一种基于混沌蚁群系统的云中科学工作流费用优化调度方法与流程
本发明属于云计算以及调度算法两大领域,尤其涉及一种基于混沌蚁群系统的云中科学工作流费用优化调度方法。
背景技术:
现代科学在生物信息、天文学、物理学等不同研究领域中运行日益繁杂的大规模科学应用,以模拟和分析现实世界的活动,而科学工作流已被证实是建模和管理这些复杂问题的最有效手段。随着科学计算系统的不断复杂化,科学工作流特征主要表现为数据密集型与计算密集型。通常将科学工作流部署在分布计算环境中,以此达到在合理时间内执行工作流的目的。然而,在传统分布系统平台(超级计算机、集群及网格计算平台等)中部署科学工作流不仅费用昂贵,且资源可扩展性差。现如今,云计算因按需资源供应以及即付即用付费模式的突出优势,使得越来越多的科学工作流应用都转移到云计算中,为科学工作流执行提供了较好的解决方案。
科学工作流调度是在满足一些性能指标下为每个任务分配计算资源的过程,其中调度算法的性能指标中,用户最关心的是租赁计算资源的总费用。如今云计算服务供应商的收费模式一般以小时为最小计费单位(如amazonec2),意味着即使用户仅使用计费单位的一小部分,仍需要支付整个计费单位的费用,也就是无论租赁资源五十九分钟还是一秒钟,都以一小时为单元进行租赁费用的收取。因此,如何在一定的时间(截止期限)内以较低的费用来调度任务成为了云中科学工作流的一个主要问题,而一个好的调度方法或者策略,可以高效完成任务调度以及有效降低租赁资源的总费用。
技术实现要素:
本发明的目的在于:针对基于混沌蚁群系统的云中科学工作流调度租赁虚拟机所需费用问题,提出了一种基于混沌蚁群系统的云中科学工作流费用优化调度方法,旨在减少整个云中工作流任务租赁虚拟机的费用。
为了达到上述目的,本发明所采用的技术方案包括如下部分:
1.一种基于混沌蚁群系统的云中科学工作流费用优化调度方法,具体实施步骤如下:
步骤1:用户提交需求:用户提交科学工作流及相关的资源需求和整个科学工作流调度截止期限;
步骤2:对相关概念进行定义:包括对本文目标函数、约束条件、任务间的传输数据的通信开销、任务开始运行时间、结束运行时间等的定义;
步骤3:云中科学工作流任务排序:计算任务的概率向上权值并根据向上权值降序排列得出任务序列sortedt;
步骤4:使用混沌蚁群系统选择虚拟机:使用混沌蚁群系统对sortedt中的任务在满足截止期限下以费用最小化为目标选择最合适的虚拟机。
2.进一步地,根据专利要求1,本发明提出的基于混沌蚁群系统的云中科学工作流下费用优化调度方法,所述的用户所提交的工作流用有向无循环图g={t,e}来描述,其中图中所有顶点t={t1,t2,...,tn}表示含有n个任务节点的有限集,图中所有有向边e={ei,j|ti,tj∈t}表示任务之间的优先级约束有限集,每一项ei,j表示只有当任务ti执行结束后才能执行任务tj。进一步地,设定datai,j为附属在ei,j上的传输数据,表示只有当任务tj完全接收任务ti传输的数据后才能执行。
3.进一步地,根据专利要求1所述的步骤2中定义的目标函数为租赁所有虚拟机的总费用,约束条件为其工作流的完成时间需满足用户定义的截止期限。
s.t.wft≤d(2)
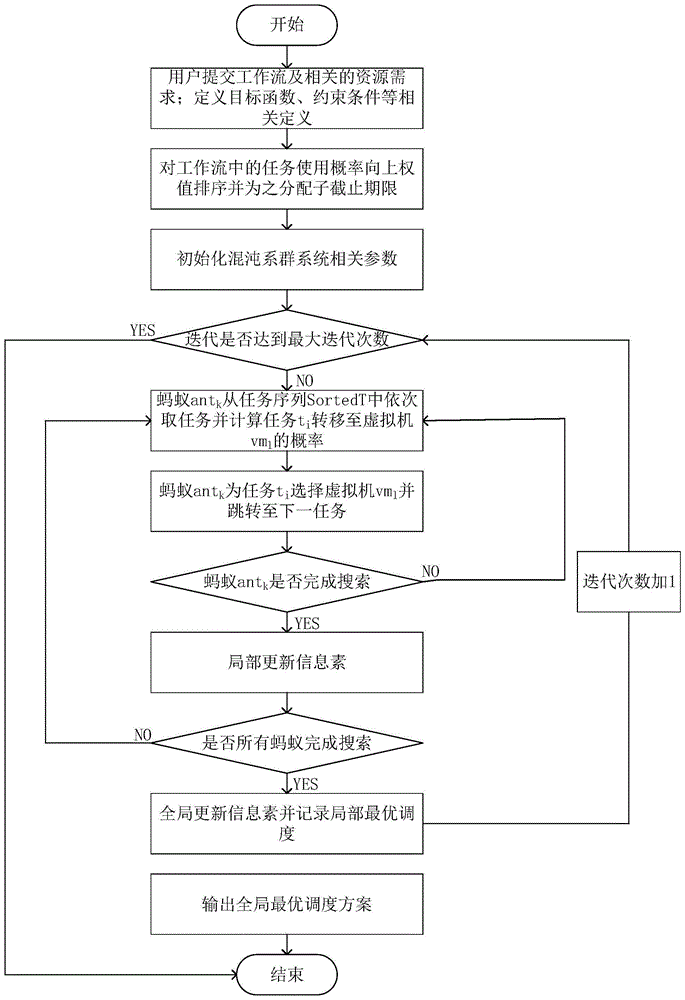
4.本发明基于混沌蚁群系统的云中科学工作流费用优化调度方法,根据专利要求1所述的步骤4使用混沌蚁群系统对排好序的任务进行调度的过程是一个迭代的过程,具体迭代步骤如下:
步骤4.1:初始化蚁群算法相关参数,其中对于初始蚁群信息素τ0使用logistic混沌函数产生;
步骤4.2:迭代开始:判断是否已达到最大迭代次数itmax,若没有达到,则执行步骤4.3,否则迭代结束,转到步骤4.9;
步骤4.3:状态转移规则:蚂蚁antk从任务序列sortedt中依次取任务并计算任务ti分配至虚拟机vml的概率;
步骤4.4:选择虚拟机:根据贪心算法或轮盘赌方式选择虚拟机;
步骤4.5:判断蚂蚁antk是否完成搜索,若已完成搜索则转到步骤4.7,否则转到步骤4.3;
步骤4.6:局部更新信息素;
步骤4.7:判断是否所有蚂蚁都已完成搜索,若已全部完成搜索则转到步骤4.9,否则转到步骤4.3;
步骤4.8:使用混沌算子全局更新信息素并记录局部最优调度方案;
步骤4.9:输出全局最优调度方案。
5.进一步地,根据权利要求4,本发明基于混沌蚁群系统的云中科学工作流费用优化调度方法,所述的步骤4.8中为了提高算法的收敛速度,对全局信息素更新规则增加混沌扰动,修改后的全局信息素更新规则如下:
τi,l(t+1)=(1-ρ)τi,l(t)+δτi,l(t)+r(3)
其中,nc表示当前迭代次数,nc0表示迭代阈值,xn表示根据logistic混沌函数产生的混沌量。
本发明提供的优化调度方法具有如下优点和有益效果:本发明考虑到关键任务对于科学工作流完成时间的影响,使用传统的概率向上权值对任务优先级进行排序,然后使用混沌蚁群系统进行以最小化租赁费用为目标进行虚拟机选择,此方法可有效降低任务的总租赁费用。
附图说明
图1为本发明提供的云中科学工作流下费用优化调度方法流程图;
图2为云工作流实例结构图;
具体实施方式
为了使本领域技术人员更好地理解本申请中的技术问题、技术方案和技术效果,下面结合附图和具体实施方式对本发明一种基于混沌蚁群系统的云中科学工作流下费用优化调度方法作进一步详细说明。
如图1为本发明的方法具体实施步骤:
步骤1:用户提交工作流g={t,e}及整个工作流调度截止期限d;具体实例如图2所示,图中每个顶点表示一个任务,此实例中共有13个任务;有向边代表任务之间优先级约束的关系。如从任务t2指向任务t8的有向边便表示只有任务t2执行结束任务t8才可以执行,此时的data2,8为3,表示任务t2与任务t8传输数据量为3。
步骤2:本发明设定虚拟机共有m种虚拟机且都处于同一数据中心,由于虚拟机都处于同一个数据中心,则虚拟机带宽(也就是bw)都相同。
步骤3:任务ti的概率向上权值ri是从本身至texit的关键路径长度,定义公式如公式5所示,其中eti表示任务ti的平均执行时间,定义公式如公式6所示。根据概率向上权值ri的大小对工作流中所有任务进行优先级大小排列,得到任务排序队列sortedt。
步骤4.1:初始化蚁群算法相关参数,其中对于初始信息素使用logistic混沌函数产生的混沌量也就是给每条路径进行信息素初始化,使得每条路径上的信息素都不相同,可有效减少搜索最优路径的时间;
步骤4.2:迭代开始:判断是否已达到最大迭代次数itmax,若没有达到,则执行步骤4.3,否则迭代结束,转到步骤4.10;
步骤4.3:计算转移概率:蚂蚁antk从任务序列sortedt中依次取任务并计算任务ti选择虚拟机vml的概率;
其中,τi,l表示路径(i,l)上的信息素浓度;α为信息素启发因子,表示蚂蚁在路径上留下的信息素的重要性,越大说明信息素对后面其他蚂蚁选择路径的影响越大;β为期望启发因子,反映了启发函数的重要性,β越大说明蚂蚁在移动过程中启发信息受重视程度越高。
对于上文提到的启发函数ηi,l,定义在虚拟机vml上新增任务ti后增加的租赁费用addci,l的倒数作为启发函数,也就是增加的租赁费用addci,l越少,启发函数ηi,l值越大,任务ti被分到虚拟机vml的概率越高。
addci,l=newcl-oldcl(10)
其中,newcl为在虚拟机vml上增加任务ti后新的总租赁费用,oldcl为在虚拟机vml上增加任务ti前原始的总租赁费用。值得注意的是,在虚拟机vml上新增任务ti所花费的费用可能为0,因此本发明在启发式函数的分母增加一个常数c,以此避免分母为0情况的出现。
步骤5.4:选择虚拟机:为任务根据概率转移公式以及满足子截止期限选择合适的虚拟机。
步骤5.5:判断蚂蚁antk是否完成搜索,若已完成搜索则转到步骤5.7,否则转到步骤5.3。
步骤5.6:局部更新信息素:若一只蚂蚁完成对任务的调度,则进行局部更新信息素,转到步骤5.3,否则转到步骤5.4。局部信息素更新公式为:
其中δτki,l为路径(i,l)上第k只蚂蚁遗留的信息素增量矩阵之和,q表示信息素强度常量,tlck为第k只蚂蚁使用虚拟机的所有费用。
步骤5.7:判断是否所有蚂蚁都已完成搜索,若已全部完成搜索则转到步骤5.9,否则转到步骤5.3。
步骤5.8:全局更新信息素并记录局部最优调度方案;
为了提高算法的收敛速度,我们在迭代前期中将混沌算子添加到全局信息素更新规则中。修改后的全局信息素更新公式如12所示:
全部信息素更新公式为:
τi,l(t+1)=(1-ρ)τi,l(t)+δτi,l(t)+r(12)
其中ρ表示信息素挥发系数;(1-ρ)表示信息素的残留因子,为了防止信息素无限积累,取值范围限定在0~1之间;δτi,l表示路径(i,l)上所有蚂蚁遗留的信息素增量矩阵之和,由公式14计算可得。
步骤5.9:输出全局最优调度方案。
以上实例仅用以说明本发明而非限本发明所描述的技术方案,对于本领域技术人员应该理解,对上述发明所公开的云中科学工作流下截止期限约束的费用优化调度方法,在不脱离大名远离的前提下,还可以在此基础上做出改进,这些改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!