一种基于深度神经网络的软件缺陷定位方法与流程
本发明涉及软件测试
技术领域:
,具体来说,是一种基于深度神经网络(dnn)的多特征软件缺陷定位方法。
背景技术:
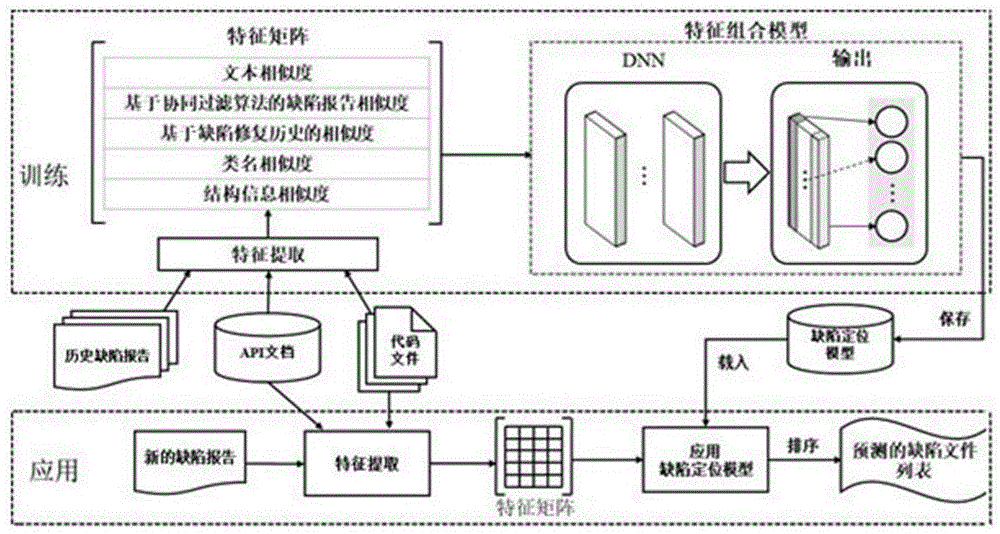
:对于一个大规模的软件系统,在软件开发和维护的整个生命周期,许多项目每天都会收到大量的缺陷报告。开发人员手动完成缺陷定位是一项具有挑战性且耗时的任务。自动缺陷定位研究旨在自动定位对缺陷报告负责的潜在错误文件,以帮助开发人员专注于解决错误文件。缺陷跟踪系统(例如bugzilla和jira)经常被用来记录和管理缺陷。一旦发现软件项目的异常行为,开发者或者用户可以把缺陷报告提交到缺陷跟踪系统。这些缺陷报告包含了许多字段,例如摘要和详细描述,它们描述软件的一个异常行为。这些字段对被分配去修复缺陷的开发者是非常重要的。通常,为了定位到一个缺陷报告对应的代码文件,开发者需要分析缺陷报告并查看大量代码文件,以便快速有效地修复它们。不幸的是,这些缺陷报告的数量通常对于开发者来说太大了。例如,到2016年12月,eclipse项目报告了5100万个缺陷。对于一个给定的缺陷,手动识别潜在的缺陷文件代价太大了。因此,为了减轻软件维护团队的负担,有效的自动缺陷定位方法需求很大。现有技术中几种自动化的缺陷定位方法已经被提出来帮助开发人员专注于潜在的缺陷文件。现有的方法可以分为三组:动态,静态和动静混合。动态方法通常通过收集和分析程序数据、断点和系统的执行轨迹来定位缺陷。这种方法依赖于在某些输入条件下跟踪一组成功或失败的测试用例的执行轨迹。基于频谱的缺陷定位,和基于模型的缺陷定位是两种众所周知的动态方法。动态方法通常耗时且昂贵,它的准确率高度依赖于测试套件的质量。在实际程序中,由于大多数测试套件可能没有足够的代码覆盖来定位缺陷,动态方法有可能不可取。另外一方面,静态方法不需要执行跟踪,并且可以在软件开发的任何阶段被运用。它们只需要缺陷报告和代码文件就能定位缺陷。信息检索(ir)是被广泛使用的静态技术,传统的基于ir的缺陷定位通常计算缺陷报告中包含的文本描述和代码文件中的标识符名称与注释之间的相似度,然后根据它们的相似度返回一组排好序的代码文件名称。为了提高基于ir的缺陷定位的准确性,还从缺陷报告和代码文件中提取了许多其他特征,例如结构化信息检索,缺陷报告中的元数据,动态分析,版本历史等。这些结合多个特征的方法总是比仅仅使用ir相似度的方法表现得更好。最近,机器学习技术被用于缺陷定位研究。这些方法通常采用训练好的机器学习模型,将缺陷报告的主题与代码文件的主题相匹配,或者将历史修复文件作为分类标签把代码文件分成许多类。王等人(wangs,chollakd,movshovitz-attiasd,etal.bugram:bugdetectionwithn-gramlanguagemodels[c].proceedingsofthe31stieee/acminternationalconferenceonautomatedsoftwareengineering.acm,2016:708-719)使用n-gram语言模型生成可能的缺陷列表。叶等人(yex,bunescur,liuc.mappingbugreportstorelevantfiles:arankingmodel,afine-grainedbenchmark,andfeatureevaluation[j].ieeetransactionsonsoftwareengineering,2016,42(4):379-402.)使用learningtorank方法对从代码文件、api描述、缺陷修复和代码变更历史中提取出的19个特征进行自适应排名。最近,深度学习被用于处理一些软件工程问题。霍等人(huox,lim,zhouzh.learningunifiedfeaturesfromnaturalandprogramminglanguagesforlocatingbuggysourcecode[c]//ijcai.2016:1606-1612.)尝试使用一个基于cnn的模型来学习缺陷定位的统一功能。肖等人(xiaoy,keungj,miq,etal.improvingbuglocalizationwithanenhancedconvolutionalneuralnetwork[c]//asia-pacificsoftwareengineeringconference(apsec),201724th.ieee,2017:338-347)将增强的cnn、新的rtf-iduf方法和与word2vec技术结合起来,以提高缺陷定位的性能。lam等人(laman,nguyenat,nguyenha,etal.buglocalizationwithcombinationofdeeplearningandinformationretrieval[c]//programcomprehension(icpc),2017ieee/acm25thinternationalconferenceon.ieee,2017:218-229.)结合了dnn和基于信息检索的方法来定位有缺陷的文件。尽管现有技术中已经提出了许多缺陷定位的方法,有些取得了一定的效果,但是实际缺点定位非常复杂和耗时,对于实际应用来说,定位准确性依然很差,缺陷报告中的自然语言文本与代码中的编程语言之间存在着显著的固有词汇不匹配。目前的实证研究表明,缺陷定位的准确性依赖于缺陷报告和代码文件之间的多个特征提取并以适当的方式组合这些特征,这将提高缺陷定位的性能。技术实现要素:针对现有技术中存在的软件缺陷定位复杂耗时,定位准确性差的问题,本发明提供一种使用多特征组合的基于深度神经网络的软件缺陷定位方法(dmf-bl,multiplefeaturebuglocalizationbasedondeepneuralnetwork),该方法仅提取了文本相似度、结构信息相似度、基于协同过滤算法的缺陷报告相似度、基于缺陷修复历史的相似度和类名相似度五个特征,取得了优异的软件缺陷定位性能。为实现上述技术目的,本发明采用的技术方案如下:一种基于深度神经网络的软件缺陷定位方法,包括如下步骤:s1:收集待测软件的相关数据访问缺陷跟踪系统获取软件的缺陷报告,使用git工具获取软件的代码文件及api文档;s2:数据预处理对s1中收集的缺陷报告进行预处理得到如下数据:缺陷报告集合每个缺陷报告xi代表缺陷报告中的一个单词,缺陷报告集合b的个数记为db;缺陷报告修复时间向量tl表示缺陷报告修复的时间;缺陷报告提交时间向量tsl表示缺陷报告bl提交的时间;对s1中获得的代码文件进行预处理得到如下数据:代码文件集合每个代码文件yj代表代码文件中的一个单词,代码文件集合s的个数记为ds;代码文件的名称向量单词snm表示代码文件的名称;对s1中获取的api文档进行预处理得到如下数据:api文档集合zk代表api文档的一个单词;api文档的名称向量dan表示api文档的名称;每个缺陷报告对应一组标签tagi表示缺陷报告所对应的代码文件的名称;其中l、m、n,i、j和k均为正整数;s3:为每个代码文件添加对应的api描述遍历代码文件集合s,对于每一个遍历向量若j=n时,yj=dan,则构成集合其中s4:提取如下五个特征s41:文本相似度分别构造缺陷报告向量空间和和代码文件的向量空间用于记录单词和单词出现的次数,和初始化为空集;遍历缺陷报告集合b,对于每一个向量都将其添加到向量空间中(重复单词会增加向量空间中对应单词出现的次数);遍历集合s′,对于每一个向量都将其添加到向量空间中;对于和保留单词出现次数较多的单词,舍去其余记录的单词,得到新的向量空间v′b和v′s;将和收尾相连形成新的词汇向量将相同的单词仅保留一个,并将单词出现的次数合并;由于和有可能包含同样的单词,所以vbs需要去除相同的单词,并将单词计数合并,所以的单词数量nbs≤1000;记di是缺陷报告集合b中包含单词xi的向量的数量,单词xi对应的逆文档频率遍历缺陷报告集合b,对于每一个向量设向量为在向量空间上的映射,大小为nbs,若xi属于向量空间单词xi在向量中出现的次数记为则单词xi在向量中出现的词频单词xi对应的权重大小记dj是集合s′中包含单词yj的向量的数量,单词yj对应的逆文档频率遍历集合s′,对于每一个向量设向量为在向量空间上的映射,大小为nst,若yj属于向量空间单词yj在向量中出现的次数记为fj,则单词yj在向量中出现的词频单词yj对应的权重大小遍历缺陷报告集合b和集合s′,对于每个向量组令nterm为向量的长度,缺陷报告和代码文件的文本相似度s42:基于协同过滤算法的缺陷报告相似度遍历代码文件集合s,对每一个代码文件建立逆标签集合cm,cm同时对应代码文件的名称snm,并初始化cm为空集;遍历缺陷报告集合b,对于每一个缺陷报告对应的标签将与进行对比,若便把向量添加至集合cm中,形成遍历缺陷报告集合b和代码文件集合s,对于每个向量组遍历集合cm,若计算与的余弦相似度,得相似度向量其中simn表示与的余弦相似度;将向量按从大到小的顺序排列,得到其中每个元素已做正则化处理计算缺陷报告和代码文件的基于协同过滤算法的缺陷报告相似度这里n≤3;s43:基于缺陷修复历史的相似度新建代码文件修复事件集合表示代码文件被修复的历程,初始化为空向量;遍历缺陷报告集合b,对于每一个缺陷报告都有其对应的tl和若则在向量中添加元素tl;遍历集合f,对于每一个向量将元素从晚到早顺序排列,得遍历向量和集合f,对于每个缺陷报告和代码文件若对应的提交时间为tsl,对应的修复事件向量为将中大于tsl的元素删除,得计算缺陷报告和代码文件的基于缺陷修复历史的相似度p为正整数,上述k值根据软件缺陷报告提交的频率决定;s44:类名相似度遍历缺陷报告集合b和向量对于每一个缺陷报告和代码文件名称snm,若记缺陷报告和代码文件的类名相似度反之,记将类名相似度归一化;s45:结构信息相似度将缺陷报告集合b拆分为集合summary和集合description,其中summary是缺陷报告中的summary,记description是缺陷报告中的description,记则将代码文件集合s拆分成四个集合class、method、var和comment,class是缺陷报告中的class,method是缺陷报告中的method,var是缺陷报告中var,comment是缺陷报告中的comment,记则遍历缺陷报告集合b和代码文件集合s,对于缺陷报告和代码文件使用简单共有词方法计算如下文本相似度:计算缺陷报告和代码文件的结构信息相似度s5:cnn非线性组合s51:使用步骤s4中的五个特征构造训练数据集,对于每一个缺陷报告有5×ds个特征值(因为代码文件有ds个,每个缺陷报告和代码文件都有五个特征值),构造特征值矩阵缺陷报告对应的标签为s52:构建卷积神经网络权重初始化采用标准正态分布;c1:卷积层共有12个卷积核和12个偏移量,其中5×1的卷积核3个,分别为得矩阵大小为1×ds;4×1的卷积核3个,分别为得矩阵大小为2×ds;3×1的卷积核3个,分别为得矩阵大小为3×ds;2×1的卷积核3个,分别为得矩阵大小为4×ds;c2:池化层采用单列最大池化策略,如矩阵池化结果为大小为1×ds;c3:采用矩阵拼接的形式构建新矩阵,共得到如下4个矩阵是由拼接而成,大小为4×ds;是由拼接而成,大小为4×ds;是由拼接而成,大小为4×ds;是由拼接而成,大小为4×ds;c4:卷积层共有3个卷积核和3个偏移量,卷积核大小为3×1,得12个矩阵,大小都为2×ds;c5:卷积层共有3个卷积核和3个偏移量,卷积核大小为2×1,得36个矩阵,大小都为1×ds;c6:全连接层,权重矩阵为偏移向量b6,c7:分类,将c6展开得代入下述公式,得缺陷报告的预测值向量其中,误差函数:采用梯度下降法更新参数;s6:对于新的缺陷报告通过s4计算5个特征值,构建特征矩阵,利用步骤s5已训练好的cnn模型,得出对应预测值向量对到进行大小排序,得可能具有缺陷的代码文件列表,排名越靠前可能性越大。进一步限定,所述缺陷报告、代码文件以及api文档通过文本分词、去停用词和提取词干的操作进行预处理得到缺陷报告集合b,代码文件集合s以及api文档集合d。文本分词算法是以空格、符号或段落为间隔,将文本分为单词组;去停用词采用国际通用的停用词表;提取词干采用porter词干提取法。本申请提出了软件缺陷定位方法利用缺陷报告和代码文件之间的相关性来增强缺陷定位的性能。而且,本申请只提取了5个有用的特征,包括文本相似度、结构信息相似度、基于协同过滤算法的缺陷报告相似度、基于缺陷修复历史的相似度和类名相似度。实验结果表明其性能超过了现有的方法。首先,本申请使用修订过的vsm(rvsm)提取特征来检测缺陷报告和代码文件之间的文本相似度。此外,api规范也被用作输入以桥接缺陷报告中的自然语言和代码文件中的编程语言之间的词汇差距。其次,从前修复过的代码文件也可能对应相似的缺陷报告。叶等人提出的协同过滤的方法使用相似缺陷报告的简单总和并不完全准确,本申请提出了一种识别可疑文件的改进方法,而不是使用简单的总和。实验证明,改进后的特征能提高缺陷定位的性能。第三,本申请使用了缺陷预测技术,它旨在预测哪个代码文件将来可能会出错。第四,如果缺陷报告在摘要或详细描述中提到类名,则可以使用类名信息来识别相应的代码文件。我们还使用类名相似度特征来定位可疑的代码文件。第五,我们整合了saha等人提出的结构信息,如代码文件的类和方法。最后,我们用dnn来结合五个特征,利用足够的训练数据,可以从非线性结合的数据中学习特征的权重。dnn与非线性函数的组合预期比基于ir的自适应学习的线性组合表现更好。本发明相比现有技术,具有如下有益效果:1、本申请提出的基于dnn的软件缺陷定位方法提取了五个特征,包括文本相似度、结构信息相似度、基于协同过滤算法的缺陷报告相似度、基于缺陷修复历史的相似度和类名相似度,而dnn方法能够整合所有分析数据,从而捕获特征之间的非线性关系。2、本申请对缺陷定位方法进行了大规模的评估,在超过23000个缺陷报告上运行了该定位方法,它们来自6个开源项目,包括eclipse、jdt、birt、swt、tomcat和aspectj。实验表明,我们的方法相比于目前最先进的方法,比如map和mrr,都有了大幅的提高。附图说明图1为本申请基于深度神经网络的软件缺陷定位方法的基本框架图;图2为porter词干提取法的流程图;图3为深度神经网络的结构图;图4为五个特征分别在6个项目上的map值。具体实施方式为了使本领域的技术人员可以更好地理解本发明,下面结合附图和实施例对本发明技术方案进一步说明。图1显示了本申请dmf-bl模型的整体框架。dmf-bl模型是把一组存储在缺陷追踪系统中的历史缺陷报告、一组系统的代码文件、在代码文件中使用的api描述和一个待定位的缺陷报告作为输入。我们将缺陷报告、代码文件和api描述预处理后提取了五个特征,并且建立了特征向量。这些特征包括:1)文本相似度;2)结构信息相似度;3)基于协同过滤算法的缺陷报告相似度;4)基于缺陷修复历史的相似度;5)类名相似度。每一个特征会对每一个段代码文件输出一个可疑度,这五个可疑度将被输入到深度神经网络模型中,以学习并找到缺陷报告所对应的代码文件位置。神经网络模型可以获取特征间的非线性关系,而且比将特征线性加权的方法更加合适。在提取特征之前,首先要对软件的缺陷报告、代码文件以及api描述进行预处理。1、数据预处理数据预处理(datapreprocessing)是指在主要的处理以前对数据进行的一些处理。在线问答社区的数据是英文文本数据,对应的数据预处理是英文文本预处理。英文文本的预处理方法和中文的有部分区别。首先,英文文本挖掘预处理一般可以不做分词(特殊需求除外),而中文预处理分词是必不可少的一步。第二点,大部分英文文本都是uft-8的编码,这样在大多数时候处理的时候不用考虑编码转换的问题,而中文文本处理必须要处理unicode的编码问题。而英文文本的预处理也有自己特殊的地方,第三点就是拼写问题,很多时候,预处理要包括拼写检查,所以需要在预处理前加以纠正。第四点就是词干提取(stemming)和词形还原(lemmatization),原因主要是英文有单数,复数和各种时态,导致一个词会有不同的形式,比如“countries”和"country","wolf"和"wolves",需要将这些词用同一个词来表示。总的来说,对于缺陷报告、代码文件和api描述中的文本数据进行预处理,需要经过这样几个步骤:文本分词、去停用词和提取词干。下面将对这些预处理方法做一些说明。1.1分词算法文本分词是数据预处理过程中不可缺少的部分,因为在建立索引和查询的过程中,是需要使用文本中的每一个单词作为一个表征文本,以基本的表征文本为单位。分词质量对于基于词频的相关性计算来说是无比重要的,而本次研究对象是英文文本,英文语言的基本单位就是单词,所以分词相对于中文来说较容易。大多数分词算法是以空格、符号或段落为间隔,将文本分为单词组,使用的正则表达式如下:1.2去停用词在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为停用词(stopwords),去停用词是文本数据处理阶段中很重要的一个环节。对于一个给定的目的,任何一类的词语都可以被选作停用词。通常意义上,停用词大致分为两类。一类是人类语言中包含的功能词,这些功能词极其普遍,与其他词相比,功能词没有什么实际含义,最普遍的功能词是限定词(“the”、“a”、“an”、“that”、和“those”),这些词帮助在文本中描述名词和表达概念,如地点或数量。介词如:“over”,“under”,“above”等表示两个词的相对位置。这些功能词的两个特征促使在搜索引擎的文本处理过程中对其特殊对待。第一,这些功能词极其普遍。记录这些词在每一个文档中的数量需要很大的磁盘空间。第二,由于它们的普遍性和功能,这些词很少单独表达文档相关程度的信息。如果在检索过程中考虑每一个词而不是短语,这些功能词基本没有什么帮助。另一类词包括词汇词,比如'want'等,这些词应用十分广泛,但是对这样的词搜索引擎无法保证能够给出真正相关的搜索结果,难以帮助缩小搜索范围,同时还会降低搜索的效率,所以通常会把这些词从问题中移去,从而提高搜索性能。去停用词的步骤包括建立停用词表和检索停用词表两步。停用词表的建立方式有两种,人工建立和基于概率统计自动建立。人工建立指的是通过人的主观判断或根据实际经验而建立的停用词表。基于概率统计的停用此表是根据词频信息通过一定算法构建停用词表。1.3提取词干词干提取(stemming)是英文文本预处理的特色。词干提取是词形规范化处理的重要技术之一,主要应用于信息检索和文本处理。在检索系统中,对文本中的词进行词干提取,能够减少词的数量,缩减索引文件所占空间,并且使检索不受输入检索词的特定词形的限制,扩展检索结果,提高查全率。词干提取主要就是根据语言形态中的规律进行处理的,去除屈折或派生形态的词缀,获得词干。因此,只有掌握语言构成特点,深入解析语言形态变化,才能发现其中规律,提高词干提取的准确性。目前,在信息检索和文本处理应用当中,词干提取还是较为浅层的词形规范化技术,不考虑词性、语义等复杂问题,主要是进行词形的统一。词干提取目前有3大主流算法porterstemming、lovinsstemmer和lancasterstemming。本申请主要使用porterstemming(porter词干提取法),其算法主要流程如图2所示。2、特征提取dmf-bl将一个缺陷报告-代码文件对(b,s)表示为一个含有k个特征的向量i。我们提取了五个特征来捕获缺陷报告和代码文件之间的隐含关系。这些功能还通过使用项目特定的api文档来桥接缺陷报告和代码文件之间的词汇差距。表1总结了dmf-bl模型中使用的五个特征。1)文本相似度;2)结构信息相似度;3)基于协同过滤算法的缺陷报告相似度;4)基于缺陷修复历史的相似度;5)类名相似度表1dmf-bl模型中使用的五个特征2.1文本相似度通常,缺陷报告是用自然语言表示的,而代码文件用编程语言表示。我们可以将缺陷报告和代码文件看作文本文档然后计算它们之间文本相似度。经典的文本相似度测量使用vsm(vectorspacemodel)和tf-idf将缺陷报告和代码文件建模为术语频率向量,并使用余弦相似度计算每个代码文件和缺陷报告之间的相似度。多年来,已经提出了许多方法来改进vsm模型的性能。周(j.zhou,h.zhang,andd.lo,“whereshouldthebugsbefixed?-moreaccurateinformationretrieval-basedbuglocalizationbasedonbugreports,”inproceedingsofthe34thinternationalconferenceonsoftwareengineering,ser.icse’12.ieeepress,2012,pp.14–24.)提出了rvsm(revisedvectorspacemodel),它可以通过调整大文件的排名并结合更有效的术语-频率变量来帮助定位相关的缺陷文件。在本文中,我们采用rvsm,因为它已被证明比传统的vsm具有更好的性能。对于缺陷报告,我们提取了摘要和详细描述来创建特征表示。对于代码文件,除了代码文件中使用的注释和标识符之外,我们还提取了字符串文字,每个代码文件后面也添加了对应的api描述。在缺陷报告和代码文件进行预处理之后,所有输入文本数据都被标记为单个术语或单词。假设{x1,x2,…xn}和{y1,y2,…yn}分别是从缺陷报告和代码文件中提取的术语,其中n是所提取术语的总数。为了测量缺陷报告和代码文件之间的相似度,这两种类型的术语向量应该在相同的高维空间中。因此,如果从所有的缺陷报告集合中提取出了nb个单词,b={b},并且还从所有的代码文件集合中提取了nf个单词,f={f},然后我们将其结合成大小为n=nb+nf的单词向量,并用这个组合向量来模拟每个缺陷报告bi(i={1,…,|b|})和每个代码文件fj(j={1,…,|f|}),使它们在相同的n维向量空间中。在传统的vsm中,缺陷报告和代码文件之间的相关性得分被称为它们对应的向量之间的标准余弦相似度,其计算方法见等式(2)。基于单词频率(tf)和逆文档频率(idf)计算出单词权重w。在rvsm中,tf(t,d)的对数变量用于帮助平滑高频术语的影响并优化经典vsm模型。在等式(3)中,ftd指的是文档d中的单词t出现的次数。文档向量中的每个权重w由等式(4)计算。其中dt表示包含单词t的文档数,d表示存储库中的文档总数。tf(t,d)=log(ftd)+1(3)由于较大的代码文件往往具有较高的包含缺陷的可能性。因此,在缺陷定位时,rvsm把较大的文件排得比较靠前。在等式(5)中,#terms表示文档d中的单词总数,函数g被定义为模型文档长度,其中n(#terms)是#term的规范化值。这里,我们使用min-max来规范化#terms的值,并把它作为指数函数e-x的输入。e-x是一种逻辑函数,它确保较大的文档在排名时获得较高的分数。然后按照等式(4)计算rvsm分数。它可以直接用作计算每个代码文件和缺陷报告之间相似度分数的特征。2.2基于协同过滤算法的缺陷报告相似度软件存储库中有大量历史修复缺陷报告。许多类似的缺陷报告可能与一个相同的代码文件有关。如果先前修复过的报告与当前缺陷报告在文本上相似,那么这些相似缺陷报告相关的缺陷文件也可能与当前报告相关。协同过滤是一种广泛应用于零售、社交媒体和流媒体服务的技术,其基于这样的想法:对于某些事物感兴趣的人在其他事物中也可能具有相似的品味。它在解决历史类似缺陷报告时也是适用的,因为它们始终与相同的缺陷有关。叶等人采用协同过滤的方法来提高缺陷定位的准确性。但是,他们采用了一种简单地将相似缺陷报告相加的办法。如等式(6)所示,他们计算当前缺陷报告的文本与所有历史缺陷报告br(b,s)的摘要之间的文本相似度,这些摘要与相同的已修复代码文件有关。score2=sim(b,br(b,s))(6)本申请针对现有协同过滤算法计算缺陷报告相似度的方法进行改进,其主要步骤如下:步骤1:遍历代码文件集合s,对每一个代码文件建立逆标签集合cm,并初始化cm为空集;遍历缺陷报告集合b,对于每一个缺陷报告对应的标签将与进行对比,若便把向量添加至集合cm中;遍历缺陷报告集合b和代码文件集合s,对于每个向量组遍历集合cm,若计算与的余弦相似度,得相似度向量其中simn表示与的余弦相似度;将向量按从大到小的顺序排列,得到其中每个元素已做正则化处理步骤2:计算新的缺陷报告和某一个代码文件之间的相似度,需要找到所有代码文件有错并已被修复的缺陷报告集合{b1,b2,b2…bn};步骤3:取中最大的前k个相似度值带入公式(7),计算和缺陷报告集合{b1,b2,b2…bn}中每个缺陷报告的基于协同过滤算法的缺陷报告相似度得分公式,即2.3基于缺陷修复历史的相似度版本控制系统中由许多代码文件变更历史数据。当缺陷被发现时,开发人员需要修复缺陷文件。然而,缺陷文件可能会在修复缺陷之前又产生新的缺陷。缺陷修复历史记录提供的信息可以帮助预测容易出错的代码文件。缺陷预测技术可以在用户或开发人员发现异常行为之前预测缺陷文件,这可以提供额外的特征来量化代码文件的缺陷倾向。缺陷修复历史信息可以用于帮助预测容易出错的文件。被预测容易出错的文件具有较高的可疑分数。kim等人(d.kim,y.tao,s.kim,anda.zeller.whereshouldwefixthisbug?atwo-phaserecommendationmodel.ieeetrans.softw.eng.,39(11):1597-1610,nov.2013.)提出了bugcache,它使用先前缺陷的位置信息并维护一个大多数容易出错的代码文件或方法的相对较短的列表。它创建了一个“缓存”文件,这个文件预计在特定提交时容易出错。rahman等人(f.rahman,d.posnett,a.hindle,e.barr,andp.devanbu.bugcacheforinspections:hitormiss?inproceedingsofthe19thacmsigsoftsymposiumandthe13theuropeanconferenceonfoundationsofsoftwareengineering,esec/fse’11,pages322-331,newyork,ny,usa,2011.acm.)发现了一种更简单的算法,它只能根据缺陷修复提交的数量来预测容易出错的文件。实验表明,该算法更加简单有效,但是运行起来几乎和bugcache是一样的。lewis等人(lewisc,our.bugpredictionatgoogle[j].url:http://google-engtools.blogspot.in/2011/12/bug-prediction-at-goodle.html.2011.)改变了rahman等人的算法并提出了一个新算法,这个算法被称为时间加权风险(tmr)。tmr通过谷歌系统上的缺陷修复提交情况来预测缺陷文件,它的结果简单快捷。因此,我们决定使用和修改这种经过良好测试的tmr方法,以便从缺陷修复历史文件中找到容易出错的文件。它的定义如下:w=mints(ts∈hk)(9)其中hk是指在提交缺陷报告前k天发现的缺陷文件集b。k是由用户指定的,参数k的设置在实验部分将会说明。值ts是缺陷修复提交的输入缺陷报告之间经过的天数。在lewis等人提出的算法中,w定义了衰退的程度。在本申请中,w定义了代码文件的重要性,它表示缺陷修复提交和当前缺陷报告之间的最短时间,如公式(9)所示。w越大,输出越小。此算法的输出是每个代码文件对应的可疑分数。2.4类名相似度在许多缺陷报告中,我们可以发现在摘要或者详细描述中都直接提到了类名,这提供了一个有用的信号:相关的类文件可能负责这个错误报告。例如,swt中id为255600的缺陷报告标记化后的详细描述包含类名“viewerattributebean,viewer,attributeandbean”,但是只有最长名称“viewerattributebean”是相关文件。因此,当类名更长时,它更具体。我们将缺陷报告与每个代码文件的名称进行比较,如果能在缺陷报告中获取到名称,则根据类名的长度得到一个score4(b,s)的值,否则为0。s.class表示代码文件s的类名,|s.class|是名称的长度。然后,我们根据等式(10)计算类名相似度。这个特征的值的范围可能很大。使用特征缩放可以使所有的特征处于一个相同的范围,从而使它们彼此具有可比性。min-max标准化用于标准化score4(b,s)。2.5结构化信息tf-idf模型为所有的单词赋予相同的权重。但是,有时缺陷报告只与类或方法名称类似,但与其他所有内容不同,由于其数值很大,导致余弦值很小,关键信息可能会被其他标识削弱。在这种情况下,我们认为基于代码结构的结构信息检索能够实现更加准确的缺陷定位。saha等人(r.k.saha,m.lease,s.khurshid,andd.e.perry,“improvingbuglocalizationusingstructuredinformationretrieval,”inproceedingof28thieee/acminternationalconferenceonautomatedsoftwareengineering,ser.ase’13,siliconvalley,ca,usa,november11-15,2013,pp.345–355.)基于结构化检索提出了bluir来进行缺陷定位,以提高技术的准确性。我们采用bluir方法将错误报告b解析为两个字段:b.summary和b.description,并将代码文件解析为四个字段:s.class,s.method,s.variable和s.comment。这些字段中的每一个都表示为遵循相似度计算过程的向量,然后对八个相似度求和。结构组件特征得分可以如下计算:其中bp是缺陷报告中的特定字段,sp是代码文件中的特定字段,而sim(bp,sp)是bp和sp的向量表示的余弦相似度。输出的结构是一组可疑分数,每个可疑分数对应一个文件。3、深度神经网络(dnn)结构以合适的方式组合上述有益特征可以改善缺陷定位的性能。现有方法始终将特征与预设权重线性结合。然而,线性模型难以不捕捉特征之间的非线性关系,这就可能限制定位的性能。dnn因为其具有出色的容量,在处理输入和输出之间高复杂度的非线性关系获得了成功,受到它的启发,我们使用dnn作为非线性特征的组合器来计算最终的可疑性分数。dnn是一种前向传递的人工神经网络,在输入和输出层之间有多个隐藏层,如图3所示,其中较高层能够组合来自较低层的特征。在本申请基于dnn的软件缺陷定位中,提取出来的特征可以作为五个输入向量并被送到输入层。dnn通过隐藏层中的非线性函数转换输入特征,然后通过输出层中的线性函数对这些要素进行分类。在dnn中,隐藏层具有抽象效果,隐藏层的数量决定了网络提取特征的处理能力。在实验中,我们发现dnn中隐藏的层越多,使用的计算资源就越多。隐藏层数超过3层以后,训练时间将大大增加。因此,我们在dnn模型中选择3个隐藏层。通常,当训练样本确定时,输入和输出层的节点也可以确认;因此,确定节点数也很重要。如果隐藏的节点数量太少,则不具备必要的学习能力和信息处理能力。相反,如果隐藏的节点数量太多,网络结构的复杂性将大大增加,网络可能在学习过程中陷入局部极小。而且,网络的学习速度也会变慢。根据公式和已知条件(输入层有五个节点,输出层平均有近3000个节点),我们将隐藏节点的数量设置为9,12和7。假设l-1层有m个神经元,对于l层中第j个节点的输出,我们有等式(12)个输出层。其中是l层中第j个节点的值,是l-1层中第k个神经元到第l层中第j个神经元的权重,是输出中第j个节点的偏移量;σ是一个类似于sigmoid或者relu函数的非线性函数。4、评估实验为了评估dmf-bl的有效性,在这个部分,我们在六个开源的软件项目上进行了实验,并且把它和三种目前最先进的缺陷定位算法进行了比较。4.1数据集为了进行比较,我们使用叶等人提供的相同的数据集来对learning-to-rank进行评估。这个数据集总共包含超过22000个缺陷报告,它们来自六个已公开的开源项目,包括:eclipseplatformui,jdt,birt,swt,tomcat和aspectj。表2详细描述了这个数据集。这些项目都把bugzilla作为缺陷跟踪系统,并且把git作为版本控制系统(早期的版本控制从cvs/svn转移到git)。所有的缺陷报告、代码文件存储库链接、错误文件和api规范都已经在发布在http://dx.doi.org/10.6084/m9.figshare.951967。根据需要,可以自行下载。表2基准数据集projecttimerange#bugreports#sourcefiles#apientrieseclipse10/01–01/14649534541314jdt10/01–01/14627481841329birt06/05–12/1341786841957swt02/02–01/1441512056161tomcat07/02–01/1410561552389aspectj03/02-01/04593443954对于每个项目中按时间顺序排列的缺陷报告,我们把它分成两个部分,其中80%作为训练集(较旧的缺陷),另外20%作为测试集(较新的缺陷)。在检查错误分类的实验结果时,我们发现在训练集(较旧的缺陷)中找不到一些新的错误文件,但是它们却对应了测试集中许多缺陷报告(较新的缺陷)。在本文中,我们提取了缺陷修复历史和协同过滤这两个特征,并且它们两个都需要一些历史缺陷修复数据。然而,在这种情况下,我们的方法并不能对这些从未被训练的错误文件产生作用。因此,我们将在测试集中与新的java文件相关的一些缺陷报告与训练集中的缺陷报告进行了交换。这种交换所带来的性能提升将会在下面进行说明。4.2评估指标为了对我们所提出的缺陷定位方法进行有效性评估,我们采用了三种主流的评估指标:top-n排序,平均精度(map)和平均倒数排名(mrr)。top-n排序:这个指标记录了其关联的缺陷代码文件在返回结果中前n(n-=1,5,10)排名的缺陷数。给定一个缺陷报告,如果前n个查询结果里面包含至少一个正确的建议,那么我们认为这个缺陷定位是准确的。这个指标的值越高,则缺陷定位的性能越好。平均精度(map):map是最常见的评估排序方法的ir指标,它计算了所有缺陷报告的平均精度。因此,map强调了所有的缺陷文件而不是第一个。单个查询的平均精度计算如下:其中k是返回的已排序文件中的排名,m是排名文件的数量(件),pos(k)表示第k个文件是否是错误文件,p(k)是给定顶部截止排名k的精度,计算如下:平均倒数排名(mrr):mrr是一个统计值,用于评估生成对于一个查询的可能响应列表的过程。一个查询的倒数排名是返回的已排序文件中第一个错误文件的位置的乘法逆。mrr是所有查询的倒数排名的平均值:4.3实验结果这部分展示了dmf-bl在表1所示的六个项目上执行缺陷定位的评估结果。我们将dmf-bl与以下三种最新的最先进的缺陷定位方法和一个基线进行了比较:方法1:leaningtorank(yex,bunescur,liuc.mappingbugreportstorelevantfiles:arankingmodel,afine-grainedbenchmark,andfeatureevaluation[j].ieeetransactionsonsoftwareengineering,2016,42(4):379-402.)通过代码文件的功能分解将领域知识用于方法、api描述、缺陷修复历史和代码变成历史。方法2:buglocator(j.zhou,h.zhang,andd.lo,“whereshouldthebugsbefixed?-moreaccurateinformationretrieval-basedbuglocalizationbasedonbugreports,”inproceedingsofthe34thinternationalconferenceonsoftwareengineering,ser.icse’12.ieeepress,2012,pp.14–24.)是一种总所周知的缺陷定位技术,它根据文本相似度、代码文件的大小以及以前缺陷修复的信息对代码文件进行排名。方法3:vsm方法根据代码文件和缺陷报告的文本相似度对其进行排名。为了进行比较,我们实现了用于评估其他三种方法的相同数据集。表3展示了所有程序的实验结果。通过比较每一个系统的指标,我们发现dmf-bl和learningtorank比buglocator和vsm结果更好。dmf-bl只用了五种特征。相比于learningtorank使用了19种特征,已经少了太多。然而,在结果上,dmf-bl的表现优于learningtorank太多。在aspectj中,dmf-bl成功定位了40.2%的缺陷;在eclipse中找到了40.2%的错误;在tomcat中,排名前1位的错误也找到了43.4%。对于其他指标也观察到了同样的趋势。与learningtorank方法相比,在前1的准确性上提高了7.5-33.5%;在前5的准确性上,提高了4-28.4%;在前10的准确性上,提高了3-35%。和buglocator相比,无论是前1、前5还是前10,dmf-bl都表现得更好。在map和mrr方面,aspectj得分为0.40和0.45,birt得分为0.21和0.23,优于其他三种方法。在swt中,dmf-bl要比其他方法好很多,map(0.51)比learningtorank高27.5%。dmf-bl的平均mrr比learningtorank高8.6%。dmf-bl持续较高的map和mrr也表明dmf-bl产生的有缺陷文件的整体排名也比learningtorank、buglocator和vsm要好。表3bmf-bl与其他算法之间的性能比较dmf-bl在缺陷定位上使用了五种不同的特征。为了评估每个特征对性能的影响,我们选择在不使用dnn的情况下使用每种特征进行排名,然后计算每个特征的map。图4中的结果显示了这五种特征在每一个项目上的map值。例如,在aspectj中使用文本相似度特征,系统可以获得0.2644的最佳map。当在aspectj中使用缺陷修复历史特征时,系统获得了0.2469的第二高map。另一方面,在tomcat中使用相同的缺陷修复历史特征时,系统得到了0.0373的最低map值。这说明每个特征在不同的项目中扮演者不同角色。根据图4,计算缺陷报告和代码文件之间的词汇相似度的文本相似度特征是aspectj、eclipse和tomcat项目最重要的特征。用于测量新缺陷报告与之前修复过的缺陷报告之间的相似度的协同过滤特征,是项目birt、jdt和swt的最重要的特征。总而言之,最重要的特征是文本相似度和协同过滤,其他特征提供了补充信息,进一步提高了定位的性能。缺陷定位是一项具有挑战性且耗时的任务。因此,对于一个给定的缺陷报告,我们需要开发一种自动缺陷定位技术。在本文中,我们提出了dmf-bl,这是一种基于深度学习的模型,它结合了缺陷报告和代码文件之间的五个特征。dmf-bl通过api规范、缺陷修复历史和代码文件的结构信息来利用项目知识。实际缺陷定位任务的实验结果表明,dml-bl在缺陷定位上比最先进的ir和机器学习技术表现得更好。以上对本发明提供的基于深度神经网络的多特征缺陷定位方法进行了详细介绍。具体实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本
技术领域:
的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1