本发明涉及学生网络的知识融合方法。
背景技术:
场景语义分割是对图像进行像素级别的标签分类。目前场景语义分割的主流方法为使用卷积神经网络。现有的深度网络模型主要有pspnet,refinenet,finernet,segnet。其中pspnet使用金字塔池化操作获得多尺度特征;refinenet使用多通路的网络结构,融合低层特征与高层语义特征;finernet通过级联一系列的网络,得到不同粒度的语义图;segnet则使用编码器-解码器结构。其中segnet网络鲁棒性强,性能先进,故使用该网络为本专利技术的基本网络结构。
早期深度估计方法使用手工定义的特征和图模型,如将深度问题转化为马尔可夫条件随机场问题,这些方法性能不佳。目前方法主要采用卷积神经网络,自动学习不同特征。如使用多尺度深度网络,预测粗粒度深度,随后细化。另有其他方法将深度估计问题与场景语义分割、表面法向量预测任务结合,进行多任务预测。深度估计问题与场景语义分割问题的主要区别在于,前者的输出为连续的正数,后者输出为离散的标签。本专利技术中,将深度估计问题转化为分类问题,将深度划分为n个范围,预测落在各个范围中心部分的概率,计算得到连续的深度值,得到深度估计教师网络。
表面法线预测是对图像进行逐像素的表面法向量预测。表面法线经常在计算机图形学中用于计算光照。现有的法线预测神经网络模型中使用rgb图像或rgb-d图像作为输入。
知识蒸馏技术能够学习事先训练好的深度网络教师模型,通过训练软目标得到一个精简的低复杂度学生网络。该学生网络能够达到与教师网络相近,甚至更高的性能。知识蒸馏技术能够有效利用现有的深度网络模型,一定程度上减轻深度学习领域中标签数据不足的问题。该技术应用于计算机视觉领域的分类问题时主要有两种方式:一种使用单个教师网络,或一组同类别分类的教师网络,得到低复杂度学生网络;另一种通过学习多个分类不同类别的教师网络,得到能够处理复杂分类任务的学生网络。该技术还可应用于目标检测、深度估计以及自然语言处理的序列模型等,可以达到超越教师网络的性能。目前该技术目前的局限性在于只能学习单个教师网络,或一组同任务类型的教师网络,得到的学生网络无法处理多任务。
技术实现要素:
本发明要克服传统知识蒸馏只能学习单个任务的缺陷,以及多任务视觉应用场景中计算资源不足的的不足,在使用无标签数据集、保证学生网络规模不大的基础上,提供一种通过投射融合特征,训练得到多功能高精度学生网络的办法,能够融合多个不同任务的教师网络。
本发明是一种使用针对不同任务的多个教师网络,通过投射融合特征的训练紧凑多功能学生网络的知识融合方法。本发明的通过投射特征训练多任务学生网络的知识融合方法,包括如下步骤:
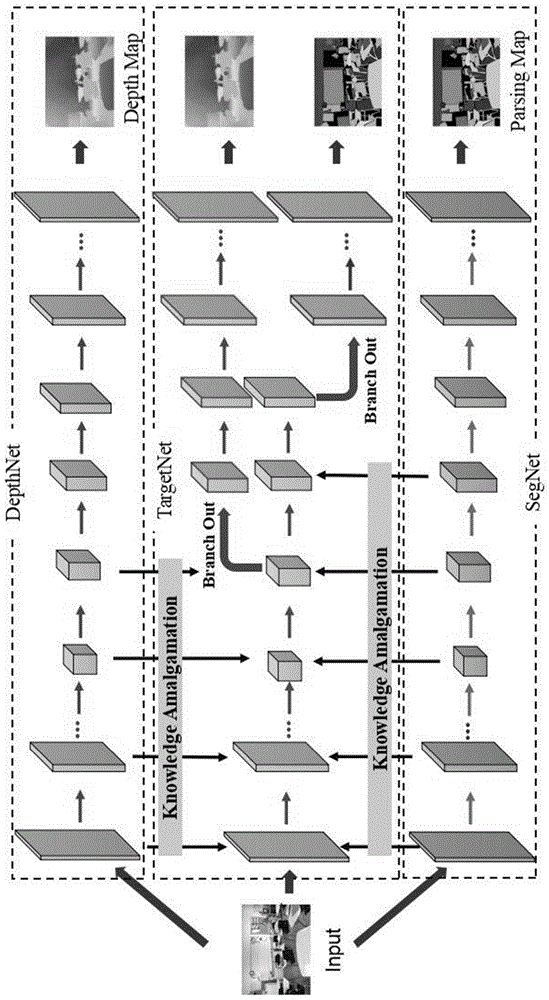
1)初始化目标网络targetnet结构,与教师网络相同;
网络使用编码器-解码器结构,编码器中block由卷积层和池化层组成,解码器中block由卷积层和上采样层构成。为targetnet的第n个block输出的融合特征图,使用不同的通道编码将转化为不同任务域中的特征fus和fud。
2)逐个训练targetnet的block,得到融合特征图
对双任务教师网络,将无标记样本输入教师网络segnet和depthnet,得到不同任务的特征图和将教师网络的对应block的和分别替换为fus和fud,替换后通过segnet得到预测分割depthnet得到预测深度最后对于预测值和教师网络原有预测结果s,d,建立损失函数对于多任务教师网络(加入normnet为例),一种方法使用不同通道编码映射并通过normnet得到预测法向量建立损失函数另一种用已训练好的分割与深度估计学生网络targetnet-2和normnet作为教师网络,根据步骤1.2)为学生网络targetnet-3引入通道编码u-channelcoding,映射为m-channelcoding映射为随后将根据步骤1.2)和步骤2.1)得到将根据步骤2.1)得到建立损失函数
3)确定targetnet中不同任务的各自分支位置;
根据步骤2)中每个block的最终loss,对不同任务选择分支点p:p=argminnln
4)使用教师网络中的对应分支作为学生网络的分支;
确定不同任务的分支位置后,移除targetnet中从靠后的分支点到网络末尾之间的所有block。不同任务的分支使用对应教师网络中block,得到最终的targetnet结构。使用步骤2)中的损失函数,利用梯度下降调优targetnet。
本发明具有的有益效果是:与现存的只能学习单个教师网络,或多个同任务教师网络的知识蒸馏方法相比,能够融合不同任务的教师网络知识,得到轻量级、高性能、多任务的学生网络;在需要部署多任务神经网络的应用场景中,能够大幅度减少机器计算资源、内存空间的消耗,同时能够保证每个任务的高精确度。
附图说明
图1为本发明实施例中的双教师网络知识融合的神经网络示意图。
图2为本发明实施例中的双教师网络知识融合方法融合学习学生网络特征的示意图。
图3为本发明实施例中的多教师网络知识融合方法二的通道编码示意图。
图4为本发明实施例中的学生网络结果与真值、教师网络的效果对比图。
具体实施方式
下面结合附图进一步说明本发明的技术方案。
本发明的一种使用针对不同任务的多个教师网络,通过投射特征训练多任务学生网络的知识融合方法,包括如下步骤:
1.初始化目标网络targetnet结构,与教师网络相同;
为了保证学生网络足够小,并同时能够拥有与教师网络相近的性能,设置目标网络targetnet结构具体包括:
1.1.初始化学生网络的结构为与教师网络相同的编码器-解码器结构。编码器中的每个block由两到三个卷积核大小为3x3的卷积层和一个2x2不重叠的最大池化层构成。解码器中的每个block由两到三个卷积核大小为3x3的卷积层和一个上采样层构成。
1.2.为targetnet的第n个block输出的融合特征图,编码了多个任务的特征。对每个教师网络,均引入通道编码。使用不同的通道编码,转化为不同任务域中的特征。对于场景分割(segnet)和深度估计(depthnet)双任务教师网络,通过s-channelcoding映射为分割任务的特征fus,通过d-channelcoding映射为深度估计任务的特征fud。
2.逐个训练targetnet的block,得到融合特征图
2.1.对于双任务教师网络,将无标记样本输入教师网络segnet和depthnet,分别对第n个block得到分割任务特征图和深度估计任务特征图融合和时,一种直观思路为采用欧氏距离作为损失函数。这种方法严重浪费时间与计算力。为了减少繁琐的融合过程,使用一种与教师网络关系密切的训练方法,具体包括:首先将通过步骤1.2)的通道编码分别得到fus和fud;其次将教师网络的对应block的和分别替换为fus和fud,替换后通过segnet得到预测分割depthnet得到预测深度最后对于预测值和教师网络原有预测结果s,d,建立损失函数
其中λ1,λ2为定值权重,lseg,ldepth分别为segnet,depthnet的损失函数。逐block进行梯度下降。
2.2.对于多任务教师网络(以加入表面法向量估计normnet为例),有两种方法:一种根据步骤1.2)引入normnet的通道编码m-channelcoding,映射并通过normnet得到预测法向量建立损失函数
其中λ1,λ2,λ3为定值权重,lnorm为normnet的损失函数,逐block进行梯度下降。另一种使用已训练好的分割与深度估计学生网络targetnet-2和normnet作为教师网络,根据步骤1.2)为学生网络targetnet-3引入通道编码u-channelcoding,映射为m-channelcoding映射为随后将根据步骤1.2)和步骤2.1)得到将根据步骤2.1)得到建立损失函数
其中λ1,λ2为定值权重,lu2为步骤2.1)中损失函数。
3.确定targetnet中不同任务的各自分支位置
根据步骤2.1)获取每个block的最终loss,
对不同任务选择分支点pseg,pdepth,(pnorm):
其中使所有分支点处于解码器结构内。
4.使用教师网络中的对应分支作为学生网络的分支;
根据步骤3.确定pseg,pdepth后,移除targetnet中从靠后的分支点到网络末尾之间的所有block。pseg,pdepth之后的block使用对应教师网络中block作为分支,得到最终的targetnet结构。使用步骤2中的损失函数,利用梯度下降调优targetnet。
通过上述步骤,可以利用多个不同任务的教师网络得到一个性能更优,规模较小的多任务学生网络。除上述的场景分割、深度估计、表面法向量预测任务之外,还可以应用于其他计算机视觉任务。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围的不应当被视为仅限于实施例所陈述的具体形式。相反,本发明涵盖任何由权利要求定义的在本发明的精髓和范围上做的替代、修改、等效方法以及方案。