基于强化学习的情感对话异步生成模型生成文本的方法与流程
本发明涉及人工智能技术领域,尤其涉及基于强化学习的情感对话异步生成模型生成文本的方法。
背景技术:
近年来,随着人工智能与机器人领域如火如荼的发展,情感计算(affectivecomputing)在人工智能的人机交互相关研究中的地位越来越重要,兼具情感与智能的人工智能有更高的实用价值和现实意义,情感对话在教育行业、管理行业、贸易方面以及健康领域有着重要发展和深刻影响。
基于先验知识库的索引与匹配模型和基于传统rnn的神经网络语言模型是目前使用广泛的两种情感对话模型,但这两种模型均存在着一些缺陷,以上两种模型虽然可以注意到情感因素在对话系统中的重要性,但取得的效果却不尽人意,不能够很好的挖掘对话内容中的情感要素,生成的回答情感强度不可控、不细致,难以充分发挥情感在对话中的作用,生成的句子显得十分生硬和呆板,因此本发明提出基于强化学习的情感对话异步生成模型生成文本的方法,以解决现有技术中的不足之处。
技术实现要素:
针对上述问题,本发明在分析用户情感的同时,通过结构预测器和关键词预测器生成合适的情感关键词,生成模块再以此为基础扩展出带有情感色彩的回复,生成的回答较具有更强的情感相关度、情感强度,更能够提升体验感,主题在回答中的表达更加清晰,通过异步解码器的异步生成框架,摒弃了一次性从左到右的生成全部的回复的做法,减少了单个解码器的压力,组合后的回答更加多样化。
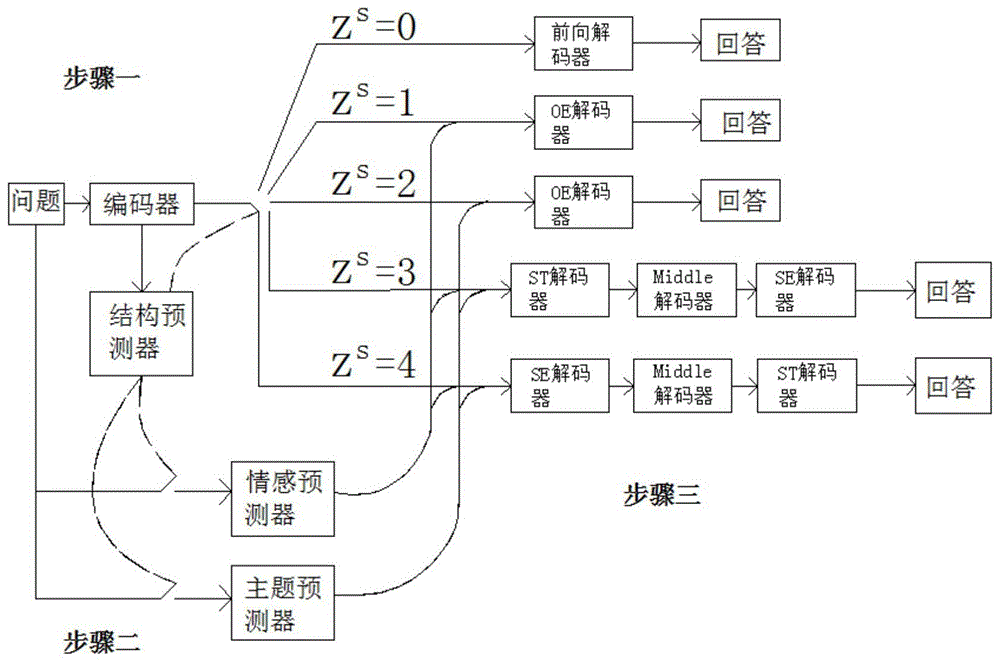
本发明提出基于强化学习的情感对话异步生成模型生成文本的方法,包括以下步骤:
步骤一:选择一个agent,设定所述agent中x代表外界环境输入的句子,y代表agent针对输入给出的回答,然后给定一个问句post,利用编码器对问句post进行编码;
步骤二:首先根据输入的问句post,使用结构预测器来预测回答中是否需要包含关键词,以及关键词之间的位置关系,其中关键词为情感关键词和主题关键词;
步骤三:基于步骤二中的预测结果,使用关键词预测器来生成对应的关键词,并将生成的关键词作为先验知识指导回答的生成;
步骤四:生成关键词之后,采用异步生成方法来生成文本,然后对生成的回答进行连贯度、主题相关度以及情感相关度的指标考量,为了促进各个指标之间的学习,引入基于参数共享的多任务学习策略,在回答的生成过程中共享编码器,在各个子句的生成过程中,使用同一个编码器使各个指标相互结合,从整体的角度去衡量一个句子的质量,并对生成的子句进行计算奖励。
进一步改进在于:所述步骤二中结构预测器没有预测到关键词时,使用一个普通的前向解码器来生成回答,结构预测器预测到一个情感关键词时,采用异步解码器从情感关键词向前、向后生成回答,结构预测器预测到只有一个主题关键词时,采用异步解码器从主题关键词向前、向后生成回答,结构预测器预测到包含主题关键词和情感关键词,且顺序为主题关键词在前,情感关键词在后时,以两个关键词为界限将句子分为三部分,采用异步解码器依次生成三个子句,结构预测器预测到包含主题关键词和情感关键词,且顺序为情感关键词在前,主题关键词在后时,以两个关键词为界限将句子分为三个部分,采用异步解码器依次生成三个子句。
进一步改进在于:所述步骤二中对于输入的问句post,首先利用编码器得出隐向量序列h,再通过一个全连接层算出zs,具体过程如公式(1)所示:
其中,
进一步改进在于:所述步骤三中采用关键词预测器生成对应的关键词时,首先利用预训练的lda模型对输入的问句post进行分析,预测回答的主题类别,引入主题类别向量和情感类别向量,由类别算出对应的向量,再利用类别向量进一步预测关键词,生成先验知识,最后采用注意力机制来强化情感特征。
进一步改进在于:所述步骤三中的先验知识需要综合,通过计算不同类别的知识向量k={ket,ktp}之间的相联度以及编码器的隐向量序列,作为注意力框架中的权重参数,其具体的计算细节如下公式(2)、(3)和(4)所示:
其中,*∈{et,tp}表示是主题或者情感,
其中,ck,et和ck,tp是利用公式(2)得出的,公式(5)和(6)可以看做是一种多类别的分类器,它会生成整个情感词典和主题词典上的概率分布,从而从词典中选出最合适的关键词。
进一步改进在于:所述步骤四中采用异步生成方法来生成文本的具体过程为:将步骤一中设定的句子x送入模型中转化为向量表示,从而使agent更新自身状态,做出相应的动作,生成对应的回答,使用随机取样策略得出回答语句,并使用policygradient策略进行网络训练。
进一步改进在于:所述步骤四中为了保证答在语法上具有优秀的连贯度,利用两个seq2seq模型来衡量回答的连贯度,回答y的流畅度计算公式如公式(7)所示:
其中,pseq2seq(y|x)代表seq2seq模型输出的概率分布,表示基于给定的句子x,生成回答y的概率;
进一步改进在于:所述步骤四中为了保证生成的回答的主题相关度高,需要再次使用预训练的lda模型对生成的回答进行主题类别预测,回答y的主题相关度计算公式如公式(8)所示:
其中,ktp为给定句子x的主题类别,lda(y)为lda模型对回答的主题预测概率分布,ntp表示主题类别的总数。
进一步改进在于:所述步骤四中为了保证生成的回答情感相关度高,需要利用卷积神经网络对生成的回答进行情感类别分类,根据预测结果来考察回答是否符合预先要求的情感类别,回答y的情感相关度计算公式如公式(9)所示:
其中,ket为指定的情感类别,det(y)为分类器对回答的预测概率分布,net表示情感类别的总数。
进一步改进在于:所述步骤四中对于一个动作a,其奖励是连贯度、主题相关度以及情感相关度指标的加权和,计算公式如公式(10)所示:
r(a,[x,y])=λ1r1+λ2r2+λ3r3(10)
为了加强对回答生成过程的约束,对每一个生成的子句都计算奖励,对于生成一句回答的动作的最终奖励为如公式(11)所示:
r(a,[x,y])=ret+rmd+rtp+r(11)
其中,ret,rmd和rtp分别表示三个子句yet,ymd和ytp的奖励,r表示回答被拼接、裁剪优化之后的奖励。
本发明的有益效果为:本发明在分析用户情感的同时,通过结构预测器和关键词预测器生成合适的情感关键词,生成模块再以此为基础扩展出带有情感色彩的回复,生成的回答较具有更强的情感相关度、情感强度,更能够提升体验感,主题在回答中的表达更加清晰,通过利用主题相关度奖励指标的约束,使得生成的回答能够紧扣问句主题,具有更强的逻辑性,通过异步解码器的异步生成框架,摒弃了一次性从左到右的生成全部的回复的做法,利用主题关键词和情感关键词之间不同组合的多样性,一步只生成序列的一部分,减少了单个解码器的压力,组合后的回答更加多样化。
附图说明
图1本发明方法流程示意图。
图2为本发明关键词预测器工作流程示意图。
图3为本发明异步解码器工作流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
根据图1、2、3所示,本实施例提出基于强化学习的情感对话异步生成模型生成文本的方法,包括以下步骤:
步骤一:选择一个agent,设定所述agent中x代表外界环境输入的句子,y代表agent针对输入给出的回答,然后给定一个问句post,利用编码器对问句post进行编码;
步骤二:首先根据输入的问句post,使用结构预测器来预测回答中是否需要包含关键词,以及关键词之间的位置关系,其中关键词为情感关键词和主题关键词,对于输入的问句post,首先利用编码器得出隐向量序列h,再通过一个全连接层算出zs,具体过程如公式(1)所示:
其中,
步骤三:基于步骤二中的预测结果,使用关键词预测器来生成对应的关键词,并将生成的关键词作为先验知识指导回答的生成,采用关键词预测器生成对应的关键词时,首先利用预训练的lda模型对输入的问句post进行分析,预测回答的主题类别,引入主题类别向量和情感类别向量,由类别算出对应的向量,再利用类别向量进一步预测关键词,生成先验知识,最后采用注意力机制来强化情感特征,先验知识需要综合,通过计算不同类别的知识向量k={ket,ktp}之间的相联度以及编码器的隐向量序列,作为注意力框架中的权重参数,其具体的计算细节如下公式(2)、(3)和(4)所示:
其中,*∈{et,tp}表示是主题或者情感,
其中,ck,et和ck,tp是利用公式(2)得出的,公式(5)和(6)可以看做是一种多类别的分类器,它会生成整个情感词典和主题词典上的概率分布,从而从词典中选出最合适的关键词;
步骤四:生成关键词之后,采用异步生成方法来生成文本,先将步骤一中设定的句子x送入模型中转化为向量表示,从而使agent更新自身状态,做出相应的动作,生成对应的回答,使用随机取样策略得出回答语句,并使用policygradient策略进行网络训练,然后对生成的回答进行连贯度、主题相关度以及情感相关度的指标考量,引入基于参数共享的多任务学习策略,在回答的生成过程中共享编码器,在各个子句的生成过程中,使用同一个编码器使各个指标相互结合,从整体的角度去衡量一个句子的质量,并对生成的子句进行计算奖励为了保证回答在语法上具有优秀的连贯度,利用两个seq2seq模型来衡量回答的连贯度,回答y的流畅度计算公式如公式(7)所示:
其中,pseq2seq(y|x)代表seq2seq模型输出的概率分布,表示基于给定的句子x,生成回答y的概率;
其中,ktp为给定句子x的主题类别,lda(y)为lda模型对回答的主题预测概率分布,ntp表示主题类别的总数,为了保证生成的回答情感相关度高,需要利用卷积神经网络对生成的回答进行情感类别分类,根据预测结果来考察回答是否符合预先要求的情感类别,回答y的情感相关度计算公式如公式(9)所示:
其中,ket为指定的情感类别,det(y)为分类器对回答的预测概率分布,net表示情感类别的总数,对于一个动作a,其奖励是连贯度、主题相关度以及情感相关度指标的加权和,计算公式如公式(10)所示:
r(a,[x,y])=λ1r1+λ2r2+λ3r3(10)
为了加强对回答生成过程的约束,对每一个生成的子句都计算奖励,对于生成一句回答的动作的最终奖励为如公式(11)所示:
r(a,[x,y])=ret+rmd+rtp+r(11)
其中,ret,rmd和rtp分别表示三个子句yet,ymd和ytp的奖励,r表示回答被拼接、裁剪优化之后的奖励。
本发明在分析用户情感的同时,通过结构预测器和关键词预测器生成合适的情感关键词,生成模块再以此为基础扩展出带有情感色彩的回复,生成的回答较具有更强的情感相关度、情感强度,更能够提升体验感,主题在回答中的表达更加清晰,通过利用主题相关度奖励指标的约束,使得生成的回答能够紧扣问句主题,具有更强的逻辑性,通过异步解码器的异步生成框架,摒弃了一次性从左到右的生成全部的回复的做法,利用主题关键词和情感关键词之间不同组合的多样性,一步只生成序列的一部分,减少了单个解码器的压力,组合后的回答更加多样化。
以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!