一种作品名称与多媒体文件的匹配方法及存储介质与流程
本发明涉及多媒体技术领域,特别是涉及一种作品名称与多媒体文件的匹配方法及存储介质。
背景技术:
在电影库或音乐库等多媒体软件的物理存储介质中,存储有大量的多媒体文件,并且需要不断的更新近期发布的多媒体文件(即新作品)。然而更新的多媒体文件是通过不同的渠道收集到的,由于不同的数据提供方对多媒体文件的命名规则通常是不同的,经常含有各种复杂的字符串;同时,多媒体文件还存在多种格式,例如mp4,avi,mkv,iso-dvd;因此导致很难将收集到的多媒体文件与列表中的作品名称对应起来。
专利号为cn201810814634.9,专利名称为《电影信息获取方法、装置及移动终端》公开了一种根据电影名称匹配影库的方法,该方法采用相关机器学习方法,做分词构造,将每个分词与影库中电影名称一一匹配,再定义一个阈值,评估每个分词的匹配度。这种方法对复杂的字符串如《十x面.y埋z伏》识别率低且耗时较高,而传统的字符串相似度算法(jaro–winkler,编辑距离等)也不适用于这种多媒体文件的名称含有复杂字符串的场景。
由于现有技术中没有成熟有效的匹配方案,能够准确、快速的将多媒体文件与作品名称对应起来,因此,在多媒体软件的数据整理或更新过程中,需要花费大量的时间进行匹配多媒体文件工作。
技术实现要素:
为此,需要提供一种作品名称与多媒体文件的匹配方法,用于解决上述现有技术难以准确、快速将多媒体文件与作品名称进行匹配的技术问题。
为实现上述目的,本发明提供了一种作品名称与多媒体文件的匹配方法,包括以下步骤:
获取作品名称和多媒体文件;
对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串;
将所述作品名称与过滤处理后的多媒体文件的名称进行匹配,得到匹配分数;
将匹配分数最高的所述多媒体文件与所述作品名称相关联。
进一步的,所述步骤“对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串”包括以下步骤:
对所述多媒体文件的名称进行过滤处理,去除所述多媒体文件的名称中所包含的除中文、英文字符、数字、‘(’、‘)’和‘:’之外的字符。
进一步的,所述步骤“对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串”包括以下步骤:
将所述多媒体文件的名称中的大写英文字符替换为对应的小写英文字符。
进一步的,所述步骤“对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串”包括以下步骤:
对所述多媒体文件的名称进行过滤处理,去除所述多媒体文件的名称中所包含的年份信息以及文件格式信息。
进一步的,所述步骤“对所述多媒体文件的名称进行过滤处理,去除所述多媒体文件的名称中所包含的年份信息以及文件格式信息”包括以下步骤:
以间隔符为分界,将所述多媒体文件的名称分割成两个以上的子字符串;
判断各子字符串是否为年份字符,若第二个子字符串或其之后的子字符串为年份字符,则去除该子字符串以及之后的其他子字符串。
进一步的,所述步骤“将所述作品名称与过滤处理后的多媒体文件的名称进行匹配,得到匹配分数”包括以下步骤:
将所述作品名称逐个字符与过虑处理后的所述多媒体文件的名称进行对比,判断所述作品名称中的字符是否存在于所述多媒体的名称中;
根据预设的匹配度计分机制以及各字符的对比结果逐一进行评分,将各所述评分相加得到所述多媒体文件的名称的匹配分数。
进一步的,所述预设的匹配度计分机制包括:
根据所述多媒体文件的名称中匹配的字符的类型,向所述匹配分数累加不同的第一分值,其中,第一分值为正数,并且中文字符的第一分值大于英文字符或数字字符的第一分值;
当所述多媒体文件的名称中存在连续匹配的字符,则再向所述匹配分数中累加第二分值,第二分值为正数且与连续匹配字符的个数正相关;
当所述多媒体文件的名称出现不匹配的字符,向所述匹配分数中累加第三分值,其中,第三分值为负数。
进一步的,所述预设的匹配度计分机制还包括:
累计所述多媒体文件的名称中匹配字符或字符串的间隔次数,当所述间隔次数超过预设值则结束匹配度计分。
进一步的,所述多媒体名称为电影或歌曲,所述作品名称与多媒体文件的匹配方法还包括步骤:
根据所述匹配分数由高至低显示所述多媒体文件或作品名称。
进一步的,为解决上述技术问题,本发明还提供了另一技术方案:
一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现以上任一项技术方案所述的步骤。
区别于现有技术,上述技术方案在为多媒体文件匹配信息时,对多媒体文件的名称进行过滤处理,以除去多媒体文件的名称中所包含的预设字符或字符串,然后再将过滤处理后的多媒体文件的名称与作品名称进行匹配,将匹配分数最高的所述多媒体文件与所述作品名称相关联。其中,对检索到的多媒体文件的名称进行过滤处理时,可滤除其中的无用字符,提升文件其可读性和匹配准确率,同时也减小匹配过程的数据处理量和耗时,提高匹配效率。
附图说明
图1为具体实施方式所述作品名称与多媒体文件的匹配方法的步骤流程图;
图2为具体实施方式对所述多媒体文件的名称匹配进行的流程图;
图3为具体实施方式所述匹配度计分机制的流程图;
图4为具体实施方式所述计算机可读存储介质框图。
具体实施方式
为详细说明技术方案的技术内容、构造特征、所实现目的及效果,以下结合具体实施例并配合附图详予说明。
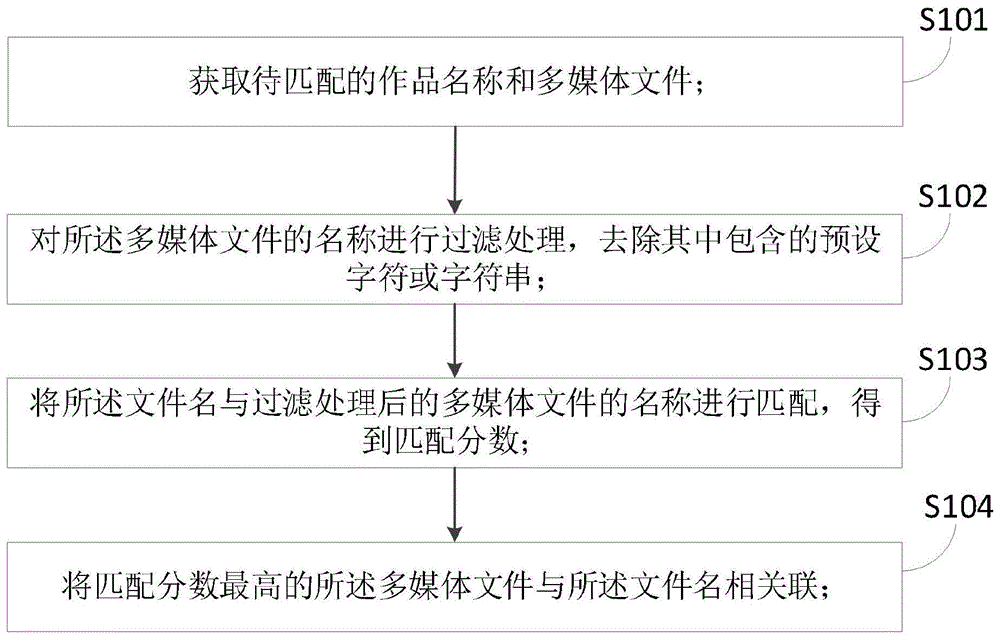
请参阅图1至图3,本实施例提供了一种作品名称与多媒体文件的匹配方法。所述作品名称与多媒体文件的匹配方法可用于对影库、音乐库等多媒体软件的存储介质中所存储的电影、音乐、mv等多媒体文件,与作品列表中的标准作品名称进行匹配。所述作品名称与多媒体文件的匹配方法包括步骤:
s101、获取作品名称和多媒体文件;其中,在获取作品名称和多媒体文件时,可一次获取多个作品名称和多个多媒体文件。所述作品名称为标准的多媒体作品的名称,例如所述作品名称可以为影库、音乐库等软件的播放列表中的作品名称(如电影名:十面埋伏,歌曲名:童话镇)。其中,作品名称可以在收集多媒体文件时一并收集到,例如,通过某一渠道收集到一批电影文件时,该渠道同时提供了这批电影的作品列表。所述多媒体文件可以为电影、音乐、mv等不同类型,并且,每种多媒体文件可以有多种不同的格式,例如,电影文件的格式可以包括mp4,avi,mkv,iso-dvd等。为了便于说明和理解,我们将所述作品名称定义为第一名称,将所述多媒体文件的名称定义为第二名称。由于新增的多媒体文件的命名是不规则的,与新增的作品列表中的作品名称无法直接关联,因此在使用时无法直接通过作品列表中的作品名称直接关联到对应的多媒体文件。因此,需要在使用前将作品列表中的作品名称与存储介质中的多媒体文件进行匹配。在获取作品名称和多媒体文件之后,即可进入步骤s102。
s102、对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串;其中,由于所述多媒体文件的名称中包含了除作品名称之外的其他信息,因此,为了提高匹配的准确性和时效性,在过滤处理时应能滤除与作品名称无关的信息,且要能保证不误将作品名称滤除。因此,所述预设字符或字符串应当为所表达的信息与多媒体文件的名称无关的字符或字符串,例如大部分的特殊字符,或包含有这些特殊字符的字符串。以电影为例,所述预设字符或字符串中可以包括年份字符、视频编码字符、分辨率字符、或文件格式字符等。在所述过滤处理之后进入步骤s103。
s103、将所述作品名称(即第一名称)与过滤处理后的多媒体文件的名称(即第二名称)进行匹配,得到匹配分数;其中,进行匹配时可以将过滤处理后的多媒体文件的名称(即过滤后的第二名称)与所述作品名称(即第一名称)逐一字符进行匹配,并根据匹配程度得到相应的匹配分数,匹配分数与匹配程度正相关,匹配程度越高,匹配分数也越高,反之亦然。经过匹配处理即可得出各多媒体文件的名称与所述作品名称的匹配分数,并可将各多媒体文件按匹配分数由高至低排列;获得得到各作品名称与过滤后的多媒体文件的名称的匹配分数,并可将作品名称按匹配分数由高至低排列。在得到匹配分数之后进入步骤s104。
s104、将匹配分数最高的所述多媒体文件与所述作品名称相关联,或将匹配分数最高的所述作品名称与所述多媒体文件相关联。因此,通过所述多媒体文件与所述作品名称进行关联,即可通过作品名称定位至对应的多媒体文件,在通过影库、音乐库等软件进行多媒体文件播放时,通过选择作品列表中的作品名称即可链接到对应的多媒体文件进行播放。并且可将该信息显示于终端,以便用户浏览。通过上述方法,可实现自动将存储介质中的多媒体文件与作品名称进行关联,无需用户手动操作,提高匹配效率。
该作品名称与多媒体文件的匹配方法对检索到的多媒体文件的名称(即第二名称)进行过滤处理时,可滤除其中的无用字符,提升多媒体文件的名称的可读性以及后续匹配步骤中匹配的准确率,同时也减小匹配过程的数据处理量和耗时,提高匹配效率。
在一实施例中,所述步骤:s102中“对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串”包括以下步骤:
对所述多媒体文件的名称进行过滤处理,去除所述多媒体文件的名称中所包含的除中文、英文字符、数字、‘(’、‘)’和‘:’之外的字符。该过滤步聚也称之为浅过滤,其主要是滤除名称中除中英文字符和数字外的所有特殊字符(保留‘(’和‘)’和‘:’)该过滤方式较为简单,便于实现,同时又能保留原有信息。为了便于后续的匹配步骤,在该实施例中,还可将信息中所有的大写英文字符字母转变为小写字母。
在另一实施例中,所述步骤:s102中“对所述多媒体文件的名称进行过滤处理,去除其中包含的预设字符或字符串”包括以下步骤:去除所述多媒体文件的名称中所包含的年份信息以及文件格式信息。由于多媒体文件的名称(即第二名称)中的年份信息或文件格式信息具有较为固定的格式,便于识别且与作品名称不相关,所以通过滤除年份信息以及文件格式信息可进一步简化所述多媒体文件的名称(即第二名称),从而减小匹配步骤的数据处理量,以及减小其与匹配精度的影响,提高匹配准确度。
发明人经过大量观察,发现保存在本地的多媒体文件特别是电影文件,其命名规则有一个共同点:多媒体文件的名称往往会出现在发行年份之前,并且中间如果有间隔符(如'.'或空格),则后面的字段几乎是为与文件的名称无用信息(如视频编码,分辨率,压缩小组,字幕信息等)。因此,在一实施例中,在去除所述多媒体文件的名称(即第二名称)中所包含的年份信息以及文件格式信息时,具体可以以间隔符为分界,将所述多媒体文件的名称(即第二名称)分割成两个以上的子字符串;并判断各子字符串内是否包含年份字符,若第二个子字符串或其之后的子字符串中包含有年份字符,则去除包含有所述年份字符的子字符串以及之后的其他子字符串,若年份字符作为第一子字符串出现在电影名之前,如《2017.十面埋伏.1080p》,则全部保留,其中,年份字符可通过正则表达式识别。这样即能删除多媒体文件的名称(即第二名称)中的年份字符,又能保留了以年份为电影名称的文件如《2012》。因此,该滤除方法数据处理量小,并且通过该过滤方式可滤掉大量无用信息,且尽可能只保留作品名称,极大加快匹配效率和准确性。对于电影库、音乐库这类软件的存储介质中有大量多媒体文件需要匹配,上述匹配方法就尤为适用。
如图2所示,在一实施例中,所述步骤s103“将所述作品名称(即第一名称)与过滤处理后的多媒体文件的名称(即第二名称)进行匹配,得到匹配分数”包括以下步骤:
s201、将所述作品名称(即第一名称)逐个字符与过虑处理后的所述多媒体文件的名称(即第二名称)进行对比,判断所述作品名称中(即第一名称)的字符是否存在于所述多媒体的名称(即第二名称)中;
s202、根据预设的匹配度计分机制以及各字符的对比结果逐一进行评分,将各所述评分相加得到所述多媒体文件的名称的匹配分数。
具体的,在进行所述作品名称(即第一名称)与所述多媒体文件的名称(即第二名称)对比时,可设置两个指针,一个指针用于所述作品名称(即第一名称),另一个指针用于所述多媒体文件的名称(即第二名称),两个指针的初始位置均分别指向起始位置(即第一个字符所在位置)。
在对比时,首先找到所述作品名称(即第一名称)的第一个字符在所述多媒体文件的名称(即第二名称)出现的位置,若出现,则所述多媒体文件的名称(即第一名称)对应的指针指向该位置,若不存在,则所述作品名称(即第一名称)指针下移一位,并寻找指针当前所指字符是否在所述多媒体文件的名称(即第二名称)出现,然后所述多媒体文件的名称(即第二名称)的指针指向该位置。依此类推将所述作品名称(即第一名称)中的每个字符逐一与所述多媒体作品名称中的各字符进行对比,直到找到初始匹配字符为止。
若在对比过程中,遇到两指针所指向的字符相同,则两个指针均下移一位;遇到两指针指向的字符不一致时,寻找所述作品名称(即第一名称)指向的字符在所述多媒体文件的名称(即第二名称)当前位置之后出现的位置,若存在,则所述多媒体文件的名称(即第二名称)指针指向该位置;若不存在,所述作品名称(即第一名称)指针下移一位,再寻找当前所述作品名称(即第二名称)指针指向的字符在所述多媒体文件的名称(即第二名称)的当前位置之后出现的位置,若存在,则所述多媒体文件的名称(即第二名称)指针指向该位置,否则匹配结束。两个指针如果有其中一个指针指向了末尾,则匹配结束。
在其他实施方式中,还提供了通过数组的方式实现所述作品名称与多媒体文件的名称对比,其中,可设置两个数组,并通过改变数组的下标来分别指向所述作品名称与多媒体文件的名称中的不同字符,通过数组实现字符对比的方案与上述通过指针实现对比的方案近似,这里就不再赘述。通过上述描述可知,在该匹配过程中,能够保证所述作品名称中每个字符都能够被扫描到并逐一与多媒体文件的名称中各字符进行对比,并且匹配度计分机制逐一对所述作品名称中各字符进行评分,从而保证所得到的匹配分数的可靠性。
考虑到作品名称中不同类型的字符对匹配度具有不同的权重,为了提高作品名称匹配的准确度,如图3所示,在一实施例中提供了一种匹配度计分机制,所述预设的匹配度计分机制包括:
s301、根据所述多媒体文件的名称中匹配的字符的类型,向所述匹配分数累加不同的第一分值,其中,第一分值为正数,并且中文字符的第一分值大于英文字符或数字字符的第一分值;
s302、当所述多媒体文件的名称中存在连续匹配的字符,则再向所述匹配分数中累加第二分值,第二分值为正数且与连续匹配字符的个数正相关;
s303、当所述多媒体文件的名称出现不匹配的字符,向所述匹配分数中累加第三分值,其中,第三分值为负数。
为了便于计分,可以设定一个初始匹配分数,以及间隔次数(即先后两个匹配的字符中间出现不匹配字符就计为间隔一次),例如初始匹配分数设置为10分,无上限,间隔计数初始为0。
当匹配一个中文字符或保留的特殊符号(即(’、‘)’和‘:’)时,均在基础分上加第一分值(例如5分);
当匹配一个英文字符或数字字符时,均在基础分上加第一分值(例如2分);
当非英文字符或数字字符,每连续匹配时,均在基础分上加分(即第一分值)的前提上,再加连续匹配次数分(即第二分值)。如连续匹配三次,则三次总共加5+(5+1)+(5+2)=18分;
当遇到一个不匹配字符(不区分中英文字符,数字以及其他符号),均加第三分值(例如-5分,即扣5分)。
在匹配结束时,匹配分数若大于0,返回当前匹配分数和相同字符的个数(称作匹配个数);否则匹配失败。匹配失败的作品名称或多媒体文件会被抛弃。
在该匹配度计分机制中,匹配的中文字符以及保留的特殊符号所赋予的第一分值,大于匹配的英文字符或数字字符所赋予的第二分值,因此突出中文字符在作品名称匹配度中重要性;并且当出现连续匹配的字符时,在累加第一分值的基础上,额外累加了第二分值,突出字符连续匹配对作品名称匹配度的重要性,该匹配度计分机制将两者结合,提高多媒体文件的名称匹配的准确度。
在一实施列中,所述预设的匹配度计分机制还包括:
累计所述多媒体文件的名称(即第二名称)中匹配字符或字符串的间隔次数,当所述间隔次数超过预设值则结束匹配度计分。
例如,在所述作品名称(即第一名称)与多媒体文件的名称(即第二名称)对比过程中,如果遇到两个字符串不匹配,则间隔数加1,一旦间隔次数达到预设值例如3次,则判定为匹配失败,并结束该次匹配。通过该匹配度计分机制累计间隔次数,能够提前判定匹配结果是否失败,并提前结束该匹配的计分过程,从而减少时间浪费,提高匹配时效。
当系统批量下载大量多媒体文件,并同时获取对应的作品名称时,在上述匹配度计分机制中,可以以作品名称(即第一名称)为标准,对多个不同的多媒体文件的名称(即第二名称)与该作品名称(即第一名称)的匹配度进行打分(即计算不同的多媒体文件的名称的匹配分数),而在数据库中将匹配分数最高的多媒体文件与该作品名称(即第一名称)建立关联,即该匹配分数最高的多媒体文件就是该作品名称所对应的文件。采用该技术方案,可实现自动对批量多媒体文件进行作品名称的匹配。
当系统只增加一件多媒体文件时,在上述匹配度计分机制中,也可以以多媒体文件的名称(即第二名称)为标准,对多个不同的作品名称(即第一名称)与该多媒体文件的名称(即第二名称)的匹配度进行打分(即计算不同的作品名称的匹配分数),而在数据库中将匹配分数最高的作品名称与该多媒体文件建立关联。采用该技术方案,可实现对新增的多媒体文件自动匹配作品名称。
在一些实施例中,所述预设的匹配度计分机制还可包括前缀约束,所述前缀约束具体为:判断作品名称(即第一名称)的前缀不匹配数是否超过预设值(例如两次),若是,则直接判定匹配失败;若否,则每一个不匹配扣除一定分值(例如4分)。其中,在对比开始时,如果所述作品名称(即第一名称)中从第一个字符连续多个字符,均在所述多媒体文件的名称(即第二名称)中找不到匹配的字符,则作品名称中连续不匹配字符的个数即为所述作品名称的前缀不匹配数,例如,作品名称为“天下无贼”,而多媒体文件的名称为“十面埋伏”,此时作品名称中的各字符均匹配不同,其前缀不匹配数为4;当作品名称“新警察故事”,而多媒体文件的名称为“海豚的故事”,此时作品名称中第四个字符才匹配的到,之前的三个字符均匹配不到,因此其前缀不匹配数即为3。通过该前缀约束也可提前判定匹配失败,并提前结束该匹配的计分过程,从而减少时间浪费,提高匹配时效。
在该匹配度计分机制中,还可对完全匹配的多媒体文件的名称在连续匹配加分基础上,另多加一定的分值(例如10分)。
在一实施例中,是以多媒体文件的名称为标准,对多个不同的作品名称进行匹配计分,因此在该实施例中,在根据所述匹配度计分机制对各作品名称进行匹配计分后,使用堆排序法将所有通过匹配并具有匹配分数的作品名称按匹配分数高到低做排序,并选出前若干个结果;然后遍历每个作品名称,计算匹配的作品名称的数量(记为a),并将每个匹配的作品名称中匹配的字符个数(记为l)除以匹配的作品名称的数量(即l/a),如果得到的值小于某个阈值(通常设计为0.8,也可以按实际情况设计),则抛弃该结果。将最后将得到的作品名称重排序之后,并将排在第一位的作品名称与多媒体文件关联。
在另一实施例中,是以作品名称为标准,对多个不同的多媒体文件的名称进行匹配计分,因此在该实施例中,在根据所述匹配度计分机制对各多媒体文件的名称进行匹配计分后,使用堆排序法将所有通过匹配并具有匹配分数的多媒体文件的名称按匹配分数高到低做排序,并选出前若干个结果;然后遍历每个多媒体文件的名称,计算匹配的多媒体文件的名称的数量(记为a),并将每个匹配的多媒体文件的名称中匹配的字符个数(记为l)除以匹配的多媒体文件的名称的数量(即l/a),如果得到的值小于某个阈值(通常设计为0.8,也可以按实际情况设计),则抛弃该结果。将最后将得到的多媒体的名称重排序之后,并将排在第一位的多媒体与作品名称关联。
在另一实施例中,提供了一种计算机可读存储介质400,计算机可读存储介质上存储有计算机程序,所述程序被处理器执行时实现以上任一项实施例中的步骤。优选的,所述计算机可读存储介质400为ktv、喝吧等数字娱乐场所中多媒体点播系统的可读存储介质。
需要说明的是,尽管在本文中已经对上述各实施例进行了描述,但并非因此限制本发明的专利保护范围。因此,基于本发明的创新理念,对本文所述实施例进行的变更和修改,或利用本发明说明书及附图内容所作的等效结构或等效流程变换,直接或间接地将以上技术方案运用在其他相关的技术领域,均包括在本发明的专利保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!