文本分类方法和文本分类系统与流程
本发明涉及计算机技术领域,具体涉及一种文本分类方法和文本分类系统。
背景技术:
随着“大数据”技术的发展,越来越多的领域均开始利用计算机进行文本匹配和分类,而随着文本数据集规模的快速增长,文本分类的算法越来越多,计算复杂度也越来越高。
常用的文本分类方法有基于关联规则或基于关键词进行的分类,该类方法均是根据目标文本中含有的关键词或根据关联关系进行分类,当某一目标文本中包含了某一关键词时,则可以较好的分类,若目标文本中没有包含预先选定的关键词,则无法进行该文本的分类,这样的分类方法导致很多目标文本无法匹配到合适的分类中,且基于关键词的推荐方法较为粗糙,没有很好地考虑语义信息,分类结果不精确。
因此,发明人认为,上述的文本分类方法有很大的局限性,基于关键词对目标文本进行分类,存在查找耗时耗力,而且分类不准的问题。
技术实现要素:
有鉴于此,本发明实施例提供一种文本分类方法和文本分类系统,使用卷积网络将目标文本编码为第一文本向量,然后再通过聚类模型将文本库中的源文本表示为多个第二文本向量,通过计算量向量之间的距离,选择距离最近的文本库作为目标文本的待分类文本库,完成文本分类,避免因为目标文本中不含关键词就无法准确分类的问题。
根据本发明第一方面,提供一种文本分类方法,包括:
获取目标文本,并采用卷积网络将其编码为第一文本向量;
将每个文本库中的源文本均采用聚类模型分为多个类别,每个所述类别均以该类别的聚类中心对应的第二文本向量表示;以及
分别计算所述第一文本向量与多个所述第二文本向量之间的距离,采用排序模型将距离最近的k个所述第二文本向量对应的所述聚类中心所在的所述文本库作为所述目标文本的候选文本库,k为正整数。
优选地,所述文本分类方法还包括:从存储系统中获取多个所述文本库,每个所述文本库均包括多个所述源文本。
优选地,获取目标文本,并采用卷积网络将其编码为第一文本向量包括:
对所述目标文本进行分词操作;
将所述目标文本对应的分词集合通过映射函数映射为词向量;
对每个所述词向量进行维度填充,并赋予随机值;
对每个所述词向量进行卷积和池化操作,然后进行拼接得到第一文本向量。
优选地,将每个文本库中的源文本均采用聚类模型分为多个类别,每个所述类别均以该类别的聚类中心对应的第二文本向量表示包括:
设定每个所述文本库对应的所述聚类中心的数量;
将每个所述文本库中的所有所述源文本采用所述聚类模型聚类为设定数量的所述类别;
用所述聚类中心的坐标作为第二文本向量表示每个对应的所述类别;
将每个所述文本库的聚类结果存储。
优选地,所述聚类中心的数量为4个。
优选地,用文本相似度来表示所述第一文本向量与所述第二文本向量之间的距离。
优选地,所述文本相似度包括余弦相似度。
优选地,采用排序模型将距离最近的k个所述第二文本向量对应的所述聚类中心所在的所述文本库作为所述目标文本的候选文本库包括:
采用排序函数对所述余弦相似度进行排序;
挑选排序后的余弦相似度位于前k位的所述第二文本向量对应的所述聚类中心所在的所述文本库作为所述目标文本的候选文本库。
优选地,所述卷积网络包括textcnn网络,所述聚类模型包括kmeans聚类模型。
根据本发明第二方面,提供一种文本分类系统,包括:
目标文本获取单元,用于获取目标文本,并采用卷积网络将其编码为第一文本向量;
聚类单元,用于将每个文本库中的源文本均采用聚类模型分为多个类别,每个所述类别均以该类别的聚类中心对应的第二文本向量表示;以及
筛选单元,用于分别计算所述第一文本向量与多个所述第二文本向量之间的距离,采用排序模型将距离最近的k个所述第二文本向量对应的所述聚类中心所在的所述文本库作为所述目标文本的候选文本库,k为正整数。
优选地,所述文本分类系统还包括:
文本库获取单元,用于从存储系统中获取多个所述文本库,每个所述文本库均包括多个所述源文本。
优选地,所述目标文本获取单元包括:
分词单元,用于对所述目标文本进行分词操作;
映射单元,用于将所述目标文本对应的分词集合通过映射函数映射为词向量;
填充单元,用于对每个所述词向量进行维度填充,并赋予随机值;
拼接单元,用于对每个所述词向量进行卷积和池化操作,然后进行拼接得到第一文本向量。
优选地,所述聚类单元包括:
数量设定单元,用于设定每个所述文本库对应的所述聚类中心的数量;
分类单元,用于将每个所述文本库中的所有所述源文本采用所述聚类模型聚类为设定数量的所述类别;
向量显示单元,用于用所述聚类中心的坐标作为第二文本向量表示每个对应的所述类别;
聚类存储单元,用于将每个所述文本库的聚类结果存储。
优选地,所述聚类中心的数量为4个。
优选地,用文本相似度来表示所述第一文本向量与所述第二文本向量之间的距离。
优选地,所述文本相似度包括余弦相似度。
优选地,所述筛选单元包括:
排序单元,用于采用排序函数对所述余弦相似度进行排序;
选取单元,用于挑选排序后的余弦相似度位于前k位的所述第二文本向量对应的所述聚类中心所在的所述文本库作为所述目标文本的候选文本库。
根据本发明第三方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机指令,所述计算机指令被执行时实现如上述所述的文本分类方法。
根据本发明第四方面,提供一种文本分类装置,包括:存储器,用于存储计算机指令;处理器,耦合到所述存储器,所述处理器被配置为基于所述存储器存储的计算机指令执行实现如上述所述的文本分类方法。
本发明的实施例具有以下优点或有益效果:该文本分类方法和文本分类系统首先采用网络结构来对目标文本进行编码,编码成第一文本向量,然后通过聚类模型将多个文本库中的源文本进行聚类,每个类别均以其聚类中心的第二文本向量表示,分别计算第一文本向量与多个第二文本向量之间的距离,选择距离最近的几个第二文本向量对应的源文本所在的文本库作为目标文本的待选文本库,由此完成对目标文本的分类。通过对目标文本编码,然后对文本库聚类,可以将文本分类问题转化为向量之间的计算,只需要计算向量之间的距离即可得知目标文本与多个文本库之间的关系,从未进行分类,不需要将目标文本与庞大的文本库中所有的源文本进行匹配,也不需要逐一进行相似度的计算,简化了计算步骤,节省了计算量,可以快速高效地完成文本分类,且分类准确,提高了文本分类的效率,避免了根据关键词分类带来的弊端。
附图说明
通过参照以下附图对本发明实施例的描述,本发明的上述以及其它目的、特征和优点将更为清楚,在附图中:
图1示出了本发明实施例中的文本分类方法的流程图;
图2示出了本发明实施例中汇总的文本分类方法的流程图;
图3a示出了图1所示的步骤s101的具体流程图;
图3b示出了本发明实施例中目标文本的编码过程的示意图;
图4示出了图1所示的步骤s102的具体流程图;
图5示出了本发明实施例中的文本分类系统的结构图;
图6示出了本发明实施例中汇总的文本分类系统的结构图;
图7示出了本发明实施例的文本分类系统中的目标文本获取单元501的具体结构图;
图8示出了本发明实施例中的文本分类系统中的聚类单元502的具体结构图;
图9示出了根据本发明实施例的文本分类装置的结构图。
具体实施方式
以下基于实施例对本发明进行描述,但是本发明并不仅仅限于这些实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程没有详细叙述。另外附图不一定是按比例绘制的。
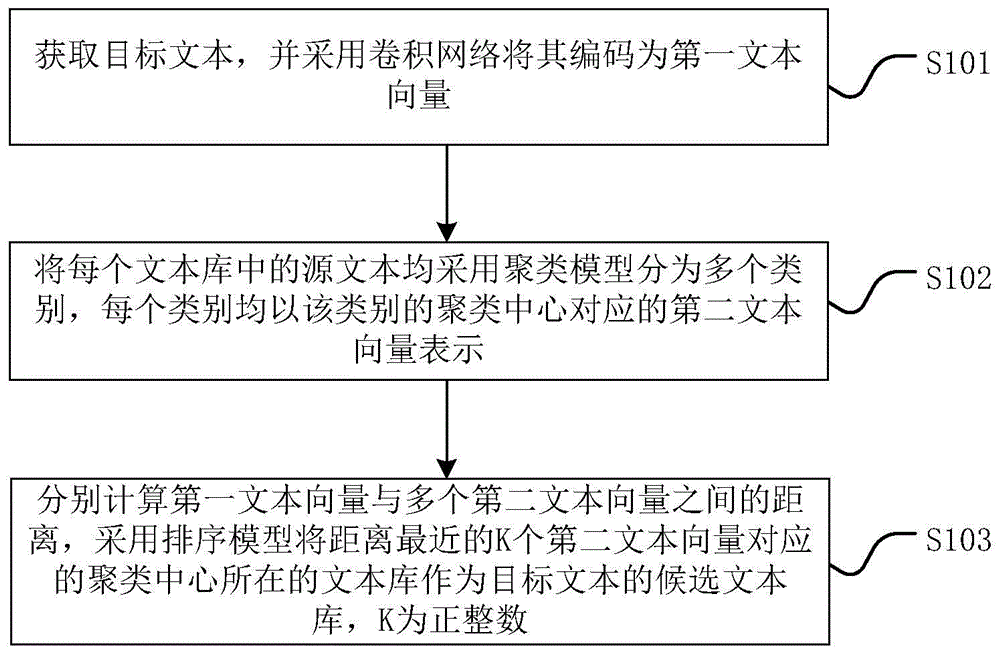
图1示出了本发明实施例中的文本分类方法的流程图,具体步骤包括s101-s103。
在步骤s101中,获取目标文本,并采用卷积网络将其编码为第一文本向量。
在步骤s102中,将每个文本库中的源文本均采用聚类模型分为多个类别,每个类别均以该类别的聚类中心对应的第二文本向量表示。
在步骤s103中,分别计算第一文本向量与多个第二文本向量之间的距离,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,k为正整数。
在本实施例中,将待分类的目标文本以向量形式表示,并计算其与存储系统中的各文本库中的源文本对应的向量之间的距离,距离小代表相似度高,选择相似度最高的几个文本库作为目标文本的待分类文本库,然后再利用其他的方法进行精确地分类,此分类方法可以减小匹配计算量,提升文本分类效率,以下进行详细说明。
在步骤s101中,获取目标文本,并采用卷积网络将其编码为第一文本向量。
本实施例中采用的文本分类思想是,首先将文本映射为文本向量,然后通过比较文本向量之间的相似度来判断文本之间的匹配度,从而进行分类,所以首先要将文本以文本向量的形式表示出来。
给定一个目标文本,将其分类到最可能的文本库中,需要比较目标文本和文本库中的源文本的相似度。首先通过一系列函数将目标文本转化为第一文本向量,本实施例中,采用卷积网络将目标文本编码为192长度的特征向量,采用的卷积网络例如是textcnn网络。当然也可以使用lstm、bilstm等其他网络,在表征目标文本的向量的时候,cnn模型可能更加具有优势,所以本实施例中的编码部分使用了textcnn网络。
卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现,它包括卷积层(convolutionallayer)和池化层(poolinglayer)。而textcnn模型是卷积神经网络在自然语言处理中的变体,主要不同在于卷积操作的时候卷积核的宽度是整个词嵌入向量的长度,池化阶段是对全部的卷积结果一次性池化,其他操作与卷积神经网络基本一致。
本实施例采用卷积网络,将目标文本进行编码,首先是经过分词,词嵌入等操作,然后进行卷积,池化和拼接等,形成一个具有192长度的向量,具体地向量编码过程在图3a和图3b进行描述。
在步骤s102中,将每个文本库中的源文本均采用聚类模型分为多个类别,每个类别均以该类别的聚类中心对应的第二文本向量表示。
上一步中已经对目标文本进行了向量化,本步骤是对源文本的向量化,源文本是存储在不同的文本库中的,每个文本库中的所有源文本都具有一定的相似度,而不同的文本库代表不同的类别。虽然同一文本库中的源文本的相似度较高,但是由于源文本数量较多,还可以进行更细致的分类。目标文本直接与每个文本库中的所有源文本进行相似度比较,计算量太庞大,直接与文本库的名称匹配,又可能分类不精确,所以可以将每个文本库中的源文本再进行分类,分为几个不同的类别,每个类别都具有一个中心源文本,用目标文本和该中心源文本进行比较,计算量减小很多,匹配结果也更精确。
本实施例选用聚类模型进行分类,将每一个文本库中的所有源文本再进行一个级别的分类,聚类模型例如采用kmeans模型,每个文本库中需要分类的数量可以提前设定,例如是分为4个类别,则对应有4个聚类中心。keans聚类是把n个点(可以是样本的一次观察或一个实例)划分到k个聚类中的模型,首先随机初始化聚类中心,把所有点向该聚类中心聚类,然后再计算上次聚类结果的簇中心点,然后再次计算;等到簇中心变化收敛的时候,聚类结束。
本实施例选用的只是一种示例性的聚类模型,还可以通过一些指标来确定聚类数,同时聚类方法可以使用层次聚类、谱聚类等。
通过聚类后,一个文本库中的源文本被分为4个类别,每个类别都具有一个聚类中心,且每个类别中的源文本的相似度更高,用聚类中心的坐标作为第二文本向量,表征该类别。由此完成对第一文本向量和第二文本向量的向量化,例如,设定目标文本对应的文本向量为第一文本向量,表示为vec1,设定源文本对应的聚类中心的文本向量为第二文本向量,表示为vec2。
在步骤s103中,分别计算第一文本向量与多个第二文本向量之间的距离,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,k为正整数。
将目标文本转化为192长度的第一文本向量vec1,然后分别计算该向量vec1与每个文本库中每个聚类中心的距离,即计算第一文本向量vec1和第二文本向量vec2之间的距离,距离近的代表相似度较高,关联度较高,距离远的表示差别较大。
在一个实施例中,采用文本相似度来表示第一文本向量与第二文本向量之间的距离,文本相似度包括余弦相似度。例如,在和衡量距离的时候,选择cos(a,b)来衡量向量a与向量b之间的距离。所以,采用余弦相似度函数,比较第一文本向量vec1和第二文本向量vec2之间的余弦相似度,从而判断目标文本和源文本之间的关联程度。用公式表示为:sim1=cos(vec1,vec2),其中cos()表示余弦函数,sim1表示比较的两个文本间的余弦相似度。在一定程度上认为,相似度越高,两个文本之间的关联程度越高。
将目标文本和源文本用文本向量表示,并计算二者之间的余弦相似度,用相似度来表示向量之间的距离,降低了计算时间,提高了分类效率。
计算出文本向量之间的距离后,根据计算结果为目标文本匹配合适的文本库,首先需要对距离进行排序,距离短的代表相似度较高,目标文本与该文本库中的源文本属于同一类的可能性较高,所以,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,其中,k为正整数。
在一个实施例中,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库包括:采用排序函数对余弦相似度进行排序;以及挑选排序后的余弦相似度位于前k位的第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,排序函数例如是top-k函数。例如,挑选余弦相似度最高的前15个第二文本向量对应的聚类中心所在的几个文本库作为目标文本的候选文本库,至此文本分类结束。
本实施例的文本分类方法首先采用网络结构来对目标文本进行编码,编码成第一文本向量,然后通过聚类模型将多个文本库中的源文本进行聚类,每个类别均以其聚类中心的第二文本向量表示,分别计算第一文本向量与多个第二文本向量之间的距离,选择距离最近的几个第二文本向量对应的源文本所在的文本库作为目标文本的待选文本库,由此完成对目标文本的分类。通过对目标文本编码,然后对文本库聚类,可以将文本分类问题转化为向量之间的计算,只需要计算向量之间的距离即可得知目标文本与多个文本库之间的关系,从未进行分类,不需要将目标文本与庞大的文本库中所有的源文本进行匹配,也不需要逐一进行相似度的计算,简化了计算步骤,节省了计算量,可以快速高效地完成文本分类,且分类准确,提高了文本分类的效率,避免了根据关键词分类带来的弊端。
本实施例的文本分类方法可应用在实践中,例如,目前很多超市中的商品都是按照三级分类进行展示的,例如,食品可以分为生鲜和熟食;而生鲜可以分为蔬菜、水果、鲜肉和加工食品等,熟食可以分为热食和凉拌;蔬菜包括叶菜类、花果类、菌类和调味类等,水果包括国产水果、进口水果、特价水果等……热食包括烧烤、油炸、蒸炒等,凉拌包括寿司和凉菜等。此时,就是按照三级分类进行的,生鲜和熟食就可以作为第三级分类,蔬菜,水果等作为第二级分类,进口水果和国产水果可以作为第一级分类。如果有某一样新产品,需要对其进行三级分类时,就可以采用本实施例的文本分类方法。
将该产品对应的名称作为目标文本,而已经分好类的三级品类产品作为文本库,例如第三级分类的种类即为文本库的数量,而三级分类下的所有产品的名称均可以看做是源文本,每个文本库包括不同的源文本。对每个三级分类下的源文本进行聚类,选择出设定数量的聚类中心,将聚类中心和目标文本均以向量形式表示,然后计算二者之间的距离,距离小的,说明相似度较高,选择新产品的名称对应的文本向量与三级分类下的聚类中心对应的文本向量之间距离最小的前几位,它们所对应的第三级分类可以作为新产品的候选分类,然后根据其他的方法判断该新产品到底该归类到哪一个第三级分类中。
将本发明实施例的文本分类方法应用于产品分类的实践中,是采用textcnn网络结构来表示产品名称,然后通过通过聚类模型来选择三级品类的代表点,然后计算新产品与类中心的距离,最终实现三级品类的分类。
图2示出了本发明实施例中汇总的文本分类方法的流程图,具体包括以下步骤。
在步骤s201中,获取目标文本,并采用卷积网络将其编码为第一文本向量。
在步骤s202中,从存储系统中获取多个文本库,每个文本库均包括多个源文本。
在步骤s203中,将每个文本库中的源文本均采用聚类模型分为多个类别,每个类别均以该类别的聚类中心对应的第二文本向量表示。
在步骤s204中,分别计算第一文本向量与多个第二文本向量之间的距离,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,k为正整数。
本实施例是比前述实施例更加完善的文本分类方法。其中,步骤s201和步骤s203-s204和图1的步骤s101-s103相同,这里就不再赘述。
在步骤s202中,从存储系统中获取多个文本库,每个文本库均包括多个源文本。
因为文本库的数据较为庞大,所以文本库是存储在存储系统中的,要将目标文本进行分类和匹配,就需要获取文本库,每个文本库均包含多个不同的源文本,每一个文本库中的所有源文本之间都有着较为密切的联系,且一个文本库代表着一个类型的分类。
通过本实施例的文本分类方法,可以将目标文本最可能匹配的几个文本库选择出。选择出目标文本对应的待分类文本库后,可以将分类结果反馈给文本分类的请求发起者。
结合上一实施例,将本实施例的文本分类方法应用于新产品的分类中时,不仅要获取新产品的名称对应的第一文本向量,还需要获取大量的已有产品对应的三级分类,这些经过三级分类的产品数据均存储在存储系统中,从存储系统中提取出这些数据,然后进行目标文本的分类。
提取出的数据也可以看做是模型数据,如下表1所示,模型数据例如为第三方商家提供的商品数据,包含商品名称和商品对应的三级品类名称、商品编码等。系统中存储的商品对应的三级品类在3300个左右,经过数据清理之后,现有的三级品类数目在2900左右,表1示出的是抽样的部分数据。第一列为三级品类名称(第三级分类的名称),第二列为抽样的部分商品的数据。
表1
从表1中可以看到,第三级分类是两个,也就是代表两个文本库,分别是led光源和u盘,而每个分类下对应着多个商品,这些商品的名称可以看做是源文本,另外,每个三级品类下对应多个分类,可以看做是经过聚类后的分类,每个分类可以有一个聚类中心。
根据本实施例提供的文本分类算法,采用textcnn网络结构与kmeans聚类相结合的方法,可以快速为新产品进行分类,那么再计算机的实现方面,则是用户输入的部分为商品名称数据,模型输出的部分是该新商品所属的top-k三级品类,其中k值可以设定。
通过对新产品的名称,即目标文本进行向量化操作后,新商品名称通过物流报价分类textcnn模型编码为192向量,即已经将商品名称数字化了,下一步在每一个三级品类中将商品向量聚类,然后将聚类中心作为该三级品类的代表,之后将192长度向量与三级品类的聚类中心向量计算距离,然后返回距离最近的k个三级品类作为待分类的三级品类。
图3a示出了图1所示的步骤s101的具体流程图。具体包括以下步骤。
在步骤s1011中,对目标文本进行分词操作。
对目标文本进行分词操作,即将目标文本对应拆分成多个字符或单词。假设某目标文本可以分为n个分词,则分词后的分词集合为:w={w1,w2,…,wn},其中n表示该文本的分词总数。所以,经过分词后,目标文本对应的第一分词集合表示为:w1={w1,w2,…,wn}。
图3b示出了本发明实施例中目标文本的编码过程的示意图,结合图3a和图3b,商品名称编码部分采取了textcnn网络,最终将由若干字组成的商品名称转化为拼接向量输出,如图3b,图中以其中一个商品名称“纯彩手机屏幕防爆钢化玻璃膜”为例,说明整个网络计算过程。
首先,用户输入“纯彩手机屏幕防爆钢化玻璃膜”时,使用jieba分词包或其他分词方法将名称分词为:“纯彩”、“手机”、“屏幕”、“防爆”和“钢化玻璃”,然后执行下一步的操作。
在步骤s1012中,将目标文本对应的分词集合通过映射函数映射为词向量。
本实施例例如采用映射函数将分词转化为向量,例如采用word2vec特征将分词映射为向量。
在步骤s1013中,对每个词向量进行维度填充,并赋予随机值。
经过分词和词嵌入之后,再使用工具函数将商品名称的分词结果填充为相同长度的词组,分别对每个分词进行不同的填充,使得填充之后的每个分词的长度一致。然后分别将五个词随机赋值为128维度的位于-1和1之间的随机数。
本实施例采用将商品名称数据通过词嵌入矩阵的方式来数字化商品名称数据,利用卷积网络textcnn编码商品名称,将商品名称文字转化为32维度的向量然后输出,单在实施时,本实施例抽取该卷积模型中的的倒数第二层的输出结果(192长度向量)作为最终输出,将192长度的向量作为第一文本向量。
在步骤s1014中,对每个词向量进行卷积和池化操作,然后进行拼接得到第一文本向量。
根据不同的卷积窗口来覆盖不同数量的词汇数来卷积操作,由于上下文之间是具有语义相关性的,使用不同卷积窗口来卷积可以尽可能的包含上下文词汇。然后对卷积结果进行池化操作,池化就是对卷积结果进行降维的一个操作,采用最大值池化就是选择同大小卷积窗口的多个结果中最大值作为最终结果的一种操作。然后再将不同卷积窗口的池化输出结果拼接为一个向量,然后将拼接的向量作为商品名称的数字化表示。
本流程是对目标文本的向量化的具体说明,而且本实施例中是以商品名称为例进行的说明,其他的文本分类也可以采用该流程。
下面结合图4对本发明实施例的文本分类方法的聚类模型的分类流程进行简要说明。
图4示出了图1所示的步骤s102的具体流程图。
在步骤s1021中,设定每个文本库对应的聚类中心的数量。
本实施例例如使用kmeans方法在三级品类内聚类,首先设定每个文本库中可以分类的聚类中心的数量,然后再进行聚类。例如,聚类中心的数量为4个。则在每个三级品类中选择的聚类数都为4,然后保留每一个三级品类中的4个聚类中心的坐标。
在步骤s1022中,将每个文本库中的所有源文本采用聚类模型聚类为设定数量的类别。
确定好聚类中心的数量之后,就按照此数量进行多次聚类,最终在每个文本库中均选择出四个聚类中心,四个聚类中心分别代表四个类型的源文本。
在步骤s1023中,用聚类中心的坐标作为第二文本向量表示每个对应的类别。
本实施例中,对聚类中心进行向量化表示,例如可以将聚类中心对应的坐标作为第二文本向量,如果向量的长度不够,可以采用一定的手段将长度填充起来。
在步骤s1024中,将每个文本库的聚类结果存储。
将聚类后的每个文本库的聚类结果进行存储,便于后续计算时的调用。由于数据量较为庞大,存储起来可以随时取用,不用担心数据的丢失。
在聚类的时候,将聚类的结果缓存为初始数据,新商品与聚类中心计算相似度的时候,只需要实现新商品与2900三级品类*4类中心的计算量,而不需要去和所有的商品计算相似度,大大减小了文本匹配的运算量。而且该聚类模型在后期的可拓展性也是较高的,即使第三方商家提供的商品sku突然增加,计算量也是相对稳定的,可以以接口服务的形式快速响应。大大的减小了文本分类时的计算量和计算难度,而且可以避免由于商品名称中不包含关键词而无法准确分类的情况,文本分类的准确度和精度都提高了。
应该指出的是,本发明不仅限于上述实施例提供的文本向量的获取算法和聚类算法,其他算法,也可以实践本发明实施例提供的文本分类方法。
图5示出了本发明实施例中的文本分类系统的结构图。
该文本分类系统500包括目标文本获取单元501、聚类单元502和筛选单元503。
目标文本获取单元501用于获取目标文本,并采用卷积网络将其编码为第一文本向量;
聚类单元502用于将每个文本库中的源文本均采用聚类模型分为多个类别,每个类别均以该类别的聚类中心对应的第二文本向量表示;
筛选单元503用于分别计算第一文本向量与多个第二文本向量之间的距离,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,k为正整数。
在本实施例中,文本分类系统500首先采用网络结构来对目标文本进行编码,编码成第一文本向量,然后通过聚类模型将多个文本库中的源文本进行聚类,每个类别均以其聚类中心的第二文本向量表示,分别计算第一文本向量与多个第二文本向量之间的距离,选择距离最近的几个第二文本向量对应的源文本所在的文本库作为目标文本的待选文本库,由此完成对目标文本的分类。通过对目标文本编码,然后对文本库聚类,可以将文本分类问题转化为向量之间的计算,只需要计算向量之间的距离即可得知目标文本与多个文本库之间的关系,从未进行分类,不需要将目标文本与庞大的文本库中所有的源文本进行匹配,也不需要逐一进行相似度的计算,简化了计算步骤,节省了计算量,可以快速高效地完成文本分类,且分类准确,提高了文本分类的效率,避免了根据关键词分类带来的弊端。
在一个实施例中,用文本相似度来表示第一文本向量与第二文本向量之间的距离,文本相似度包括余弦相似度,那么筛选单元503包括排序单元(图中未示出)和选取单元(图中未示出)。
排序单元用于采用排序函数对余弦相似度进行排序;选取单元用于挑选排序后的余弦相似度位于前k位的第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库。
图6示出了本发明实施例中汇总的文本分类系统的结构图,图6所示的实施例在图5的实施例的基础上增加了文本库获取单元601。
文本库获取单元601用于从存储系统中获取多个文本库,每个文本库均包括多个源文本。
图7示出了本发明实施例的文本分类系统中的目标文本获取单元501的具体结构图。
该文本分类系统500的目标文本获取单元501包括分词单元5011、映射单元5012、填充单元5013和拼接单元5014。
分词单元5011用于对目标文本进行分词操作;
映射单元5012用于将目标文本对应的分词集合通过映射函数映射为词向量;
填充单元5013用于对每个词向量进行维度填充,并赋予随机值;
拼接单元5014用于对每个词向量进行卷积和池化操作,然后进行拼接得到第一文本向量。
图8示出了本发明实施例的文本分类系统中的聚类单元502的具体结构图。
该文本分类系统500的聚类单元502包括数量设定单元5021、分类单元5022、向量显示单元5023和聚类存储单元5024。
数量设定单元5021用于设定每个文本库对应的聚类中心的数量;
分类单元5022用于将每个文本库中的所有源文本采用聚类模型聚类为设定数量的类别;
向量显示单元5023用于用聚类中心的坐标作为第二文本向量表示每个对应的类别;
聚类存储单元5024用于将每个文本库的聚类结果存储。
在一个实施例中,聚类中心的数量为4个。
应该理解,本发明实施例的系统和方法是对应的,因此,在系统的描述中以相对简略的方式进行。
图9示出了本发明实施例的文本分类装置的结构图。图9示出的设备仅仅是一个示例,不应对本发明实施例的功能和使用范围构成任何限制。
参考图9,该文本分类装置900包括通过总线连接的处理器901、存储器902和输入输出设备903。存储器902包括只读存储器(rom)和随机访问存储器(ram),存储器902内存储有执行系统功能所需的各种计算机指令和数据,处理器901从存储器902中读取各种计算机指令以执行各种适当的动作和处理。输入输出设备包括键盘、鼠标等的输入部分;包括诸如阴极射线管(crt)、液晶显示器(lcd)等以及扬声器等的输出部分;包括硬盘等的存储部分;以及包括诸如lan卡、调制解调器等的网络接口卡的通信部分。存储器902还存储有以下的计算机指令以完成本发明实施例的文本分类方法规定的操作:获取目标文本,并采用卷积网络将其编码为第一文本向量;将每个文本库中的源文本均采用聚类模型分为多个类别,每个类别均以该类别的聚类中心对应的第二文本向量表示;分别计算第一文本向量与多个第二文本向量之间的距离,采用排序模型将距离最近的k个第二文本向量对应的聚类中心所在的文本库作为目标文本的候选文本库,k为正整数。
相应地,本发明实施例提供一种计算机可读存储介质,该计算机可读存储介质存储有计算机指令,所述计算机指令被执行时实现上述文本分类方法所规定的操作。
附图中的流程图、框图图示了本发明实施例的系统、方法、装置的可能的体系框架、功能和操作,流程图和框图上的方框可以代表一个模块、程序段或仅仅是一段代码,所述模块、程序段和代码都是用来实现规定逻辑功能的可执行指令。也应当注意,所述实现规定逻辑功能的可执行指令可以重新组合,从而生成新的模块和程序段。因此附图的方框以及方框顺序只是用来更好的图示实施例的过程和步骤,而不应以此作为对发明本身的限制。
系统的各个模块或单元可以通过硬件、固件或软件实现。软件例如包括采用java、c/c++/c#、sql等各种编程语言形成的编码程序。虽然在方法以及方法图例中给出本发明实施例的步骤以及步骤的顺序,但是所述步骤实现规定的逻辑功能的可执行指令可以重新组合,从而生成新的步骤。所述步骤的顺序也不应该仅仅局限于所述方法以及方法图例中的步骤顺序,可以根据功能的需要随时进行调整。例如将其中的某些步骤并行或按照相反顺序执行。
根据本发明的系统和方法可以部署在单个或多个服务器上。例如,可以将不同的模块分别部署在不同的服务器上,形成专用服务器。或者,可以在多个服务器上分布式部署相同的功能单元、模块或系统,以减轻负载压力。所述服务器包括但不限于在同一个局域网以及通过internet连接的多个pc机、pc服务器、刀片机、超级计算机等。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!