一种由粗到细的视频目标行为识别方法与流程
本发明涉及视频中行为识别领域,尤其是涉及一种由粗到细的视频目标行为识别方法。
背景技术:
不同于基于图像的识别和检测,基于视频的内容和人体行为分析是人类视觉理解目前具有较大困难和挑战的任务。视频人体行为识别作为视频异常行为检测、关系推理与内容深度理解的基础研究,一直以来受到研究者的广泛关注。
目前较为成熟的行为识别方案根据应用场景和信息源的不同可以分为两类:(1)基于背景建模的模板匹配。该方法主要将视频中运动目标,即将输入的静态图像进行场景分割,利用帧差法或背景建模方法,分割出视频前景与背景,再在前景中提取特定运动目标,生成运动模板,利用巴氏距离(bhattacharyyadistance)等匹配相似运动。这类方法适用于简单的实验室环境行为,分辨识别的行为种类数受限。(2)基于统计学习。即将所有已知属于某一类行为的视频收集起来形成训练集,基于一个人工设计的算法对训练集视频提取特征。提取的特征一般为视频行为人的轨迹、纹理、梯度直方图和轨迹直方图等信息。继而根据大量的训练样本的特征库来构建行为识别分类器。分类器一般可用支持向量机(supportvectormachine,svm)和神经网络等模型。
综合而言近年来基于统计学习的行为识别算法表现较优,基于统计学习的行为识别算法可以分为传统人工特征行为识别算法以及深度网络特征行为识别算法。
传统人工特征行为识别算法主要是指利用人工设计的特征,来进行行为建模和分类。可根据运动前景和视频中的连续序列特点构建运动能量图(motionenergyimage,mei)和运动历史图(motionhistoryimage,mhi)模板(therecognitionofhumanmovementusingtemporaltemplates.ieeetransactionsonpatternanalysisandmachineintelligence,2001,23(3):257–267),继而通过计算其二值图的轮廓和灰度图的梯度直方图等信息,对运动进行分类判断;但该算法实验环境为室内,背景单一,人的行为具有特例性,无法在现实生活场景中得到有效利用。基于局部特征的方法主要是基于视频序列中时空兴趣点(spatio-temporalinterestpoints,stip)如wang等人提出的密集轨迹(improveddensetrajectories,idt)特征(actionrecognitionwithimprovedtrajectories.ieeeinternationalconferenceoncomputervision.2013:3551–3558.)。该特征通过采集图像金字塔上的密集轨迹,提取轨迹邻域像素的特征描述子如梯度直方图(histogramofgradient,hog)和光流直方图(histogramofflow,hof)等作为该轨迹的特征。idt描述子设计复杂且对现实多变场景行为仍具有局限性。
随着深度学习在图像领域取得了巨大进步,研究者也开始在视频上应用卷积神经网络。根据提取时域信息方式不同,基于深度学习视频行为识别可分为多流网络特征融合、时空注意力特征(包括循环神经网络,结合人体姿态特征网络)和3d时空网络特征。例如:基于simonyan等人提出的双流法(two-streamconvolutionalnetworksforactionrecognitioninvideos.advancesinneuralinformationprocessingsystems,2014,1(4):568–576),wang提出(temporalsegmentnetworks,tsn)将视频分成多段(clips),对每个分段的视频帧密集采样,融合多段序列的cnn特征,加强视频中时域上特征的学习。基于循环神经网络主要将时域上多帧输入到记忆网络,通过训练记忆网络学习时域上不同视频行为特征;并且结合人体姿态关节点信息,进一步学习时空特征。tran等人提出c3d(learningspatiotemporalfeatureswith3dconvolutionalnetworks.proceedingsoftheieeeinternationalconferenceoncomputervision.2015:4489–4497.)与carreira等人提出的i3d(quovadis,actionrecognition?anewmodelandthekineticsdataset.ieeecomputervisionandpatternrecognition.2017:4724–4733.)等指出由于目前行为视频数据集数据量少,3d神经网络较难学到较好特征。后续的p3d(learningspatio-temporalrepresentationwithpseudo-3dresidualnetworks.2017ieeeinternationalconferenceoncomputervision(iccv).2017:5534–5542.)和s3d(rethinkingspatiotemporalfeaturelearningforvideounderstanding.arxivpreprint,2017)进一步优化3d神经网络结构,提高识别精确率。但是该类方法缺少语义、注意力机制等信息指导,需要大规模视频数据集来训练,增加了存储消耗和计算量。
上述行为识别方法旨在通过单阶段识别框架对行为视频进行分类识别。在实际应用中我们发现,视频中某些行为具有相似性,可以将相似细粒度类别行为聚类成同一个粗粒度类别,针对性的训练不同分类器,使得分类器具有识别该细粒度类似行为之间的差异特性。利用全局特征如全身和上下文信息,加权具有较大差异的行为类别的特征表达,训练一个粗粒度分类器,以便能更好的区分粗粒度类行为。即加权全局信息训练粗粒度分类器,加权具体身体部位信息训练细粒度分类器,最后结合二者分类识别结果形成层次化的行为识别框架。
技术实现要素:
针对上述发现并针对单阶段视频行为识别方法存在的相似行为易分类错误的不足,本发明的目的是提供一种由粗到细的视频目标行为识别方法,该识别方法不仅可以分析不同身体部位及身体部位组合对不同行为识别的影响,也可以针对性分类相似行为,降低相似行为识别错误率。
本发明的目的是这样实现的:
一种由粗到细的视频目标行为识别方法,特征是:具体步骤如下:
a、利用现有成熟的姿态估计算法或者视频内标注信息获取人体关键点信息,裁剪缩放人体不同身体部位图像:上半身,左手部,右手部,下半身部和全身部五个部位;
b、以深度神经网络(deepneuralnetworks,dnn)作为特征提取网络,通过卷积神经网络(convolutionalneuralnetwork,cnn)对输入视频的连续帧和光流帧中的不同部位区域进行多层卷积、池化和全连接运算,提取不同视频i中不同部位pj视频的特征向量
c、利用提取出的不同部位和全局视频特征向量
d、训练细粒度分类器;每个细粒度分类器选取不同部位特征向量级联
e、将粗粒度分类器概率
在步骤c中,利用提取出的不同部位和全局视频特征向量,迭代训练分类器,寻找最优粗分类类别与粗粒度行为类别里所包含的细粒度行为种类,是指:利用真值映射方案,迭代训练粗粒度分类器,将行为类别映射至不同粗类别,直到粗分类器输出粗类别错误率低于阈值。
在步骤d中,每个细粒度分类器选取不同部位视频特征向量级联,针对当前包含的多种细粒度行为训练,是指:针对相似行为聚合成的一个细粒度行为集合,组合加权行为人身体部位特征表达,达到细粒度分类更准确的目的。
在步骤e中,将两级即粗粒度分类器和细粒度分类器分类结果概率融合,得到整个行为识别最终结果,是指:将在步骤c和在步骤d得到的粗粒度结果和多个细粒度分类器结合,形成由粗到细的行为识别框架;利用细粒度分类器分类相似行为的特点,提高行为识别准确率。
本发明将某些具有相似性行为类别聚类成同一个粗粒度类别,针对性的训练不同细粒度分类器,使得分类器具有识别该细粒度类似行为之间的差异特性。利用身体部位信息加权细粒度分类器特征表达,利用全局特征如全身和上下文信息,加权这些具有较大差异的粗粒度行为类别的特征表达。即加权全局信息训练粗粒度分类器,加权具体身体部位信息训练细粒度分类器,最后结合二者分类识别结果形成层次化的行为识别框架。
因此,本发明通过构造一个由粗到细的行为识别框架,利用级联行为人不同身体部位不同粒度的特征表达,针对性的训练行为分类器,从而有效地降低分错相似行为概率,提高了整体行为识别准确率。
附图说明
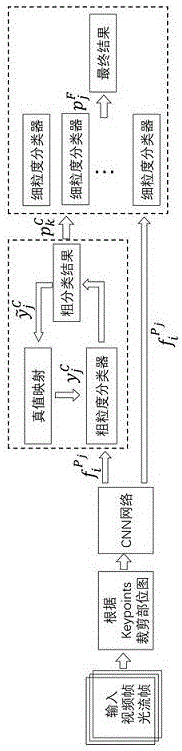
图1为由粗到细的视频目标行为识别的示意图。
具体实施方式
下面对照实施例并结合附图对本发明作进一步的说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
一种由粗到细的视频目标行为识别方法,将某些具有相似性行为类别聚类成同一个粗粒度类别,针对性的训练不同细粒度分类器,使得不同细粒度分类器具有识别该细粒度类似行为之间的差异特性。利用身体部位信息加权细粒度分类器特征表达,利用全局特征如全身和上下文信息,加权这些具有较大差异的粗粒度行为类别的特征表达。即加权全局信息训练粗粒度分类器,加权具体身体部位信息训练细粒度分类器,最后结合二者分类识别结果形成由粗到细的行为识别框架。
以标注关节点人体运动数据集(joint-annotatedhumanmotiondatabase,jhmdb)行为数据集分类识别为例。jhmdb数据集特点:特点1、视频数据量少。由于jhmdb数据集是从人体运动数据集(humanmotiondatabase51,hmdb51)行为数据集筛选出的单人为主行为,且行为人关键点信息已经标注。该行为数据集包含21类行为,928个有效视频,如果训练神经网络易发生过拟合现象,导致分类器性能较差。特点2、行为类别分布广泛且存在相似行为。jhmdb行为由于单人运动为主,行为类别有限但跨度较大,有梳妆类、体育类和日常行为类。但相似行为存在较多,例如抓和篮球、射击和射箭,跑、走、跳和踢球等。
本发明提出的由粗到细框架结合不同粒度特征方法,正是从人为语义理解出发,将行为数据集按照主要执行行为部位不同,将jhmdb数据集分为上半身类行为、下半身类行为和其他行为。对相似行为例如上半身类行为,选择加权左手部、右手部、上半身特征,对于差异性较大的不同粗类行为,加权全身和上下文信息全局信息的表示。
本发明包括构建利用行为人身体部位关键点,裁剪视频帧和计算好的光流图像,获取不同身体部位图像与光流区域图像,送入cnn网络提取全连接层网络特征,聚合多帧特征和不同身体部位特征,针对性的训练行为识别分类器,此处选用svm分类器。对于粗类别分类器中粗类别真值的获取,即如何将相似行为归为同一个粗类问题,本发明采用真值映射方案,迭代训练粗分类器,将行为类别映射至不同粗类别,直到粗分类器输出粗类别错误率低于阈值。对于每个细粒度分类器,聚合不同身体部位特征,这里粗类别分类器特征和细粒度分类器最后的特征向量都包含原始图像的结构纹理特征和光流图像的运动特征。最后将粗粒度分类器结果概率和细粒度分类器结果概率结合,形成最后分类结果,具体步骤细节为:
a、利用现有成熟的姿态估计算法或者视频内标注信息获取人体关键点信息,裁剪缩放人体不同身体部位图像:上半身,左手部,右手部,下半身部和全身部五个部位。具体以左手手腕、左手臂关键点确定左手部在图像的位置区域;以右手腕、右手臂确定右手部区域;以腰处、头颈处、左右手腕和左右手臂关键点确定人体上半身部区域;以腰处、左右膝关节处和左右脚腕处确定人体下半身区域;以人体所有关键点包括左右手、左右腿、头颈处、腰处关键点处确定全身区域。放大五个部位区域1.2倍左右,使子图像完全包含部位信息,裁剪后并缩放存储,例如网络输入大小为224*224,可裁剪成256*256大小,输入时可以通过随机偏移裁剪的数据增强手段至标准输入大小;
b、以视觉计算组网络(visualgeometrygroupnetwork,vgg)网络作为特征提取网络,通过卷积神经网络对输入视频的连续帧和光流帧中不同部位区域进行多层卷积和池化运算,提取vgg网络倒数第二层4096维的全连接层向量,利用最大、最小聚合策略聚合多帧的特征,级联视频帧和光流图像的特征,形成最后的不同视频i中不同部位pj视频的特征向量
c、利用提取出的不同部位特征与全局视频向量
训练粗分类器中,采用真值映射方案,迭代训练粗分类器,将行为类别映射至不同粗类别,直到粗分类器输出粗类别错误率低于阈值;
其中,n表示第j类行为包含的测试样本数,t表示行为类别总数,k表示划分的粗类别数。划分jhmdb数据集为k=3个粗类别。
迭代训练粗粒度分类器,并且每个类别粗粒度分类错误率控制在0.3以下。测试时,测试视频得到粗粒度分类器识别结果概率
d、训练细粒度分类器:每个细粒度分类器选取不同部位视频特征向量级联,针对当前包含的多种细粒度行为进行分类器训练,遍历视频的不同身体部位区域特征向量组合,找到针对当前细粒度行为分类器的身体部位最佳组合。例如训练区别射击与射箭类运动的上半身类行为分类器,测试时,测试视频得到细粒度分类器识别结果概率
五、利用公式(3)将两级即粗粒度分类器和细粒度分类器分类结果概率融合,得到整个行为识别最终结果:
其中,
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 还没有人留言评论。精彩留言会获得点赞!