一种基于无监督物体检测消除偏差的网络数据学习方法与流程
本发明属于计算机视觉技术领域,涉及到一种消除网络图像偏差用于训练卷积神经网络的方法,更具体地,涉及一种基于无监督物体检测消除偏差的网络数据学习方法。
背景技术:
近年来,深度学习的迅速发展对计算机视觉领域中很多经典问题的解决起到了巨大的推动作用,如图片检索、显著性区域检测、物体检测、物体识别等。而训练卷积神经网络需要依赖大量带有标签的数据,使用人工标注是非常费时费力的。对于需要专业知识标注的数据,人工标注更为困难。近几年,为了解决训练卷积神经网络时面临的数据不足问题,大量的网络图像引起越来越多的研究人员的关注。网络上的图像是容易获取且数量庞大并不断增长的,使用这些图像训练卷积神经网络可以有效地减少人工标注数据的代价。但是在以往的工作中,由于网络图像带有噪声,利用网络数据训练卷积神经网络获得的性能提升是非常有限的。
s.e.reed等人在文献1中证明使用网络数据训练深度网络模型可以提升模型的性能。此外,文献2中提出了一种两阶段的方法,该方法利用噪声网络数据和卷积神经网络的可迁移性进行学习。这项工作假设标签的噪声独立于图像,这就导致模型性能将会受到人工定义的噪声标签的影响。2015年,t.xiao等人在文献3中使用概率框架来处理噪声标签,并在端到端学习过程中训练分类器,使模型对于噪声数据具有一定的鲁棒性。然而,目前包括标签过滤方法在内的使用网络数据训练卷积神经网络的方法,均没有对分类效果进行明显改善。其主要原因在于网络数据和目标任务的标准数据集之间存在数据偏差。
网络图像的内容相比标准数据集来说更为复杂、凌乱,这使得网络数据集与标准数据集之间的数据分布存在着差异,来自于两种数据集的图像很可能是完全无关的。在细分类任务中,大多数标准数据集图像中的物体通常处于图像的中央位置并且尺寸适宜,而网络图像往往存在目标物体太小、位置处于角落、图像内容和标签不对应等问题。这些因素造成网络图像与标准数据集之间存在构造偏差,从而影响利用网络数据辅助图像分类的效果。因此,使用网络图像训练卷积神经网络仍具有很大的挑战。
参考文献:
文献1:reedse,leeh,anguelovd,etal.trainingdeepneuralnetworksonnoisylabelswithbootstrapping.corr,2014,abs/1412.6596.
文献2:chenx,guptaa.weblysupervisedlearningofconvolutionalnetworks.in:iccv,2015.
文献3:xiaot,xiat,yangy,etal.learningfrommassivenoisylabeleddataforimageclassification.in:iccv,2015.
技术实现要素:
本发明的目的是从容易获得的、大规模的网络图像中学习,用以解决卷积神经网络训练过程中面临的数据较少的问题。相比现有技术仅对噪声图片进行剔除而忽略了网络图像与标准数据集之间的偏差,本发明提出一个基于无监督的物体检测消除偏差的网络数据学习方法,进一步解决网络图像与标准数据集之间存在的偏差问题。该发明可以过滤噪声数据、消除网络数据与标准数据集之间的偏差,利用消除偏差后的网络图像来训练深度模型,从网络数据中学习知识。
本发明使用无监督物体检测方法从内容较为复杂的网络图像中获得与目标标签一致的物体区域,并使生成的物体区域中目标物体的大小适宜且处于图像中心位置,最终将生成的无偏于标准数据集的图像区域作为新的网络图像用于卷积神经网络的训练。
本发明的技术方案:
一种基于无监督物体检测消除偏差的网络数据学习方法,该方法包括:
a.在目标任务的标准数据集上,根据先验知识“标准细分类数据图像通常包含一个位于靠近中心位置的、尺度较好的单个物体”生成弱边界框标记目标物体,并用来训练第一个候选区域生成网络模型;
b.使用步骤a中的标准数据集和生成的弱边界框作为输入数据,基于faster-rcnn训练第一个候选区域生成网络模型rpn;
c.为进一步筛选图像,对于从网络中收集的图像数据,使用步骤b中得到的第一个候选区域生成的网络模型rpn获得包含目标物体的候选内容区域图像,为后面步骤中对候选的区域图像的进一步筛选做准备;这一步骤过滤掉了与目标标签完全无关的图像(例如在狗的细分类数据集中,目标标签为艾尔谷犬,则过滤掉不含有狗的图像),使得内容区域含有相关目标物体(例如狗),这并不是对网络图像中目标物体的精准定位,而是根据网络图像生成包含对象的候选内容区域,为后面步骤中对候选区域图像的进一步筛选做准备;
d.为进一步筛选图像,使用相比第一种弱边界框尺度更小的第二种弱边界框标记标准数据集图像用于训练第二个物体区域生成网络模型rpn,将步骤c中得到的网络图像的候选内容区域作为第二个物体区域生成网络模型的输入数据,得到步骤c中生成的内容区域图像上的对象区域,使得新生成的对象区域中对象的尺度大小、密度、位置和内容接近标准数据集图像,这一步骤严格地限制了目标物体的标签、过滤掉了标签错误的图像(例如区域中需要含有艾尔谷犬);
e.为了减少冗余计算,需要先对步骤d中获得的所有对象区域采用非最大抑制nms,而后设置形式约束和标签约束来消除偏差,根据步骤d中得到的对象区域和任务的相关程度,优化形式约束和标签约束的得分方程,从对象区域中选择出相对于标准数据集无偏差的区域(图像的标签准确且图像中的目标物体在尺度、位置上类似于标准数据集)作为新图像用于训练卷积神经网络。
本发明的优点和有益效果为:
本发明方法能够有效地消除网络数据集与标准数据集之间的偏差,并且可以应用于不同的数据集和模型,具有一定的鲁棒性。对于使用卷积神经网络时面临的数据不足的现象,本方法可以低成本、快速地从网络中获得大量无偏差的数据,在多种分类任务中相比只使用标准数据训练的模型得到了更好的效果。总的来说,本发明从一个全新的角度着手处理网络数据,利用处理后的网络图像辅助训练卷积神经网络,实现网络数据集与标准数据集之间的标签一致性,相信该方法可以很好地应用在很多其他计算机视觉分类任务中。
附图说明
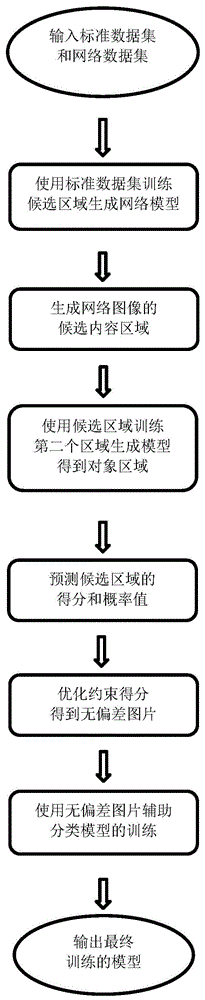
图1为基于无监督物体检测消除偏差的网络数据学习方法的流程图。
图2为基于无监督物体检测消除偏差的网络数据学习方法的示意图。
具体实施方式
下面结合附图对本发明的具体实施方式作进一步详细说明。以下实施例用于说明本发明,但不用来限制本发明的范围。
如图1所示一种基于无监督物体检测消除偏差的网络数据学习方法。
步骤一,对于任意给定的标准数据集ds={(x(m),y(m))}m=1...m,其中
x和y分别表示图像样本和对应的标签,共有m张图像。如food-101、dog-120和indoor-67三个标准数据集,分别含有101000、20580、15620张图像。根据“标准细分类数据图像通常包含一个位于靠近中心位置的、尺度较好的单个物体”的先验知识生成第一种弱边界框用于标记目标物体,图像x(m)的弱边界框的顶点坐标(lm(x),lm(y))按照如下公式定义:
其中wm和hm分别表示图像x(m)的宽和高,参数λ用于控制弱边界框的大小。
用wm(b)和hm(b)分别表示物体弱边界框的宽和高,他们的定义为:
wm(b)=λwm,hm(b)=λhm.
然后,使用上述定义的标准数据集和弱边界框作为卷积神经网络的输入,使用faster-rcnn训练第一个候选区域生成网络模型rpn。
步骤二,使用标准数据集上训练得到的第一个候选区域生成网络模型,在网络数据集dw上生成包含目标物体的候选内容区域。对应三个标准数据集,本发明分别使用了240096(食物)、52115(狗)、76907(室内场景)张网络图像进行实验。
步骤三,为了进一步对候选内容区域进行筛选,我们缩小λ的值对标准数据集图像生成约束更强的第二种弱边界框,用于训练第二个物体区域生成网络模型rpn,该网络模型可以生成对象区域,这时的弱边界框相比第一种弱边界框更小。如图2所示,两种不同大小的弱边界框分别表示候选的内容区域和对象区域。得到的候选区域中的目标物体几乎都处于中心位置,这使得图像中目标物体的大小、密度和内容相似于标准数据集。
步骤四,对于网络图像x,通过第二个物体区域生成网络模型rpn生成得到k个对象区域
通过结合两种约束信息,将原网络数据集dw映射到新的数据集dw*={rsub}中,解决了训练卷积神经网络过程中数据不足的问题,并从网络数据中学习知识用于计算机视觉领域的细分类任务。
本发明在food-101、dog-120和indoor-67三个标准数据集及其相应的网络数据集中进行实验,其分类准确率如表1所示。从实验结果看出,直接使用网络图片作为训练数据进行分类相比只是用标准数据集的分类结果提升较小,本发明有效地从网络图片中学习,并进一步提升分类精度。
表1.基于resnet-50和resnet-110网络,在food-101、dog-120、indoor-67三个标准数据集及其相应的网络数据集上的分类结果。
图2展示了本发明的示意图,其中对于算法在各阶段的核心问题、训练过程以及系统输入和输出都有很形象的描述。图2和图1表达同样的意思,只是抽象层次不同,主要是帮助理解图1中各个部分。图中(a)部分使用标准数据集图像训练两个候选区域生成网络模型时,rpn同时优化了分类损失和边界回归损失。(b)部分使用训练好的两个prn模型分别生成网络图像中内容区域和对象区域时,对每一张网络图像得到输出的预测框以及对应的置信度,以及预测框中子图的标签。从对象区域中选取标签准确且置信度大于0.4的预测框组成处理后的网络数据集。
- 还没有人留言评论。精彩留言会获得点赞!