一种反馈随机森林-压缩感知的脉冲星辨识方法与流程
本发明属于天文信号处理技术领域,具体涉及一种基于反馈随机森林-压缩感知的脉冲星辨识方法。
背景技术:
脉冲星是一种高速自转的中子星,由于其具有良好的周期稳定性,可用于航天器自主导航。由于正确识别脉冲星类别可以尽快确定导航脉冲星相关参数,进而确定航天器位置、姿态、速度以及时间等信息,并验证其姿态方向是否准确,方便实时调整,所以快速识别脉冲星的类别,对脉冲星自主导航系统有着重要意义。
当前,脉冲星信号识别的关键技术是对脉冲星提取主要特征。传统方法从累积脉冲轮廓的功率谱中提取特征向量进行轮廓匹配。为了克服积分双谱方法计算量大,信息被遗漏或被重复使用等缺点,清华大学的张贤达教授提出了选择双谱[1],避免了平凡双谱和交义项。在此基础上,谢振华改进了特征向量的降维方法,将一维选择线谱应用于脉冲星识别算法中[2]。由于该算法需计算所有双谱值,计算量大。华中科技大学的刘劲博士提出了一种新的信号识别算法[3],利用小波变换结合双谱变换,只需计算几个低频和高频系数双谱值即可,从而降低了运算复杂度。西安电子科技大学的苏哲博士提出了一种基于bispectra-mellin(bm)谱的脉冲星辨识算法[4]。其特点是利用简化的fisher可分离度使bm幅度谱域降维,得到主要特征向量,该方法普遍适用于xpnav系统,扩展性不强。哈尔滨工程大学朱晓蕾针对通信电台识别提出了基于压缩感知和随机森林的模式识别方法研究[5]。但其在压缩感知部分选取的测量矩阵为高斯矩阵,针对本发明脉冲星信号集中在低频,噪声在高频,用哈达玛矩阵可以有效的滤除噪声,高斯矩阵不如哈达玛矩阵稳定,识别率不高。且本发明通过反馈机制通过识别准确率调节测量矩阵的大小,逐渐调节识别率到稳定状态。
以上方法虽各有优势,但是脉冲星信号数据量大,需要很大的运算量。上述方法无法对脉冲星信号快速辨识,这对航天器自主导航的实时性产生较大影响,在实际应用中具有一定的局限性。
相关参考文献:
[1]zhangxd,shiy,baoz.anewfeaturevectorusingselectedbispcctraforsignalclassificationwithapplicationinradartargetrecognition[j].ieeetransactionsonsignalprocessing,2001,49(9):1875—1885.
[2]谢振华,许录平,倪广仁等.基于一维选择线谱的脉冲星辐射脉冲信号辨识.红外与毫米波学报.2007.26(3):187-195.
[3]刘劲,马杰,田金文等.基于小波和双谱的脉冲星信号识别[j].信息与控制,2009,38(2):249-252.
[4]苏哲,王勇,许录平.一种新的脉冲星累积脉冲轮廓辨识算法[j].宇航学报,2010,31(6):1563-1568.
[5]朱晓蕾.基于随机森林压缩感知和随机森林的模式识别方法研究[d].哈尔滨工程大学:信息与通信工程学院,2018..
技术实现要素:
本发明的目的在于克服上述技术中存在的不足,即降低计算量,提高航天器自主导航的实时性。
本发明的技术方案为一种反馈随机森林-压缩感知的脉冲星辨识方法,通过结合压缩感知和随机森林方式,并进行反馈调节优化,实现脉冲星辨识,实现方式如下,
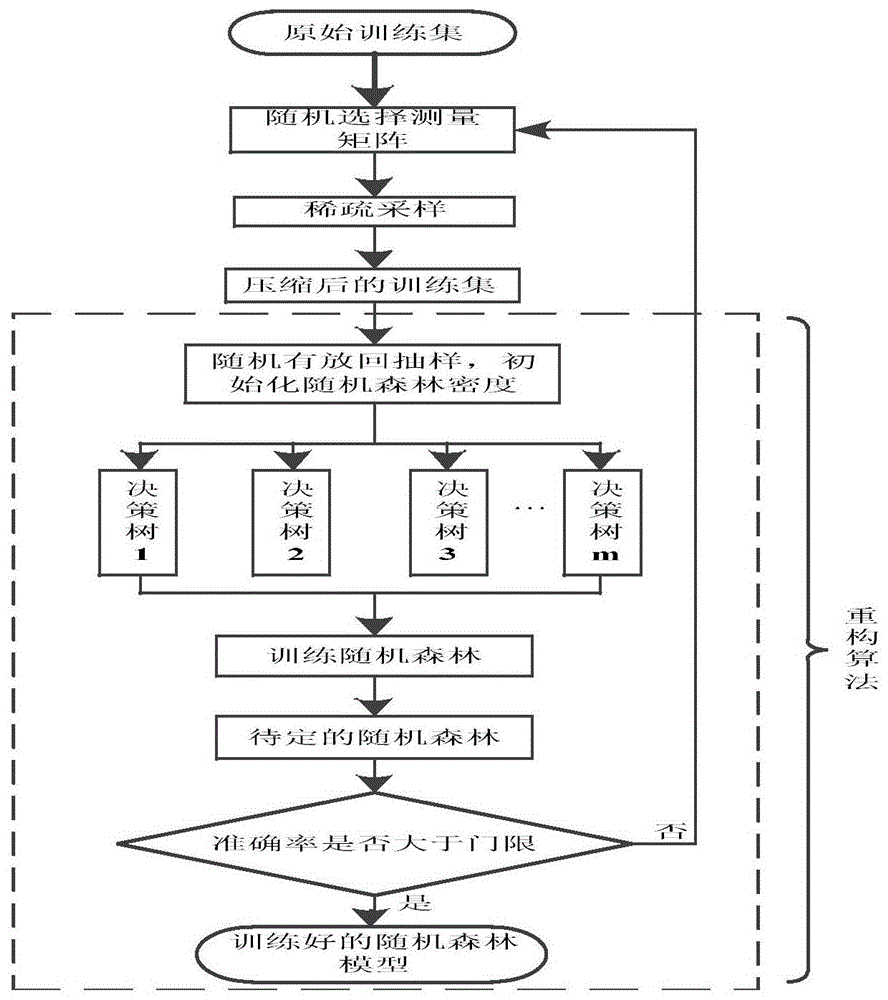
首先进行训练数据预处理过程,对脉冲星轮廓进行稀疏采样,得到观测矢量;再进行训练过程,利用随机森林进行训练,从而得到待定的随机森林识别模型,并以识别率为依据,通过反馈机制优化测量矩阵,从而得到最终的随机森林识别模型及对应的测量矩阵;最后,对于测试信号,将经过稀疏采样得到的观测矢量送入训练好的随机森林识别模型,得到类别标签,完成对脉冲星信号的辨识。
而且,所述训练数据预处理过程中,将多个脉冲星的标准轮廓数据制作为原始脉冲星数据集,归一化处理脉冲星信号,对每个原始的脉冲星信号进行拟合,将每个脉冲星的信号点数统一变换为n个数据点,得到标准脉冲星数据集;其中,n为脉冲星的信号点数。
而且,所述训练过程中,包括执行以下步骤,
步骤一,随机选择压缩感知的测量矩阵,包括随机选择m值,从n×n的哈达玛矩阵中取前m行构成测量矩阵φm×n,
其中,m为随机设置的测量矩阵行数,要求m<n,且m为2的幂次;
步骤二,基于步骤一所得测量矩阵,利用稀疏采样,提取脉冲星累积轮廓信号的主要特征信息,得到观测矢量;
步骤三,根据步骤二所得观测矢量训练随机森林模型;
步骤四,反馈机制优化模型参数,包括判断待定随机森林的准确率是否大于预设的识别率门限,
如果小于等于预设的识别率门限,则重复执行步骤一~三,重新随机选择随机选择m值,生成新的测量矩阵;
如果大于,则确定训练好的随机森林和测量矩阵。
而且,设置n=1024,m取值范围为32-1024。
而且,预设的识别率门限为95%。
而且,随机森林模型的密度n取80。
本发明针对脉冲信号的数据特点,考虑搭配压缩感知的重构算法较为复杂,选取随机森林的方式替代,并且加上反馈调节进行优化。与传统方法相比,本发明具有以下优势:
1)无需人工提取特征。通过压缩感知中的测量矩阵将信号主要特征提取出来,避免了人工特征提取,并有效抑制了噪声。
2)较高的准确率和召回率。用随机森林作为压缩感知中信号重构算法,充分发挥随机森林集成学习的优点,构建多棵决策树来识别,克服单一分类器泛化能力不强的问题,实现信号的辨识。
3)反馈调节适应性强。稀疏采样性能与测量矩阵有关。而测量矩阵大小又是随机选择。这使得随机森林-压缩感知算法的性能不稳定。本发明通过反馈机制,多次选择测量矩阵,并训练随机森林,得到测量矩阵与随机森林的最优组合,实现高性能脉冲星辨识。
附图说明
图1为本发明实施例的训练过程流程图;
图2为本发明实施例的测试过程流程图。
具体实施方式
下面结合实施例和附图说明本发明的技术方案。
本发明提出了基于反馈随机森林-压缩感知(randomforest-compressedsensing,rf-cs)脉冲星识别方法,结合压缩感知和随机森林技术,加上反馈调节优化模型结构。用压缩感知[6](compressedsensing,cs)中的稀疏采样技术将脉冲星辐射信号中的主要特征提取出来,有效去除噪声,节省了处理脉冲星原始信号所需的计算资源。采用随机森林(randomforest,rf)算法做作为cs中的重构算法,实现脉冲星识别。rf是由教授leobreiman教授于2001年提出的一种基于cart[7](classificationandregressiontree)决策树的组合分类模型。rf算法在样本数据量较小时具备良好的特征学习和提取能力[8],可避免数据过拟合,具有泛化能力强、识别精度高,运算速率快等优点,在很多数据集上优势明显。
可参见:
[6]donohodl.compressedsensing[j].ieeetransactionsoninformationtheory,2006,52(4):1289-1306.
[7]breimanl.randomforest[j].machinelearning,2001,1845(1):5-32.
[8]breimanl,friedmanj,stonecj,etal.classificationandregressiontrees[m].crcpress,1984.
本发明首先进行训练数据预处理过程,对脉冲星轮廓进行稀疏采样,得到观测矢量,再进行训练过程,利用随机森林进行训练,从而得到待定的随机森林识别模型。并以识别率为依据,通过反馈机制优化测量矩阵,从而得到最终的随机森林识别模型及其对应的测量矩阵。最后,对于测试信号,采用类似方法,将测试样本经过稀疏采样得到的观测矢量送入训练好的随机森林识别模型,得到测试样本类别标签,完成对脉冲星信号的辨识。
本发明实施例首先进行训练数据预处理过程,具体步骤如下:
1)将epn提供的120颗脉冲星的标准轮廓数据加载进数据库,制作为原始脉冲星数据集,并为其分配编号,例如j2145-0750的序号为1,b0329+54的序号为2……依次类推,给120颗脉冲星分配一个唯一的序号。
2)归一化处理脉冲星信号(优选采用三次样条插值法实现),对每个原始的脉冲星信号进行拟合,并制作新的标准轮廓信号集,将每个脉冲星的信号点数统一变换为n=1024个数据点,用于随后训练随机森林模型,实施例将这个数据集称之为标准脉冲星数据集。其中,n为脉冲星的信号点数。
本发明实施例的训练过程流程如图1所示,具体步骤如下:
步骤一:随机选择压缩感知的测量矩阵。
x射线脉冲星累积轮廓是由一段观测时间内x射线探测器接收到的光子累积而成,对于批量脉冲星识别而言数据庞大,并且包含大量噪声。本发明运用压缩感知中测量矩阵进行特征提取,对数据进行降维处理,去除部分噪声。具体实施时,可以选取部分哈达玛矩阵作为测量矩阵。本发明实施例随机选择m值,从哈达玛矩阵(n×n)中取前m行构成测量矩阵φm×n,n=1024。其中,m为随机设置的测量矩阵行数(m<1024,且m为2的幂次)。因为取值过小效果不佳,优选地,m取值范围为32-1024。
步骤二:利用稀疏采样,提取脉冲星累积轮廓信号的主要特征信息,得到观测矢量。
如果一个稀疏的脉冲星累积轮廓信号x∈rn,能够由正交基向量
ψ=[ψ1,ψ2,...ψn]表示为:
其中,α与x均为n×1的矩阵,ψi为子正交基,αi为子矩阵,·表示点乘,r为实数。
实施例选取的测量矩阵φm×n简化记为φ,与脉冲星累积轮廓信号x相乘,获得原始信号的一个测量值,即观测矢量:
y=φx(式二)
其中,y为观测矢量,为m×1矢量;x为脉冲星累积轮廓信号,为1×n矢量。
由于本步骤中选取测量矩阵的大小为m×n,则脉冲星轮廓在测量矩阵上的投影为m维,包含了原始信号的主要特征信息。将测量对象由n维降到m维,得到观测矢量y,实现了稀疏采样。
步骤三:训练随机森林模型。
在压缩感知中,重构算法将压缩信号重构出来。重构信号即完成了识别目的。本发明将随机森林算法作为重构算法,将脉冲星压缩量测值作为随机森林分类器的输入值。
将步骤二中经过特征提取压缩过的信号y,送入随机森林分类器进行分类识别。
具体实施时,可以利用bootstrap抽样从原始观测投影有放回地随机抽取n次样本,每个样本从所有属性中选择k个属性。假设从样本空间s随机采样会有m类标签li(i=1,2,...,m),于是对于样本空间s的基尼系数可以定义如下:
式(7)中pi是属于li类的样本数与总样本s的比率。
因为随机森林分类器采用的cart树是二叉决策树,实施例中取值是2。即当m取2时,对于每一次样本空间s被划分成子样本集s1,s2,分裂之后的基尼系数就变为:
其中,gini(s1)和gini(s2)根据式三计算得到,其中,|s1|表示子样本集s1的样本数目,|s2|表示子样本集s2的样本数目,|s|表示样本空间s的样本数目。
运用gini系数为评价标准作为该候选特征的最佳划分方式,选出gini指标最小的特征作为该节点的分裂特征。
重复上述过程,即进行抽取样本,选择分裂特征,选择基尼系数小的特征进行分裂生长,直到生成n棵决策树(密度n需要足够大,具体实施时用户可以预设取值),多棵cart树构成森林得到待定的随机森林。本发明实施例选择使用经典的随机森林模型,使用scikitlearn提供的随机森林类,考虑到算法时间复杂度,本发明实施例初始化随机森林模型由80颗树组成,即初始化森林密度为80。随机采样以及cart树随机分裂的特征让模型中的每个分类器互相之间具有极高的独立性,随机采样有利于降低树之间的相关性。决策树算法的随机特征选择,不容易陷入过拟合。因此模型最终具有良好的泛化能力。并且每个分类器可以单独进行训练,适合并行化实现,具有极高的训练效率。
实施例中,将预处理过程所取120颗脉冲星轮廓作为训练样本,送入随机森林模型进行训练,实验进行50次,实验结果为平均实验结果。80%观测值进行训练,20%的袋外数据集可以用来优化随机森林模型,提高模型的泛化能力,从而增强模型的鲁棒性和准确性。
步骤四:反馈机制优化模型参数,所述模型参数为测量矩阵大小m×n,也即m的取值(n取值固定)。
判断待定随机森林的准确率是否大于预设的识别率门限,本发明实施例中识别率门限为95%。如果小于等于预设的识别率门限,则重复训练过程的步骤一~三,重新随机选择m值,生成新的测量矩阵。如果大于,则确定训练好的随机森林和测量矩阵。实施例中,通过反馈机制优化后确定m=128,即经过反馈优化后的测量矩阵选取前128行压缩信号。
本发明实施例的测试过程流程图如图2所示。
1)对测试数据进行预处理方法同数据预处理过程中步骤相同,得到脉冲星测试集数据。
2)根据训练过程中步骤四确定的参数,从哈达玛矩阵(n×n)中取前m行构成测量矩阵φm×n,代入步骤二的(式二)中。测试集数据经过稀疏采样,得到压缩后的观测值。
3)利用训练好的随机森林进行分类。包括将经过稀疏采样后的观测值送入上述已确定参数(包括压缩感知中测量矩阵的大小和随机森林的密度)的随机森林-压缩感知模型中,即可实现对脉冲星的辨识。
具体实施时,以上流程可采用计算机软件技术实现自动运行流程。实施本发明方法的装置也应当在本发明的保护范围内。
以上所述仅为本发明中的一个实施例,并不用于限制本发明。凡在本发明的精神与原则之内,所做的任何修改,改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!