-net网络和o-net网络,如下分别介绍上述三个网络:
p-net(proposalnetwork):网络结构如图2所示,网络采用12pixel×12pixel×3channel作为网络输入,经过3×3的卷积网络->maxpooling层->3×3的卷积网络->3×3的卷积网络->3×3的卷积网络后得到1×1×32的输出结果,该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(nms)来合并高度重叠的候选框;
r-net(refinenetwork):网络结构如图3所示,该网络结构主要是通过边界框回归和nms来去掉那些false-positive(网络预测为人脸区域但是事实上并不是)的区域。只是由于该网络结构和p-net网络结构有差异,输入改成24pixel×24pixel×3channel,并且多了一个全连接层,所以会取得更好的抑制false-positive的作用;
outputnetwork(o-net):网络结构如图4所示,该网络结构输入进一步扩大到48pixel×48pixel×3channel所以输入的信息会更加精细,并且该层比r-net层又多了一层卷基层,作用和r-net层作用一样。但是该层对人脸区域进行了更多的监督,作为整个模型的最后阶段,输出的五个面部特征点(landmark,包括左眼瞳孔、右眼瞳孔、鼻尖、嘴巴最左点和嘴巴最右点)相比于前两个阶段要精准很多,三个小网络结构都输出了面部五个特征点坐标,但是由于r-net和p-net网络输入太小,面部特征点的信息很少,所以在前两个阶段的人脸面部特征点回归所产生的损失函数的权重系数设置为比较小的0.5,而在最后阶段的o-net网络产生的人脸面部特征点损失函数采用的权重比较大为1.0,因为面部特征点的预测在o-net阶段输出的结果最为准确,所以实践中选择在最后阶段o-net网络输出的时候作为面部特征点预测结果,o-net的网络输入也是这三个小网络里面最大,有利于更准确提取面部特征;
进一步的,mtcnn特征描述的损失函数主要包含3个部分:人脸/非人脸分类器、边界框回归和特征点定位;
其中,人脸分类损失函数表示如下:
上式(1)为人脸分类的交叉熵损失函数,其中,pi为是人脸的概率,
人脸框损失函数表示如下:
上式(2)是通过欧氏距离计算的回归损失,其中,
面部特征点损失函数表示如下:
和边界框回归一样,上式(3)还是计算网络预测的面部特征点位置和实际真实面部特征点的欧式距离,并最小化该距离。其中,
综上,整个模型训练过程的整体损失函数可以表示为如下:
p-netr-net(αdet=1,αbox=0.5,αlandmark=0.5)
o-net(αdet=1,αbox=0.5,αlandmark=1)
其中,n是预设人脸框的正样本数量;αdet、αbox和αlandmark表示分别表示人脸分类损失、人脸框和面部特征点损失的权重;
由上可知,在训练的时候虽然都会计算上述的3个损失函数,但并不是对每个输入这些损失都有意义,因此定义了上述公式(1)-(3)用来控制对不同的输入采用不同的损失以及分配不同的权重,可以看出,在p-net和r-net中,面部特征点回归的损失权重αlandmark要小于o-net部分,这是因为前面2个stage重点在于过滤掉非人脸的bbox,β存在的意义是:当非人脸输入,就只需要计算有意义的人脸分类损失,而不需要计算无意义的边界框和面部特征点的回归损失,因为针对非人脸区域,以减少冗余计算。
经过上述训练过程,可以得到一个能够精准检测人脸框以及面部特征点的深度学习神经网络模型(第一神经网络模型),用于预测视频或/和图片中的人脸框及面部特征点的位置,进而提取出人脸为下一步提取人脸角度和人脸模糊度分析所用;
s12.第二神经网络模型训练:在训练第二神经网络模型时,先使用前面训练好第一神经网络模型来进行人脸框的数据的预测和面部特征点的预测,使模型在实际使用的时候是更为精准,具体的,在线使用的时候利用第一神经网络模型进行图片和视频检测,得到图片和视频中人脸位置及面部五个特征点的预测,此时的数据还未人工标注人脸框位置,而在得到人脸框的位置后,使用处理工具将图片和视频中的人脸根据人脸框进行人脸的矫正和剪切,矫正的过程采用的方法是:首先通过第一神经网络模型预测出的两个眼睛瞳孔的位置,计算双瞳孔的连线与水平线的夹角,进行逆向旋转,得到一张双瞳水平的照片,具体的,旋转的中心点的获取为再根据双瞳连线的中点,与嘴上的两点连线中点进行链接作为纵线,从上到下取线段的0.406作为图像的中心点,其中中心点系数0.406是根据大量真实场景人脸标定得到的系数;剪切的过程为首先对获取的人脸框的位置进行预设比例的放大,然后进行剪切,最后经过定中心点进行逆向旋转得到大量校正后的人脸照片,然后将校正后的人脸照片给到数据标注人员进行人脸角度(包含5个属性,分别是左大侧脸ll、左小侧脸lm、正脸f、右小侧脸rm和右大侧脸rl)和人脸模糊度标注(包含2个属性,清晰和模糊),进而得到大量具有人脸角度和人脸模糊度标签的数据,提取出全部的人脸模糊度标签为清晰的数据,然后使用基于然后使用基于opencv(基于bsd许可(开源)发行的跨平台计算机视觉库)的motionblur(运动模糊添加)和gaussianblur(运动模糊消除)将抽取出的清晰并且带有标注的人脸角度数据制造分不同程度可量化的模糊数据,即得到第二神经网络模型的训练数据;接着将标注好的数据及相对应的人脸角度和人脸模糊度量化标签输入第二神经网络模型中进行训练;本实施例的人脸角度和人脸模糊度分析的神经网络模型(第二神经网络模型)采用lightcnn模型作为特征抽取层,输入为128pixel×128pixel×3channel,输出为512维向量作为抽取的特征,本实施例中,在抽取的特征后面接着并行的两个分支,分别是人脸角度互斥类分支和模糊度的回归值分支,每个分支都使用512×256×n的全连接层(n代表每个大类内对应的小类数,例如人脸角度大类内分为5个小类,分别为左大侧脸ll、左小侧脸lm、正脸f、右小侧脸rm和右大侧脸rl,该分支就是512×256×5的结构),如果是人脸模糊度的回归值分支,则在最后采用sigmoid层将最终输出转化成概率值,如果是人脸角度互斥类分支,则在最后采用softmax层使得将输出转化成概率值并且本类内各个小类的概率和为1;
对于人脸角度分类,采用交叉熵celoss(crossentropyloss)作为损失函数,如下:
对于人脸模糊度回归值,采用均方差mseloss(meansquarederrorloss)作为损失函数,如下:
其中,在以上两个损失函数(5和(6)中,
经过大量训练调参,得到一个能够较为精确预测人脸角度和人脸模糊度的第二神经网络模型,用于人脸角度和人脸模糊度属性的分析。
s2.待检测图片提取:获取各种场景下摄像头内图片或/和视频数据(可存于数据库),从(数据库)中提取待检测的单张图片;具体的,可通过各种场景下的摄像头获取各种场景下摄像头内的录像数据,目前各种摄像头上的摄像头内的摄像头都有存档功能,可以在电脑上很方便的找到存储的各种场景下摄像头内的摄像头记录的视频;
s3.图片的人脸检测与矫正:通过训练好的第一神经网络模型对单张图片进行人脸检测,若未检测到人脸则返回步骤s2,若检测到人脸,则获取人脸框位置(x1,y1,x2,y2)及面部特征点位置,其中,x1和y1为人脸框的左上角的坐标;x2和y2为人脸框右下角的坐标;然后使用opencv库作为工具先读取图片,然后再读取对应这张照片中人脸框的位置及面部特征点位置,根据人脸框位置和面部特征点位置来矫正和截取对应矩形中的图片,得到大量校正后的人脸的照片,用于后面的人脸角度和人脸模糊度分析根据人脸框位置和面部特征点位置进行图片矫正和截取(剪切),获得矫正标准化的人脸图片;
s4.人脸角度和模糊度预测:如图5所示,使用第二神经网络模型对人脸图片进行分析,得到按照预设好的属性顺序对应的各项属性置信度,进而用于下一步的属性选择;再根据预设好的人脸角度和人脸模糊度顺序,先进行人脸角度属性选择,此时选择这个组内置信度最大的属性作为该组的最终选择结果输出,以代表人脸角度属性这个类别的预测值,后进行人脸模糊度回归值的预测,将模型预测的人脸模糊度的回归值作为人脸模糊情况的输出,并分别设定[0-0.15]为清晰,[0.15-0.35]为轻度模糊,[0.35-0.65]中毒模糊,[0.65-1]为重度模糊;
s5.属性输出:根据预设的人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度和人脸模糊度的回归值。
根据此上述方法预测输出的结果制定相应策略,可以满足一些需要判断人脸角度和人脸成像质量的需求场景,例如判断图片指令是否满足要求,可否用于与身份证图片进行人证比对等,若不可用,则返回步骤s2选择新的图片进行检测和分析。本发明的人脸角度及模糊度分析方法能有效快速准确的检测视频或/和图片内人脸位置及特征点并预测出其人脸角度和人脸模糊度,以帮助一些对人脸质量有要求的项目或者场景进行人脸图片质量分析,进而可以更好的分析和利用相关数据。
进一步的,上述根据人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度,包括:
将人脸角度属性归类为互斥类;互斥类的所有分支概率和为1.
输出互斥类中置信度最大的属性及对应的置信度。
进一步的,对于所述互斥类,采用交叉熵作为损失函数,如下:
对于模糊度回归,采用均方差作为损失函数,如下:
其中,
如图6所示,本发明还揭示了一种人脸角度和人脸模糊度分析系统,其包括:
模型训练模块100,用于训练人脸检测的基于深度学习的第一神经网络模型和人脸角度和人脸模糊度分析的第二神经网络模型;
图片提取模块200,用于获取摄像头内图片或/和视频数据,从中提取单张待检测图片;
人脸检测与矫正模块300,用于通过训练好的第一神经网络模型对单张图片进行人脸检测,获取人脸框位置和面部特征点位置;根据人脸框位置和面部特征点位置进行图片矫正和截取,获得矫正标准化的人脸图片;
角度及模糊度分析模块400,用于通过训练好的第二神经网络模型对矫正标准化的人脸图片进行人脸角度和人脸模糊度分析,获得人脸角度分类的置信度及人脸模糊度的回归值;
属性输出模块500,用于根据预设的人脸角度属性选择策略确定人脸角度属性,输出对应的属性及置信度和人脸模糊度的回归值。
本发明还提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时以实现上述的人脸角度和人脸模糊度分析方法。
上述说明示出并描述了本发明的优选实施例,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!