基于特征函数滤波的神经网络参数更新的图像分类方法与流程
本发明属于人工智能中的图像分类技术领域,涉及一种基于特征函数滤波的神经网络参数更新的图像分类方法。
背景技术:
人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的,并具有自学习和自适应的能力。作为人工智能的重要组成部分,它由输入层、输出层及包含在它们之间的单个隐层或者多个隐层三部分构成。神经网络的结构设计主要包括以下几个部分:隐层数量的确定,每个隐层中节点个数的数量及每个节点的激励函数的选取等。当结构性问题确定后,余下的问题中最重要的就是构建目标函数,以及在一定准则下如何辨识网络中包含的众多参数的问题。
对于神经网络中的参数辨识方法,如梯度下降法、最小二乘法等方法均存在一些不足。如梯度下降法迭代算法中步长的选取难以存在一般性标准;算法的复杂度会随着隐层的数量和每个隐层中节点的数量增加而成指数形式增加;由于它本质上是一个局部线性化问题,因此,会因目标函数非线性程度提高而产生较大的训练误差,并且容易收敛到局部极值。
图像分类是计算机视觉、模式识别与机器学习领域非常活跃的研究方向。图像分类与检测在很多领域得到广泛应用,包括安防领域的人脸识别、行人检测、智能视频分析、行人跟踪等,交通领域的交通场景物体识别、车辆计数、逆行检测、车牌检测与识别,以及互联网领域的基于内容的图像检索、相册自动归类等。图像分类通常使用神经网络来实现,然而如上所述,神经网络的参数更新方法中存在的问题成为了图像分类精确度与时间复杂度的瓶颈。因此一种新的神经网络参数更新方法对于图像分类而言就有了重要的意义。
技术实现要素:
本发明针对现有技术的不足,设计了一种基于特征函数滤波的神经网络参数更新的图像分类方法。该方法中所使用的特征函数滤波只需假设测量误差存在均值,模型噪声存在分布函数,不存在局部线性化以及局部收敛的问题,且可以实现网络参数的实时在线自适应更新。将本发明用于图像识别分类,可以提高图像分类的准确率,并降低参数更新的时间复杂度。
本发明包括以下各步骤:
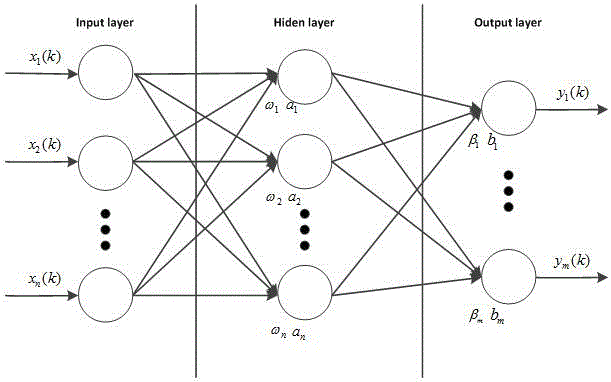
步骤(1)建立由样本输入集x(k)=[x1(k),x2(k),…,xn(k)]t到输出集y(k)=[y1(k),y2(k),…,ym(k)]t之间的关系映射的神经网络模型,其中样本输入集为每个图像样本经过预处理后的特征值,样本输出集为相应每个图像的分类类别,k为第k个样本集的选择,xn(k)为第k个样本的第n个输入,ym(k)为第k个样本的第m个输出。
其中,g(·)为激活函数,通常选取如sigmoid函数,relu函数,高斯函数,多项式等,ωi=[ωi1,ωi2,…,ωil]t,i=1,…,n与a分别为隐层的权重参数与偏置参数,ωi中的各项为其分向量,l为单隐层节点个数,β为输出层权重参数。
其损失函数的一般形式为
其中,
在此所使用的损失函数的具体形式为
步骤(2)初始化网络中隐层的权重参数与偏置参数以及输出层权重参数
每一次迭代在隐层权重参数和偏置参数随机给定的情况下,将网络的全部参数求解问题转化成通过最小二乘来求解输出层权重参数β的问题。该算法具体描述如下:
当隐层的激活函数无限可微时,神经网络不再需要对所有参数进行求解,隐层权重参数和隐层偏置参数可以通过随机选择的方式实现且整个过程中维持不变,此时若将公式(1)中对于模型的描述改为如下形式:
y(k)=h(k)β(3)
其中
h(k)=[h1(k)h2(k)…hl(k)]t
则由于隐层权重参数和隐层偏置参数已确定而使得h(k)已知,所以此时的问题可以转化为如何通过公式(3)求解输出层权重参数β,目标函数也由公式(2)转换为如下形式:
在此使用最小二乘方法,则其解为
上式中,h-1为隐层输出矩阵h的moore-penrose逆。
步骤(3)通过当前新的图像样本输入更新神经网络的输出层权重参数β。
该步骤中使用kalman滤波来进行输出层权重参数β的实时更新。要想用kalman滤波来进行该参数的实时更新,那就必须建立符合kalman滤波的状态方程和测量方程。考虑到待估输出层权重参数β是受一定随机干扰缓变的,故将kalman滤波的状态方程进行如下建模:
β(k+1)=a(k+1,k)β(k)+w(k)(4)
为模拟待估参数受到的干扰,方程中加入了白噪声序列w(k)。
由公式(3)可以得到测量方程如下:
y(k)=hβ(k)+v(k)(5)
其中,v(k)与状态方程类似,也为白噪声序列。
上述kalman滤波模型中,过程噪声w(k)和观测噪声v(k)均为白噪声序列,在采样间隔内为常值。且有e{w(k)w′(k)}=q和e{v(k)v′(k)}=r,a(k+1,k)=e,当w(k)和v(k)相互独立时,e{w(k)v′(k)}=0,β(k)为第k个输出层权重参数。
则该模型求解的第k+1个输出层权重参数β的最优估计值:
其中,
步骤(4)通过特征函数滤波更新隐层权重参数和隐层偏置参数。
特征函数滤波是一种新型的非高斯滤波方法,在特征函数滤波中,当观测方程关于状态变量为非线性时,若满足以下两个要求:
要求1:{w(k)}与{v(k)}为有界的平稳随机过程,x(0)为初始状态,{w(k)},{v(k)}及x(0)相互独立,且已知{w(k)}的分布函数,且其特征函数为
要求2:h(·)是一个已知的波尔可测且光滑的非线性函数。
则可设计如下形式的滤波器:
其中,a(k)为状态转移矩阵,
令
其性能指标为
其中,
加权函数k(t)的选取是为保证j0是实值且有界的,它是给定的正定的权重矩阵,为了约束增益矩阵,最小化此性能指标则可求得滤波增益阵。
下面给出增益阵k(k+1)求解方法和过程。
若令p1(k)和p2(k)分别为
则性能指标可改写为
为了求取增益矩阵k(k+1),令
由于
因此式(13)求得的解即为最小化性能指标的极值点。
设计基于特征函数的参数更新方法可以分两步实现:首先进行隐层权重参数ω与偏置参数a更新,其次是输出层权重参数β更新。但是由于其高复杂性,在此把它分为三个步骤。其描述如下:
对于已经通过步骤(1),步骤(2)和步骤(3)中方法确定了隐层权重参数ω与偏置参数a以及输出层权重参数β的单隐层神经网络,每有新的图片样本输入,依次执行如下三个步骤:
步骤(4-1)隐层权重参数ω更新
首先使用特征函数滤波更新隐层权重参数ω,假定隐层偏置参数a与输出层权重参数β为不变,则对于第k+1个样本,隐层权重参数ω的最优估计值为
该步骤中,对于隐层权重参数ω的更新,由于ω=[ω1,ω2,…,ωn],ωi=[ωi1,ωi2,…,ωil]t是隐层权重参数ω的分向量,ω为n维向量,则需要对于ωi,i=1,…,n分别进行建模求解更新。对于每次ωi的估计,假设ωj,j=1,…,i-1,i+1,…,n均为不变。则以ωi为特征函数滤波中的状态变量可以建立如下状态方程和观测方程:
ωi(k+1)=a·ωi(k)+w(k)(16)
其中模型噪声w(k)只需存在分布函数,测量误差v(k)只需存在均值。则该模型第k个ωi(k)的最优估计值的求解过程如下:
(a)计算p1(k)
如公式(10)所示求解增益阵u(k)的组成矩阵p1(k)。其中,k(t)为加权函数,
(b)计算p3(k)
y(k)为样本输出集中第k个的图片分类类别,
(c)计算增益阵u(k)
u(k)是正定矩为假设阵r(k)固定的权重矩阵
(d)计算待估计的隐层权重参数的分向量ωi(k)在k时刻的估计值
步骤(4-2)隐层偏置参数a更新
然后使用特征函数滤波更新隐层偏置参数a,假定隐层权重参数ω与输出层权重参数β不变,则对于第k+1个图片样本,隐层偏置参数a的最优估计值为
该步骤中以隐层偏置参数a为状态变量建立与步骤(3-1)中类似的状态方程和观测方程并求解得到第k个隐层偏置参数a(k)的最优估计值。
步骤(4-3)输出层权重参数β更新
使用线性卡尔曼滤波方法更新输出层权重参数β,假定隐层权重参数ω与隐层偏置参数a均为不变,则对于第k+1个样本,输出层权重参数β的最优估计值为
该步骤中的建模和参数求解与步骤(3)中相同。
本发明的有益效果:使用特征函数滤波和卡尔曼滤波相结合的方法,用于更新神经网络中的所有参数。在图片分类中应用该方法,每有新的图片样本到来,不需要结合旧的图片样本就可以更新神经网络中的所有参数以适应图片工况的变化,且提高了图片分类的准确率,减小了计算的复杂度。
附图说明
图1是单隐层神经网络模型图。
图2是本发明的计算步骤流程图。
具体实施方式
以下结合附图2对本发明作用于图像分类的应用作进一步说明。
本发明具体步骤如下
步骤(1)建立由样本输入集x(k)=[x1(k),x2(k),…,xn(k)]t到输出集y(k)=[y1(k),y2(k),…,ym(k)]t之间的关系映射的神经网络模型,其中样本输入集为每个图像样本经过预处理后的特征值,样本输出集为相应每个图像的分类类别,k为第k个样本集的选择,xn(k)为第k个样本的第n个输入,ym(k)为第k个样本的第m个输出。以单隐层神经网络为例,见图1:
其中,g(·)为激活函数,通常选取如sigmoid函数,relu函数,高斯函数,多项式等,ωi=[ωi1,ωi2,…,ωil]t,i=1,…,n与a分别为隐层的权重参数与偏置参数,ωi中的各项为其分向量,l为单隐层节点个数,β为输出层权重参数。
其损失函数的一般形式为
其中,
在此所使用的损失函数的具体形式为
步骤(2)初始化网络中隐层的权重参数ω与偏置参数a以及输出层权重参数β
每一次迭代在隐层权重参数ω和偏置参数a随机给定的情况下,将网络的全部参数求解问题转化成通过最小二乘来求解输出层权重参数β的问题。该算法具体描述如下:
当隐层的激活函数无限可微时,神经网络不再需要对所有参数进行求解,隐层权重参数ω和隐层偏置参数a可以通过随机选择的方式实现且整个过程中维持不变,此时若将公式(1)中对于模型的描述改为如下形式:
y(k)=h(k)β(3)
其中
h(k)=[h1(k)h2(k)…hl(k)]t
则由于隐层权重参数ω和隐层偏置参数a已确定而使得h(k)已知,所以此时的问题可以转化为如何通过公式(3)求解输出层权重参数β,目标函数也由公式(2)转换为如下形式:
在此使用最小二乘方法,则其解为
上式中,h-1为隐层输出矩阵h的moore-penrose逆。
步骤(3)通过当前新的图像样本输入更新神经网络的输出层权重参数β。
该步骤中使用kalman滤波来进行输出层权重参数β的实时更新。要想用kalman滤波来进行该参数的实时更新,那就必须建立符合kalman滤波的状态方程和测量方程。考虑到待估输出层权重参数β是受一定随机干扰缓变的,故将kalman滤波的状态方程进行如下建模:
β(k+1)=a(k+1,k)β(k)+w(k)(4)
为模拟待估参数受到的干扰,方程中加入了白噪声序列w(k)。
由公式(3)可以得到测量方程如下:
y(k)=hβ(k)+v(k)(5)
其中,v(k)与状态方程类似,也为白噪声序列。
上述kalman滤波模型中,过程噪声w(k)和观测噪声v(k)均为白噪声序列,在采样间隔内为常值。且有e{w(k)w′(k)}=q和e{v(k)v′(k)}=r,a(k+1,k)=e,当w(k)和v(k)相互独立时,e{w(k)v′(k)}=0,β(k)为第k个输出层权重参数。
则该模型求解的第k+1个输出层权重参数β的最优估计值:
其中,
步骤(4)通过特征函数滤波更新隐层权重参数ω和隐层偏置参数a。
设计基于特征函数的参数更新方法可以分两步实现:首先进行隐层权重参数ω与偏置参数a更新,其次是输出层权重参数β更新。但是由于其高复杂性,在此把它分为三个步骤。其描述如下:
对于已经通过步骤(1),步骤(2)和步骤(3)中方法确定了隐层权重参数ω与偏置参数a以及输出层权重参数β的单隐层神经网络,每有新的图片样本输入,依次作如下三个步骤:
步骤(4-1)隐层权重参数ω更新
首先使用特征函数滤波更新隐层权重参数ω,假定隐层偏置参数a与输出层权重参数β为不变,则对于第k+1个样本,隐层权重参数ω的最优估计值为
该步骤中,对于隐层权重参数ω的更新,由于ω=[ω1,ω2,…,ωn],ωi=[ωi1,ωi2,…,ωil]t是隐层权重参数ω的分向量,ω为n维向量,则需要对于ωi,i=1,…,n分别进行建模求解更新。对于每次ωi的估计,假设ωj,j=1,…,i-1,i+1,…,n均为不变。则以ωi为特征函数滤波中的状态变量可以建立如下状态方程和观测方程:
ωi(k+1)=a·ωi(k)+w(k)(16)
其中模型噪声w(k)只需存在分布函数,测量误差v(k)只需存在均值。则该模型第k个ωi(k)的最优估计值的求解过程如下:
(a)计算p1(k)
如公式(10)所示求解增益阵u(k)的组成矩阵p1(k)。其中,k(t)为加权函数,
(b)计算p3(k)
y(k)为样本输出集中第k个的图片分类类别,
(c)计算增益阵u(k)
u(k)是正定矩为假设阵r(k)固定的权重矩阵
(d)计算待估计的隐层权重参数的分向量ωi(k)在k时刻的估计值
步骤(4-2)隐层偏置参数a更新
然后使用特征函数滤波更新隐层偏置参数a,假定隐层权重参数ω与输出层权重参数β不变,则对于第k+1个图片样本,隐层偏置参数a的最优估计值为
该步骤中以隐层偏置参数a为状态变量建立与步骤(3-1)中类似的状态方程和观测方程并求解得到第k个隐层偏置参数a(k)的最优估计值。
步骤(4-3)输出层权重参数β更新
使用线性卡尔曼滤波方法更新输出层权重参数β,假定隐层权重参数ω与隐层偏置参数a均为不变,则对于第k+1个样本,输出层权重参数β的最优估计值为
该步骤中的建模和参数求解与步骤(3)中相同。
在图片分类中应用本方法,每有新的图片样本到来,不需要结合旧的图片样本就可以更新神经网络中的所有参数以适应图片工况的变化,且提高了图片分类的准确率,减小了计算的复杂度。
- 还没有人留言评论。精彩留言会获得点赞!