一种基于可逆网络的单一图像超分辨率方法与流程
本发明涉及一种基于可逆网络的单一图像超分辨率方法,属于图像处理领域。
背景技术:
图像超分辨率(imagesuperresolution)是指由一幅低分辨率图像或图像序列恢复出高分辨率图像。单一图像超分辨率(singleimagesuperresolution,sisr)则是在低分辨率图像和高分辨率图像之间建立一种映射,并通过输入的低分辨率图像生成超分辨率图像。目前超分辨率的方法主要包括基于插值,基于重建,基于学习的方法。常见的插值方法有双线性插值,双三次插值方法等,但是通过插值得到的重建图像容易产生模糊、锯齿现象,并且缺少纹理细节。基于重建的方法是利用低分辨率图像作为约束的前提下,结合图像的先验知识进行重建还原,例如迭代反向投影法,凸集投影法。而基于学习的方法是通过提取高分辨率图像和低分辨率图像的特征学习两者之间的映射关系来对高分辨率图像进行重建,这也是目前比较主流的方法。研究者们提出了很多的基于学习的重建方法,例如邻域嵌入方法,概率图模型,线性及非线性回归,稀疏编码以及随机森林。
近些年,随着深度神经网络的飞速发展,越来越多的研究人员开始使用各种深度神经网络结构来解决超分辨率问题。相对于其他传统的超分辨率方法,具有深度神经网络结构的超分辨率重建方法能够取得更高的psnr(峰值信噪比,db)和ssim(结构相似性)值。超分辨率卷积网络(dongc,chencl,hek,etal.imagesuper-resolutionusingdeepconvolutionalnetworks[j].ieeetransactionsonpatternanalysis&machineintelligence)较早提出利用深度卷积网络来解决超分辨率重建问题,其设计了由三个卷积核大小不同的卷积层构成的网络,将三层卷积网络分别解释为三个步骤:补丁提取,非线性映射,图像重建。在图像输入到srcnn中去之前,会经过一个基于插值的超分辨率过程将其尺寸放大到预期尺寸。espcn(shiw,caballeroj,huszarf,etal.real-timesingleimageandvideosuper-resolutionusinganefficientsub-pixelconvolutionalneuralnetwork[c].computervisionandpatternrecognition)提出了一种新的扩张图像尺寸的结构:亚像素卷积层,通过减少图像的通道数增加图像的尺寸。srgan(ledigc,wangz,shiw,etal.photo-realisticsingleimagesuper-resolutionusingagenerativeadversarialnetwork[c].computervisionandpatternrecognition.)利用残差神经网络来设计超分辨网络结构,通过结合对抗学习和迁移学习取得了杰出的感知表现。
上述基于深度神经网络的图像超分辨算法相对于其他算法能够取得更好的效果,但这些方法都是将低分辨率图像投影到高分辨率图像空间来估计一个超分辨率图像,然后利用超分辨率图像和估计的高分辨率图像之间的差异来构建损失函数并进行优化,没有利用低分辨率图像和高分辨率图像之间的相互依赖,无法更有效地利用两个图像之间的互信息,从而影响了模型图像超分辨的效果。
技术实现要素:
为了解决目前存在的现有技术没有利用低分辨率图像和高分辨率图像之间的相互依赖,无法更有效地利用两个图像之间的互信息,从而影响了模型图像超分辨的效果问题,本发明提供了一种基于可逆网络的单一图像超分辨率方法,所述方法利用可逆网络构建进行超分辨率的网络模型,然后将低分辨率图像输入到网络模型的一端生成超分辨率图像,将高分辨率图像输入到网络模型的另一端生成低分辨率重建图像,利用生成的超分辨率图像以及低分辨率重建图像与真实的高分辨率图像以及低分辨率图像之间的差异来设计优化的目标函数,通过最小化目标函数的值来对网络模型的参数进行更新,以提升网络模型的超分辨能力。
可选的,所述方法包括:
(1)选择训练数据集d:选择一个用来训练网络模型的数据集d,该数据集d需包括多张尺寸为w×h×c的低分辨率图像和对应的尺寸为rw×rh×c的高分辨率图像,其中w、h以及c分别为图像的宽度、高度以及通道数,r为超分辨率因子;
(2)建立可逆模块:可逆模块由位于两端的1×1可逆卷积层和位于中间的仿射耦合层组成,其中仿射耦合层按以下步骤计算得到:
仿射耦合层正向过程:对于尺寸为
y1=x1(1)
y2=x2·exp(f(x1))+g(x1)(2)
其中,f(x1)和g(x1)分别代表没有限制且不改变数据尺寸的非线性映射;将得到的y1和y2在通道处进行拼接得到尺寸为
仿射耦合层逆向过程:对于尺寸为
x′1=y′1(3)
x′2=(y′2-g(y′1))/exp(f(y′1))(4)
将得到的x′1和x′2在通道处进行拼接得到尺寸为
(3)建立网络模型:网络模型由24个步骤(2)建立的可逆模块组成;
(4)建立批数据:从数据集d中随机选择16个高分辨率图像进行拼接得到尺寸为16×rw×rh×c的高分辨率图像批数据ihr_b,将对应的16个低分辨率图像进行拼接得到尺寸为16×w×h×c低分辨率图像批数据ilr_b;
(5)数据预处理:对尺寸为16×w×h×c的低分辨率图像批数据ilr_b进行基于双立方插值的超分辨率处理将其尺寸放大为16×rw×rh×c,然后利用亚像素卷积操作将尺寸调整为
(6)生成重建图像:将尺寸为
(7)计算优化目标值:利用得到的超分辨率图像批数据ihr_b_re与真实高分辨率图像批数据ihr_b确定高分辨率图像空间的损失函数:
其中,x和y分别表示图片中单个像素的横坐标和纵坐标;
利用得到的低分辨率重建图像ilr_b_re和真实的低分辨率图像ilr_b确定低分辨率图像空间的损失函数:
将高分辨率图像空间和低分辨率图像空间的损失函数进行加权得到网络模型的优化目标:
其中λ1和1-λ1分别代表了高分辨率图像空间损失函数和低分辨率图像空间损失函数的权重,0.4<λ1<1;
(8)更新网络模型的参数:利用批数据作为输入得到的loss对网络模型的所有参数wm进行求导得到wm关于loss的导数δwm,然后利用梯度下降法以α=0.0001以及下述公式(8)对网络模型参数进行更新:
wm=wm-α·δwm(8)
(9)跳转至步骤(4),并在迭代次数达到10万后将α减半,在迭代次数达到20万次时结束迭代,得到训练好的网络模型;
(10)将需要进行超分辨率的低分辨率图像输入到训练好的网络模型的低分辨率一端,由网络模型的高分辨率一端生成超分辨率图像。
可选的,步骤(2)所述的可逆模块中的1×1可逆卷积层按以下步骤计算得到:
(2.1)1×1可逆卷积正向过程:对于尺寸为
(2.2)1×1可逆卷积逆向过程:对于尺寸为
增加
可选的,所述用来训练网络模型的数据集d中至少包括4000张尺寸为w×h×c的低分辨率图像和对应的尺寸为rw×rh×c的高分辨率图像。
可选的,步骤(7)中λ1的取值范围为0.4<λ1<0.6。
可选的,λ1取值0.5。
可选的,步骤(8)中梯度下降法包括随机梯度下降法和momentum梯度下降法。
可选的,步骤(8)中梯度下降法α取值范围为[0.00005,0.0005]。
本申请还提供上述方法在图像处理领域内的应用。
本申请还提供上述方法在监控设备、卫星图像和医学影像领域内的应用。
本发明有益效果是:
通过引入可逆网络来构建超分辨率模型的网络结构,利用可逆网络的可逆性质实现了高分辨率图像空间和低分辨率图像空间的相互映射,从低分辨率和高分辨率两个方向对超分辨率过程进行优化,解决了其他基于深度学习的超分辨率方法无法有效利用高分辨率和低分辨率图像之间的相互依赖的问题,从而提升了模型进行图像超分辨率的能力。还通过引入奇异值分解初始化1×1可逆卷积层的权重矩阵,提升了1×1可逆卷积层的逆过程的传播速度;采用本申请方法建立的网络模型生成的超分辨率图像能够得到更清晰的纹理结果以及更好的视觉效果,从而更好的满足监控设备、卫星图像以及医学影像等领域对超分辨图像更严格的要求。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
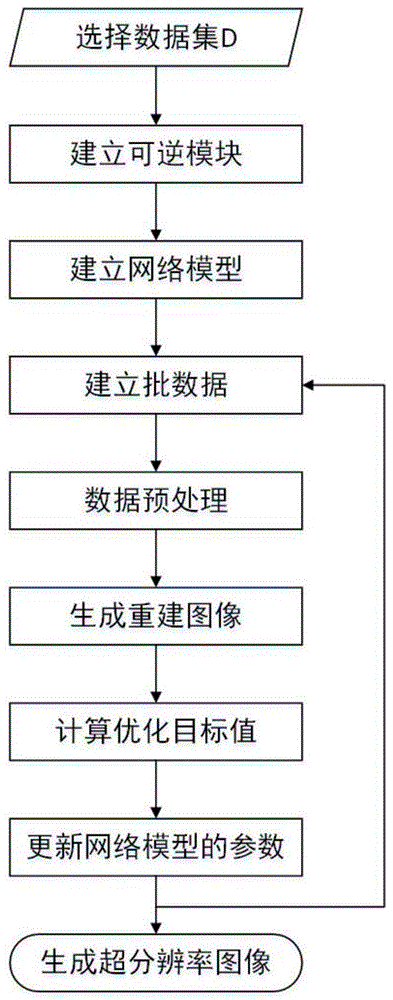
图1是本发明方法的整体流程图。
图2是可逆模块结构图。
图3是模型整体结构图。
图4是从基准数据集set5中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
图5是从基准数据集set14中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
图6是从基准数据集bsd100中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
首先对本申请涉及的可逆网络进行介绍如下:
可逆网络是具有可逆结构的网络。对于可逆网络来说,输入数据经正向传播得到输出后,可以通过逆向传播由输出以相反的过程得到最初的输入数据,在这个过程中输入数据没有任何信息的丢失。
较早前,就有论文应用神经网络中的某些可逆特性,例如利用随机梯度下降的可逆性质对模型的超参数进行微调。近些年,又出现了很多研究与利用可逆网络的论文。nice(l.dinh,d.krueger,y.bengio,nice:non-linearindependentcomponentsestimation,arxiv)和rnvp(l.dinh,s.d.jascha,s.bengio.densityestimationusingrealnvp.arxiv)将可逆网络与最大似然估计相结合提出了基于流的生成模型,利用网络的可逆特性,通过最大化生成过程的逆过程得到的潜变量的对数似然函数值来优化模型生成能力与拟合真实数据分布的能力。nice提出了一种耦合层的结构来实现可逆。在加性耦合层中,每一层的输入x从通道或者空间上被分成两个部分x1和x2,通过下面公式计算输出:
y1=x1
y2=x2+f(x1)
将y1和y2拼接得到输出y。在网络逆向传播时,将该层输出y以与拼接相反的方式分成两个部分y1和y2,通过下面公式得到输入x:
x1=y1
x2=y2-f(y1)
在rnvp中,作者首先引入了卷积操作,为了保证卷积操作所需的局部相关性,只能对图像进行通道处或空间棋盘式分割。其次,作者提出了更为一般的仿射耦合层。在仿射耦合层中,在每一层输入被分割成两部分x1和x2后,通过下面公式得到输出y:
y1=x1
在逆向传播时,将y分割成y1和y2,通过下面公式得到输入x:
x1=y1
x2=(y2-g(y1))/exp(f(y1))
其中
实施例一:
本实施例提供一种单一图像超分辨率方法,参照图1,本发明的具体实施步骤包括如下:
步骤1.选择训练数据集d:选择一个用来训练网络模型的数据集d,该数据集需包括多张尺寸为w×h×c的低分辨率图像和对应的尺寸为rw×rh×c的高分辨率图像,其中w、h以及c分别为图像的宽度、高度以及通道数,r为超分辨率因子;
深度学习要求训练数据集的样本越多越好,越多效果会越好,本实施例中提高一个经验参考值,训练数据集d至少包含4000张以上的满足上述要求的图像。
步骤2.建立可逆模块:可逆模块由位于两端的1×1可逆卷积层和位于中间的仿射耦合层组成;
其中1×1可逆卷积层按以下步骤计算得到:
(2.1)1×1可逆卷积正向过程:对于尺寸为
(2.2)1×1可逆卷积逆向过程:对于尺寸为
增加
其中可逆模块中的仿射耦合层正向和逆向过程按以下步骤计算得到:
(2.3)仿射耦合层正向过程:对于尺寸为
y1=x1(1)
y2=x2·exp(f(x1))+g(x1)(2)
其中,f(x1)和g(x1)分别代表着没有限制的不改变数据尺寸的非线性映射;将得到的y1和y2在通道处进行拼接得到尺寸为
(2.4)仿射耦合层逆向过程:对于尺寸为
x′1=y′1(3)
x′2=(y′2-g(y′1))/exp(f(y′1))(4)
将得到的x′1和x′2在通道处进行拼接得到尺寸为
步骤3.建立网络模型:网络模型由24个可逆模块组成;
步骤4.建立批数据:从数据集d中随机选择16个高分辨率图像进行拼接得到尺寸为16×rw×rh×c的高分辨率图像批数据ihr_b,其中b=16表示批数据中所含图像的数量,将对应的16个低分辨率图像进行拼接得到尺寸为16×w×h×c低分辨率图像批数据ilr_b;
步骤5.数据预处理:对尺寸为16×w×h×c的低分辨率图像批数据ilr_b进行基于双立方插值的超分辨率处理将其尺寸放大为16×rw×rh×c,然后利用亚像素卷积操作将其尺寸调整为
步骤6.生成重建图像:将尺寸为
步骤7.计算优化目标值:利用得到的超分辨率图像批数据ihr_b_re与真实高分辨率图像批数据ihr_b确定高分辨率图像空间的损失函数:
其中,x和y分别表示图片中单个像素的横坐标和纵坐标。
利用得到的低分辨率重建图像ilr_b_re和真实的低分辨率图像ilr_b确定低分辨率图像空间的损失函数:
将高分辨率图像空间和低分辨率图像空间的损失函数进行加权得到网络模型的优化目标:
其中λ1和1-λ1分别代表了高分辨率图像空间损失函数和低分辨率图像空间损失函数的权重,0.4<λ1<1
步骤8.更新网络模型的参数:利用梯度下降法以α=0.0001为学习率更新网络模型的参数来减小优化目标值loss;(8.1)更新网络模型的参数:利用批数据作为输入得到的loss对网络模型的所有参数wm进行求导得到wm关于loss的导数δwm,然后利用梯度下降法以α=0.0001以及下面的公式对进行网络模型参数进行更新:
wm=wm-α·δwm(8)
步骤9.跳转至步骤4,并在迭代次数达到10万后将α减半,在迭代次数达到20万次时结束迭代,得到训练好的网络模型;
其中的梯度下降法包括随机梯度下降法和momentum梯度下降法,α取值范围为[0.00005,0.0005],本申请以采用梯度下降法以α=0.0001为例进行说明,且α=0.0001效果较好。
步骤10.将需要进行超分辨率的低分辨率图像输入到训练好的网络模型的低分辨率一端,由网络模型的高分辨率一端生成超分辨率图像。
为进一步说明本发明的效果,下述通过仿真实验进一步说明:
1、仿真条件及参数
在整个实验中,本申请采用的超分辨率因子为4×,表示4倍,即r为4。所使用的训练图片来自于raise(http://mmlab.science.unitn.it/raise/)数据集,该数据集包括了8156对低分辨率图片以及其对应的高分辨率图片。其中低分辨率图片是由高分辨率图片经过一个缩放因子为4的双三次插值缩放得到。
本实验中,步骤2中的目标损失函数中的权重因子λ1为0.5。
选择set5,set14和bsd100三个基准数据集生成超分辨率图像以验证本申请提出的方法。
2、仿真内容及结果分析
仿真实验中,将本发明方法与其他一些基于插值、基于重建以及基于深度学习的超分辨率方法进行对比分析,试验主要从以下方面开展。
实验1:生成超分辨率图像在超分辨率评价指标上的对比,超分辨率评价指标包括峰值信噪比psnr和结构相似性ssim,这两个值代表重建图像的像素值和原始图像像素值的接近程度;2个图像之间psnr值越大,则越相似。ssim取值范围为[0,1],值越大,表示图像失真越小。
将本发明方法中训练好的模型生成的超分辨率图像与其他方法生成的超分辨率图像进行超分辨率评价指标上的定量对比:
表1:在基准数据集set5上本发明方法与其他方法的对比
表2:在基准数据集set14上本方法与其他方法的对比
表3:在基准数据集bsd100上本方法与其他方法的对比
如表1所示:我们的方法在psnr上略低于srcnn和kim,高于其他方法;在ssim上我们的方法高于其他所有方法。
如表2、表3所示:我们的方法在psnr和ssim上都高于其他所有方法。
综合表1、表2、表3,通过生成的超分辨率图像的定量对比可知,本申请提供的方法能够取得较好的超分辨率效果。
实验2:生成的超分辨率图像在视觉效果上的对比
将本发明方法中训练好的模型生成的超分辨率图像与其他方法生成的超分辨率图像进行视觉上的对比:
图4是从基准数据集set5中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
图5是从基准数据集set14中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
图6是从基准数据集bsd100中选择的图像在本发明方法训练好的模型中生成的超分辨率图像与在其他方法中得到的超分辨率图像的视觉对比图。
由图4可以看出:在set5数据集蝴蝶图像上,相对于我们的方法所生成的超分辨率图像,nearest方法生成的图像在蝴蝶条纹处具有严重的锯齿纹理,而bicubic和glasner方法生成的图像更加模糊,而scsr、srcnn以及kim等方法生成的图像在蝴蝶的条纹两边具有伪影效果。
由图5可以看出:在set14数据集斑马图像上,相对于我们的方法所生成的超分辨率图像,nearest方法生成的图像在斑马身上黑白条纹处具有严重的锯齿纹理,bicubic、scsr、srcnn以及kim方法所生成的图像在斑马身上条纹上具有间断在原图中没有的黑色阴影块,而glaster方法生成的图像具有比原图更细的斑马条纹。
由图6可以看出:在bsd100数据集的鱼图像上,相对于我们的方法所生成的超分辨率图像,nearest方法生成的图像具有严重的锯齿纹理,bicubic、glaster、scsr以及srcnn生成的图像在鱼头上的白色条纹上都具有原图所没有的黑色阴影块,而kim方法生成的图像则在鱼头的白色条纹两边具有伪影效果。
通过生成的超分辨率图像的定性对比,说明我们的方法能够生成在视觉效果上更好的超分辨率图像。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!