一种答题内容评测方法及装置与流程
本申请涉及自然语言处理领域,更具体地说,涉及一种答题内容评测方法及装置。
背景技术:
当今社会各行各业都存在对用户的考评,且考试的种类越来越多,考试过程需要对答题者提交的答题内容进行评测,以对答题者的水平进行衡量。考试试题一般可以包括客观题和主观题,其中,客观题一般包括选择题或判断题等题型。主观题一般包括古文翻译、论述题、材料分析题、仿写题等题型,此类题型要求答题者采用自己语言进行陈述作答,以表达自己对问题的理解。
目前,对主观题的答题内容采用人工评测的方式,即评分者根据答题者的答题内容进行评测,通过衡量答题内容的质量给出人工评测结果,显然,人工评测过程具有耗时长、效率低、成本高的缺点。
例如,语文考试中的古文翻译、论述题、材料分析题或仿写题均为主观题,以材料分析题为例,当学生对题目问题进行作答并提交后,需要评分老师对所有学生的答题内容进行评分,由于学生对材料的理解层次不同以及表达方式不同,需要评分老师利用较长的时间对各个学生的答题内容进行衡量,导致人工评测耗费的时间长,且效率低,当答题学生较多时,人工评测方法需要投入大量的人工,造成较高的人工成本。
技术实现要素:
有鉴于此,本申请提供了一种答题内容评测方法及装置,以解决现有答题内容评测方法耗时长、效率低且人工成本高的问题。
为了实现上述目的,现提出的方案如下:
一种答题内容评测方法,包括:
获取待评测答题内容;
确定所述待评测答题内容的深度特征,所述深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力;
基于所述深度特征,确定所述待评测答题内容的评测结果。
优选地,确定所述待评测答题内容的深度特征,包括:
将所述待评测答题内容输入预置的深度特征确定模型,得到所述深度特征确定模型输出的所述待评测答题内容的深度特征;其中,
所述深度特征确定模型为,以相比于相同评测结果,对不同评测结果对应答题内容所确定的深度特征间的表征差异性更大为训练条件,和/或,以对差别越大的评测结果对应的答题内容所确定的深度特征间的表征差异性越大为训练条件训练得到。
优选地,确定所述待评测答题内容的深度特征,包括:
将所述待评测答题内容按照设定映射条件映射到多维欧式空间,得到映射后的深度特征,所述设定映射条件包括:
相比于相同评测结果,不同评测结果对应答题内容在所述多维欧式空间中映射的深度特征间的表征差异性更大;和/或,
差别越大的评测结果对应的答题内容在所述多维欧式空间中映射的深度特征间的表征差异性越大。
优选地,深度特征确定模型的训练过程,包括:
选取多个n元组,每个n元组包含n个答题内容样本,且每个n元组中存在不同评测结果对应的答题内容样本,n大于等于3;
以每个n元组为训练样本,以针对每个n元组中不同评测结果对应的答题内容所确定的深度特征向量间的距离大于相同评测结果的答题内容所确定的深度特征向量间的距离为训练条件,和/或,以针对每个n元组中差别越大的评测结果对应的答题内容所确定的深度特征向量间的距离越大为训练条件,训练深度特征确定模型。
优选地,选取多个n元组,包括:
对每一初始待评测答题内容进行异常检测,得到异常检测通过后的初始待评测答题内容;
对异常检测通过后的初始待评测答题内容进行聚类,得到多个聚类簇;
从每个聚类簇中抽取初始待评测答题内容,抽取后的初始待评测答题内容作为人工评测的对象;
从人工对初始待评测答题内容评测后得到的答题内容中,选取多个n元组。
优选地,对每一初始待评测答题内容进行异常检测,包括:
以每一初始待评测答题内容为目标对象,确定所述目标对象在所有初始待评测答题内容中的出现概率;
基于所述目标对象的出现概率,确定所述目标对象是否通过异常检测。
优选地,基于所述深度特征,确定所述待评测答题内容的评测结果,包括:
将所述深度特征输入预置的评测模型,得到所述评测模型输出的所述待评测答题内容的评测结果,所述评测模型为,以答题内容样本的深度特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
优选地,本方法还包括:
确定所述待评测答题内容的浅层特征;
则所述基于所述深度特征,确定所述待评测答题内容的评测结果,包括:
将所述浅层特征和所述深度特征组合,得到组合特征;
将所述组合特征输入预置的评测模型,得到所述评测模型输出的所述待评测答题内容的评测结果,所述评测模型为,以答题内容样本的深度特征和浅层特征组合后的组合特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
一种答题内容评测装置,包括:
答题内容获取单元,用于获取待评测答题内容;
深度特征确定单元,用于确定所述待评测答题内容的深度特征,所述深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力;
评测结果确定单元,用于基于所述深度特征,确定所述待评测答题内容的评测结果。
优选地,深度特征确定单元包括:
第一深度特征确定子单元,用于将所述待评测答题内容输入预置的深度特征确定模型,得到所述深度特征确定模型输出的所述待评测答题内容的深度特征;其中,
所述深度特征确定模型为,以相比于相同评测结果,对不同评测结果对应答题内容所确定的深度特征间的表征差异性更大为训练条件,和/或,以对差别越大的评测结果对应的答题内容所确定的深度特征间的表征差异性越大为训练条件训练得到。
优选地,深度特征确定单元包括:
第二深度特征确定子单元,用于将所述待评测答题内容按照设定映射条件映射到多维欧式空间,得到映射后的深度特征,所述设定映射条件包括:
相比于相同评测结果,不同评测结果对应答题内容在所述多维欧式空间中映射的深度特征间的表征差异性更大;和/或,
差别越大的评测结果对应的答题内容在所述多维欧式空间中映射的深度特征间的表征差异性越大。
优选地,还包括:模型训练单元,其包括:
样本选取单元,用于选取多个n元组,每个n元组包含n个答题内容样本,且每个n元组中存在不同评测结果对应的答题内容样本,n大于等于3;
样本训练单元,用于以每个n元组为训练样本,以针对每个n元组中不同评测结果对应的答题内容所确定的深度特征向量间的距离大于相同评测结果的答题内容所确定的深度特征向量间的距离为训练条件,和/或,以针对每个n元组中差别越大的评测结果对应的答题内容所确定的深度特征向量间的距离越大为训练条件,训练深度特征确定模型。
优选地,样本选取单元包括:
异常检测单元,用于对每一初始待评测答题内容进行异常检测,得到异常检测通过后的初始待评测答题内容;
聚类单元,用于对异常检测通过后的初始待评测答题内容进行聚类,得到多个聚类簇;
人工评测对象抽取单元,用于从每个聚类簇中抽取初始待评测答题内容,抽取后的初始待评测答题内容作为人工评测的对象;
n元组选取单元,用于从人工对初始待评测答题内容评测后得到的答题内容中,选取多个n元组。
优选地,异常检测单元包括:
出现概率确定单元,用于以每一初始待评测答题内容为目标对象,确定所述目标对象在所有初始待评测答题内容中的出现概率;
异常判断单元,用于基于所述目标对象的出现概率,确定所述目标对象是否通过异常检测。
优选地,评测结果确定单元包括:
第一模型预测单元,用于将所述深度特征输入预置的评测模型,得到所述评测模型输出的所述待评测答题内容的评测结果,所述评测模型为,以答题内容样本的深度特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
优选地,本装置还包括:
浅层特征确定单元,用于确定所述待评测答题内容的浅层特征;
优选地,评测结果确定单元包括:
组合特征获取单元,用于将所述浅层特征和所述深度特征组合,得到组合特征;
第二模型预测单元,用于将所述组合特征输入预置的评测模型,得到所述评测模型输出的所述待评测答题内容的评测结果,所述评测模型为,以答题内容样本的深度特征和浅层特征组合后的组合特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
一种答题内容评测设备,包括存储器和处理器;
所述存储器,用于存储程序;
所述处理器,用于执行所述程序,实现如上答题内容评测方法的各个步骤。
一种可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如上答题内容评测方法的各个步骤。
从上述的技术方案可以看出,本申请实施例提供的答题内容评测方法,对于待评测答题内容确定其深度特征,该深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力,进一步基于该深度特征可自动确定待评测答题内容的评测结果,由此可见,本方案能够实现自动对待评测答题内容进行评测的目的,相比于现有的人工评测方法,具有耗时短、效率高的优点,并且大大降低了人工成本。
进一步地,考虑到实际情况中,答题内容间的差异性会对评测结果带来影响,并且,不同评测结果对应的答题内容间的差异性应当大于相同评测结果的答题内容间的差异性,此外,差别越大的评测结果对应的答题内容间的差异性应当越大。基于上述介绍可知,本案中所确定的待评测答题内容的深度特征,具备了相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力,也即,本案对于不同评测结果对应的答题内容所确定的深度特征间的差异性大于对相同评测结果的答题内容所确定的深度特征间的差异性,以及对差别越大的评测结果对应的答题内容所确定的深度特征间的差异性越大。在此基础上,本方案根据深度特征确定待评测答题内容的评测结果,利用深度特征所具备的上述能力,充分考虑不同评测结果对应的答题内容之间的差异性,由此提高了评测结果的准确性。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
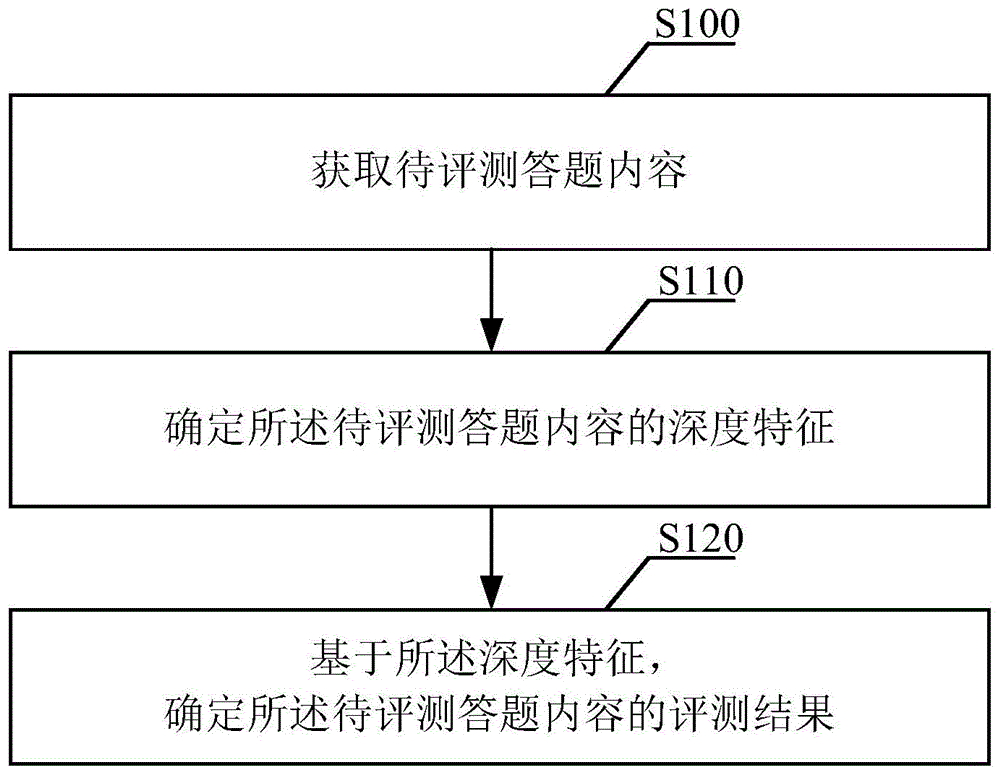
图1为本申请实施例公开的一种答题内容评测方法流程图;
图2示例了一种选取四元组的方法示意图;
图3示例了一种选取三元组的方法示意图;
图4示例了一种深度特征确定模型训练过程示意图;
图5为本申请实施例公开的一种答题内容评测装置结构示意图;
图6为本申请实施例公开的一种答题内容评测设备的硬件结构框图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
为了能够提升答题内容评测效率,降低人工成本,本案发明人进行了深入研究:
起初的思路是基于浅层特征对待评测答题内容进行自动评测,具体地,首先,获取待评测答题内容;然后,确定待评测答题内容的浅层特征,其中,浅层特征可以包括待评测答题内容的词袋特征、n-gram特征或与参考答案间的相似度特征中任一项或多项;进一步,针对每一待评测答题内容,基于待评测答题内容的浅层特征确定评测结果。
可以理解的是,上述方法虽然可以实现自动评测的目的,但是发明人发现,浅层特征一般表征的都是答题内容自身的属性,如词袋特征描述的是答题内容自身所包含的所有单词,再比如相似度特征描述的是答题内容自身与参考答案间的相似度。而实际情况下,答题内容之间会存在一定的差异,且答题内容之间的差异性会对评测结果带来影响,并且,不同评测结果对应的答题内容间的差异性应当大于相同评测结果的答题内容间的差异性,此外,差别越大的评测结果对应的答题内容间的差异性应当越大。
而上述对待评测答题内容所抽取的浅层特征,没有考虑不同答题内容间差异性对评测结果所带来的影响,其确定的待评测答题内容的评测结果不够准确。
所以,本案发明人进行了进一步的研究,提供了一种基于深度特征的答题内容评测方法,可以解决上述提出的问题,详细参照下文介绍。
本申请提供的基于深度特征的答题内容评测方法,可以适用于需要对待评测答题内容进行评测的场景,例如,对学生作答的试卷进行评分的场景,或者对员工考评表进行评级的场景,一般的,本答题内容评测方法中的待评测答题内容为主观题答题内容。
进一步的,本申请方法可以应用于具有评测功能的智能设备,例如电脑、平板或智能手机,或者可以应用于预设有评测系统的服务器。接下来,结合附图1对本申请提供的答题内容评测方法进行介绍,图1示例了一种答题内容评测方法流程图,该方法详细包括:
步骤s100、获取待评测答题内容。
具体地,本步骤将需要进行评测的答题内容定义为待评测答题内容,一般为主观题答题内容,其中,待评测答题内容可以为考试中答题者提交测评试卷中的答题内容,一般的,测评试卷可以分为纸质试卷或者电子试卷,本实施例中可以直接获取答题者提交的电子试卷中的答题内容作为待评测答题内容,或者,可以将答题者提交的纸质试卷中的答题内容图片经过扫描识别,利用ocr(opticalcharacterrecognition,光学字符识别)技术转换成电子文本,并将转换后的电子文本内容作为待评测答题内容。
步骤s110、确定待评测答题内容的深度特征。
具体地,由于待评测答题内容受答题者主观因素影响较大,例如,每个答题者对问题的理解程度不同,或文本表述能力和习惯有所不同,所以待评测答题内容之间具有不同程度的差异性,该差异性可以导致评测结果的不同,可以理解的是,不同评测结果对应的答题内容间的差异性应当大于相同评测结果的答题内容间的差异性,此外,差别越大的评测结果对应的答题内容间的差异性应当越大。
例如,一场考试的评测结果包括优秀、良好、及格或不及格,若答题者甲和乙的评测结果都为优秀,答题者丙的评测结果为及格,答题者丁的评测结果为不及格,则理论上来说,相对于答题者甲和乙的答题内容,答题者甲和丙的答题内容之间的差异性应当更大,并且答题者甲和丁的答题内容之间的差异性应当大于答题者甲和丙的答题内容之间的差异性。
基于此,本步骤获取每个待评测答题内容的深度特征,其中,深度特征同时考虑了每个待评测答题内容的差异性,具体地,深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力。
可以理解的是,深度特征可以具备上述两种能力中的至少一种能力,当然,当深度特征同时具备上述两种能力时,更能表征答题内容间的差异性,基于此确定的评测结果也会更加准确。
步骤s120、基于深度特征,确定待评测答题内容的评测结果。
具体地,每一待评测答题内容都对应于一个评测结果,评测结果可以是定性的,也可以是定量的,如评测结果可以包括评测等级或评测分数。例如,员工考评题目的评测结果可能为优秀、良好、及格或不及格中的一项,语文考试中的材料阅读题的评测结果可能为0分至满分之间的任一分数。
其中,深度特征为从每个待评测答题内容中提取的特征,每一待评测答题内容对应的深度特征可以表征其属性,且深度特征获取过程充分考虑待评测内容间的差异性对评测结果产生的影响,所以,本步骤中针对待评测答题内容,基于其深度特征,可以确定待评测答题内容的评测结果。
从上述的技术方案可以看出,本申请实施例提供的答题内容评测方法,对于待评测答题内容确定其深度特征,该深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力,进一步基于该深度特征可自动确定待评测答题内容的评测结果,由此可见,本方案能够实现自动对待评测答题内容进行评测的目的,相比于现有的人工评测方法,具有耗时短、效率高的优点,并且大大降低了人工成本。
进一步地,考虑到实际情况中,答题内容间的差异性会对评测结果带来影响,并且,不同评测结果对应的答题内容间的差异性应当大于相同评测结果的答题内容间的差异性,此外,差别越大的评测结果对应的答题内容间的差异性应当越大。基于上述介绍可知,本案中所确定的待评测答题内容的深度特征,具备了相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力,也即,本案对于不同评测结果对应的答题内容所确定的深度特征间的差异性大于对相同评测结果的答题内容所确定的深度特征间的差异性,以及对差别越大的评测结果对应的答题内容所确定的深度特征间的差异性越大。在此基础上,本方案根据深度特征确定待评测答题内容的评测结果,利用深度特征所具备的上述能力,充分考虑不同评测结果对应的答题内容之间的差异性,由此提高了评测结果的准确性。
接下来提出本申请的一个实施例对步骤s110,确定待评测答题内容的深度特征的可选的两种实现方式进行说明。
第一种确定待评测答题内容的深度特征的实现方式为,利用深度特征确定模型以获得每一待评测答题内容的深度特征。
具体地,可以将待评测答题内容输入预置的深度特征确定模型,得到深度特征确定模型输出的待评测答题内容的深度特征。
其中,深度特征确定模型为预先训练好的神经网络模型,优选地,该神经网络模型可以为cnn(convolutionalneuralnetworks,卷积神经网络)模型,该模型可以由一个或多个cnn组成,模型的输入数据为待评测答题内容,输出数据为与输入数据对应的深度特征,训练条件为输入数据与输出数据间应该满足的限定条件,所以,该训练条件应该根据深度特征的所具备的能力设定。
需要说明的是,上述神经网络模型还可以为rnn(recurrentneuralnetwork,循环神经网络)模型或lstm(longshort-termmemory,长短期记忆网络)模型等神经网络模型,本申请实施例对于上述深度特征确定模型的类型不作限定,仅以cnn模型为例进行介绍。
由于,答题内容之间的差异性会对评测结果带来影响,本步骤获取的深度特征可以表征答题内容的属性,所以深度特征应该具备以下至少一种能力:不同评测结果对应的答题内容的深度特征间的差异性应该大于相同评测结果的答题内容的深度特征间的差异性;和/或,差别越大的评测结果对应的答题内容的深度特征间的差异性越大。
基于上述能力确定深度特征确定模型的训练条件,即:训练深度特征确定模型应该以:相比于相同评测结果,对不同评测结果对应答题内容所确定的深度特征间的表征差异性更大为训练条件,和/或,以对差别越大的评测结果对应的答题内容所确定的深度特征间的表征差异性越大为训练条件。
可见,通过上述训练条件预先进行训练确定的深度特征确定模型,以待评测答题内容为输入,可以输出每个待评测答题内容对应的深度特征,且能够保证输出的深度特征具有具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力。
第二种确定待评测答题内容的深度特征的实现方式为,利用空间映射的方法获得每一待评测答题内容的深度特征。其中,空间映射方法可以将一个空间中的数据映射至另一个空间,以得到原空间中难以获取的数据特征。
具体地,可以将待评测答题内容按照设定映射条件映射到多维欧式空间,得到映射后的深度特征。
其中,映射条件为该映射过程成立的条件,可以看作是原空间与多维欧式空间中的数据的对应关系,本步骤可以预先设定映射条件以得到符合要求的映射后的深度特征,其中,映射条件应该根据深度特征的所具备的能力设定。
深度特征所应具备的能力可以参照前文介绍,基于此,确定本步骤中的映射条件,即:相比于相同评测结果,不同评测结果对应答题内容在多维欧式空间中映射的深度特征间的表征差异性更大;和/或,差别越大的评测结果对应的答题内容在多维欧式空间中映射的深度特征间的表征差异性越大。
接下来举例对上述映射过程进行说明:
例如语文考试中,将答题者的待评测答题内容作答x映射至n维欧式空间rn,得到该待评测答题内容对应的深度特征,其中,该深度特征可以为欧式空间rn中的一个n维向量。可选的,映射条件可以为映射函数y,即,任一待评测内容x都对应于一个满足映射函数y的映射结果y(x),可以将该映射结果作为待评测答题内容x的深度特征。假设本例中的评测结果为评分,为了保证得到的深度特征满足上述映射条件,对映射函数y有如下要求:
不同评分对应的答题内容在欧式空间rn内的距离大于相同评分对应的答题内容;不同评分对应的答题内容,分差越大,在欧式空间rn内的距离越远。例如,答题者a答题内容为xa,其评分为90分;答题者b答题内容为xb,其评分为90分;答题者c答题内容为xc,其评分为80分;答题者d答题内容为xd,评分为40分。则上述映射条件可以表示为:
h(y(xa),y(xd))>h(y(xa),y(xc))>h(y(xa),y(xb))
式中,h表示向量之间的距离,y为映射函数,y(xa),y(xb),y(xc),y(xd)分别表示答题内容xa、xb、xc、xd映射到多维欧式空间rn对应的深度特征,该深度特征可以为n维向量。
显然,通过上述映射条件将待评测答题内容按照设定映射条件映射到多维欧式空间,得到的映射后的深度特征,能够保证输出的深度特征具备:相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,以及,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力。
由上可知,上述两种实现方式都可以自动确定待评测答题内容的深度特征。其中,第一种确定待评测答题内容的深度特征的实现方式,需要对神经网络模型进行训练,以得到上述深度特征确定模型。
接下来,本申请的另一个实施例中,对上述第一种确定待评测答题内容的深度特征中提及的深度特征确定模型训练过程进行介绍。
深度特征确定模型的训练样本可以为答题内容样本集合中的答题内容样本,其中,答题内容样本集合中可以包括多个答题内容样本,答题内容样本为预先经过人工评测确定评测结果的答题内容,可以理解的是,由于人工和时间的限制,答题内容样本的数量一般较少,为了充分利用答题内容样本以及答题内容样本的差异性,本申请实施例提出一种利用n元组采样训练深度特征确定模型的方法,训练过程具体可以包括:
s11、选取多个n元组,每个n元组包含n个答题内容样本,且每个n元组中存在不同评测结果对应的答题内容样本,n大于等于3。
具体地,答题内容样本集合中的每一答题内容样本对应于一个评测结果,一般情况下,答题内容样本集合中包括不同评测结果对应的答题内容样本,基于上训练条件,从答题内容样本集合选取的每个n元组应该包括三个及以上的答题内容样本,即,n应该大于等于3,且其中每个n元组中,应该存在不同评测结果对应的答题内容样本。可选的,选取n元组的过程可以包括:
首先,从答题内容样本集合中选择第一答题内容样本,选择方法可以包括以下两种:
第一种、随机选择一个答题内容样本,将其作为第一答题内容样本,并将其评测结果作为第一评测结果。
第二种、随机选择一个评测结果,将其作为第一评测结果,并随机选择一个该第一评测结果的答题内容样本作为第一答题内容样本。
然后,从答题内容样本集合中选择n元组中的其他n-1个答题内容样本,n-1应该大于等于2。该n-1个答题内容样本中,至少存在一个与第一评测结果不同的评测结果对应的答题内容样本。进一步,该n-1个答题内容样本中还可以存在至少一个与第一评测结果相同评测结果的答题内容样本。
由此,得到一个n元组,可见每个n元组包括n个答题内容样本,且其中一定会存在不同评测结果对应的答题内容样本,n大于等于3。
接下来分别以n=3、n=4为例对上述选取过程进行说明:
当n=4,例如,一道总分为2分的主观题,经过人工评测得到评测结果的答题内容样本为100份,该100份答题内容样本组成答题内容样本集合,假设答题内容样本对应的评测结果包括0分,1分或2分。图2示例了可选的一种从答题内容样本集合中选取四元组的方法示意图。
具体地,选取的第i个n元组为四元组时,首先随机选取一个答题内容样本xi,假设该答题内容样本的评测结果为0分,则,继续从答题内容样本选择另一个评测结果为0分的答题内容样本x’i,并从答题内容样本中分别选择评测结果为1分和2分的答题内容样本
当n=3,例如,一道总分为1分的主观题,假设答题内容样本对应的评测结果包括0分或1分。图3示例了可选的一种从答题内容样本集合中选取三元组的方法示意图。
具体地,选取的第i个n元组为三元组时,首先随机选取一个答题内容样本zi,假设该答题内容样本的评测结果为0分,则,继续从答题内容样本选择另一个评测结果为0分的答题内容样本z’i,以及从答题内容样本选择另一个评测结果为1分的答题内容样本
需要说明的是,上述选取三元组和四元组的方法为多种选取方式中可选的一种,本申请实施仅以上述为例对选取方法进行具体说明,对选取方法以及n的取值不作限定。
s12、以每个n元组为训练样本,以针对每个n元组中不同评测结果对应的答题内容所确定的深度特征向量间的距离大于相同评测结果的答题内容所确定的深度特征向量间的距离为训练条件,和/或,以针对每个n元组中差别越大的评测结果对应的答题内容所确定的深度特征向量间的距离越大为训练条件,训练深度特征确定模型。
具体地,训练过程中,深度特征确定模型的输入为答题内容样本的字符级或词级向量表示,输出为答题内容样本对应的深度特征,可选的,该深度特征可以为深度特征向量。
可以理解的是,相对于相同评测结果对应的答题内容样本,不同评测结果对应的答题内容样本的差异性应当更大,且,评测结果差别越大则其对应的答题内容样本间差异性应当越大,由于深度特征向量可以表征答题内容样本,而深度特征向量的差异性可以由深度特征向量在多维欧式空间中的距离表示,所以,以每个n元组为训练样本,训练深度特征确定模型的训练条件为:针对每个n元组中不同评测结果对应的答题内容所确定的深度特征向量间的距离大于相同评测结果的答题内容所确定的深度特征向量间的距离,和/或,针对每个n元组中差别越大的评测结果对应的答题内容所确定的深度特征向量间的距离越大。
以上述包含4个答题内容样本xi、x’i、
基于此,训练条件可以表示为:
式中,d表示向量之间的距离,f为训练函数,将基于训练函数得到的输出结果f(xi),f(x’i),
为满足上式,本申请实施例提出一种双头折页损失函数来训练深度特征确定模型,该双头折页损失函数的优化目标描述如下:
训练条件函数如下:
其中,εi和τi为松弛变量,且对于任意i,τi≥0,εi≥0,g1、g2和λ均为常量,w表示模型参数。
上述公式可以表示为:
图4示例了深度特征确定模型训练过程示意图,可选的,该深度特征确定模型为cnn模型。如图4所示,首先对答题内容样本做多次采样获得若干个n元组,以n=4为例,然后将每个四元组内的四个答题内容样本同时输入深度特征确定模型中的四个cnn网络,该四个cnn网络共享模型参数,进一步,使用双头折页损失函数对cnn模型输出的四个深度特征向量进行优化训练。最后可以使用基于随机梯度下降的反向传播算法更新cnn模型参数。
可选的,从答题内容样本中选取一小部分作为验证答题内容集,根据验证答题内容集的效果决定是否停止训练,直至完成深度特征确定模型的训练过程。
需要说明的是,本申请实施例是以n=4的四元组为例进行介绍,但本方法对n的取值不作具体限定,为了充分利用答题内容样本,n的取值一般要大于等于3,接下来对n=3的情况下的深度特征确定模型的训练过程进行说明。
例如,对于图3所示的三元组,该三元组包含3个答题内容样本,分别为zi、z’i和
式中,d表示深度特征向量之间的距离,f为训练函数,将基于训练函数f得到的输出结果f(zi)、f(z’i)、
上述实施例中,n元组是从答题内容样本集合中进行选取的,本申请实施例对选取的过程进行进一步的说明,具体可以包括:
s21、对每一初始待评测答题内容进行异常检测,得到异常检测通过后的初始待评测答题内容。
具体地,初始待评测答题内容为所有需要评测的答题内容,例如,语文考试中,答题者提交的答题内容为120份,则该120份答题内容即为初始待评测答题内容,其中可能包括异常答题的情况,所以需要对每一初始待评测答题内容进行异常检测,得到通过异常检测的初始待评测答题内容。
可选的一种异常检测的方法可以包括:
s211、以每一初始待评测答题内容为目标对象,确定目标对象在所有初始待评测答题内容中的出现概率。
首先,可以将每一初始待评测答题内容作为目标对象输入预先训练好的m元语言模型,其中,该m元语言模型的训练样本为所有初始待评测答题内容,其中,m的取值为大于等于1的整数。
当m=1时,将目标对象输入至一元语言模型,输出为目标对象中每个词在待评测答题内容中包括的所有词中出现的概率。
当m大于等于2时,将目标对象输入至m元语言模型,输出为目标对象中每个词在其前m-1个词出现时出现的概率,一般的,m应取值小于等于3。
以m=2为例进行介绍,首先对二元语言模型的训练过程进行介绍,训练样本为初始待评测答题内容中的所有词,将初始待评测答题内容中的所有词输入至二元语言模型,经过训练获得的语言模型的输出为:
上式中,wj和wj-1为所有初始待评测答题内容包括的两个词,c(wj-1wj)为wj和wj-1这两个词在所有初始待评测答题内容连续出现的次数,c(wj-1)为wj-1在所有初始待评测答题内容中出现的总次数。即,p(wj|wj-1)表示在初始待评测答题内容包括的所有词中,wj在wj-1出现后出现的概率。
可以理解的是,将目标对象输入上述训练好的二元语言模型后,该二元语言模型可以依次输出每一目标对象中包括的词出现的条件概率,其中,条件概率为目标对象包括的每一词在前一个词出现的条件下出现的概率,可以表示为p(wq|wq-1),其中,wq为目标对象中的第q个词,wq-1为目标对象中wq的前一词。
进一步,计算该目标对象对应的所有条件概率的乘积,确定目标对象在所有初始待评测答题内容中的出现概率,若目标对象包含的总词数为q,则目标对象对应的条件概率个数为q-1,目标对象在所有初始待评测答题内容中的出现概率可以表示为:
接下来举例对上述确定目标对象在所有初始待评测答题内容中的出现概率的过程进行说明,例如,目标对象包括五个词,即q=5,语言模型的输出分别为条件概率p(w2|w1),p(w3|w2),p(w4|w3),p(w5|w4),其中,p(w2|w1)表示该目标对象中的第二个词在第一个词出现的情况下出现的概率,p(w3|w2)表示该目标对象中的第三个词在第二个词出现的情况下出现的概率,p(w4|w3)表示该目标对象中的第四个词在第三个词出现的情况下出现的概率,p(w5|w4)表示该目标对象中的第五个词在第四个词出现的情况下出现的概率,则,可以确定该目标对象在所有初始待评测答题内容中的出现概率为该目标对象所有条件概率的乘积:
p(w2|w1)·p(w3|w2)·p(w4|w3)·p(w5|w4)
需要说明的是,m还可以根据需要取值为大于2的任意整数,本实施例仅以m=1和m=2为例进行说明。
s212、基于目标对象的出现概率,确定目标对象是否通过异常检测。
具体地,步骤s211已经确定每一目标对象对应的出现概率,该出现概率表征在所有初始待评测答题内容中,该目标对象出现的可能性,可以理解的是,出现概率越大则该目标对象出现的可能性越大。基于此,确定目标对象是否通过异常检测,将不通过异常检测的目标对象作为异常初始待评测答题内容排除。
本实施例示例了上述s212的几种可选实施方式,分别如下:
第一种、将出现概率小于设定阈值的目标对象判定为异常答题内容,例如,设定阈值为0.3,则将所有出现概率小于0.3的目标对象作为异常答题内容排除。
第二种、将所有目标对象按照出现概率从大到小排序之后,将固定比例排序最靠后的目标对象作为异常答题内容排除,例如将20个目标对象按照出现概率从大到小排序后,将排序在最后五个的目标对象作为异常答题内容排除。
第三种、计算所有目标对象出现概率的平均值μ和标准差σ,参照正态分布的标准差原则,将出现概率小于μ-rσ学生作答判定为异常答题内容排除,一般的,r为大于2的整数。
本步骤可以得到未通过异常检测的异常初始待评测答题内容,以及通过异常检测的非异常初始待评测答题内容。其中,对于异常初始待评测答题内容可以进入相应的异常处理流程。
s22、对非异常初始待评测答题内容进行聚类,得到多个聚类簇。
具体地,上述可知,非异常初始待评测答题内容为s21中通过异常检测的初始待评测答题内容。本步骤进一步对非异常初始待评测答题内容进行聚类,其中,聚类方法可以利用k-means(k均值聚类算法)、k-medoids(k中心点聚类算法)、lda(lineardiscriminateanalysis,线性判别分析)等聚类算法或者主题模型算法,算法所使用的聚类特征可以包括:初始待评测答题内容的词袋特征、n-gram特征、与参考答案间的相似度特征等。
由此可以获得多个聚类簇,每个聚类簇中包括一个或多个非异常初始待评测答题内容。
s23、从每个聚类簇中抽取非异常初始待评测答题内容,抽取后的非异常初始待评测答题内容作为人工评测的对象。
具体地,人工评测的对象为提交至人工进行评测的非异常初始待评测答题内容,可以按照需求预先确定人工评测的对象个数,其中,该对象个数可以根据初始待评测答题内容总个数确定,或者根据聚类簇的个数确定。可以理解的是,从每个聚类簇中抽取初始待评测答题内容的方法可以包括多种,接下来本实施例介绍其中可选的三种抽取方法。
第一种,从每个聚类簇中抽取相同数量的非异常初始待评测答题内容。
具体地,每一聚类簇中包括一个或多个非异常初始待评测答题内容,可以将预先确定的人工评测的对象个数平均分配给各个聚类簇,假设预先确定的人工评测的对象个数为k,聚类簇的个数为r,则,从每个聚类簇中一次性抽取k/r个非异常初始待评测答题内容。
可以理解的是,可能存在聚类簇中的非异常初始待评测答题内容个数少于k/r个的情况,此时可以直接抽取该聚类簇中所有非异常初始待评测答题内容。
第二种,循环地依次从每个聚类簇中抽取非异常初始待评测答题内容,其中,每个聚类簇一次只抽取一个非异常初始待评测答题内容。
具体地,首先可以将所有聚类簇随机排序,然后按照排序顺序循环地依次从每一个聚类簇中抽取一个非异常初始待评测答题内容,直至抽取出的非异常初始待评测答题内容数量达到预先确定的人工评测的对象个数后停止抽取。
需要说明的是,如果抽取过程中,某一聚类簇中的异常初始待评测答题内容剩余个数为0,则跳过该聚类簇,继续从剩余的聚类簇中循环地抽取非异常初始待评测答题内容,直至抽取出的非异常初始待评测答题内容数量达到人工评测的对象个数后停止抽取。
第三种,按比例从每个聚类簇中抽取非异常初始待评测答题内容。
具体地,每个聚类簇中包括的非异常初始待评测答题内容个数可能不同,可以首先根据每个聚类簇中的非异常初始待评测答题内容个数确定抽取比例,并按照该比例以及预先确定的人工评测的对象个数,确定从每个聚类簇中抽取非异常初始待评测答题内容的个数。
例如,共有100个初始待评测答题内容,经过聚类获得三个聚类簇,三个聚类簇分别包括50个,25个,25个非异常初始待评测答题内容,则从三个聚类簇分别抽取非异常初始待评测答题内容,抽取的比例为2:1:1,若预先确定的人工评测的对象个数为20,那么从三个聚类簇分别抽取的初始待评测答题内容个数分别为10个、5个、5个。
进一步将经过聚类抽取后的非异常初始待评测答题内容作为人工评测的对象,并将经过人工评测后的非异常初始待评测答题内容作为前述s11中的答题内容样本集合。对于非异常初始待评测答题内容中,除去作为人工评测对象后剩余的对象,可以作为上述实施例中步骤s100中的待评测答题内容,也即,上述实施例中步骤s100所获取的待评测答题内容,是经过异常检测处理后,通过异常检测的非异常初始待评测答题内容。除此之外,某些情况下,s100所获取的待评测答题内容也可以是初始待评测答题内容。
s24、从人工对初始待评测答题内容评测后得到的答题内容中,选取多个n元组。
具体地,将经过聚类抽取后的初始待评测答题内容作为人工评测的对象提交至人工评测,得到评测结果。可选的,将得到评测结果的答题内容作为答题内容样本,并从答题内容样本按照s11中介绍的方法选择n元组。
基于上述各实施例,可以确定待评测答题内容的深度特征,该深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力,由此可以基于深度特征确定每一待评测答题内容的评测结果。可选的,确定每一待评测答题内容的评测结果的实施方式可以包括多种,本申请实施例介绍其中可选的两种实施方式。
第一种、仅基于深度特征,确定待评测答题内容的评测结果。
具体地,可以将待评测答题内容对应的深度特征输入至预置的评测模型,其中,预置的评测模型可以为预先训练好的评测模型,该模型可以为xgboost提升树模型,也可以是随机森林、决策树等机器学习模型,本申请实施例对此不作限定。
可选地,评测模型可以以答题内容样本的深度特征为训练样本,以标注的答题内容样本评测结果为样本标签训练得到,即,训练后的评测模型输入为待评测答题内容,输出为待评测答题内容对应的评测结果。
基于上述评测模型,可以实现自动确定评测结果的目的,相比人工评测方法,具有耗时短、效率高的优点,并且大大降低了人工成本。进一步,相比于仅基于浅层特征确定评测结果的评测方法,本方法考虑到在实际情况下,答题内容间的差异性会对评测结果带来影响,获取待评测答题内容的深度特征并基于深度特征确定评测结果,由此提高了评测的准确性。
进一步地,对于待评测答题内容还可以提取浅层特征,其中,浅层特征能够表征待评测答题内容各自的属性,可选地,浅层特征可以包括词袋特征、n-gram特征或与参考答案之间的相似度特征等,显然,浅层特征也对待评测答题内容的评测结果产生影响,基于此,本申请实施例提出第二种确定待评测答题内容的评测结果的方法,如下:
第二种、基于深度特征和浅层特征,确定待评测答题内容的评测结果。
具体地,首先获取待评测答题内容的浅层特征。
然后,将浅层特征和上述确定的深度特征组合,得到组合特征。
可选地,组合方式可以为将表征浅层特征的浅层特征向量和表征深度特征的深度特征向量进行相加得到组合特征向量,该组合特征向量即为组合特征。
进一步地,将上述组合特征输入预置的评测模型,得到评测模型输出的待评测答题内容的评测结果。
可选地,预置的评测模型可以为预先训练好的评测模型,该模型可以为xgboost提升树模型,也可以是随机森林、决策树等机器学习模型,本申请实施例对此不作限定,其中,评测模型可以以答题内容样本的深度特征和浅层特征组合后的组合特征为训练样本,以标注的答题内容样本评测结果为样本标签训练得到。
基于此,将每一待评测答题内容的组合特征输入上述预置的评测模型,将得到评测模型输出的待评测答题内容的评测结果。
基于上述评测模型,可以实现自动确定评测结果的目的,相比人工评测方法,具有耗时短、效率高的优点,并且大大降低了人工成本。进一步,相比于仅基于浅层特征确定评测结果的评测方法,本方法在考虑待评测答题内容各自的文本特征的同时,充分考虑不同评测结果对应的答题内容之间的差异性,对于待评测答题内容提取深度特征,并基于由深度特征和浅层特征的组合特征确定评测结果,进一步提高了评测的准确性。
下面对本申请实施例提供的答题内容评测装置进行描述,下文描述的答题内容评测装置与上文描述的答题内容评测方法可相互对应参照。
参见图5,图5为本申请实施例公开的一种答题内容评测装置结构示意图。
如图5所示,该装置可以包括:
答题内容获取单元11,用于获取待评测答题内容;
深度特征确定单元12,用于确定待评测答题内容的深度特征,所述深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力;
评测结果确定单元13,用于基于深度特征,确定待评测答题内容的评测结果。
可选地,深度特征的获取方法可以包括多种,对应的,深度特征确定单元也可以有多种结构,以下介绍其中可选的两种:
第一种、深度特征确定单元包括:第一深度特征确定子单元,用于将待评测答题内容输入预置的深度特征确定模型,得到深度特征确定模型输出的待评测答题内容的深度特征。
其中,深度特征确定模型为,以相比于相同评测结果,对不同评测结果对应答题内容所确定的深度特征间的表征差异性更大为训练条件,和/或,以对差别越大的评测结果对应的答题内容所确定的深度特征间的表征差异性越大为训练条件训练得到。
第二种、深度特征确定单元包括:第二深度特征确定子单元,用于将待评测答题内容按照设定映射条件映射到多维欧式空间,得到映射后的深度特征,其中,设定映射条件包括:
相比于相同评测结果,不同评测结果对应答题内容在所述多维欧式空间中映射的深度特征间的表征差异性更大;和/或,
差别越大的评测结果对应的答题内容在所述多维欧式空间中映射的深度特征间的表征差异性越大。
可选地,本申请实施例介绍的答题内容评测装置还可以包括模型训练单元,该模型训练单元可以包括:
样本选取单元,用于选取多个n元组,每个n元组包含n个答题内容样本,且每个n元组中存在不同评测结果对应的答题内容样本,n大于等于3。
样本训练单元,用于以每个n元组为训练样本,以针对每个n元组中不同评测结果对应的答题内容所确定的深度特征向量间的距离大于相同评测结果的答题内容所确定的深度特征向量间的距离为训练条件,和/或,以针对每个n元组中差别越大的评测结果对应的答题内容所确定的深度特征向量间的距离越大为训练条件,训练深度特征确定模型。
进一步地,本申请实施例对上述提及的样本选取单元进行介绍,可以包括:
异常检测单元,用于对每一初始待评测答题内容进行异常检测,得到异常检测通过后的初始待评测答题内容。
聚类单元,用于对异常检测通过后的初始待评测答题内容进行聚类,得到多个聚类簇。
人工评测对象抽取单元,用于从每个聚类簇中抽取初始待评测答题内容,抽取后的初始待评测答题内容作为人工评测的对象。
n元组选取单元,用于从人工对初始待评测答题内容评测后得到的答题内容中,选取多个n元组。
可选地,异常检测单元可以包括:
出现概率确定单元,用于以每一初始待评测答题内容为目标对象,确定目标对象在所有初始待评测答题内容中的出现概率;
异常判断单元,用于基于目标对象的出现概率,确定目标对象是否通过异常检测。
可选地,提出本申请实施例对上述提及的评测结果确定单元进行介绍,其中评测结果确定单元可以包括两种,接下来,对此进行详细说明:
第一种、评测结果确定单元可以包括:
第一模型预测单元,用于将深度特征输入预置的评测模型,得到所述评测模型输出的待评测答题内容的评测结果,其中,评测模型为,以答题内容样本的深度特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
进一步地,本申请实施例介绍的答题内容评测装置还可以包括浅层特征确定单元,用于确定待评测答题内容的浅层特征。
基于此,介绍第二种评测结果确定单元的结果,其可以包括:
组合特征获取单元,用于将浅层特征和深度特征组合,得到组合特征;
第二模型预测单元,用于将组合特征输入预置的评测模型,得到评测模型输出的所述待评测答题内容的评测结果,其中,评测模型为,以答题内容样本的深度特征和浅层特征组合后的组合特征为训练样本,以标注的所述答题内容样本的评测结果为样本标签训练得到。
本申请实施例提供的答题内容评测装置可应用于答题内容评测设备,如pc终端、云平台、服务器及服务器集群等。可选的,图6示出了答题内容评测设备的硬件结构框图,参照图6,答题内容评测设备的硬件结构可以包括:至少一个处理器1,至少一个通信接口2,至少一个存储器3和至少一个通信总线4;
在本申请实施例中,处理器1、通信接口2、存储器3、通信总线4的数量为至少一个,且处理器1、通信接口2、存储器3通过通信总线4完成相互间的通信;
处理器1可能是一个中央处理器cpu,或者是特定集成电路asic(applicationspecificintegratedcircuit),或者是被配置成实施本发明实施例的一个或多个集成电路等;
存储器3可能包含高速ram存储器,也可能还包括非易失性存储器(non-volatilememory)等,例如至少一个磁盘存储器;
其中,存储器存储有程序,处理器可调用存储器存储的程序,所述程序用于:
获取待评测答题内容;
确定所述待评测答题内容的深度特征,所述深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力;
基于所述深度特征,确定所述待评测答题内容的评测结果。
可选地,所述程序的细化功能和扩展功能可参照上文描述。
本申请实施例还提供一种可读存储介质,该可读存储介质可存储有适于处理器执行的程序,所述程序用于:
获取待评测答题内容;
确定所述待评测答题内容的深度特征,所述深度特征具备相比于相同评测结果,对不同评测结果对应的答题内容的表征差异性更大的能力,和/或,具备对差别越大的评测结果对应的答题内容的表征差异性越大的能力;
基于所述深度特征,确定所述待评测答题内容的评测结果。
可选地,所述程序的细化功能和扩展功能可参照上文描述。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本申请。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本申请的精神或范围的情况下,在其它实施例中实现。因此,本申请将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!